六年磨砺,Node.js无难驾驭
发表时间: 2018-01-19 20:42
阿里云于近日推出了Node.js性能平台,旨在为Node.js应用提供集性能监控、性能优化和故障排查为一体的SaaS化服务。更为重要的是,阿里云公共云用户可免费使用该平台的全部功能。
随着近年社区的蓬勃发展,Node.js许多曾经的缺点都已经得到了改进;但相比其它在工业界有深厚积累和众多实践的企业级技术而言,Node.js还是一门年轻的技术,尽管使用者越来越多,可是真正涉足基础技术的人员依然很少。
早在2012年,阿里巴巴也面临着业界普遍遇到的问题。彼时,Node.js已经诞生了三年有余,而阿里也使用近一年的Node.js。阿里云的高级技术专家朴灵回忆道:“我以前端工程师身份加入淘宝,主要负责开发数据相关的Web产品,并在那时正式接触Node.js服务端。作为这门新技术的狂热粉丝,能够开发并将其落地无疑是相当兴奋激动的。当时有一个场景是要将前端数据发送到后端,通过Node.js记录到MongoDB中。然而从那时候起,噩梦开始了。创建应用在正式上线运行后,每到3天内存都会增长并触发报警直到线上重启。”
彼时团队不仅面临着如何解决线上应用内存问题的巨大压力,而且受到了为何使用新(不成熟)技术的质疑和挑战。在重读每行项目代码、线下压测之后,项目依然呈现线下ok但线上ko的诡异现象,期间只能采取定期重启应用的过渡办法。经过一段时间的寝食难安之后,团队终于定位到前端的数据提交模块,并发现是由于大量数据提交引发MongoDB调用堆积而导致的内存泄露。
“这件事情给了刚刚正式接触服务端的我很深刻的印象,只要一想起就会隐隐作痛。”朴灵说道,“这也让我意识到:‘虽然我们可以游刃有余地构建Node.js应用,但是我们并没有真正地驯服它。’”
也正是因此,朴灵开始转向底层Node.js的研究。他说道:“如今,国内很很多Node.js的开发者,在面对线上问题时,他们会像我当初一样手足无措。即使你JavaScript语言的使用轻车熟路,但是对于Node.js的底层——Chrome V8 引擎,前端工程师们几乎一无所知。”
2014年,淘宝准备大力投入Node.js以改善上层应用的开发效率。而对于阿里巴巴而言,既然决定使用一门技术,则必然要能够通透彻底地掌握该技术。就像阿里巴巴对JVM、操作系统内核、tengine等领域的投入一样,投入研发资源并专门成立了Node.js底层技术团队。
团队至此正式地开启了更底层技术的探索,但是,实话实说最开始时确实有些迷茫,团队要做一些帮助大家排坑的事情,但是对于具体做什么并不是了然于胸。团队曾经花费三个月专注在性能优化,并做出了Node Profiler 工具,该工具可以深度挖掘CPU热点问题及成因,可是它并不是刚需也不能很好地解决线上问题。
团队一边学习一边摸索,在否决掉了一些并不成功的方向后,团队确定了自己的使命:为Node.js技术提供各种支持保障,在开发、测试、监控、优化和解决故障等各个阶段都帮助Node.js开发者。
