当Scala让我想要放弃时,我转向Python和Java的怀抱
发表时间: 2020-04-15 17:21
对于Scala的炒作在2016年达到了顶峰,此后这门编程语言的热度不断下降,甚至有人认为它已经进入了衰退期。实际上,Scala的使用率近几年一直在提升。相比Java,使用Scala能将面向对象语言和函数式语言的优点相结合,用更少的代码即可实现更高的性能;而相比Python,Scala虽然上手不那么容易,但其性能和语言设计更强大,熟悉之后开发速度其实超过Python。在很多资深程序员眼中,能替代Java、并且能做得比它更好的只有Scala。问题在于,Scala未来是否能扩展新的用户群体,变得不那么“小众”?
我的一位朋友最近在推特上表示:公众对Scala编程语言的兴趣似乎已经趋于稳定或减弱,这与我的感受一致。这篇博文将会讨论为什么会发生这种情况,并且聊聊Scala现在的地位以及Scala社区的未来。
本文最初发布于Li Haoyi的个人博客,经原作者授权由InfoQ中文站翻译并分享。
本文受下面这条推特启发:
看到Typesafe/Lightbend(注:Scala的技术推广公司)的朋友被解雇是一件很遗憾的事情,但正如我一直说的,免费的东西很难卖出去。
我很想知道Scala现在的采用情况。它没死,但似乎在2016年就达到了热度的顶峰。不过我没有任何数据支持这个观点。
——Jamie Allen
Jamie注意到,公众对Scala编程语言的兴趣似乎已经减弱了:对Meetup的兴趣减少了,对会议的兴趣减少了...这或多或少跟我的观察一致。尽管面向Scala爱好者的Scala专门会议仍然很热门(或者说在新冠疫情之前,曾经很热门),但我认为毫无疑问,在更广泛的开发者社区中,关于Scala的讨论的确越来越少。
我认为,公众兴趣减弱是客观存在的事实,但任何新技术都会出现典型的“炒作周期”:
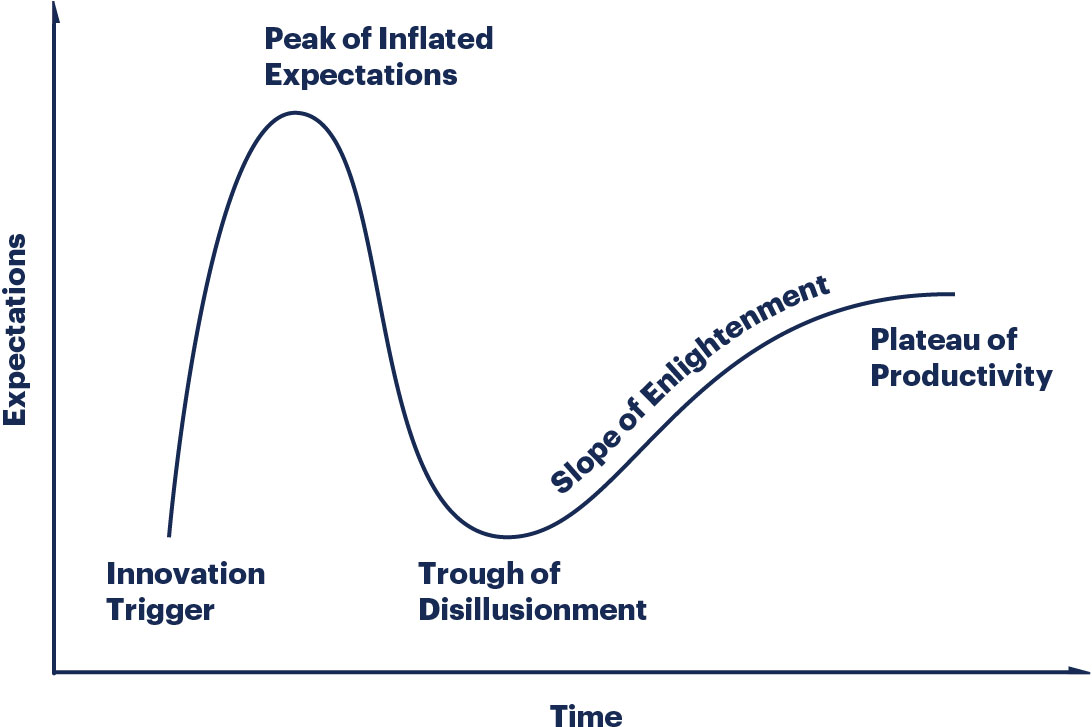
早期,Scala掀起了一波宣传热潮,坦率地说,这甚至让我感到惊讶:关于扩展语法边界的宣传,关于反应式架构的宣传,关于函数式编程的宣传,关于Apache Spark项目的宣传。但自那以后,这种宣传逐渐消失了,有一段时期,Scala社区内外都出现了反对之声。再然后,连反对的声音也消失了,只剩下这种合理但乏味的语言,稳步地向前发展,为通用软件工程提供了一个优秀的平台。
虽然Scala最初创建于2004年,但直到2010年初它才真正开始起飞:
在此之前,Scala社区非常活跃,上述这些关键节点是激发人们对这门语言兴趣的主要里程碑。其中既有大规模的商业采用、商业支持,也有像Apache Spark这样的大数据产品。所以公众的兴趣激增也就不足为奇了。Scala社区的努力主要体现在以下几个方面:
早期,人们感兴趣的是Scala语言的灵活性:它支持扩展方法、操作符重载、隐式构造函数/转换,还有一个非常灵活的、可以以各种方式使用的隐式参数特性。这种灵活性是一种解放,因为它开启了各种领域特定的语言和编程风格,这在其他语言中闻所未闻。
