数据结构与算法:揭秘面试中常问的基础算法
发表时间: 2020-09-16 06:30
上一周的几篇文章主要分享了有关数据结构相关的知识,有兴趣的可以翻回去看一下。前面我也说到:数据结构和算法是一对"相爱相杀的"组合,所以接下来要分享下我个人对于一些算法的理解和实现。本文将主要分享基础的查找和排序(代码基于python)

既然要开始分享算法,那必然要先介绍下算法相关的一些基本术语,如下。
稳定性
概念:如果值相同的元素在排序前后保证着排序前的相对位置,则称为稳定的排序,反之则为不稳定排序,如图
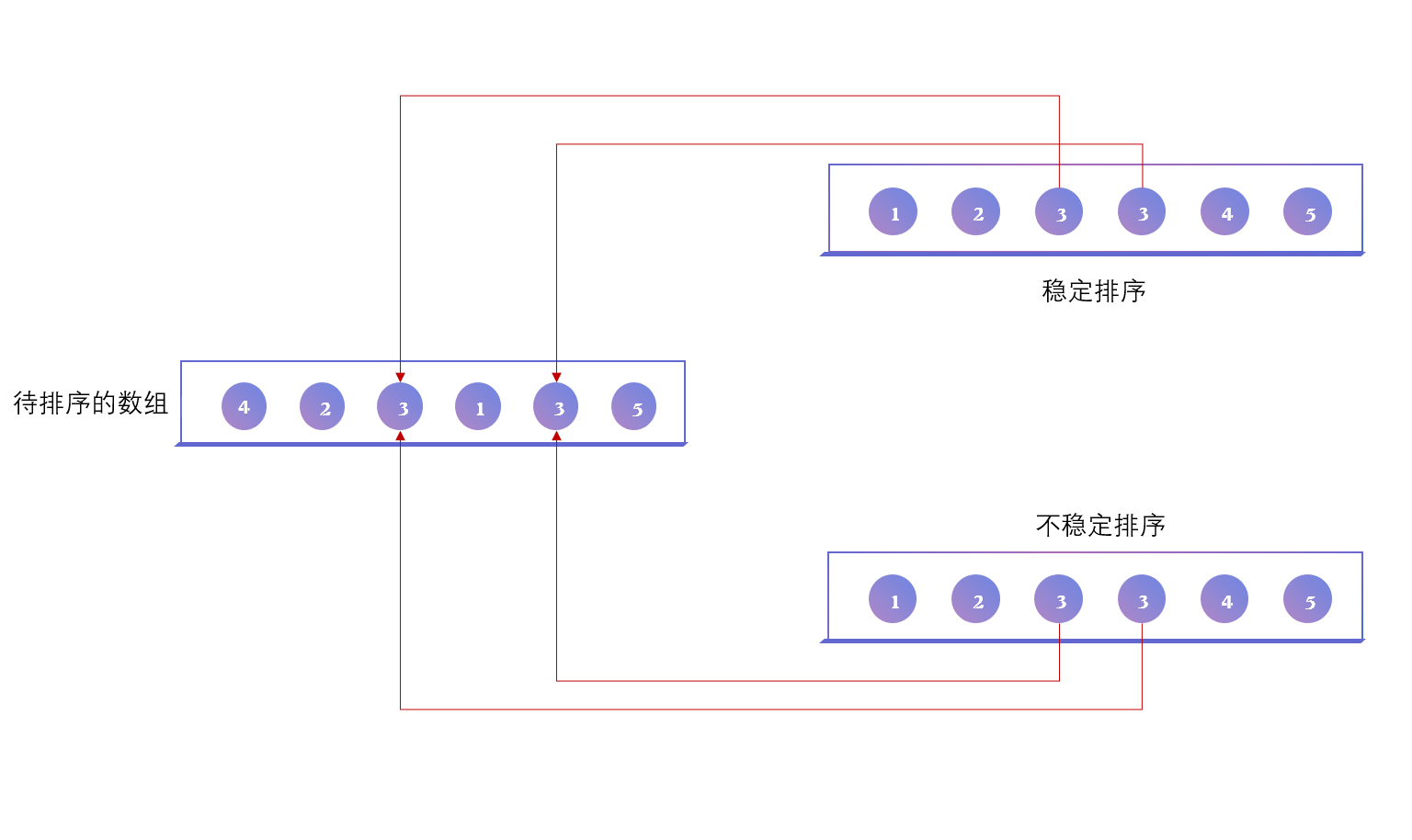
两个相同的3的相对位置的区别
主流衡量算法好坏的方法
大O表示法
它表示随着输入大小n 的增大,算法执行需要的时间的增长速度可以用 f(n) 来描述,f(n)就是问题规模n的某个函数
几个经典排序的时间复杂度(平均情况下)和稳定性
术语基本上就差不多了,接下来开始分享算法。
需求:从给定的数组中寻找某个数据
暴力法是最符合正常人逻辑的一种算法,总结来说就是穷举所有可能,然后从所有可能中寻找结果,但是时间复杂度一般比较高。