对于业界而言,Node.js的疑难杂症分为三类:
内存泄露
CPU飙高
GC停顿
彼时,也并非没有工具可以解决:比如第一类内存泄露的问题,可以通过heapdum模块生成内存堆快照,随后通过Chrome浏览器的开发者工具进行查看和分析;第二类CPU飙高问题,可以通过 v8-profiler生成 CPU profile 文件,再通过开发者工具查看和分析;第三类GC停顿问题则可以通过--gc-trace 的 flag 来输出 GC 日志从而进行问题定位。
但是,这些工具的共同缺陷是:对线上应用非常不友好,无法即插即用,定位问题成本高。一个应用在线下表现正常,上线之后发生问题再进行工具安装就为时已晚,还需要再修改上线后进行bug复现。而且,如果设置成异常时触发生成文件以备分析,就会引发应用大规模运行时堆快照的陡然增多问题。
“我们需要做一点别人做不了的事情”。团队从最初就在探索如何更好地解决Node.js应用的可诊断性问题,如何改变V8虚拟机的黑盒子情况。有两件事情必须解决:
深入了解Node.js运行时的内部状态,思考如何使之对开发和运维人员更透明。
在线上应用出现问题时,如何更好地解决问题,而非事到临头再找工具解决。
相应地,团队决定重点攻克如何提高监控能力和诊断能力。
传统的监控方案只能看到一些系统级别的信息,APM方案也不能提供彻底详尽的问题报告。比如,虽然可以得到系统级CPU过高的信息,但是究竟是因为业务代码的占用还是因为GC的消耗,则不得而知。再比如,纵然APM方案可以知晓哪些API运行缓慢,但是故障原因是CPU还是内存这样的进一步追问,并没有得到回答。
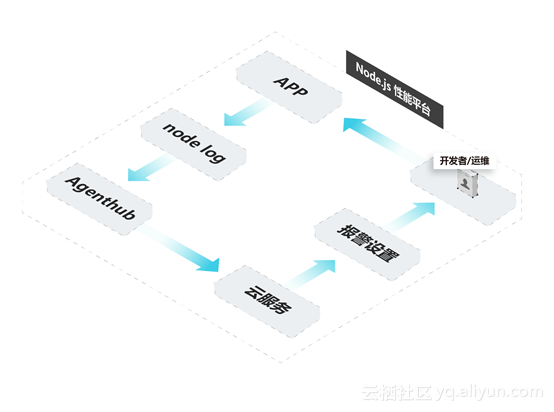
团队深入了解了Node.js内核,包括libuv和V8,并在一些地方进行埋点,通过定时日志的方式将内核的状态输出出来,其中性能指标包括GC(新生代,老生代)、堆内存(整体、分空间)、句柄、定时器等,这些性能数据与监控系统结合,再搭配上报警判断和消息通知,从而得到更深度、更透明的内核级别的性能监控。
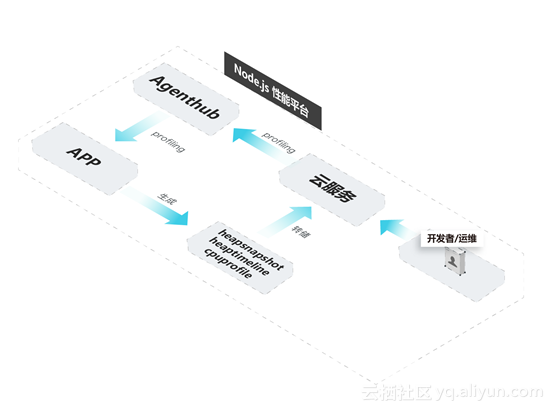
在获得了内核级的监控信息之后,就可以更加有针对性地排查问题。在内核层面,团队提供了通过信号触发内核进行Profiling的机制,并提供了一组脚本简化操作。当收到内存可能泄露的信息时,可以找到对应进程,执行生成heapsnapshot的操作,当CPU飙高时生成cpuprofile、GC有异常时进行GC trace的操作、或者在更复杂的情况下组合操作互相配合。
从具体实现层面而言,虽然Node.js和Chrome都是基于V8,但是它并不能像Chrome一样方便地实时诊断。以GC trace为例,V8可以通过flag方式输出GC日志;但是,flag是相当不友好的形式,除了进程启动时开启,其他情况下都是关闭的:如果默认进程都在启动时开启,会产生大量的无实际价值的GC日志。可是,等发生问题的时候,为了开启flag则只能重启进程。因此,团队改造GC trace功能,其开启动作无需重启进程,并且在一定时间后结束日志的输出。
