使用Python在笔记本上处理100GB数据的方法
发表时间: 2020-02-15 17:07
许多组织都想尽可能多地收集和利用数据,从而改进业务、增加收入和提升影响力。因此,数据科学家们要面对 50GB,甚至 500GB 数据集的场景变得越来越普遍。
目前,这些数据集处理起来有点麻烦。就大小而言,它们可以放进你笔记本电脑的硬盘里,但却无法装入内存。所以,仅仅打开和查看它们就很困难,更何况进一步探索和分析。
处理这样的数据集时,一般有 3 种策略。
第 1 种是对数据进行子抽样,但它有一个明显缺点:可能因忽略部分数据而错失关键信息,甚至误解数据表达的含义。
第 2 种是使用分布式计算。虽然在某些情况下这是一种有效的方法,但是管理和维护集群会带来巨大开销。想象一下,要为一个刚超出内存大小、大概 30-50GB 的数据集就建立一套集群,对我来说,这似乎有点“用力过猛”。
第 3 种是租用一个内存大小等同于数据集大小的强大云服务实例,例如,AWS 提供了 TB 级内存的云服务实例。但这种情况还需要管理云数据存储空间,并且在每次实例启动时都要等待数据从存储空间传输到实例。另外还需要应对数据上云的合规性问题,以及忍受在远程机器上工作带来的不便。更别提成本,虽然开始会比较低,但随着时间推移会快速上涨。
本文向你展示一种全新方法,它更快、更安全,可以更方便、全面地对几乎任意大小的数据集进行数据科学研究,只要这个数据集能装进你的笔记本电脑、台式机或者服务器的硬盘里就行。
Vaex 是一个开源的 DataFrame 库,对于和你硬盘空间一样大小的表格数据集,它可以有效进行可视化、探索、分析乃至实践机器学习。
为实现这些功能,Vaex 采用内存映射、高效的核外算法和延迟计算等概念。所有这些都封装为类 Pandas 的 API,因此,任何人都能快速上手。
为阐述这些概念,我们对一个远超出一般笔记本电脑内存大小的数据集进行简单地探索分析。
这里,我们使用 New York City(NYC) Taxi 数据集,它包含了标志性的黄色出租车 2009 年到 2015 年间超过十亿次的出租车行程信息。
数据从网站下载,提供 CSV 格式。完整分析可以单独查看这个 Jupyter notebook 。
第一步是将数据转换为内存映射文件格式,如 Apache Arrow 、 Apache Parquet 或 HDF5 。关于如何把 CSV 数据转为 HDF5 的例子请看这里。一旦数据存为内存映射格式,即便它的磁盘大小超过 100GB,用 Vaex 也可以在瞬间打开它(0.052 秒):

Vaex 瞬间打开内存映射文件(0.052 秒)
为什么这么快?在用 Vaex 打开内存映射文件时,实际上并没有读取数据。Vaex 只读取了文件元数据,比如数据在磁盘上的位置、数据结构(行数、列数、列名和类型)、文件描述等等。那如果想查看或者操作数据呢?
将数据结果展示在一个标准的 DataFrame 中进行预览,速度一样非常快。
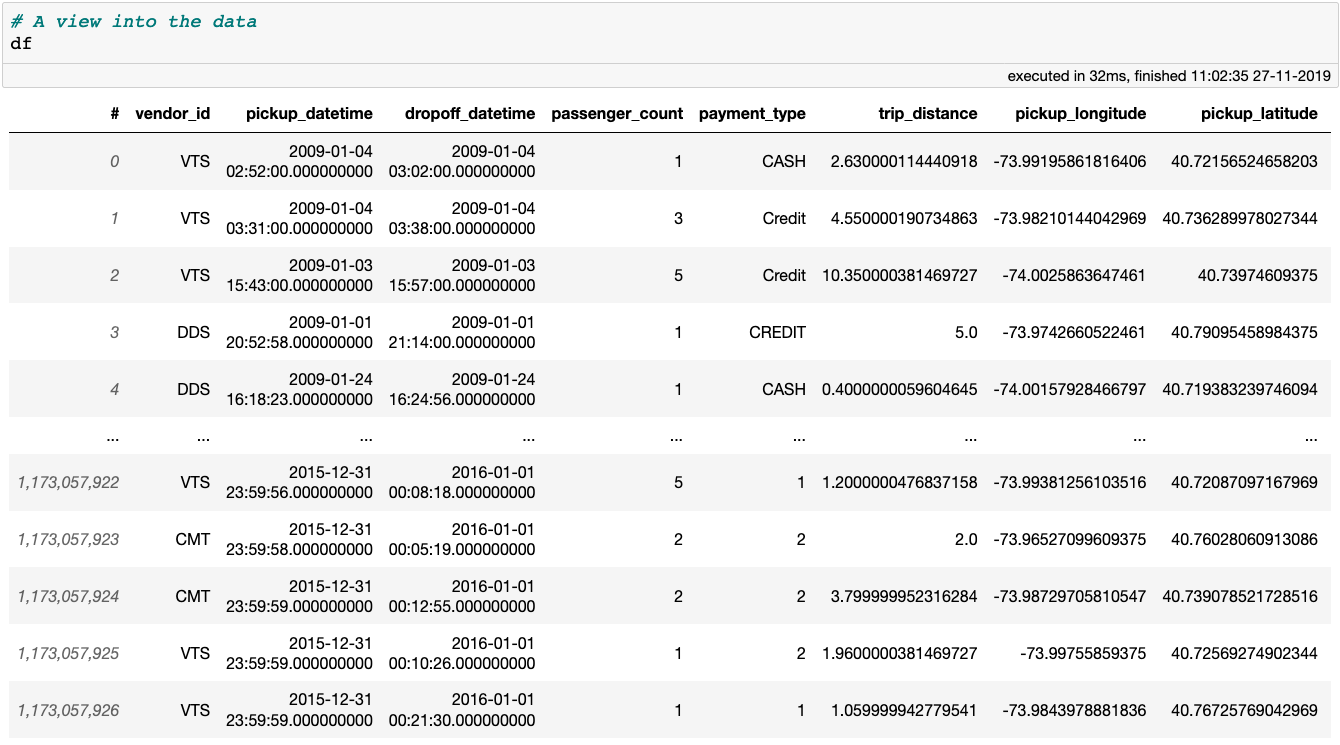
预览 New York City Yellow Taxi 数据
代码单元执行时间还是非常短。这是因为展示 Vaex DataFrame 或者某列,只需要从硬盘中读取前 5 行和后 5 行数据。这里引出另一个要点:Vaex 只会在必要的时候遍历整个数据集,而且它会尽可能遍历更少的数据。
不管怎样,我们先从异常值和错误的输入值开始清理这个数据集。一种好的方式是用describe方法获取数据的高级概览,它可以展示样本数量、缺失值的数量和每列的数据类型。
如果某列的数据类型是数值,它还将展示其平均值、标准差、最小值及最大值。而所有的这些数据都是通过一次数据遍历计算的。
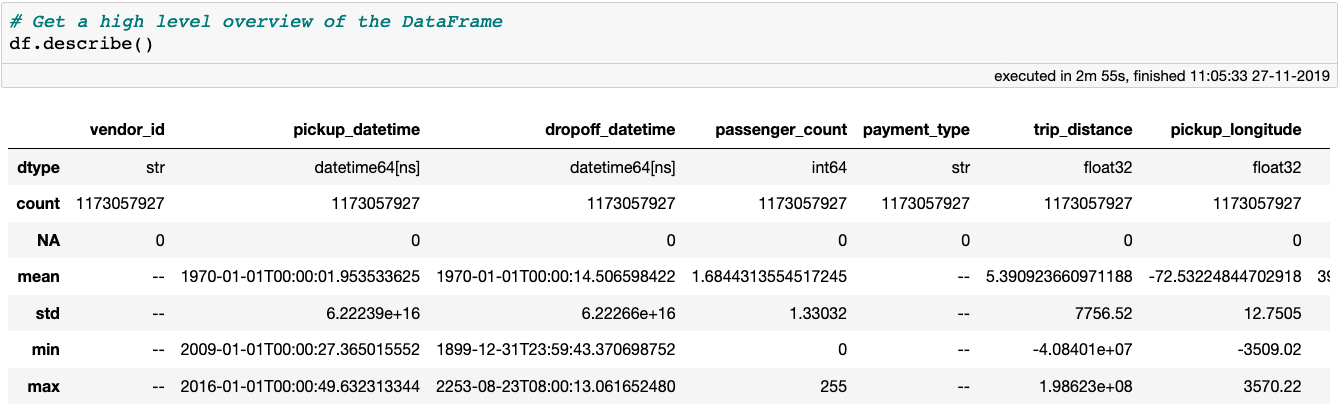
使用describe方法获得 DataFrame 的高级概览,注意这个 DataFrame 包含 18 列数据,不过截图只展示了前 7 列。
describe方法很好地体现了 Vaex 的能力和效率:所有这些数据都是在我的 MacBook Pro(15 英寸、2018 款、2.6GHz Intel Core i7 和 32G 内存)上在 3 分钟内计算出来的。其他库或方法则需要分布式计算或超过 100GB 的云服务实例才能完成相同的计算,而有了 Vaex 你需要的只是数据以及拥有几 GB 内存的笔记本电脑。
查看describe的输出很容易发现这个数据包含了一些明显的异常值。
首先从检查上车点开始,去除异常值最简单的方法就是绘制出上车点和下车点位置,并且直观地确定纽约哪些地区是要分析关注的。由于要处理的数据集如此庞大,直方图是最有效的可视化方法。用 Vaex 创建和展示直方图及热力图相当快,而且图表还是可交互的!