关于这一点,有许多项目可以证明,如Databinder Dispatch HTTP客户端、Scala-Graph数据结构库或SBT构建工具:
// 发送一个HTTP请求,在Databinder Dispatch中处理输出executer(:/(host, port) / target << reqBody >- { fromRespStr })// 在Scala Graph中构造一个边带标签的简单有向图val flights = Graph( (jfc ~+#> fra)(Flight("LH 400" ,10 o 25, 8 h 20)), (fra ~+#> dme)(Flight("LH 1444", 7 o 50, 3 h 10))// 在使用SBT通过grep过滤后,将URL的内容追加到文件url("http://databinder.net/dispatch/About") #> "grep JSON" #>> file("About_JSON") !// 使用SBT在源目录中查找null的使用"find src -name *.scala -exec grep null {} ;" #| "xargs test -z" #&& "echo null-free" #|| "echo null detected"
许多这样的库从早期就已经发展起来了,并且已经转向了更乏味的基于方法的API。事实证明,命名操作符>- ~+#>或#&&虽然可行,但有时候这样做并不是最明智的。不过,毫无疑问,使用操作符和领域专用语言来扩展Scala语法边界是人们早期对于Scala的一大兴趣点。
反应式架构主要由Lightbend通过其Akka Actor框架推动,是另外一项很大的工作。这种方法编写的代码与人们在学校里可能学到的“普通”代码差别很大,但是,它的高并发和高性能是用传统风格编写的代码所无法达到的。
在最初的语法中,Akka Actors牺牲了Scala的很多特性:actor之间完全缺乏类型安全,禁止阻塞API,以及许多其他特性。使用Akka Actors基本上是使用它们自己的语言,虽然嵌入在Scala中,但是有它们自己的约定、语法和语义。
最近,通过Typed Actors和Reactive Streams,Akka的开发体验已经与传统Scala编程的类型检查体验更接近了。我认为社区的态度也发生了转变:不再将反应式架构视为解决所有问题的通用解决方案,而是将其视为解决某一类问题的一种可能的方法。这与我在自己的应用程序中使用这些技术的经验基本一致。
关于Scala的函数式编程,最好的例子就是Scalaz和Cats项目。这两个库设法将Haskell中的很多函数式编程技术引入了Scala语言:重点关注Monads或Applicatives这样的概念,避开语言面向对象的一面,采用更纯粹的函数式风格。
这两个库的风格不同,并且都被社区的一部分人大量使用。在某种程度上,虽然布道已经停息,但是使用量仍然很大,每个人都认为函数式编程是编写Scala应用程序的一种可能的风格。
