Redis技术实战指南:从入门到精通
发表时间: 2020-11-11 08:02

阅读本文约需要10分钟,您可以先关注我们,避免下次无法找到。
Redis是现在最受欢迎的NoSQL数据库之一,目前广泛用于缓存系统、分布式锁、计数器、消息队列系统、排行榜、社交网络等场景中,本篇文章成哥为大家带来redis日常使用实践,及通过代码实现redis的分布式锁。
Redis是一个开源使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可以持久化的日志类型、key-value数据库,并提供多种语言的API。Redis的出现,很大程度上弥补了Memcache这类key/value存储的不足,在部分场合可以对关系型数据库(MySql、DB2等,关系型数据库通过外键关联来建立表与表之间的关系。非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定)起到很好的补充作用。(如可降低数据库访问压力,弊端冷数据的处理)。
(1)单线程
Redis是通过单线程实现的,单线程避免了多线程的切换性能损耗问题,同时它所有的数据都在内存中,所有的运算都是内存级别的运算,所以即使是单线程redis还能这么快。但也正是因为使用的是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
(2)IO多路复用
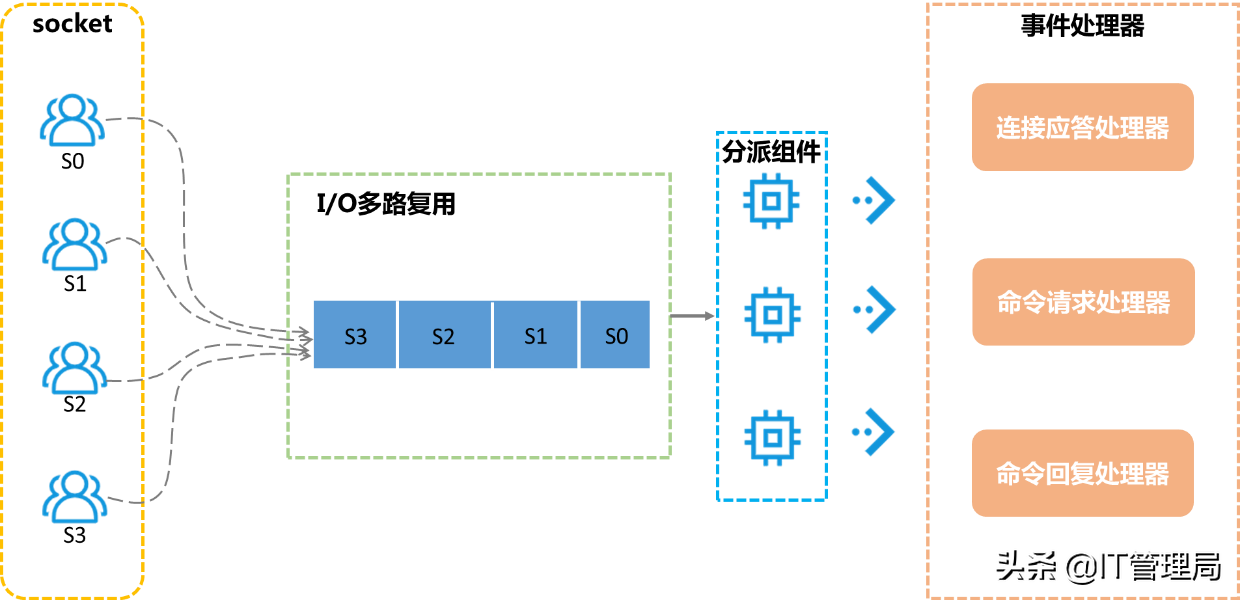
Redis通过IO多路复用解决单线程下并发客户端的访问,redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。具体架构如下:
(1)哨兵模式

在redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发,且单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率 。
(2)高可用集群模式
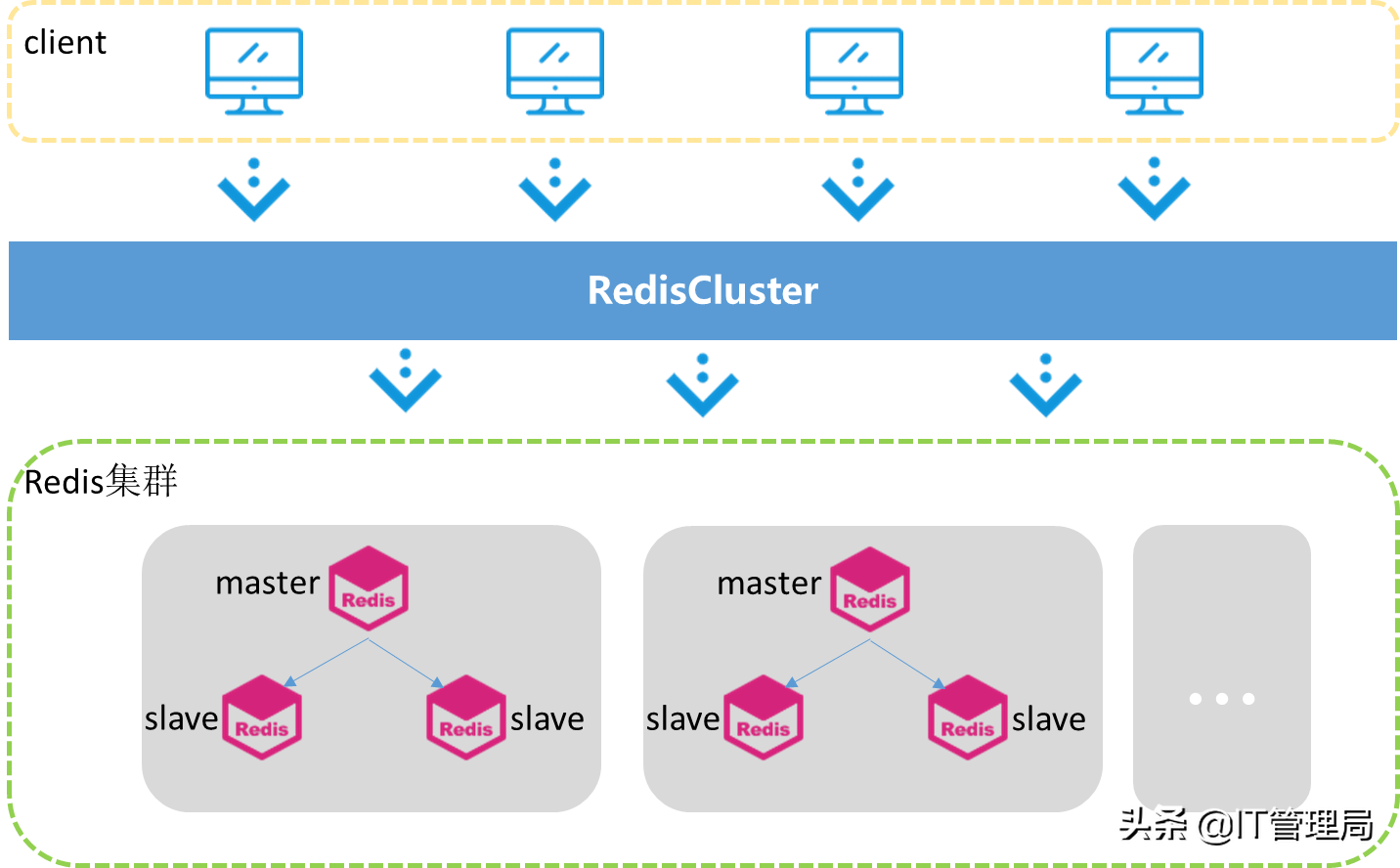
redis高可用集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。
在了解Redis集群部署常见问题之前我们先来了解一下Redis集群的实现原理。Redis Cluster 将所有数据划分为 16384 的 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