df.plot_widget(df.pickup_longitude, df.pickup_latitude, shape=512, limits='minmax', f='log1p', colormap='plasma')一旦通过交互确定纽约哪些区域是要关注的区域后,我们就可以创建一个筛选后的 DataFrame:

上述代码很酷的一点是,它只需很少内存就可以执行!在筛选 Vaex DataFrame 时并不会复制数据。而是只创建对原始对象的引用,并在其上应用二进制掩码。用掩码来选择哪些行将被显示以及将来用于计算。这为我们节省了 100GB 的内存,而像现在许多标准数据科学工具则必须得复制数据才行。
现在,来看下passenger_count这一列。单次出租车行程乘坐人数的最大值是 255,这似乎有点夸张。我们来数数每次行程的乘客人数,这里用value_counts方法很容易实现:
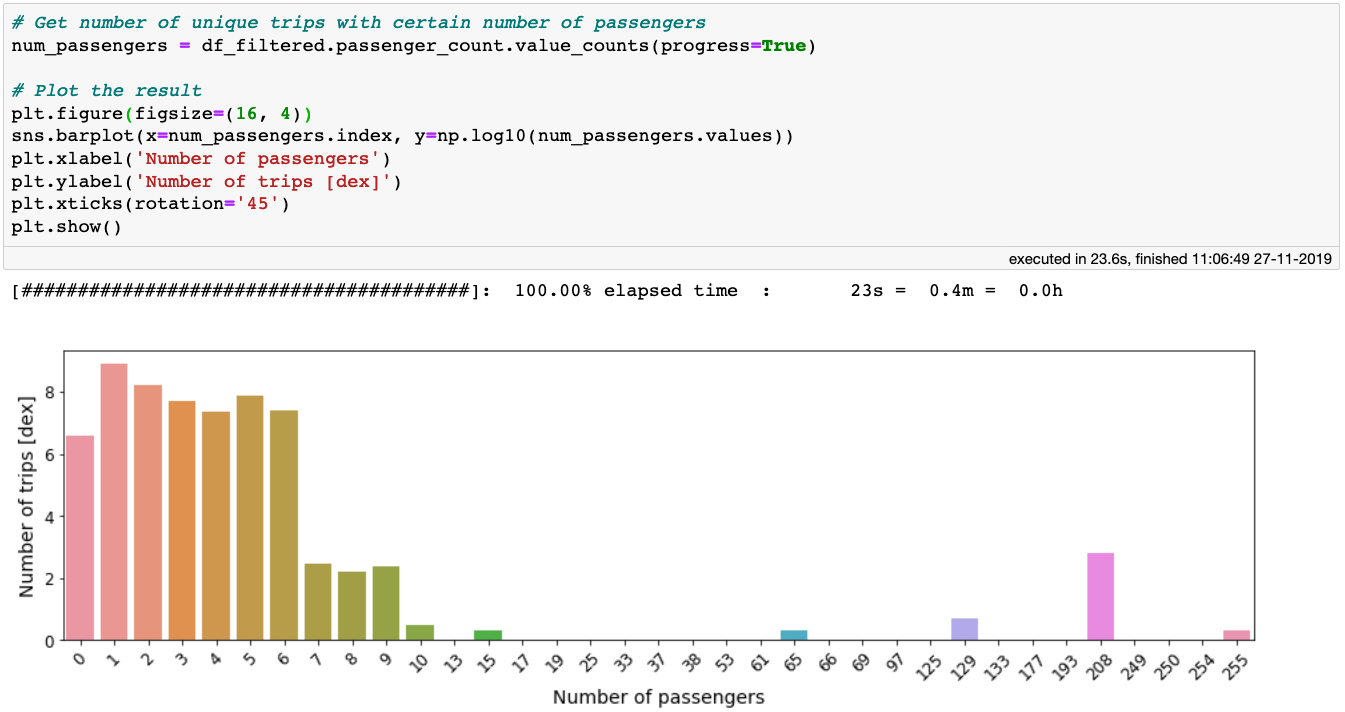
在 10 亿行数据上使用 value_counts 方法只需要 20 秒!