Apache Spark是推动Scala早期发展的最后一个大项目。Apache Spark是一个分布式大数据处理框架,它利用Scala的函数式风格和可序列化lambdas来获取公共集合,如map、filter和reduce,并在一个处理大量数据的计算集群上运行它们。与早期的Hadoop API相比,Apache Spark让我们编写大数据处理管道的代码少了几个数量级,并且运行大数据处理管道的时间也少几个数量级,因此Spark一炮而红。
作为Scala的杀手级应用,Scala社区中有很大一部分人使用Scala只是因为他们需要以某种方式与Spark进行互操作。
现在,Apache Spark已经支持多种语言的开发API:SQL、R,还有最为流行的Python。起初类似于集合的API已经在很大程度上被更接近SQL的接口所取代,后者更好优化,对于经常使用大型数据集的Apache Spark来说,这是一个重要的因素。尽管如此,Apache Spark代码库至今仍保留了大部分的Scala。
随着最初的炒作逐渐平息,肯定会出现一些反对Scala的声音。一些早期的贡献者离开了社区,并且发生了一些人际关系的不愉快。不管是总体上,还是个人层面上:我自己认识许多人,他们厌倦了自己一直在宣传的事情,心里有点失望,可还得继续前进。
很难确切地说炒作是何时消失的,可能在2016-2018年左右。
即使在技术层面上,也并非一切顺利。虽然许多组织在各自的领域中成功地使用了这些技术,但是其他组织却后悔将全部精力投入到actor和函数式编程中。他们发现,这些技术并不像他们所希望的那样适合他们的问题,并且不得不花时间从他们对特定编程范式的全部投资中退出。据我所知,许多组织都被迫做出了这样的调整。
早在2010年代初,我就对其中相关技术的炒作感到惊讶。在其中有些库,操作符的使用非常广泛,有时甚至会将简单的任务变成复杂的脑筋急转弯。对反应式架构和函数式编程的过度吹捧,与它们最适合的特定用例并不匹配:每一次Scala大会上都有主题演讲者宣称这两种方法是软件架构最重要的未来。
我一点也不惊讶,随着时间的推移,其他人会像我一样意识到其低谷期的来临。
Scala在2010年代初被大肆吹捧,随后在2010年代中后期这种炒作遭到强烈抵制。那么Scala现状如何?
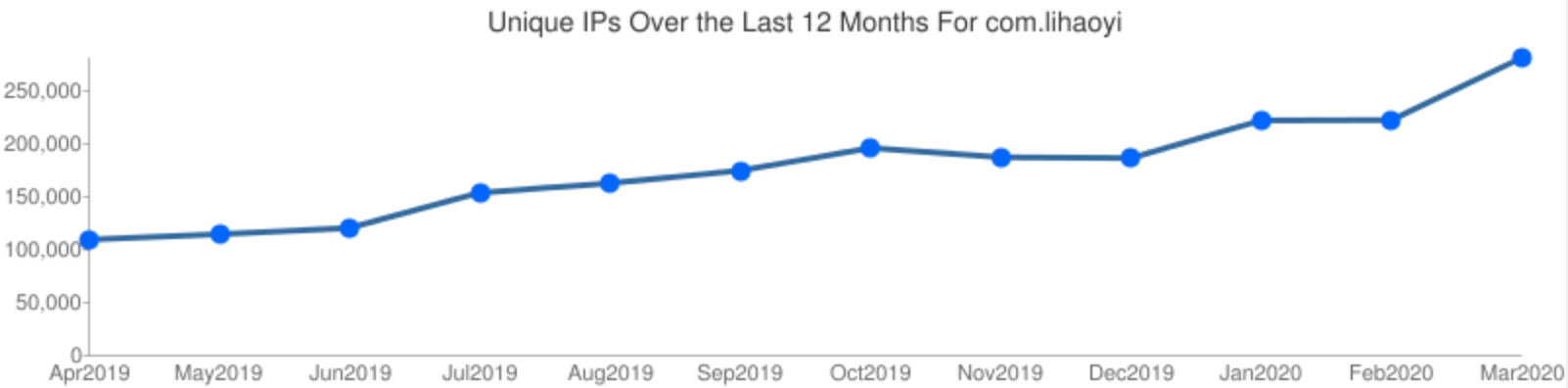
尽管公众的兴趣明显下降,但Scala的使用率仍在继续增加。我维护了许多开源库,从Maven Central软件包存储库下载这些库的非重复IP的数量比去年增加了2倍多。虽然每个包的下载量或指标存在一些差异,但总体而言,它们非常符合这一趋势。
虽然这种增长并不是部分人所期望的指数级增长,但这是一种使用量的稳步增长,符合我的主观体验:尽管炒作已经消失,但Scala的使用率仍在继续增长。如果未来能保持每年2倍的增长,我详细Scala社区将会继续保持良好的状态!