“就好像生病时,医生会通过仪器采集详细的人体体征数据做出诊断。对于线上运行的Node.js应用,Node.js性能平台的可诊断特性通过‘拍片’带来了更详尽的性能数据。诊断结束后,进程还能继续运行。”朴灵解释道,“Node.js的诊断性非常重要,它能够留取运行时的现场,从而更好地分析问题。尽管通过重启等操作,也能适当地缓解应用问题;但是,没有问题现场,就无法从根本解决问题,而没有解决的问题就如同炸弹一样,会在某时再次出现。”
除了前面提到的监控能力和诊断能力之外,团队还做到了更好的数据可视化呈现、分析问题算法、甚至直接告知问题根源。
团队充分考虑到了平台使用的易用性、稳定性和安全性:首先,自研的Node.js内核完全兼容开源社区的内核;其次,相比于传统APM方案的插桩上报,平台日志服务端完全不影响业务代码的运行,即无侵入——建设一个并不影响内核的监控体系;除了必要部署作为最初准备,在分析问题时,用户只需在界面上简单操作而无需登录服务器。
团队在2014年末完成了产品雏形,在随后的一年中服务了集团内部的业务方,早先命名为Alinode并开始商业化的尝试。彼时,业界尚无任何类似竞品,直到两年后NodeSource发布N|Solid。
Node.js在阿里巴巴内部应用相当成熟,目前已经成为仅次于Java的技术栈:除了1000+线上应用之外,还有Egg.js企业级框架、CNPM仓库解决方案以及周边数不清的业务支持中间件和SDK。而几乎所有的Node.js业务,都由Node.js性能平台提供兜底的稳定性解决方案,日均为上万台服务器提供性能监控和诊断服务。
在谈及产品定位时,朴灵说道:“我们始终注意着与社区Node.js版本保持同步一致,否则等于分裂社区。我们最重要的改进集中在稳定性方面,因为提供了深度监控和可诊断性,问题更容易地暴露和解决。”比如,在内存泄露的情况下,通过深度性能监控和在线profiling,可以将问题定位时间从1周左右降低到2-4个小时。
如今,产品已经更名为Node.js性能平台,并且正式对外提供商业化服务,所有阿里云公共云用户均可免费使用。从内部使用到对外提供服务,Node.js性能平台团队的客户范围变成是内部和外部的Node.js开发者。业界同领域产品目前只有IBM 的 Node.js SDK 和 NodeSource 的 N|Solid。在产品形态上,IBM 的产品附属在其 BlueMix 产品线上, N|Solid 则须通过 license 或私有部署,而Node.js性能平台是SaaS化服务形态。用户使用 Node.js 性能平台,不需要采购依赖的产品,也不需要进行部署,会更灵活。
值得一提的是,产品具有独一无二的堆快照分析功能。这是因为引入了在 Java 领域里非常成熟的 MAT,而不是继续依赖 Chrome 的 devtools 工具。它不仅在算法上更为先进,能够直接得到问题可疑点;并且可以良好地适用一些极端情况的问题排查分析,比如一个 2GB 的堆快照(你很难想象怎么在浏览器里分析堆快照,需要自己通过 devtools 进行分析,在庞大文件的茫茫对象中,找出有问题的那个。这如同大海捞针,是技术活,也是体力活。)。