从上图可以看出,乘客超出 6 人可能是少见的异常值或者是错误的数据输入。同时还有大量乘客数为 0 的行程。既然不知道这些行程是否合理,就先把它们过滤掉。

再用行程距离做一个类似的练习。由于它是一个连续的变量,我们可以绘制出行程距离的分布情况。行程距离的最小值是负值,而最大值比火星都远,所以还是限制在一个合理的区间内绘制直方图。
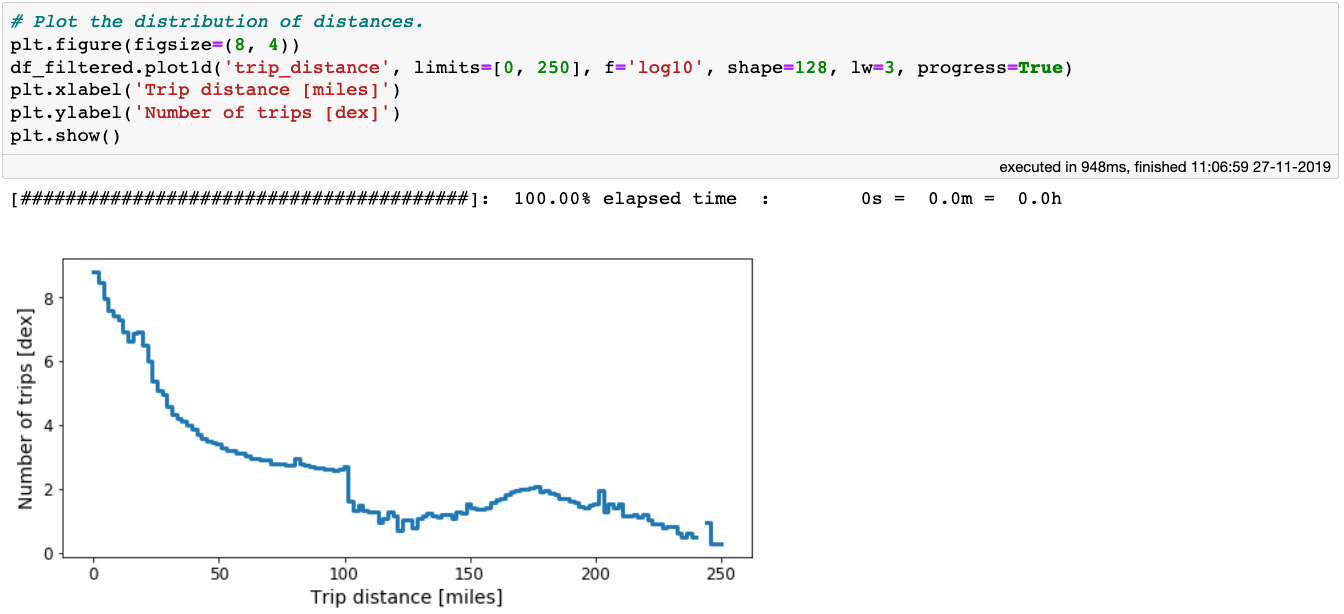
纽约出租车数据行程距离直方图
从上图中可以看到,行程数量随着距离的增加而减少。在距离大约为 100 英里处,分布有明显下降。现在,我们用这个作为分界点来消除行程距离的异常值。

在行程距离这一列中存在异常值,也因此有了动机查看行程耗费时间和平均速度。数据集中并没有提供这两个特征数据,但是很容易计算得出:

上面的代码块不需要内存也不消耗执行时间!是因为代码只会创建虚拟列(virtual columns),这些虚拟列只包含数学表达式,仅在需要时才进行计算。除此之外,虚拟列和其他常规列是一样的。注意,其他的标准库可能需要数十 GB 的内存才能实现相同操作。
好了,我们来绘制行程耗费时间的分布:
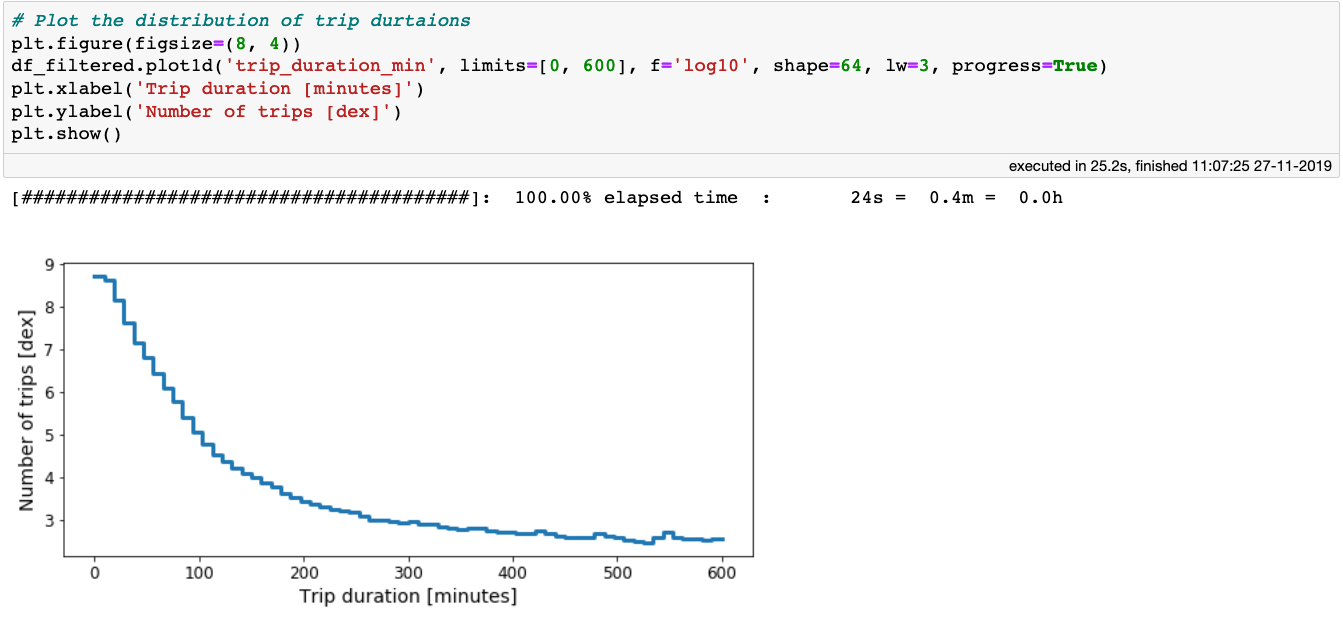
纽约超过 10 亿次出租车行程耗费时间的直方图
从上图可以看到,95% 的出租车行程不到 30 分钟就可以到达目的地,但有些行程可能花费超过 4-5 个小时。你能想象在纽约市被困在出租车里 3 个多小时的情景么?不管怎样,我们豁达点只考虑少于 3 小时的行程:

对于出租车的平均速度,也选择一个合理的范围来查看:

出租车平均速度分布
根据分布趋平的位置,可以推断出租车合理的平均速度在每小时 1 到 60 英里之间,由此可以更新筛选后的 DataFrame:

把关注点切换到出租车行程的费用上,从describe方法的输出可以看到 fare_amount、total_amount 和 tip_amount 列都有一些夸张的异常值。首先,这几列都不应该出现负值。
另一方面,有些数字表示一些幸运的司机只开一次出租车就快要成为百万富翁了。让我们在合理的范围内查看这些数量的分布:
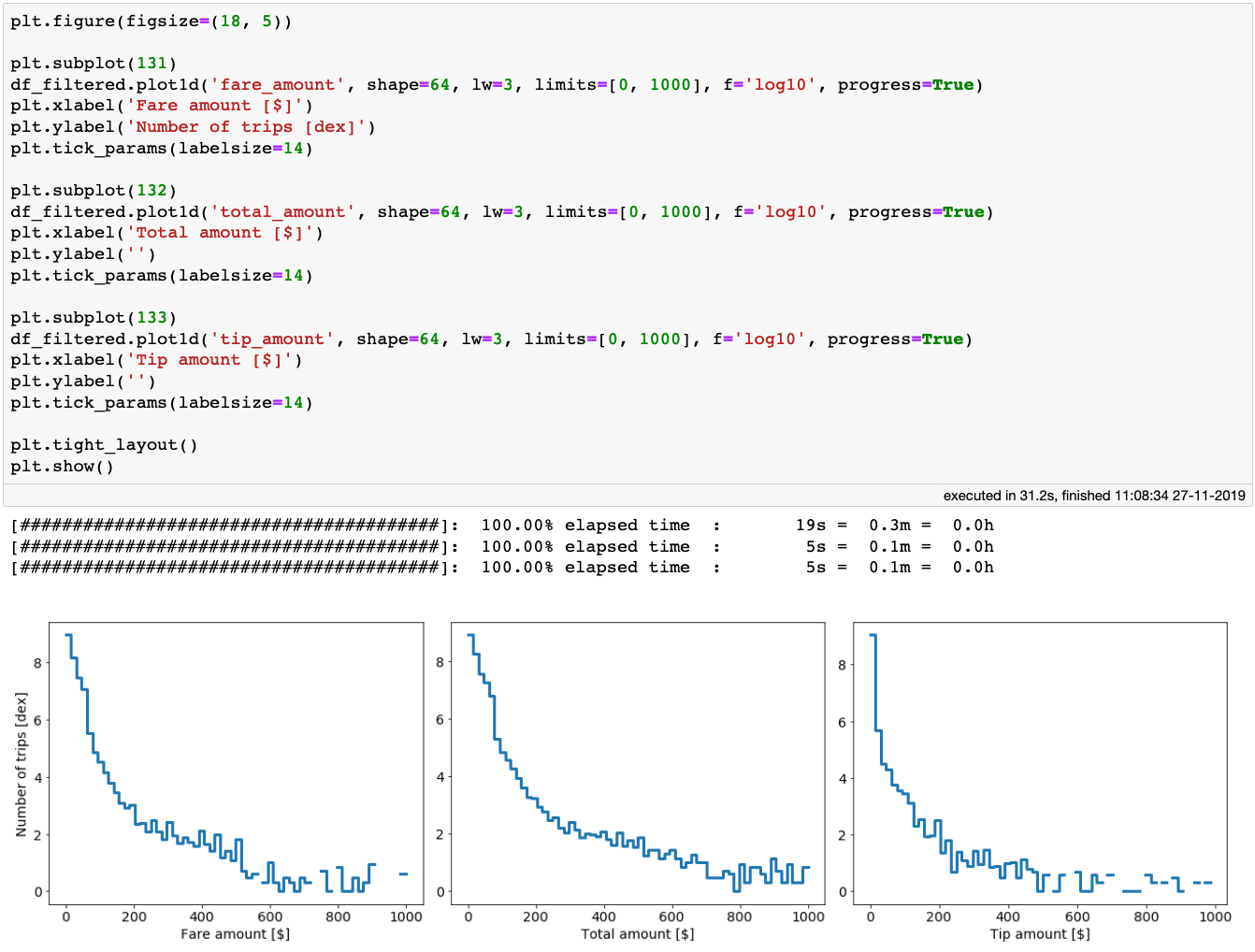
纽约超过 10 亿次出租车行程的车费、总额和小费的分布。在笔记本上绘制这些图表只用了 31 秒!