如果你看一下最近的Redmonk排名或Tiobe排名,就会发现Scala的排名稳定地徘徊在主流语言之外,分别排在第13位和第28位。不寻常,但也不难理解。
炒作和反弹都成了遥远的记忆,现在看来,Scala是一种支持多种编程风格的灵活语言,每一种风格都有自己的权衡和适用场景。早期的热情和冲突已经转变为人们使用Scala稳定地工作,享受他们自己选择的语言。
尽管天花乱坠的宣传有所减少,但Scala语言比过去要好得多:
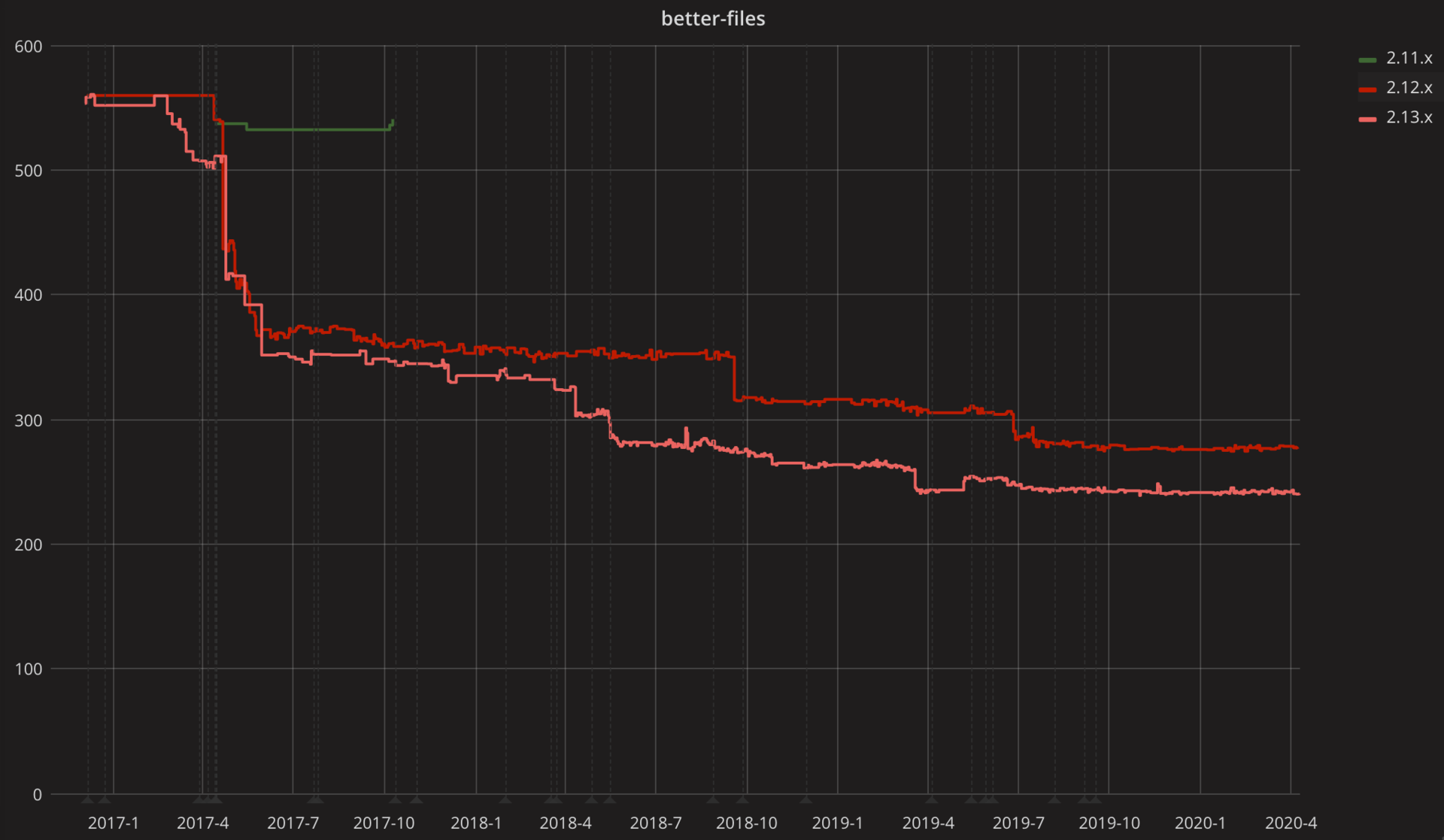
虽然语言规范在过去几年几乎没有任何变化,但是,已经实现的开发体验改进非常之多。如果你在2017年与任何使用Scala的工程组织讨论将编译时间减半的问题,他们会给你一大笔钱让你实现它!
上述所有改进都极大地改善了我自己编写Scala的体验,还有许多改进我无法在这里一一列举。
虽然对于最初四项工作的宣传已经减弱了,但它们仍然在Scala生态系统中形成了大量活跃的子社区。例如,虽然不是每个人都想使用纯函数式编程,也不是每个人都想一直使用它,但是,与之相关的库和生态系统却是多种多样,质量高且维护良好。当你遇到需要使用纯函数式编程的场合时,你可以找到所需的一切。
在某种程度上,之前的宣传达到了它的目的:通过向大量的人介绍一个特定的范例,使子社区的人数达到维持这个子社区发展的临界数量。