(1)跳转重定位问题
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。客户端收到指令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有 key 将使用新的槽位映射表。
(2)网络抖动问题
在生产环境中网络抖动问题不可避免,为解决这种问题,Redis Cluster 提供了一种选项clusternodetimeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
在多个进程/线程对同一个共享资源读写场景下,会因为资源的争夺而出现混乱,导致数据不一致。为了避免该问题我们可以在进程/线程在操作共享资源前获取一个令牌(也就锁),只有获取了该令牌的进程/线程才可以操作资源,在操作完资源后释放该令牌。这就实现了分布式锁。
Redis的分布式锁是基于Redis SETNX命令来实现的,在Redis中通过SETNX命令设置Key Value时有如下两种结果:
1)返回1,表示为指定的key设置值成功,也即表示当前进程已经获取了锁资源
2)返回0,表示为指定的key设置值失败,因为当前已存在该key,也即表示其它进程获取了锁资源
下面我们就来看看怎么通过python实现分布式锁吧
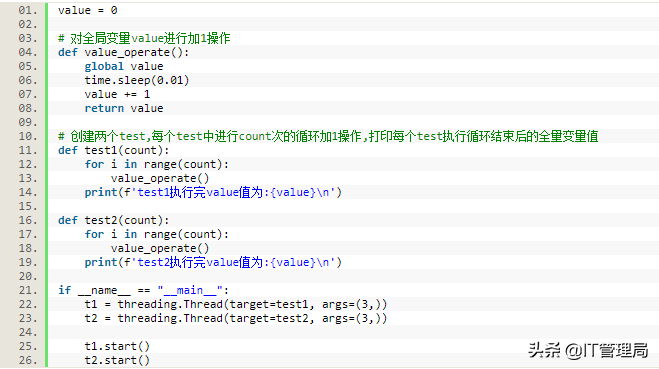
(1)首先我们创建一个不使用分布式锁的示列,通过多线程对全局变量进行加1操作看看结果如何,具体代码如下:
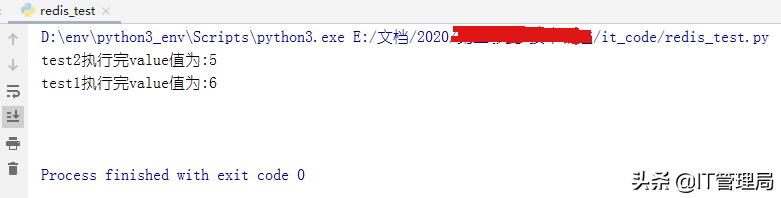
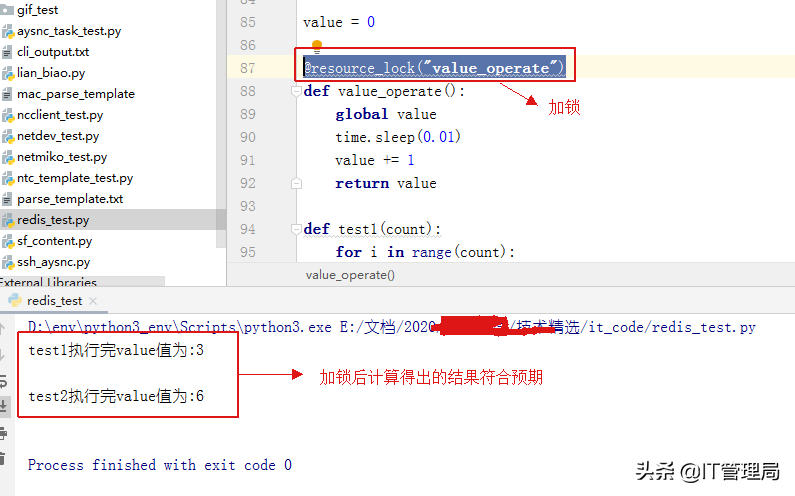
代码运行结果如下,发现不是我们预期的值(预期值应为3+3=6)
(2)接着我们创建带分布式锁的示列,我们先来看看分布式锁创建的方法,具体如下
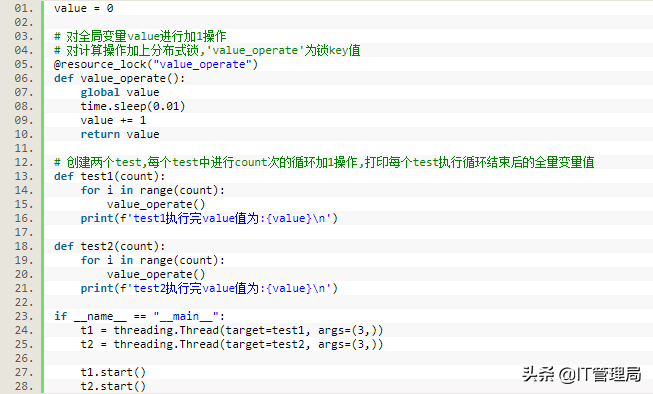
1. import time 2. import uuid 3. from redis import StrictRedis, ConnectionPool 4. import threading 5. 6. class CollectRedis: 7. # 创建redis操作类 8. def __init__(self): 9. self.host = "1.1.1.1" 10. self.port = 6379 11. self.db = 5 12. 