以上三个分布都有相当长的尾部。尾部可能有一些正确的值,而其他可能都是错误的输入。不管怎样,我们保守一点只考虑 fare_amount、total_amount 和 tip_amount 低于 200 美元的行程。另外 fare_amount、total_amount 的值还要大于 0。

最终,在初步清理之后,看看还剩下多少出租车行程数据可供分析:

还剩下 11 亿的行程!这些数据足以让我们从出租车出行中获得一些有价值的见解。
假设我们是一名出租车司机或者一家出租车公司的经理,有兴趣使用这些数据来了解如何最大化利润、最小化成本或者仅仅是改善我们的工作生活。
首先,我们找出可以带来平均最高收益的接客地点。简单讲,只需要绘制出接客地点的热力图,并用颜色标记平均价格,然后查看热点地区。但是由于出租车司机需要自行承担费用,例如燃料费。
因此,虽然将乘客载到较远的地方可能带来更高车费,但同时也意味着更多的燃料消耗和时间损失。
另外,在偏远地区找一个回市中心某地的乘客可不是那么容易,而在没有乘客的情况下回程就会很浪费。一种解决方法是用车费和行程距离之比的平均值对热力图进行颜色编码。我们来尝试一下这两种方法:
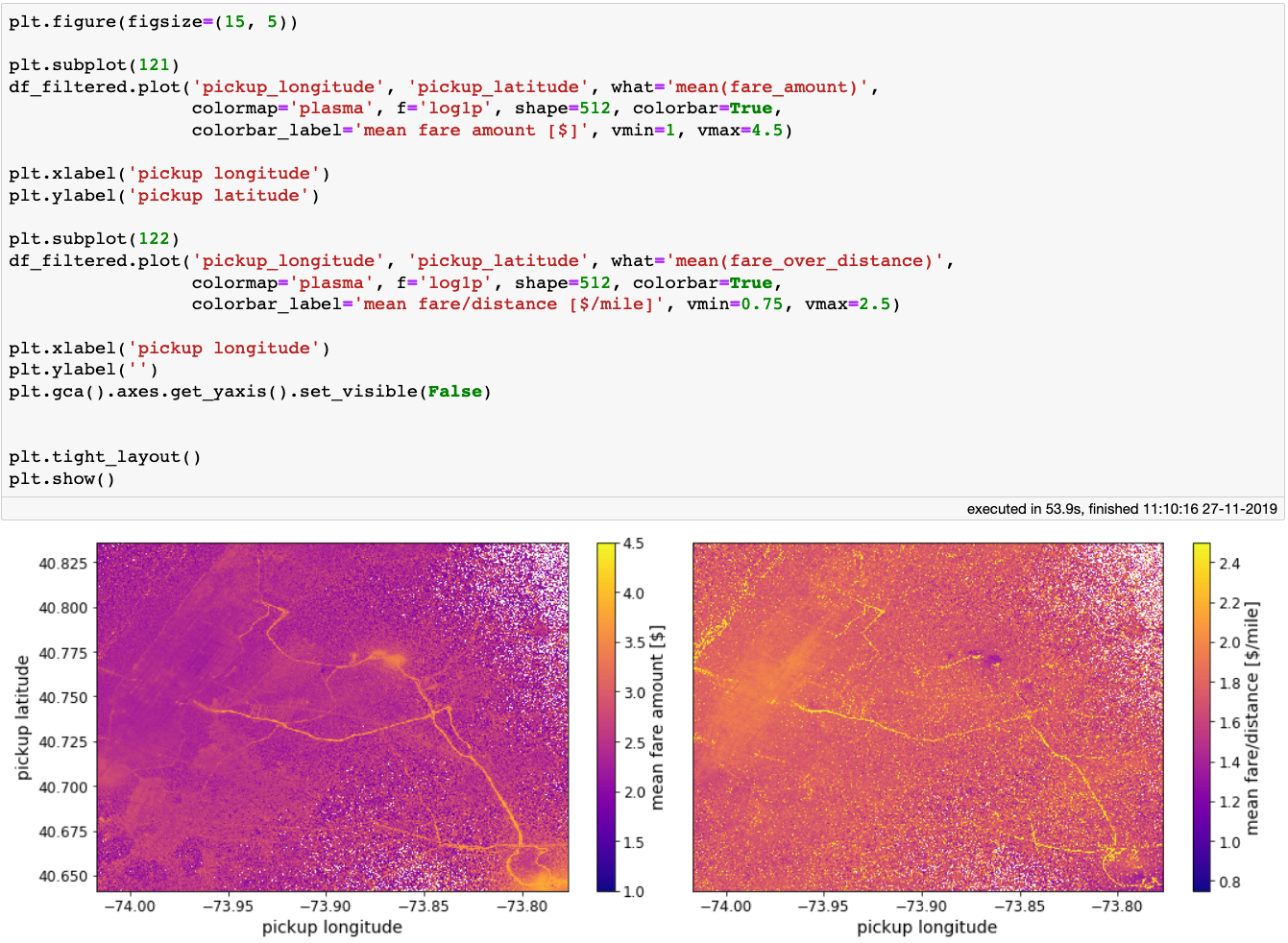
纽约热力图,颜色编码:平均车费(左),车费与行程距离的平均比值
简单情况下,只关心所提供服务的最高车费时,纽约机场以及像范怀克高速公路(Van Wyck Expressway)和长岛高速公路(Long Island Expressway)这样的主干道是最佳的载客区。