安全,是更为重要的方面。平台安全功能分为两块,扫描漏洞和数据安全。平台并不会扫描用户的代码和环境,而只会检查用户所用的 Node 版本和模块包的版本(通过配置 packages),如果版本存在安全问题则发出提醒。对于用户的数据安全,Node.js 性能平台采集 Node.js 内核运行时状态、各个空间的内存使用情况等信息,而没有涉及到业务层面。用户的日志只有用户的阿里云账号可见,需要协助时必须要授权。
Case1: 应用的稳定性,更高效更安全的runtime
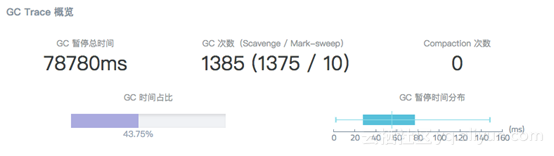
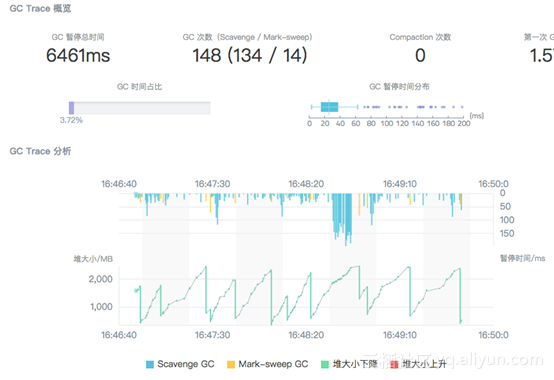
这里有一个实际客户的案例。它的 GC 占比时间达到极其夸张的 43%,这意味着3分钟的采样时间里,有 43% 的时间,应用程序都在做 GC 操作。
平均每次的停顿时间在 30ms ~ 80ms 之间。再看详细的情况,可以看到新生代 GC(Scavenge GC)极其频繁:
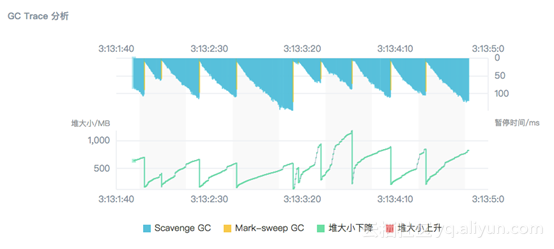
再对比老生代 GC(Mark-sweep GC),我们发现这样的现象,老生代 GC 的次数相当少,但是每次回收的内存都非常大,而新生代 GC 尽管频繁,但停顿时间与老生代 GC 几乎相同,并且,每次只能回收少许的内存。也就是说新生代 GC 的表现比老生代 GC 更差。
当然这个原因主要是由于系统中存在大对象导致的:
从 heapsnapshot 上也能验证这个问题:
为了解决客户所遇到的这个问题,我们的思路是既然新生代 GC 不够好,那我们希望能够减少不必要的新生代 GC,也就是减少新生代 GC 的次数。在相同的内存分配频率下,新生代 GC 的频率跟新生代空间的大小有一定关系,因此,只要增加新生代空间,就可以减少新生代次数。
我们让客户在启动进程的地方加上 --max_semi_space_size=64 ,后来监控情况下,极端 GC 停顿最多只达到 20%,正常情况下,均低于5%。
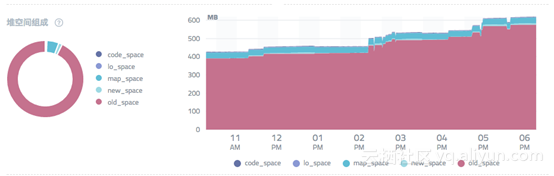
再看改造之后的表现图:
我们将新生代/老生代的占比从 1375 / 10 降低到 134 / 14,GC 停顿降低到 3%,满足正常的预期。
Case2: 解决令人头疼的内存泄露问题
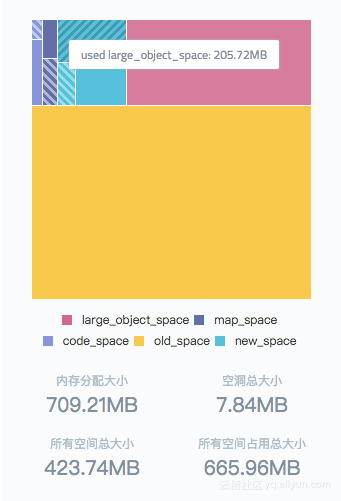
内存泄漏是指没有被正确回收的内存,当一个系统中没有被正确回收的内存逐渐增多时,系统的有效内存(能正常申请和回收)就会越来越少。对外的表现则是进程的内存占用会越来越多:
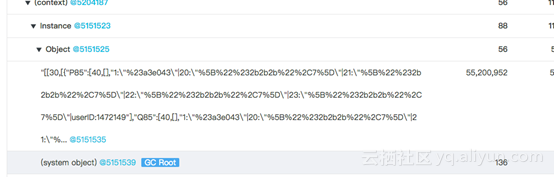