我们可以将Scala中广泛的风格看作是一种福利:不是将其视为分割社区的一种方式,而是将那些永远不会相互交流的社区聚集在一起的一种方式。没有Scala,这些社区可能各自在Haskell、Python、Java和Go系统中工作,互不相干。通过关注共享的内容而不是不同之处,Scala让这些社区在对所有人都有利的事情上协作,同时每个子社区仍然保持独一无二。
我没有默认使用Actors来设计代码架构,但是我已经交付了大量使用Actors的生产代码。我也没有默认使用纯函数式编程技术,但是我使用了一些非常深奥的结构,比如Free Applicatives。我认为,社区作为一个整体也以类似的方式变得更加成熟了:欣赏不同的风格,并在适当的地方使用它们,没有了早期困扰Scala的教条主义。
那么,Scala未来还会有什么令人兴奋的东西吗?
对我来说,Scala语言本身处于一个相对良好的状态。花一整个下午的时间编写现代Java代码就足以让我摆脱“其他编程语言已经迎头赶上Scala”的想法,花了几天时间尝试(最终并未成功)将Python项目打包成一个独立的可执行文件也是如此。
Scala未来最大的潜力在于发展新的用户群,以及寻找新的应用场景,到目前为止,这些都完全不在社区的考虑范围内。但在我看来,有两件事很重要。
在Scala最初的四项工作中,少了一样东西:让新晋开发人员能够从代码库开始,并立即具备生产力。无论你使用的是operator为主的调度风格,还是actor为主的反应风格,还是Cats/Scalaz纯粹的函数式风格,都一样:每一个开始尝试Scala的人都会遇到困难。
为什么会这样呢?
