图数据库全解析:一篇文章带你深入了解
发表时间: 2022-11-22 13:42
键值数据库:所有数据都由唯一标识符(键)和关联的数据对象(值)表示。例子包括Berkeley DB、RocksDB、Redis和Memcached。
列存储数据库(又名面向列、宽列式数据库):数据按列来存储,可能每行有大量的列,也可能每行的列数不一样。例子包括Apache HBase、Azure Table Storage、Apache Cassandra和Google Cloud Bigtable。
文档数据库(又名面向文档数据库):将数据存储到带有唯一键的文档中,该文档可以具有不同的模式,也可以包含嵌套数据。例子包括MongoDB和Apache CouchDB。
关系数据库:将数据存储在包含具有严格模式行结构的表中,允许在表之间连接行来建立关系。例子包括PostgreSQL、Oracle Database和Microsoft SQL Server。
图数据库:将数据存储为顶点(节点、组件)和边(关系)。例子包括Neo4j、Apache TinkerPop的Gremlin Server、JanusGraph和TigerGraph。
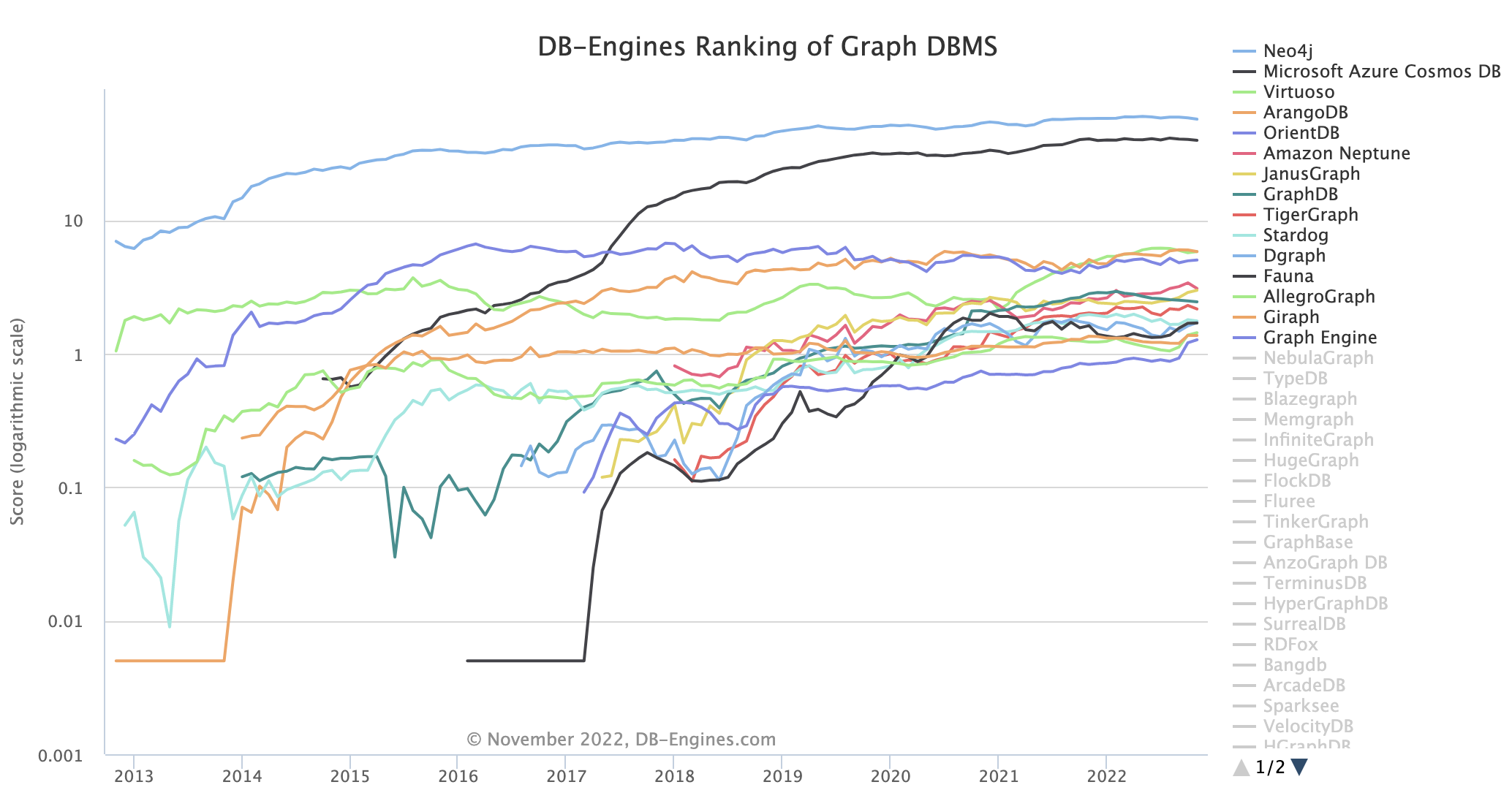
日常生活中经常提到图的概念。与大家平时口语中提及的“图”(Image)不同,数据库中的图(Graph)更多指的是“拓扑图”、“网络图”等——它是基于事物关联关系的模型表达,通过将实体与关系点边化的方式将知识结构化地保存,因此具有天然的可解释性,下图是DB-Engine对图数据库的一个排名。
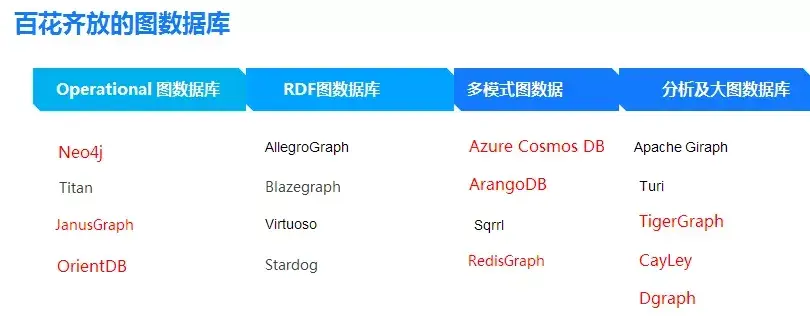
图数据库的一个分类:
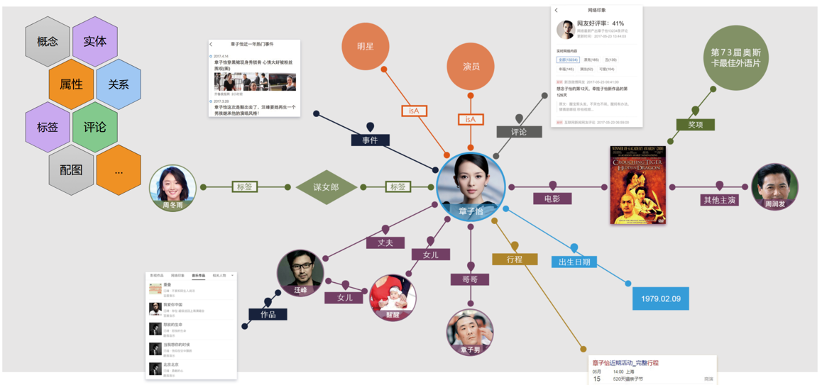
真实世界的图:
抽象图:图是由顶点和顶点之间的边组成,通常表示为G(V,E),其中G表示一个图,V表示G中顶点的集合,E表示边的集合
G = (Vertex (Node, Entity, Object),Edge (Relationship, Link, Arc))
顶点:(也叫实体,或者节点、对象)是对现实世界中的对象的一种抽象,比如一个人,一款软件,一部电影等
边:(也叫关系或者连接)是顶点所代表的对象间的关联关系,比如人与人之间可以有朋友关系或者亲属关系等
属性:顶点和边都可以有属性,用来描述顶点或者边,例如人这种顶点可以有姓名、年龄等属性,朋友这种关系可以有“认识时间”等属性
传统的关系型数据库和图数据库无论是在模型,存储以及查询优化上都存在极大的差异。比如社交用户关系中的2度查询请求,传统关系型数据库处理起来至少是秒级别的,3度查询更差甚至无法支持。
对比而言,图数据库能够轻松支持这类场景,性能往往能够轻松的达到传统关系型数据库的十倍乃至几十倍。这种性能的差异并非简单的调优问题,而是更深层次的数据库建模以及内核层面决定的。因此,图数据库在基因层面更适合高度连接数据集的处理。
图数据库与关系型数据库对比
分类 | 图数据库 | 关系型数据库 |
数据模型 | 图 | 表 |
存储对象 | 半结构化数据 | 结构化数据 |
2-3 度关联查询 | 高效 | 低效 |
6-10 度关联查询 | 高效 | 低效/不支持 |
事务性 | 支持 | 支持 |
1. 企业查询:可以查询企业,企业法人之间的关联关系,比如查找背后的实际控制人,使用图数据库可以很好的存储并表征此类关系,方便实现和找到离散的公司之前的关联关系,发现潜在价值,让更多的信息呈现出来。
2. 金融洗钱:以寻找多个账户之间相互转账,形成环路洗钱为例,要能支持实时快速检测出海量数据中存在的环,图数据库能相比其他数据库能很好的支撑这样的关联查询,保证海量数据低时延。