当考虑行程距离时,会得到一张不同的图像。范怀克高速公路、长岛高速公路以及机场仍然是搭载乘客的好地方,但它们在地图上的重要性要低得多。而在哈德逊河(Hudson river)的西侧出现了一些新的热点地区,看起来利润颇丰。
作为出租车司机,实践中可以做得很灵活。要想更好地利用这种灵活性,除了知道要在哪里载客之外,了解什么时候出车最赚钱也很有用。为回答这个问题,我们绘制一个图表来展示每天和每小时的平均车费与行程距离之比。
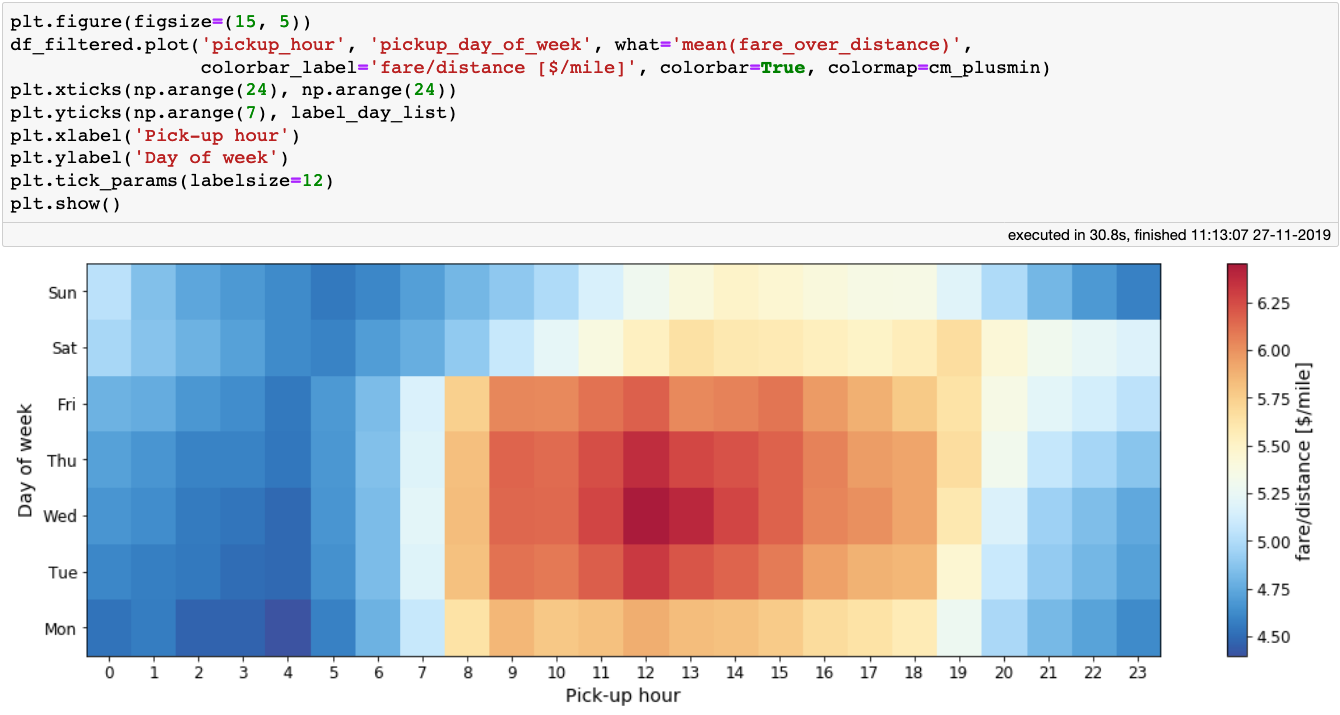
一周中每天以及一天中每小时的车费与行程的平均比值
上面的图很符合常识:高峰时段最挣钱,特别是工作日的中午。作为出租车司机,收入的一部分要交给出租车公司,所以我们可能会对哪天、哪个时段顾客给的小费最多感兴趣。绘制一个类似的图展示平均小费比例:
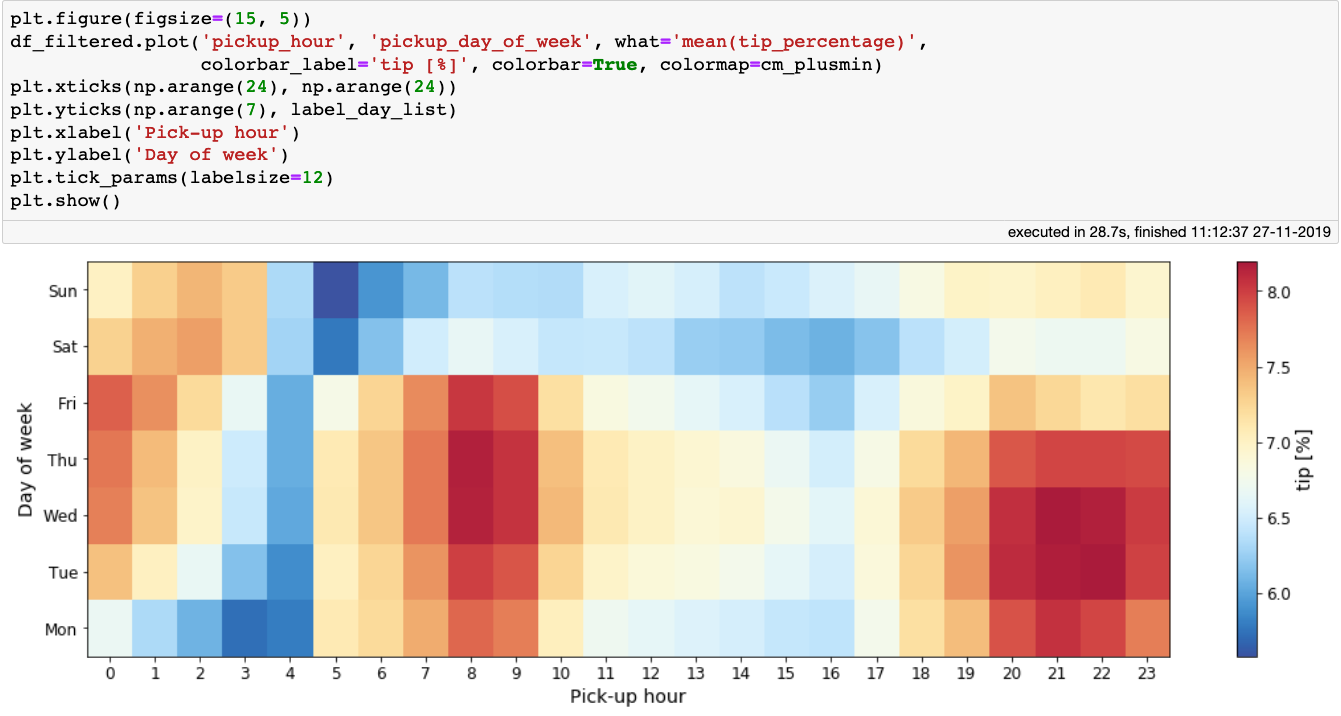
一周中每天以及一天中每小时的小费比例平均值
上图很有意思,它告诉我们在一周中前几天的早上 7-10 点和晚上 7-10 点乘客给司机的小费最多。如果在凌晨 3-4 点接乘客,不要指望会有大额小费。
结合最后两张图的经验,早上 8 点到 10 点是最好的工作时间,司机可以得到较多的车费(每英里)和小费。
在本文的前半部分,我们简要地关注了trip_distance列,在给它清理异常值时,只保留了低于 100 英里的行程。但这个边界值仍然很大,尤其是考虑到 Yellow Taxi 公司主要在曼哈顿运营。
trip_distance描述出租车从上车点到下车点的行驶距离,但是在确切的两个上车点和下车点之间,通常有多条不同距离的路线可以选择,比如为了避开交通堵塞和道路施工的情况。