官方定义
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列
理解
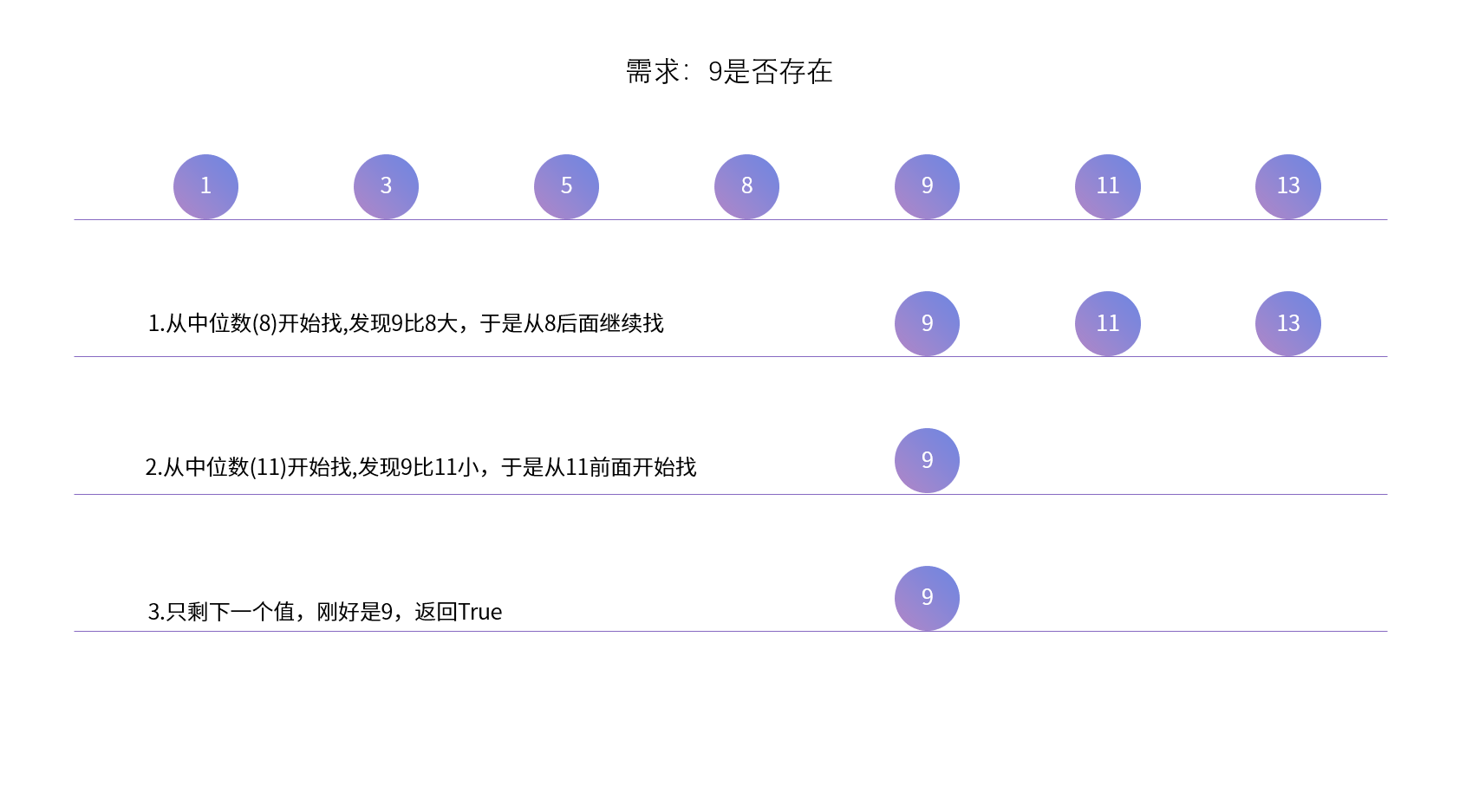
二分查找9是否存在的逻辑
代码实现

算法基本上是面试必问的问题之一了。连最基础的排序算法也有n多种不同的实现,何况还有更复杂的包括递归,动态规划等等。下面将主要分享几种非常基础但是重要的排序算法。
冒泡排序是最最最好理解的一种排序算法,但是只会下面的第一种可能不够,因为面试官很可能会问你有没有什么可优化的空间。
冒泡理解
想象一下河里的水泡,都是由小到大慢慢浮出水面的一种状态。
动图来自菜鸟,仅作技术沟通,侵删
实现
最粗暴的方式

简单优化版(减少列表有序部分的比较次数)
比如一个无序列表的几项在调整部分排序后,已经有序了,那么此时就不需要再进行比较了,程序退出即可。

继续优化
记录最后一次交换元素的位置,主要在于后面已经有序的部分不再进行比较

选择排序的原理
一般来讲,每次循环默认选定列表第一个位置为当前列表最大值,将此位置的值和后面的值做比对,如果发现更大的值,则记录该值的位置,直到遍历到列表末尾,将末尾的值和最大位置的值交换,这样最大的值便出现在列表的最后一个位置,以此类推。
所以选择排序是基于数据的索引进行排序。

动图来自菜鸟,仅作技术沟通,侵删
选择排序的代码实现

插入排序的原理
将原列表想象成两部分,前面是已经排好序的,后面是乱序的,依次将乱序部分的每一个数据都和前面排好序的部分进行比较,插入到相应的位置
算法思路
动图来自菜鸟,仅作技术沟通,侵删
插入排序代码实现

本片主要分享了最基础的关于查找和排序相关算法的原理和实现,包括二分查找,冒泡排序,选择排序,以及插入排序,这些属于入门级的算法,后面文章会继续分享基于递归的经典算法"归并排序以及快速排序"等稍微复杂一点点的排序算法。
我是一名奋战在编程界的pythoner,工作中既要和数据打交道,也要和erp系统,web网站保持友好的沟通……时不时的会分享一些提高效率的编程小技巧,在实际应用中遇到的问题以及解决方案,或者源码的阅读等等,欢迎大家一起来讨论!如果觉得写得还不错,欢迎关注点赞,谢谢。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号