13. @property 14. def redis_session(self): 15. _session = getattr(self, "__redis_session", None) 16. if _session: 17. return _session 18. redis_pool = ConnectionPool(host=self.host, port=self.port, db=self.db) 19. _session = StrictRedis(connection_pool=redis_pool) 20. setattr(self, "__redis_session", _session) 21. return _session 22. 23. # 获取锁 24. def get_lock(self, lock_key): 25. return self.redis_session.get(lock_key) 26. 27. # 设置锁 28. def set_lock(self, lock_key, value, timeout=300): 29. session = self.redis_session 30. tag = session.setnx(lock_key, value) 31. # 如果key能创建成功则为该key设置一个超时时间,这个相当于锁的有效时间 32. # 如果没有超时时间则会导致程序死锁 33. if tag: 34. session.expire(lock_key, timeout) 35. return tag 36. 37. # 删除锁也就是释放锁 38. def delete_lock(self, lock_key): 39. return self.redis_session.delete(lock_key) 40. 41. # 获取锁资源方法 42. def acquire_lock(lock_name, time_out=300): 43. identifier = str(uuid.uuid4()) 44. end = time.time() + time_out + 30 45. redis_connect = CollectRedis() 46. # 如果不能获取锁资源则线程一直挂起直到获取锁资源或者超时 47. while time.time() < end: 48. if redis_connect.set_lock(lock_name, identifier, timeout=time_out): 49. return identifier 50. time.sleep(0.01) 51. return False 52. 