所以,相对于trip_distance列,我们计算一项接送位置之间可能的最短距离,命名为arc_distance:
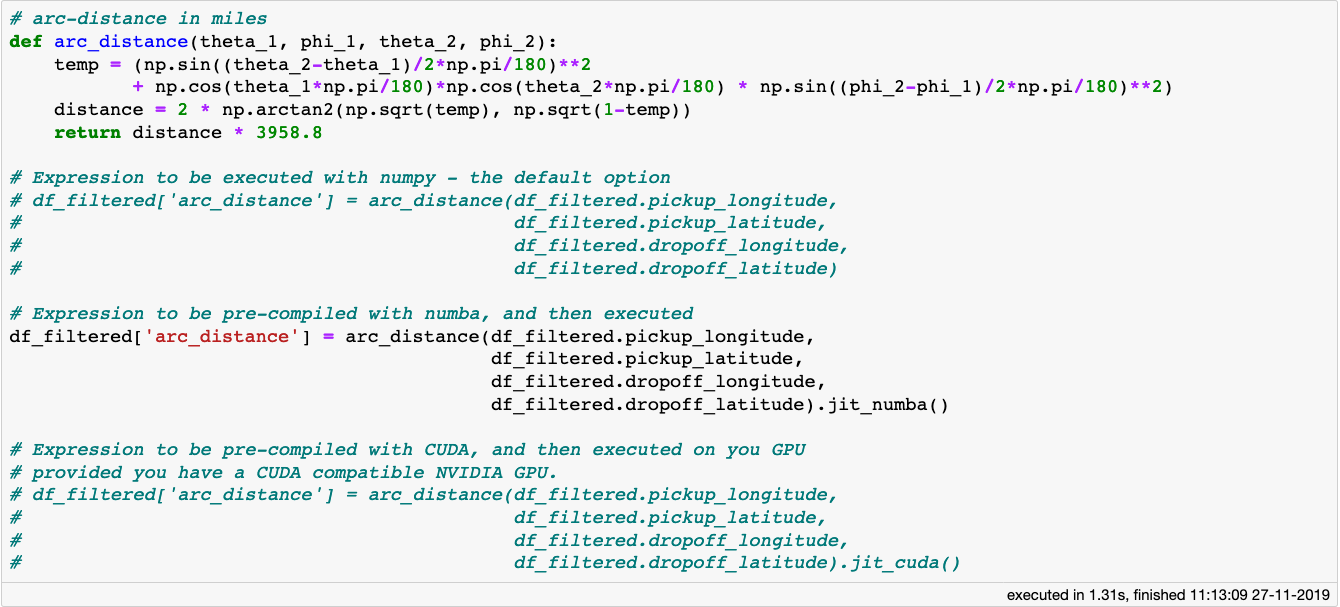
对于用 numpy 编写的复杂表达式,vaex 可以借助 Numba、Pythran 甚至 CUDA(需要 NVIDIA GPU)通过即时编译来极大提高运算速度。
arc_distance的计算公式非常复杂,它包含了大量的三角函数和数学运算,在处理大型数据集时计算代价非常高。如果表达式或函数只用到了 Python 运算符和 Numpy 库的方法,Vaex 会使用计算机的所有核心来并行计算。
除此之外,Vaex 通过 Numba (使用 LLVM)和 Pythran (通过 C++ 加速)支持即时编译从而提供更好性能。如果你碰巧有 NVIDIA 显卡,就可以通过jit_cuda方法来运用 CUDA 以获取更快的性能。
我们来绘制 trip_distance 和 arc_distance 的分布:
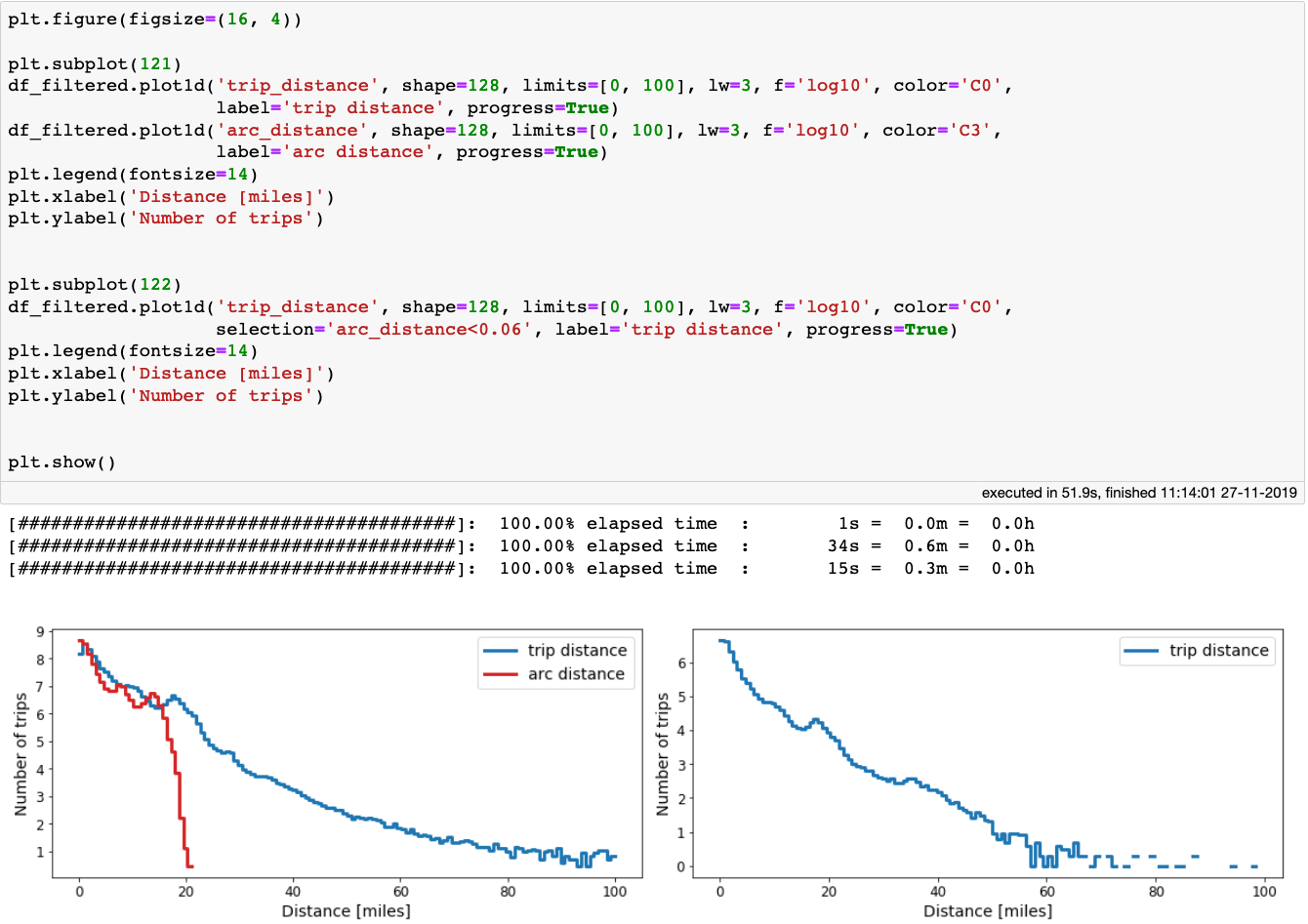
左:trip_distance 和 arc_distance 的比较;右:arc_distance<100 米时 trip_distance 的分布。
有意思的是,arc_distance从来没有超过 21 英里,但出租车实际行驶距离可能是它的 5 倍。事实上,有数百万次的行程下客点距离上客点只有 100 米(0.06 英里)!