3. 社交关系推荐:寻找 A 和 B 之间最少可以通过 2 个人可认识,如果满足这样的要求,就将 A 推荐给 B,这个在图数据库中能很容易的通过现有的语句和最短路径算法实现,大大降低了业务实现难度,使得此类业务开发更便捷容易。
目前世界一百强企业使用图数据库的比例。金融行业用图数据库的特别多,因为金融反欺诈、金融风控可以用图来降低损失。第二个行业是软件,像Oracle、SQL Server里面都会带有一些图数据库的功能。另外像零售,物流,电信行业也会用图数据库解决一些成本问题或是物流的最短路径问题。还有一些医疗行业,比如一个患者可能有很多疾病,可能有些药之间会有相互作用,还有吃的饮食和药也会冲突,这些用图数据库都能比较好地去分析处理。
应用场景总结:

首先它提供了一个更好的交叉性能,原来可能大家发现在几百万、几千万的join操作还能勉强跑下来,随着现在万物互联,可能随便一个手环、智能手表都有上亿人的设备,你要跑一些join操作基本跑不出来了,图数据库其实可以很好解决这样的问题。
第二,图数据库也可以找到更多的关系,包括物与物、物与人、人与人之间的关系,这也是传统数据库无法提取的问题。还有一些结构的灵活性,比较好添加这种Schema。
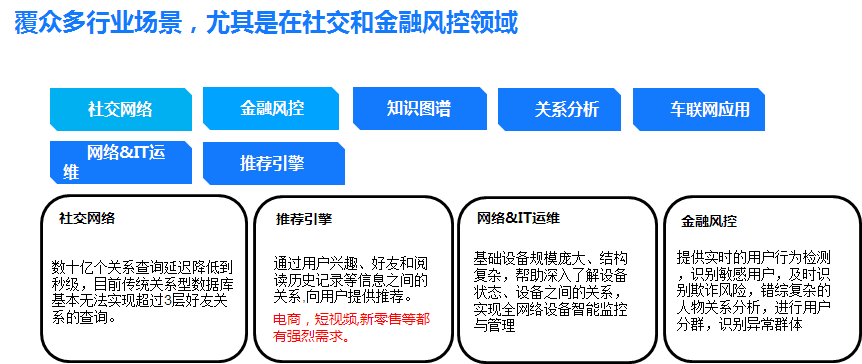
在图数据库用比较多的先是社交跟金融领域,社交领域用在什么地方?比如好友推荐,看过了这本书或者看过了这个电影,然后其他也看过这个书和电影的人都会看哪些书比较多,可以把对应的书和电影推荐出来。
同时一些网络的运维IT服务可能有设备上万台,车联网之后可能汽车也会上千万辆,汽车与汽车之间,人与汽车之间的关联也会越来越多,还有金融风控,及时找到欺诈、诈骗等相关的异常。

金融风控在传统数据库无法很好解决的问题,比如员工和亲属、员工与客户、客户之间的关系,还有业务合规的关系,这些都是非常复杂的关系。
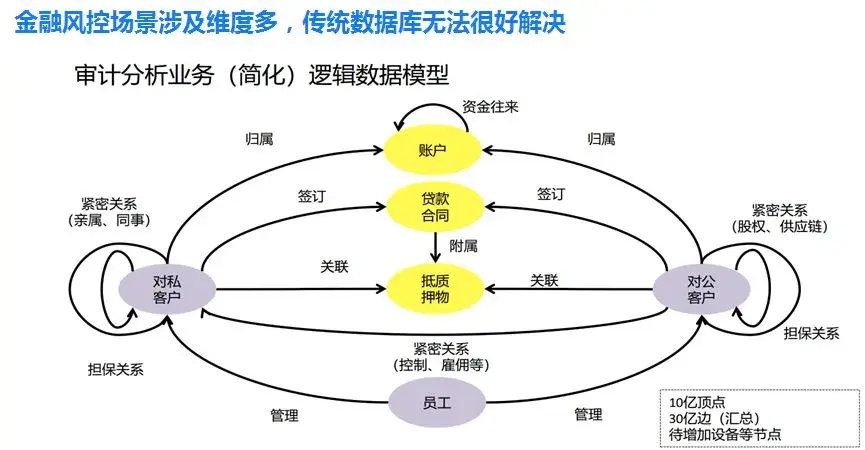
