如何用 Python 实现办公自动化,让 2 小时的工作在 10 分钟内完成?
发表时间: 2021-08-11 04:55
模块的介绍和安装
Python专栏中有对所有可以操作Excel的模块进行了对比分析,感兴趣的同学可以前去围观。
推荐阅读:Python杀死Excel?众多模块哪家强
openpyxl模块是一个可以读取和写入Excel文件的模块,可以处理Excel数据、公式、样式,在表格里面插入图表等;需要单独安装不包含在python标准库里;
安装:pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
在windows系统下使用此条指令进行第三方库的安装省时间,Mac端直接使用pip3 install 模块名
具体openpyxl的官方文档可以参照https://openpyxl.readthedocs.io/en/stable/
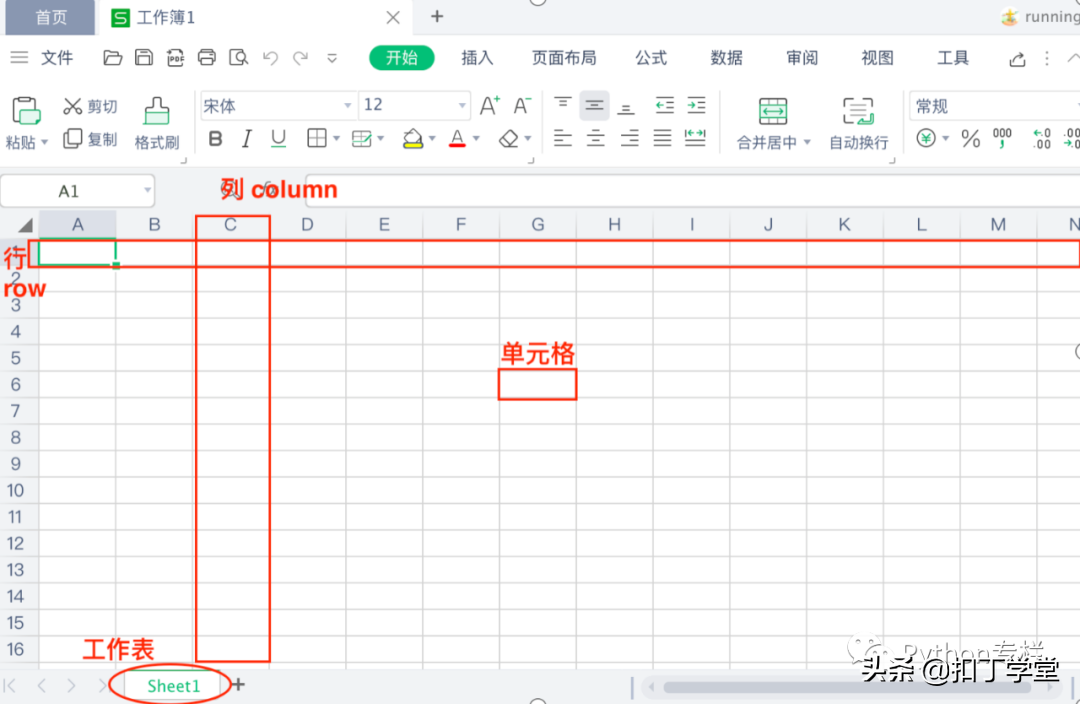
Excel表格术语
列:column,以字母表示,在表格的上方
行:row,以数字表示,但是注意这里是从1开始,在表格的左侧
表单:sheet,在表格的下部
读数据
下面读取表格的整体思路就是:
load_workbook(filename = 表格文件路径);workbook.sheetnames 获取表格文件内的sheet名称
注意:只能打开存在的表格,不能用该方法创建一个新表格文件
我们通过读取丝芙兰的售卖商品来学习Excel操作,内容如下:
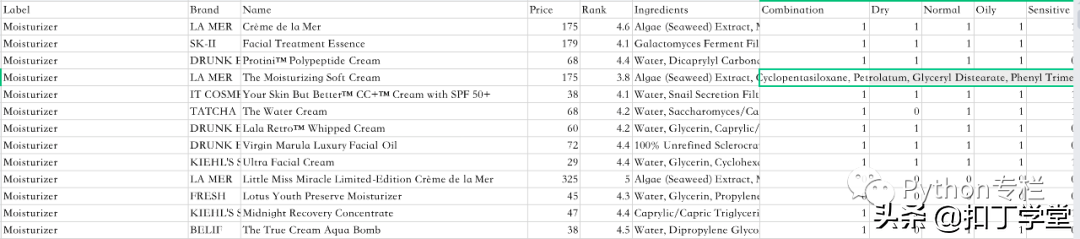
from openpyxl import load_workbookworkbook = load_workbook(filename= 'cosmetics.xlsx')print(workbook.sheetnames)可以看到有:
['cosmetics', 'Sheet1', 'Sheet2']那么我们就可以通过sheetname获取表格,但是如果Excel中只有一个sheet,那么可以直接使用.active
sheet = workbook['cosmetics'] # 返回的是workbook对象:<Worksheet "cosmetics">但是我们的workbook是有多个sheet的,active的使用如下:
sheet = workbook.active获得Excel里面的sheet之后就可以对表格的数据进行操作。比如:获取表格的尺寸大小;第一行第一列的数据,代码如下:
print(sheet.dimensions) # 获取的表格的范围:A1:K1473cell = sheet['B1']print(cell.value) # 获取B1表格的数据,结果:Brandcol_content = sheet['B'] # 表示获取B这一列row_content = sheet[3] #获取第3行数据print(row_content)注意返回的Cell单元格对象
(<Cell 'cosmetics'.A3>, <Cell 'cosmetics'.B3>, <Cell 'cosmetics'.C3>, <Cell 'cosmetics'.D3>, <Cell 'cosmetics'.E3>, <Cell 'cosmetics'.F3>, <Cell 'cosmetics'.G3>, <Cell 'cosmetics'.H3>, <Cell 'cosmetics'.I3>, <Cell 'cosmetics'.J3>, <Cell 'cosmetics'.K3>)如果想获取每个里面的值,可以结合value属性
# 接上代码for row in row_content: print(row.value).iter_rows(min_row = 最低行数,max_row = 最高行数,min_col = 最低列数,max_col = 最高列数) 按行获取
.iter_cols(min_row = 最低行数,max_row = 最高行数,min_col = 最低列数,max_col = 最高列数) 按列获取
注意:这两个演示任一个都可以,两个案例的区别就是第一个是每次获取一行内容,第二个是按照列获取内容。