我们今天使用数据集时间上跨越了 7 年。随着时间流逝,人们的兴趣如何演变可能是件有趣的事。使用 Vaex 可以进行快速的核外分组和聚合操作。
我们来看看 7 年间车费和行程距离都有什么变化:
在四核处理器的笔记本电脑上,对拥有超过 10 亿样本的 Vaex DataFrame 进行 8 个聚合的分组操作只需不到 2 分钟。
在上面的代码块中,我们执行分组操作,然后执行 8 个聚合,其中有 2 个位于虚拟列上。上面的代码块在我的笔记本电脑上执行耗时不到 2 分钟。鉴于我们使用的数据包含超过 10 亿条样本,这是相当惊人的。
总之,我们来看看结果,以下是多年来乘坐出租车的费用的变化情况:
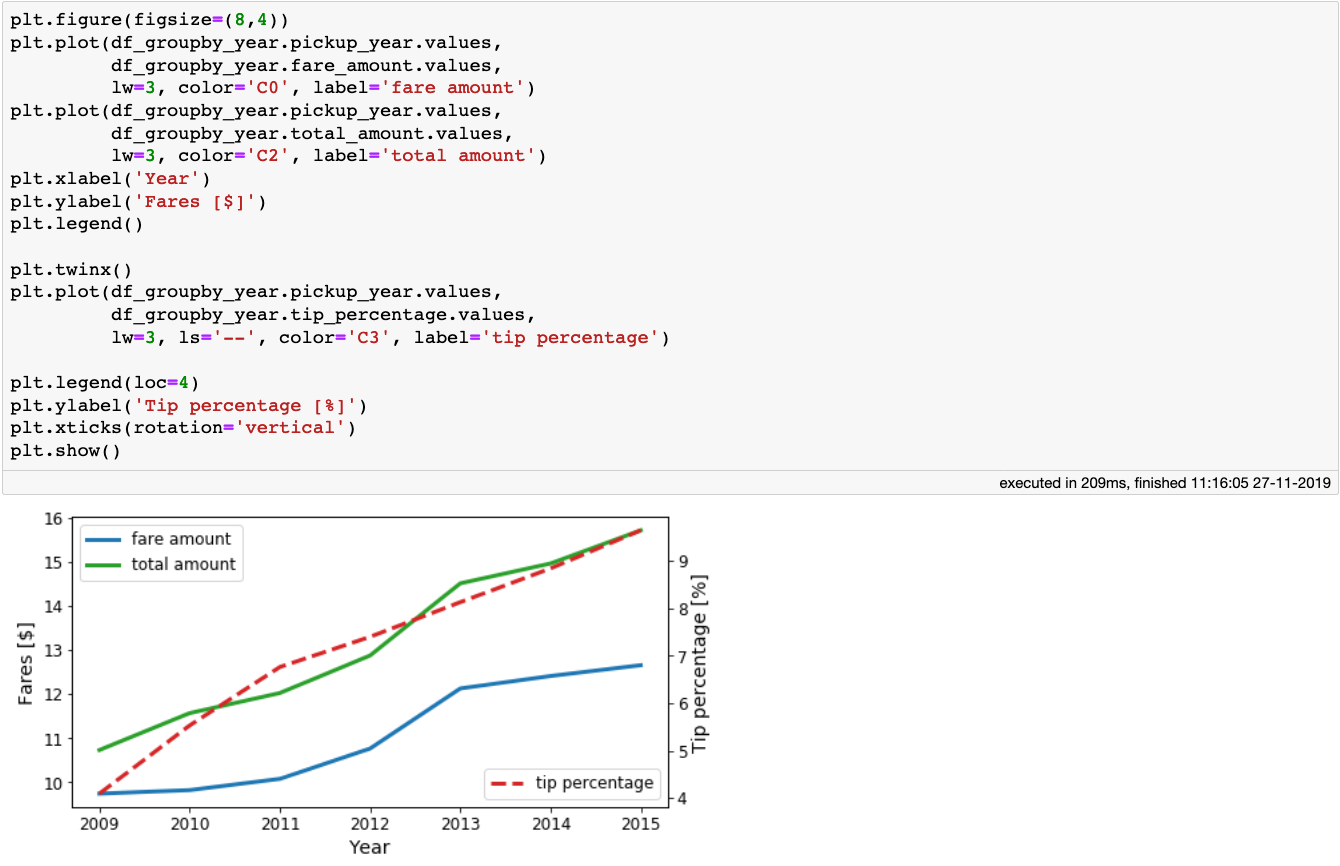
每年的平均车费和总金额以及乘客所付的小费比例
可以看出随着时间流逝,出租车费和小费都在上涨。再来看看出租车每年的平均trip_disrance和arc_distance:
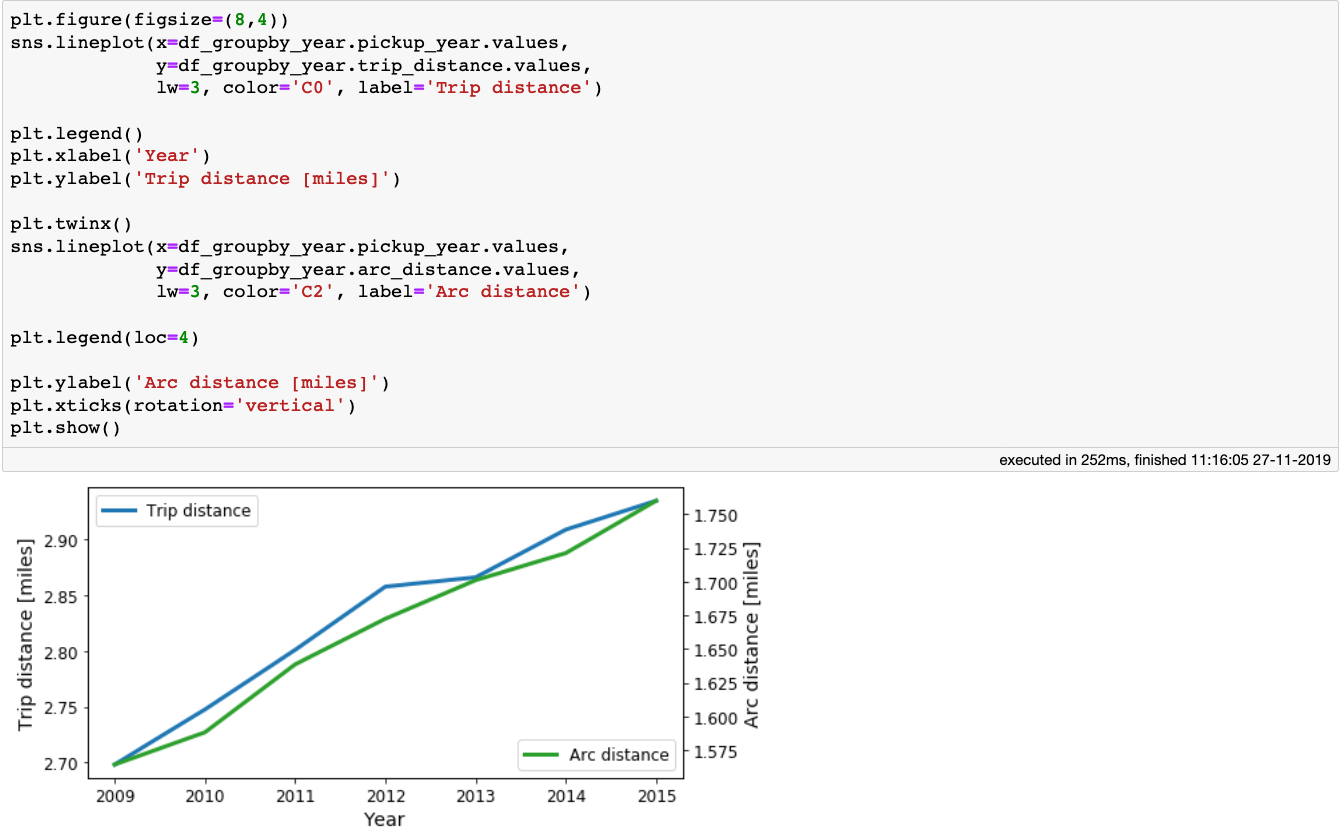
出租车每年的行程和弧距
上图显示,trip_distance和arc_distance都有一个小的增长,这意味着,平均而言,人们倾向于每年走得更远一点。
在旅程结束之前,我们再停一站,调查一下乘客是如何支付乘车费用的。数据集中包含了payment_type,来看看它都包含什么值:
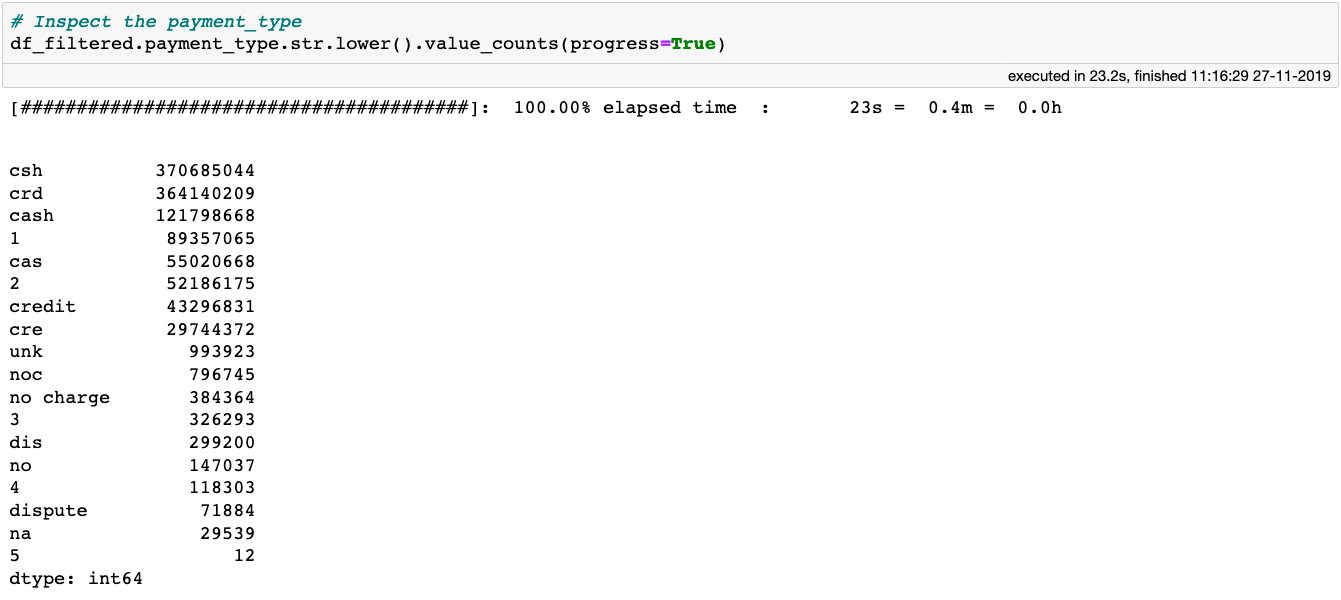
从数据集文档中,可以看出只有 6 个有效条目:
由此,可以简单地把payment_type映射到整数:

现在可以根据每年的数据进行分组,看看纽约人在支付打车费用方面的习惯是如何变化的:
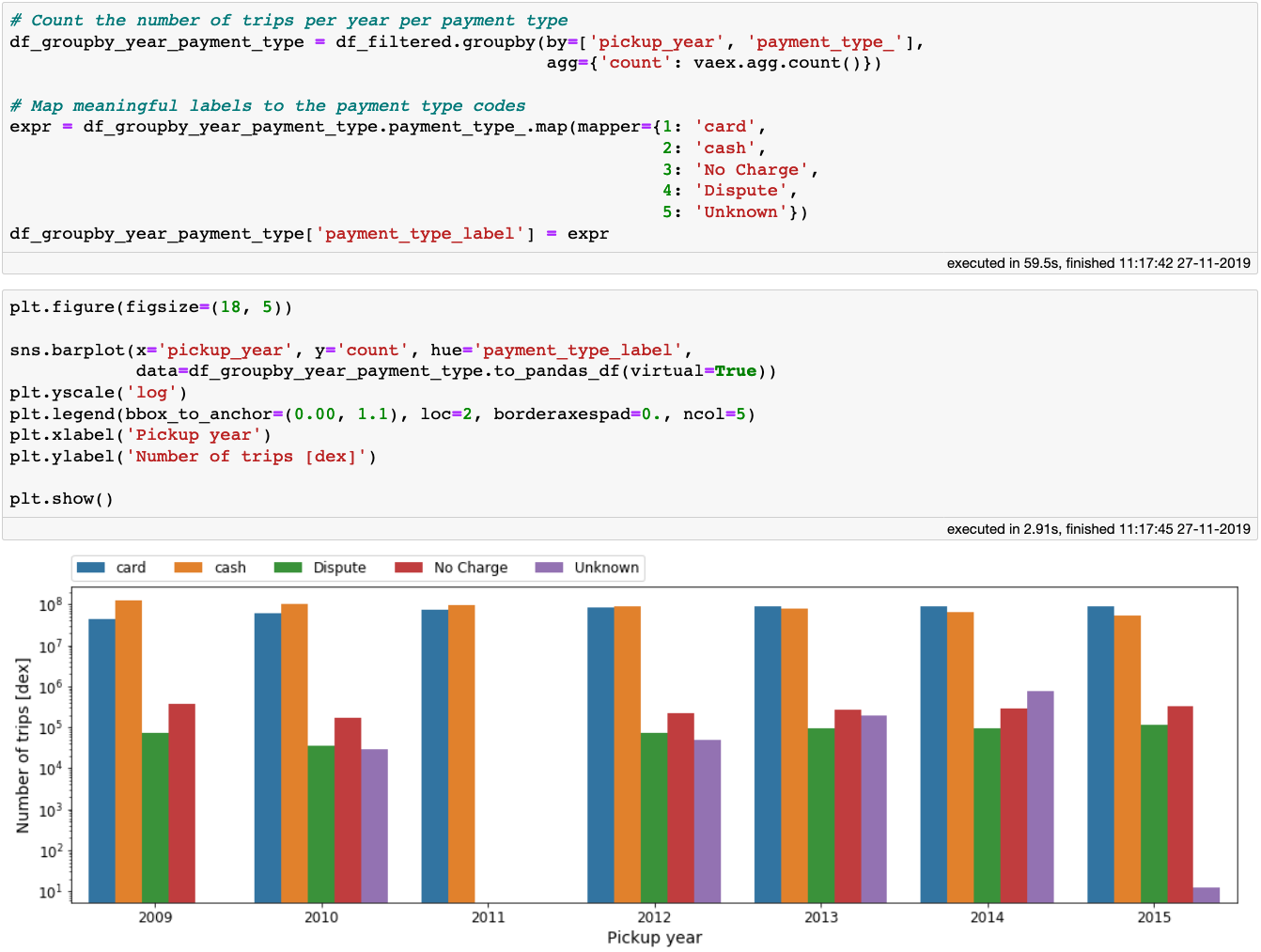
每年的支付方式