可能用这个图看得比较明显,通过这个图我知道这个客户对公、对私、对员工及相关的管理,纬度特别多,很多统计数据出来。如果用传统的数据库找里面的规律很难找,图数据库可以很简洁明了地知道都集中在哪几个类似客户上或者有员工频繁会跟他的亲属进行转账关系或者有一些深度资金往来,这样可以显示出非常大的价值。
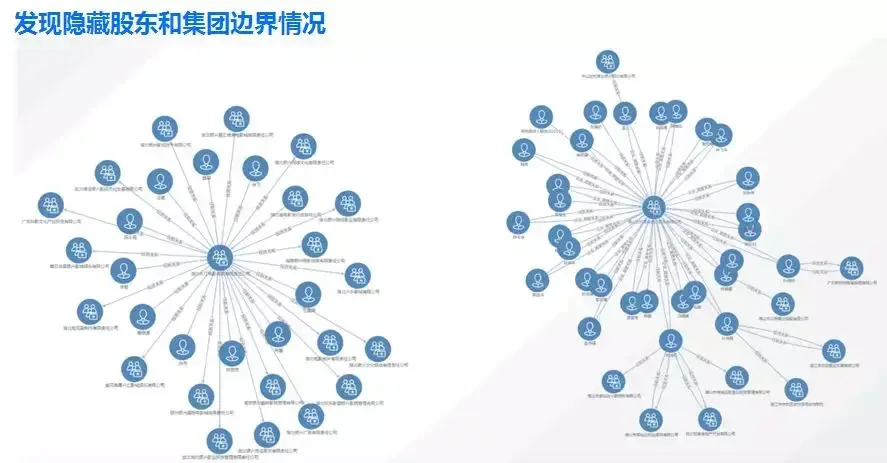
这是另外一个基于隐藏的例子,有些人幕后黑手控制了很多公司或者控制了很多集团,你通过图数据库可以看到具体是某一个人或者某一个真正的公司在控制、操纵相关公司的行为。
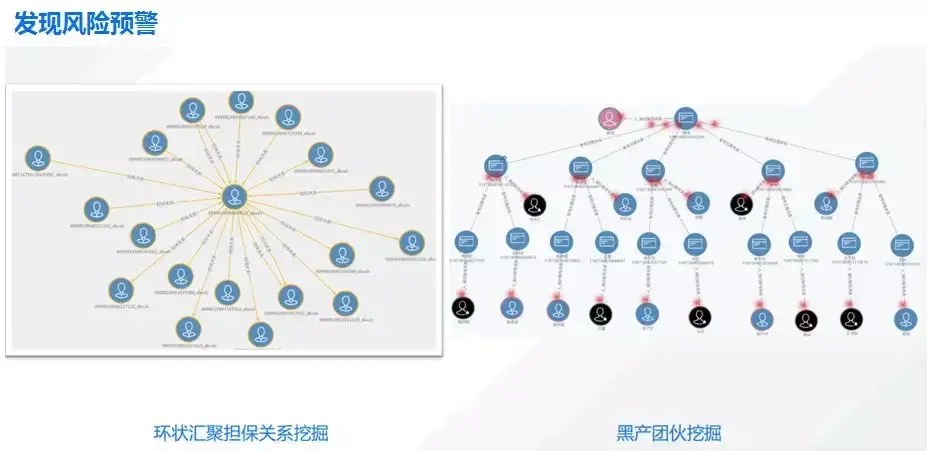
这是一些黑产的例子,像一些挖掘的效果及担保关系挖掘效果,可以快速知道这个人有没有问题,或者这个黑产有没有一些集中的特征。
图数据库的技术架构如下图所示,整体上采用分层架构的模式,从上往下依次是:接口层、计算层、存储层。

图数据库的使用场景主要是实时查询,用户通过图查询语言在图上做遍历、过滤和统计等操作,一般为局部查询,以满足实时的需求。
图数据库为实时查询提供了两类常用的图算法:
此外,用户常常会提出比实时查询更为复杂的分析需求以挖掘图数据中的潜在价值。在图算法的实现上,最理想化的选择是在图数据库上直接实现图算法,但由于图数据库更侧重于高并发和海量存储,全图算法更侧重于迭代计算,因此目前更为常见的选择是提供另外图处理引擎与图数据库集成:从图数据库对接或导入数据到图处理引擎中进行离线分析,结合其更为强大的计算能力对全图进行迭代计算,寻找某种特定模式(社区发现或欺诈模式)或者路径,满足数据挖掘的应用需求。
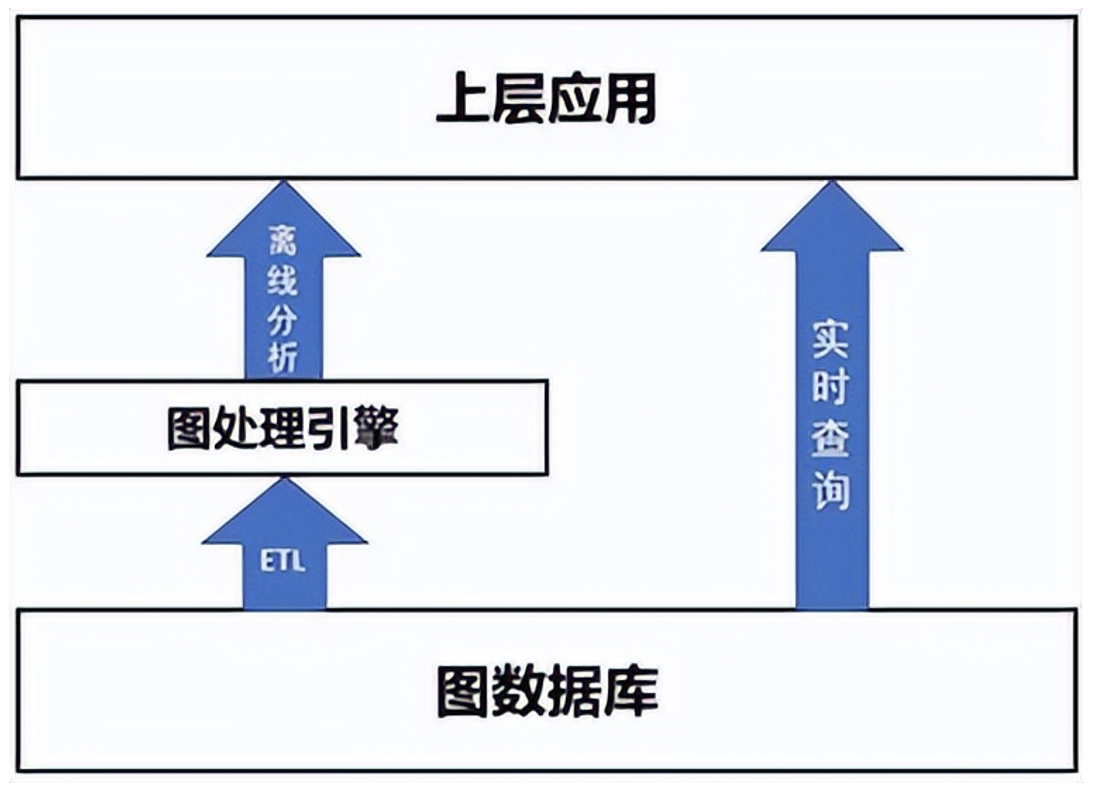
图数据库实时查询与离线分析
离线分析需要较长的时间来完成,分析的算法也相对复杂,可根据解决问题的目的不同分为以下几类:
① 中心性(Centrality):是社交网络分析(Social network analysis,SNA)中常用的一个概念,用以表达社交网络中一个点或者一个人在整个网络中所在中心的程度。通过知道一个顶点的中心性,可以用来了解和判断该顶点在网络中所占据的重要性。中心性常见算法包括:佩奇排名(PageRank)、中介中心性(Betweenness Centrality)、紧密度中心性(Closeness Centrality)和调和中心性(Harmonic Centrality)。
② 社群发现(Community detection):用以划分复杂网络的社群结构。在复杂网络的研究中,如果网络的顶点可以容易地分组成顶点集,使得每组顶点在内部密集连接,则称网络具有社群结构。这意味着社群内的点的连接更为紧密,社群间的连接较为稀疏。社群发现常见算法包括:Louvain 算法和标签传播算法(Label Propagation)。
③ 图挖掘(Graph Mining):是基于图的数据挖掘,用来发现数据的模式。通过分析图数据,发现有趣、意外、有用的模式是非常必要的,可以用来帮助理解数据或做出决策。在社交网络、医药化学、交通运输网络等诸多领域中有着重要意义。常用的图挖掘算法包括频繁子图(Frequent Subgraph)和数三角形(Triangle Counting)。
随着人工智能技术的发展,机器学习、深度学习、神经网络等算法也可通过图处理引擎分析图数据库中的数据价值。
图处理引擎又称图计算框架,主要用来做复杂图分析,是一种能够针对大型数据集运行图计算算法的技术。
由于强调全局查询,图处理引擎通常针对批量扫描和处理大量信息进行了优化,在这方面,它们类似于其它批处理分析技术,如数据挖掘和联机分析处理(On-Line Analytical Processing,OLAP)。虽然一些图处理引擎包括了图的存储层,但绝大多数的图分析引擎严格地关注从外部数据源馈入的数据,进行处理,然后将结果返回到其它地方存储。