每次获取一行数据
for row in sheet.iter_rows(min_row=2, max_row=5, min_col= 1,max_col=4): # 涵盖范围的所有单元格都会显示 # print(row) # 每行的内容是一个元组的内容,如果想看到数据还需要继续遍历 for cell in row: print(cell.value) print('-'*50)结果:

这个获取的内容有点类似使用pandas的loc获取第几行几列的情况。
同样列的获取也是一样道理,就是每次获取一列数据
for col in sheet.iter_cols(min_row=2, max_row=5, min_col= 1,max_col=4): print(col) for cell in row: print(cell.value) print('-'*50)结果:

如果有需要获取表格的行或者列可以使用,sheet.rows或者sheet.columns
案例:
编写一个python程序,要求:
(1)打开文件丝芙兰化妆品表格cosmetics.xlsx
(2)找到其中空的单元格
(3)输出这些空单元格的坐标(如A1,B5,C6)
from openpyxl import load_workbook# 1. 加载cosmetics.xlsx表格workbook = load_workbook(filename= 'cosmetics.xlsx')# 2. 得到cosmetics工作簿sheet = workbook['cosmetics']# 3. 获取工作簿的范围并切割 范围:'A1:K1473' ---->使用字符串的split分隔得到:['A1','K1473']size_ls=sheet.dimensions.split(':')# 4. 从而可以得到行和列的最大和最小值col_min,row_min,col_max,row_max = size_ls[0][0],size_ls[0][1],size_ls[1][0],size_ls[1][1:]# print(col_min,row_min,col_max,row_max) # 打印结果是:A,1,K,1473 即最小列是A,最大列是K,最小行是1,最大行是1473# 5. 声明一个空的列表存放有空值的单元格坐标none_list = []# 6. 遍历行和列# 遍历列,但是需要注意的是列是字母,所以要使用ord将字母转成数字才可以使用range范围for col in range(ord(col_min),ord(col_max)+1): # 7. 遍历行,将字符串的行转成整型 for row in range(int(row_min), int(row_max)+1): # 8. 通过chr(col)+str(row)获取单元格坐标,再通过chr将数字转成字母比如65就是A,所以chr(col)+str(row)的结果类似是:A3 if sheet[chr(col)+str(row)].value == None: # 9. 如果某个单元格没有值则将单元格坐标保存到列表:none_list中 none_list.append(chr(col)+str(row))# 10. 打印查看none_list里面的内容for i in none_list: print(i)综合对比openpyxl在读取获取数据上没有pandas有优势,但是pandas不能修改表格,但是openpyxl是可以的。
写数据
向某个格子写入数据并保存
sheet[‘A1’] = ‘你好啊’
用Python列表插入行数据
sheet.append(Python列表) 插入的数据会接在表格内已有数据后面
复制一个sheet
workbook.copy_worksheet(sheet实例)
案例:
from openpyxl import Workbookfrom openpyxl.utils import get_column_letterwb = Workbook()dest_filename = 'workbook.xlsx'# 激活默认工作薄ws1 = wb.active# 设置工作簿ws1.title = "numbers"# 向指定单元格写入内容ws1['C5'] = 3.14ws1['A2'] = 1.5# 创建第二个工作薄,名字为ws2 = wb.create_sheet(title="score")data = [ ['张三',100], ['李四',98], ['王五',83], ['赵六',99],]for row in data: ws2.append(row)# 复制一个sheetwb.copy_worksheet(ws2)# 最后将内容保存wb.save(filename = dest_filename)workbook = load_workbook(filename= 'workbook.xlsx')sheet = workbook['score']sheet['B5'] = '=AVERAGE(B1:B4)'sheet['B6'] = '=SUM(B1:B4)'workbook.save(filename='workbook.xlsx')如果你对Excel足够熟悉也可以使用过复杂的公式:
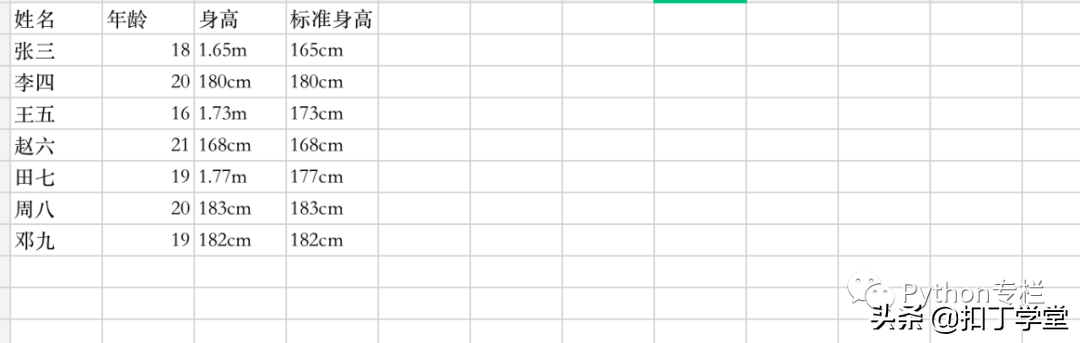
workbook = load_workbook(filename= 'workbook.xlsx')sheet = workbook['Sheet1']sheet['D1'] = '标准身高'# Excel中的公式: =IF(RIGHT(C2,2)="cm",C2,SUBSTITUTE(C2,"m","")*100&"cm")for i in range(2,9): sheet['D{}'.format(i)] = f'=IF(RIGHT(C{i},2)="cm",C{i},SUBSTITUTE(C{i},"m","")*100&"cm")'workbook.save(filename='workbook.xlsx')结果:
可以使用的公式是(可以通过下列代码获取):
from openpyxl.utils import FORMULAE print(FORMULAE)比如说有SUM

sheet.auto_filter.ref:给表格添加“筛选器”
.auto_filter.ref = sheet.dimension 给所有字段添加筛选器;
.auto_filter.ref = "A1" 给A1这个格子添加“筛选器”,就是给第一列添加“筛选器”;
sheet.freeze_panes = ‘G2’
冻结的结果是,在这个窗格的左上都是不动的,当移动滑块时,变化的只有窗格的右下方数据。也就是当运行此程序代码后,Excel表格里面会在G2窗格(左上方)处出现’十字’坐标线,在第二象限的数据没有办法移动,改变的只有其它象限的数据
from openpyxl import load_workbook# 1. 加载cosmetics.xlsx表格workbook = load_workbook(filename= 'cosmetics.xlsx')# 2. 得到cosmetics工作簿sheet = workbook['cosmetics']# 3. 设置筛选器sheet.auto_filter.ref = 'A1'# 4. 冻结C100窗口sheet.freeze_panes ='C100'# 5. 保存设置workbook.save(filename = 'cosmetics.xlsx')当然如果不需要也可以删除行、列、表,分别使用:
.remove("sheet名"):删除某个sheet表;
.delete_rows(idx = 数字编号,amount = 要插入的列数) 删除行, 从idx这一列开始,包括idx这一列
.delete_cols(idx = 数字编号,amount = 要插入的列数) 删除列, 从idx这一行开始,包括idx这一行
也可以添加空行
插入多行空行
.insert_rows(idx = 数字编号,amount = 要插入的列数) 在idx数字编号的行上边插入几行
或者多个空列
.insert_cols(idx = 数字编号,amount = 要插入的列数) 在idx数字编号的列左边插入几列
编写一个Python程序,要求:
(1)打开文件丝芙兰化妆品表格cosmetics.xlsx
(2)找到Price这一列
(3)找到Price中大于100的数据
(4)将这些数据所在行复制到一个新的Excel文件中
from openpyxl import Workbookfrom openpyxl import load_workbookworkbook = load_workbook(filename = 'cosmetics.xlsx')sheet = workbook.activeworkbook_1 = Workbook()sheet_1 = workbook_1.activecells = sheet['D']data_list = []for cell in cells: if isinstance(cell.value,int) and cell.value >100: data_list.append(cell.row)print('输出满足条件的数据所在行数的列表:\n{}\n'.format(data_list))j = 1for row in data_list: for col in range(ord('A'),ord('G')+1): sheet_1[chr(col)+str(j)] = sheet[chr(col)+str(row)].value print('正在写入第{}行数据'.format(j),end = ' ') j += 1workbook_1.save('cosmetics_other.xlsx')样式
修改字体样式
Font(name=字体名称,size=字体大小, bold=是否加粗,italic=是否斜体,color=字体颜色)
获取表格中字体的样式
cell.font.属性
设置对齐样式
Alignment(horizontal=水平对齐模式,vertical=垂直对齐模式,text_rotation=旋转角度,wrap_text=是否自动换行)
设置边框样式
Side(style=边线样式,color=边线颜色) Border(left=左边线样式,right=右边线样式,top=上边线样式,bottom=下边线样式)
填充
PatternFill(fill_type=填充样式, fgColor=填充颜色) GradientFill(stop=(渐变颜色1,渐变颜色2,…))
设置行高和列宽
.row_dimensions[行编号].height = 行高 .column_dimensions[列编号].width = 列宽
合并单元格
.merge_cells(待合并的格子编号) .merge_cells(start_row=起始行号,start_column=起始列号,end_row=结束行号,end_column=结束列号)
取消合并单元格
.unmerge_cells(待合并的格子编号) .unmerge_cells(start_row=起始行号,start_column=起始列号,end_row=结束行号,end_column=结束列号)
案例综合应用
编写一个python程序,要求
(1)打开文件丝芙兰化妆品表格cosmetics.xlsx
(2)找到Rank在4.5年以上的,Price价格大于100的数据
(3)将其他数据删除,最后不要在中间留空行
(4)将price数据背景标为红色,字体标为白色
(5)保存该Excel文件
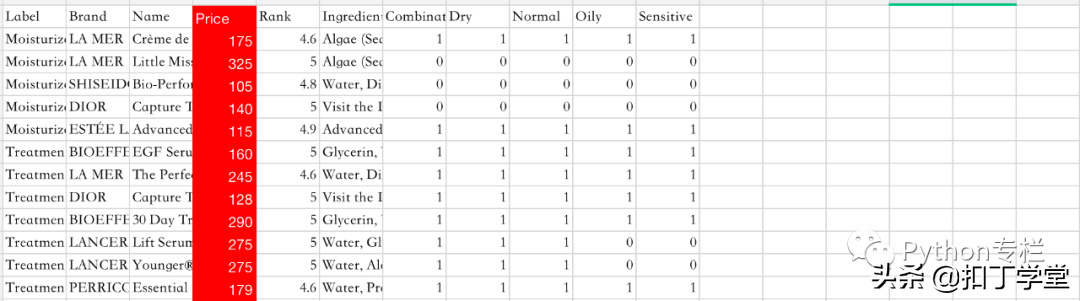
import osfrom openpyxl import Workbookfrom openpyxl import load_workbookfrom openpyxl.styles import Fontfrom openpyxl.styles import PatternFillworkbook = load_workbook(filename = 'cosmetics.xlsx')sheet = workbook.activeworkbook_1 = Workbook()sheet_1 = workbook_1.activedef return_col_or_row(content): '''函数功能:根据输入的content, 