举个相反的例子,开发人员通常觉得Python是一门很容易入门的语言:他们称之为“可执行的伪代码”。新程序员学Python,非程序员学Python。当人们使用记号笔在白板上编写代码时,他们编写的通常也是Python。虽然Python的性能、并发性或大规模可维护性存在问题,但它的易于入门是无与伦比的。
为什么Scala不能像Python那么容易上手呢?
回答这个问题是我维护这整套库的目标。我的许多库复制了Python中的同类库。例如:
事实证明,你可以让Scala变得像Python一样容易上手。而对于Python的所有弱点——性能、并发性、可维护性——Scala已经做得很好了。Scala完全有潜力成为既有Python的易用性和灵活性,又兼具Java或Go的性能和可伸缩性的编程语言,再加上远远超出了这些编程语言的类型安全可维护性,字面意义上的两全其美。
虽然在某些情况下,高并发反应式架构或纯粹的函数式编程是完成工作最好的工具,但我希望将来,开发人员将能够以一种简单明了的方式上手Scala语言,并且只在需要时才学习那些更高级的技术。
Scala.js已经证明了在其他平台上使用Scala的可行性:编译成JavaScript而不是在JVM上,JavaScript拥有充满活力的生态系统和社区,将Scala语言引入到浏览器,这是一个以前从未用过Scala的地方。
Scala-Native带来了更大的变革:通过将Scala编译成自包含的二进制可执行文件,使得Scala语言可以在JVM或JavaScript运行时启动时间和资源开销不可接受的情况下使用。如果说Scala.js将Scala引入到了浏览器,Scala-Native则有望将Scala引入更多新环境:
传统上,这类程序是用C或C++等不安全的语言编写的。最近的实现通常是用Rust或Go编写,还有一些家庭作坊式的非C语言试图填补这个空白,比如Nim、Zig或Crystal。Scala-Native有望填补这个空白,不是使用一种全新的语言,而是使用一种已经流行的语言,而且它已经有一个具备丰富的库和工具的生态系统。
Scala-Native要取得成功比Scala.js困难得多。Scala.js可以专注于编译器,然后将其委托给现有的JavaScript运行时,而Scala-Native必须根据基本原则构建自己的运行时:线程、垃圾收集、事件循环等等。这需要做大量的编译方面的工作。但是,如果成功的话,这对于拓宽Scala语言的使用范围将是一个巨大的福音。
虽然对于Scala语言的炒作在过去几年里已经逐渐平息,但它的使用率仍在稳步增长,使用体验也在不断改善。这正是你所期望的,因为一种语言在经历了炒作周期之后,会从一个炒作驱动的社区发展成一个价值驱动的社区。Scala开发人员并不是为了使用这门语言而使用,而是将其作为一种可靠的工具来实现与Scala无关的技术或业务目标。
实际上,这就是社区成熟的含义。
展望未来,我希望我们能看到更多这样的情况,更多地关注结果和价值,而不是炒作,更多的权衡利弊,而不是教条主义,更多的鼓励共享,而不是争论分歧,以及实现更多像编译器两倍速提升的优化!
我认为,让Scala社区增长10倍的方法,不是花10倍的精力去讨论现有的语言语法,不是花10倍的精力去讨论函数式编程和面向对象编程,也不是花10倍的精力去让我们已经类型安全的代码更加类型安全。相反,我们能应该通过包容性地扩展该语言,让那些以前从未接触过它的开发人员使用它:新手、非程序员、命令行工具人员、iOS开发人员等等。如果我们看看2019年的Jetbrains Python开发者调查,我们就可以看到Python语言在不同领域的使用广度:

目前,Scala主要用于后台服务和/或Spark数据管道,但其实Scala还能用于很多其他的使用场景。Scala社区要设法让Scala的使用变得足够简单和广泛,让所有人(不仅仅是后台/数据工程师)都能学会Scala并使用它,同时享受Scala社区所熟知和喜爱的简洁性、性能和类型安全。
关注我并转发此篇文章,私信我“领取资料”,即可免费获得InfoQ价值4999元迷你书!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号