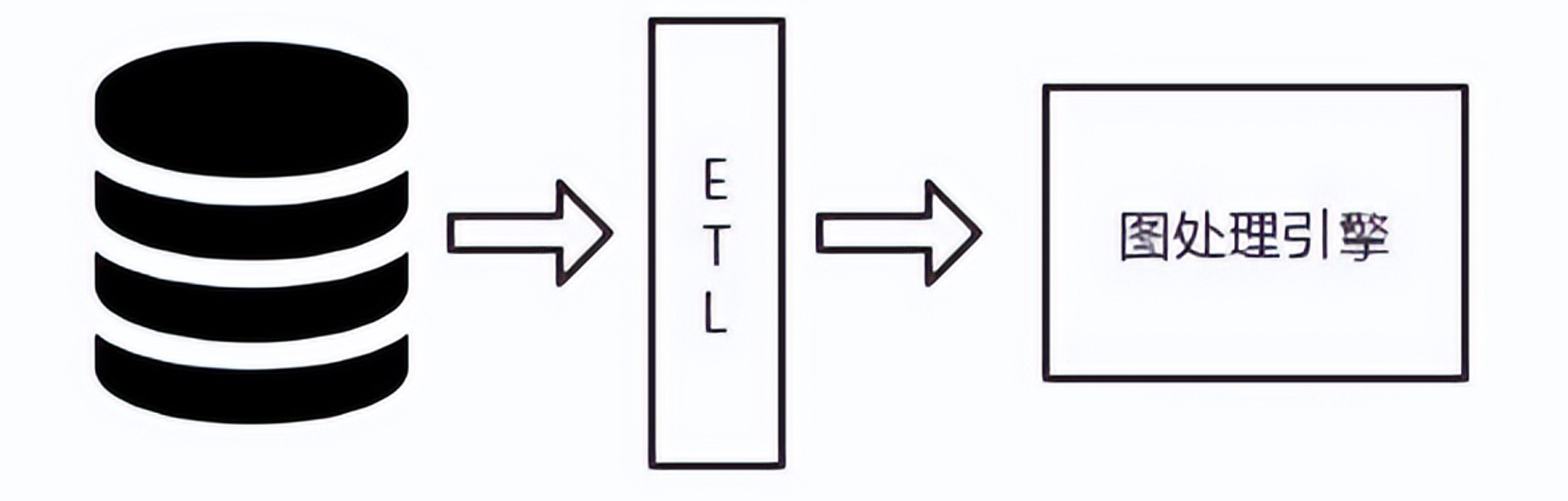
图处理引擎处理过程
图处理引擎可以独立于图数据库,可以使用任何系统作为数据来源。若已经在业务中使用了图数据库,往往也希望对图数据进行一些深层的处理和挖掘。一些图数据库产品同时也会提供图处理引擎的集成(如 JanusGraph 可集成 Spark 和 Hadoop)。当前主流的图处理引擎有以下几款:三类图处理引擎
产品名 | 提出者 | 介绍 |
GraphX | Databrick 公司,属于 Spark 计算引擎之上的图计算框架 | GraphX |
GraphLab | CMU Select 实验室 | GraphLab |
Giraph | 由雅虎开发,捐赠给Apache 基金会 | 基于 Hadoop 生态,目的是为了解决大规模图的分布式计算问题 |
数据库查询语言可以分为命令式(imperative)和声明式(declarative)。
命令式查询语言是一种描述计算机所需作出的行为的编程范型,系统需要顺序依次执行用户的指令,要求用户具备一定的编程能力,但执行效率高。声明式查询语言允许用户表达要检索哪些数据,仅需在逻辑上表述清楚查询结果需要满足的条件,剩下的由数据库优化执行,对用户负担较小。例如 SQL 是典型的声明式语言,C++和 Java 是命令式语言。
与关系型数据库不同,图数据库领域目前没有统一的查询语言标准,大多数查询语言与产品紧密关联。声明式查询语言通常作为常规查询语言,提高图数据的易用性;而命令式查询语言用在对图数据性能有较高要求的场景,同时复杂图分析场景也多使用命令式语言。目前国内一些图数据库产品使用的是自研的声明式查询语言。而常见的声明式图数据库查询语言包括 Cypher,Gremlin 和 SPARQL。
图数据库查询语言