筛选出窗格中含有这个content的所有的col(列)和row(行) 返回两个的列表,第一个是所在列的数据,第二个是所在行的数据 ''' data_size = sheet.dimensions size_ls = data_size.split(":") col_min,row_min,col_max,row_max = size_ls[0][0],size_ls[0][1],size_ls[1][0],size_ls[1][1:] row_ls = [] col_ls = [] for col in range(ord(col_min),ord(col_max)+1): for row in range(int(row_min), int(row_max)+1): if sheet[chr(col)+str(row)].value == content: col_content = chr(col) row_content = str(row) col_ls.append(col_content) row_ls.append(row_content) return(col_ls,row_ls)col_by_Rank = return_col_or_row('Rank')[0][0]col_Price = return_col_or_row('Price')[0][0]data_col_by_Rank = sheet[col_by_Rank]data_col_Price = sheet[col_Price]data_finial_row = []for i in range(len(data_col_by_Rank)): if data_col_by_Rank[i].value=='Rank': continue if data_col_Price[i].value=='Price': continue if isinstance(float(data_col_by_Rank[i].value), float) and float(data_col_by_Rank[i].value) >4.5 and isinstance(float(data_col_Price[i].value), float) and float(data_col_Price[i].value)>100: print('Rank的数值为{},对应的价格是{}'.format(data_col_by_Rank[i].value,data_col_Price[i].value)) data_finial_row.append(data_col_by_Rank[i].row)print('\n筛选后满足要求的数据行列表输出为:{}\n'.format(data_finial_row))data_finial_row.insert(0,1)#这一步的目的是将原来文件的标签写到新文件中去j = 1for row in data_finial_row: for col in range(ord('A'),ord('K')+1): #print(sheet[chr(col)+str(row)].value) sheet_1[chr(col)+str(j)] = sheet[chr(col)+str(row)].value print('正在写入第{}行数据'.format(j),end = ' ') j += 1print('\n\n数据已全部导入新Excel文件!下面给数据做标记......\n')data_after_Price = sheet_1[return_col_or_row('Price')[0][0]]for cell in data_after_Price: cell.fill = PatternFill(fill_type='solid',fgColor='FF0000') cell.font = Font(color='FFFFFF')print('数据标记完成')workbook_1.save(filename='筛选数据后的表格.xlsx')print('\ncompleted!') 结果:
绘制图形