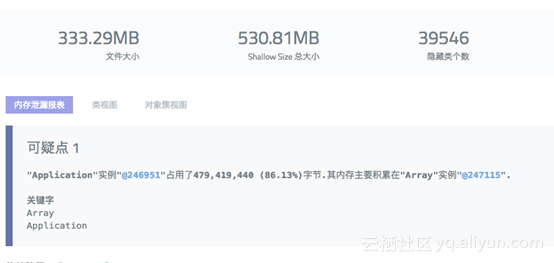
通过 Node.js 性能平台的堆快照生成功能,及分析,可以直接得到分析报告:
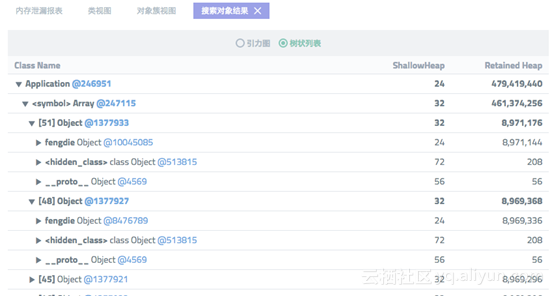
展开对象,可以看到更多细节:
最终,通过堆快照分析给出的一些关键字:Application、fengdie、symbol。可以从业务代码中迅速定位到问题。
Case3: 高效使用CPU,以便扩容
在一次帮助外部客户压测是发现了较高的CPU占用,通过平台生成含有有效信息的CPU profile文件。通过查看堆栈,看到 Writable.onwrite->clearBuffer 调用链路上占了 25% 的 CPU 资源,这个调用链路下,是 log4js 的操作。结合到当时生成的 heapsnapshot 文件,可以判定是写入日志的负载较重,发现客户记录了所有的生产日志。经过梳理,去掉不必要的日志,最终相应的 CPU 占用降低到了 6-7% 左右。
在上述过程中,Node.js性能平台配合使用了PTS进行压测。PTS 的压测可以看到在预计高流量时系统性能是否符合预期,是否存在问题;随后再通过 Node.js 性能平台,解决压测过程中遇到的瓶颈问题。
业务开发同学一般更关注的是如何实现业务逻辑,对底层技术则涉猎不多,如果要解决一些瓶颈问题或奇怪的疑难问题,则相当费时费力。Node.js 性能平台可以弥补企业级应用层面的薄弱环节,能够节省解决问题的时间和精力,让企业专注在自己的业务开发中。
除了前文提到的问题,还有一些问题算是业界比较难以解决的,比如死循环、堆外内存泄漏以及剖尸诊断(对死掉的进程进行原因分析)等等。这些都是团队正在攻克的难题,并会在不久的将来把对应的解决方案以产品功能的形式提供出来。团队会继续在增强内核能力上投入资源,并会持续在使用体验上做出改进。
如今,Node.js 性能平台免费供所有阿里云用户使用。这意味着阿里云上的所有 Node.js 用户可以受益于阿里内部在过去几年所沉淀下来的在 Node.js 领域的稳定性经验,远离那些令人饱受折磨的各种疑难杂症,从而更加专注于自有业务开发。
未来,Node.js 性能平台会往更智能化的方向前进。理想效果是,接入 Node.js 性能平台后,能自动帮助用户分析线上的潜在问题,提前提醒用户进行 Profiling,Profiling 之后,能根据性能文件自动定位出哪一行代码出了问题。并且,专有云和国际化也是产品未来发展方向之一。在服务层面上,团队期望为更多的用户提供更好的服务。目前产品上提供的工具、功能和服务,在公共云上均是免费的,团队未来也会推出专有云和专家咨询服务,不过相比维护SaaS化站点此类服务需要更多的人力成本。
“让天下没有难解决的 Node.js 问题。” 这,是Node.js性能平台团队的唯一目标。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号