查询语言 | 提出者 | 介绍 |
Cypher | Neo4J 提出 | 采 用 类 SQL 语 |
Gremlin | Apache TinkerPop开源项目的一部分 | 采用类 Scala 语法 |
SPARQL | W3C 标准 | SPARQL 是一种用于资源描述框架 (RDF) 的查询语言 |
小结
1. 图数据库的基础是离散数学的图论部分,后者已经有数百年历史了。这意味着数学家们花费了几个世纪的时间来创建术语,但并非所有术语都有用,也并非所有术语都与使用图数据库构建软件有关。
2. 图由顶点(也称为节点或实体)和边(也称为关系、链接或连接)组成。边在顶点相交。
3. 数据库的五种常见类型是键值数据库、列存储数据库、文档数据库、关系数据库和图数据库。在这五种数据库中,只有关系数据库和图数据库能够对任意复杂程度的关系进行建模。
4. 图数据库将关系设计成“一等公民”,这使构建依赖于这些关系的软件变得更加容易。当要解答严重依赖于数据之间关系的疑问时,图数据库往往比其他类型的数据库表现得更好。
5. 对于需要诸如递归查询、返回不同结果类型或返回事物之间路径等特性的用例,使用图数据库更容易编码,并且性能更好。
6. 由于图数据库的强大功能和灵活性,互联网上有很多图用例可参考,其中有好有坏。判断一个用例是好还是坏的最重要因素是对要解答的疑问有深入的了解。
展望
大数据时代业务的增长带来了数据量的剧增和数据关联的复杂化,与此同时用户对数据价值的期望也越来越高,这些都带来了数据库系统的不断创新变革。图数据库提供了对关联数据最直接的表达,图模型对异构数据天然的包容力带来了在深度关联查询上比其它数据库更为卓越的性能表现。
目前,图数据库领域正处于飞速发展的状态,随着概念的普及、需求的变化,图数据库正在向如下方向发展:
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号