可以发现随着时间的推移,信用卡支付逐渐变得比现金支付更加频繁。我们果然是生活在数字时代!在上面的代码块中,一旦完成数据聚合,小型的 Vaex DataFrame 可以轻易地转换为 Pandas DataFrame,从而传递给 Seaborn 。不用费劲在这重新发明轮子。
最后通过绘制现金支付和信用卡支付之间的比例,来查看付款方法是否取决于当天的时间或者星期几。为此,先创建一个过滤器,筛出用现金或者信用卡的行程。
下一步是我最喜欢的 Vaex 的特性之一:带选择的聚合。其他库要求对每个支付方法筛选出单独的 DataFrame 进行聚合,然后再合并为一个。
而使用 Vaex,可以在聚合函数中提供多个选择从而一步到位。这非常方便,只需进行一次数据传递,能提供更好性能。之后就可以用标准方式绘制 DataFrame:

在给定的时间和星期中某一天,现金和信用卡支付的比例
从上图可以发现其模式非常类似于之前的一周中每天以及一天中每小时的小费比例。从这两个图推测,信用卡支付的乘客倾向于比现金支付的乘客给更多的小费。
要想知道这是不是真的,我希望你去尝试把它弄清楚,因为现在你已经拥有了知识、工具和数据!你可以从这个 Jupyter notebook 获取更到额外提示。
我希望这篇文章是对 Vaex 一个有用的介绍,它会帮你缓解可能面临的一些“麻烦数据”的问题,至少在涉及表数据集时是这样的。如果你对探索本文中用到的数据集感兴趣,可以直接在 S3 中配合 Vaex 使用它,请参阅完整的 Jupyter notebook 了解如何实现。
有了 Vaex,你可以在短短几秒内遍历超过 10 亿行数据,计算各种统计、聚合并产出信息图表,这一切都能在你的笔记本电脑上完成。它免费且开源,你可以尝试一下!
数据科学快乐!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号