from openpyxl import Workbookfrom openpyxl.chart import BarChart, Series, Reference,BarChart3D wb = Workbook()ws = wb.active rows = [ (None, 2020, 2021), ("Apples", 6, 9), ("Oranges", 5, 2), ("Pears", 8, 3)] for row in rows: ws.append(row) data = Reference(ws, min_col=2, min_row=1, max_col=3, max_row=4)titles = Reference(ws, min_col=1, min_row=2, max_row=4)chart = BarChart3D()chart.title = "3D Bar Chart"chart.add_data(data=data, titles_from_data=True)chart.set_categories(titles)ws.add_chart(chart, "E5")wb.save("bar3d.xlsx")或者
from openpyxl import Workbookfrom openpyxl.chart import Series, Reference, BubbleChartwb = Workbook()ws = wb.activerows = [ ("Number of Products", "Sales in USD", "Market share"), (14, 12200, 15), (20, 60000, 33), (18, 24400, 10), (22, 32000, 42), (), (12, 8200, 18), (15, 50000, 30), (19, 22400, 15), (25, 25000, 50),]for row in rows: ws.append(row)chart = BubbleChart()chart.style = 18 # use a preset style# add the first series of dataxvalues = Reference(ws, min_col=1, min_row=2, max_row=5)yvalues = Reference(ws, min_col=2, min_row=2, max_row=5)size = Reference(ws, min_col=3, min_row=2, max_row=5)series = Series(values=yvalues, xvalues=xvalues, zvalues=size, title="2013")chart.series.append(series)# add the secondxvalues = Reference(ws, min_col=1, min_row=7, max_row=10)yvalues = Reference(ws, min_col=2, min_row=7, max_row=10)size = Reference(ws, min_col=3, min_row=7, max_row=10)series = Series(values=yvalues, xvalues=xvalues, zvalues=size, title="2014")chart.series.append(series)# place the chart starting in cell E1ws.add_chart(chart, "E1")wb.save("bubble.xlsx")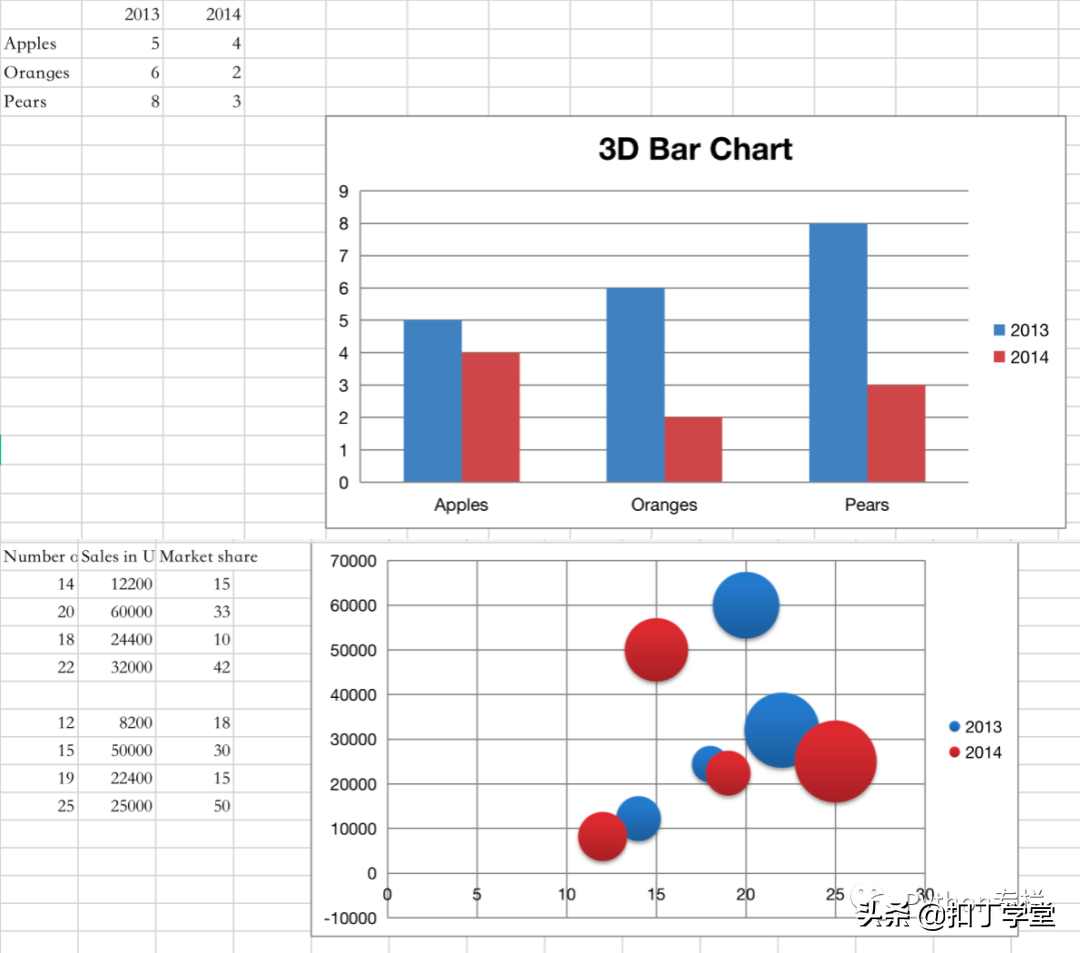
Python全栈+人工智能、网络安全等热门学科,正在火热报名中,想从事互联网IT行业,想高薪就业的同学,欢迎咨询免费体验~,线上部分学科学费最高减免3000元。
以下文章来源于Python专栏 ,作者宋宋
来源:
https://mp.weixin.qq.com/s/K_rHejrgOXKIXg9hJ30PhA
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号