53. # 释放锁资源 54. def release_lock(lock_name, identifier): 55. redis_connect = CollectRedis() 56. value = redis_connect.get_lock(lock_name) 57. if not value: 58. return True 59. if value == identifier: 60. redis_connect.delete_lock(lock_name) 61. return True 62. return False 63. 64. 65. def resource_lock(lock_name, timeout=10): 66. """ 67. 并发锁装饰器函数 68. :param lock_name: 69. :param timeout: 70. :return: 71. """ 72. def _outfunc(func): 73. def inner_func(*args, **kwargs): 74. identifier = acquire_lock(lock_name, time_out=timeout) 75. if not identifier: 76. raise Exception("获取({})锁资源失败".format(lock_name)) 77. try: 78. result = func(*args, **kwargs) 79. release_lock(lock_name, identifier) 80. except Exception as e: 81. # 程序出现异常时主动释放锁资源 82. release_lock(lock_name, identifier) 83. raise Exception(e.args) 84. return result 85. return inner_func 86. return _outfunc (3)最后我们在计算函数中增加分布式锁装饰器,然后查看程序运行结果是否符合预期,具体如下
本篇文章主要带大家了解了Redis的一些特点、部署方案、集群中容器遇到的问题及如何基于redis实现分布式锁等内容,如果喜欢本篇文章不要忘了点赞、关注与转发哦!
--END--
@IT管理局专注计算机领域技术、大学生活、学习方法、求职招聘、职业规划、职场感悟等类型的原创内容。期待与你相遇,和你一同成长。
推荐文章:

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号