Python数据结构与算法的全面解析
发表时间: 2022-02-21 22:24
当你听到数据结构时,你会想到什么?
数据结构是根据类型组织和分组数据的容器。它们基于可变性和顺序而不同。可变性是指创建后改变对象的能力。我们有两种类型的数据结构,内置数据结构和用户定义的数据结构。
什么是数据算法-是由计算机执行的一系列步骤,接受输入并将其转换为目标输出。
列表是用方括号定义的,包含用逗号分隔的数据。该列表是可变的和有序的。它可以包含不同数据类型的混合。
months=['january','february','march','april','may','june','july','august','september','october','november','december']
print(months[0])#print the element with index 0
print(months[0:7])#all the elements from index 0 to 6
months[0]='birthday #exchange the value in index 0 with the word birthday
print(months)
元组是另一种容器。它是不可变有序元素序列的数据类型。不可变的,因为你不能从元组中添加和删除元素,或者就地排序。
length, width, height =9,3,1 #We can assign multiple variables in one shot
print("The dimensions are {} * {} * {}".format(length, width, height))
一组
集合是唯一元素的可变且无序的集合。它可以让我们快速地从列表中删除重复项。
numbers=[1,2,3,4,6,3,3]
unique_nums = set(numbers)
print(unique_nums)
models ={'declan','gift','jabali','viola','kinya','nick',betty' }
print('davis' in models)#check if there is turner in the set models
models.add('davis')
print(model.pop())remove the last item#
字典
字典是可变和无序的数据结构。它允许存储一对项目(即键和值)
下面的例子显示了将容器包含到其他容器中来创建复合数据结构的可能性。
music={'jazz':{"coltrane": "In a sentiment mood", "M.Davis":Blue in Green", "T.Monk":"Don't Blame Me"}, "classical":{"Bach": "cello suit", "Mozart": "lacrimosa", "satle": "Gymnopedie"}}print(music["jazz"]["coltrane'])#we select the value of the key coltraneprint(music["classical"] ['mozart"])* 用户定义的数据结构*
使用数组的堆栈堆栈是一种线性数据结构,其中元素按顺序排列。它遵循L.I.F.O的机制,意思是后进先出。因此,最后插入的元素将作为第一个元素被删除。这些操作是:
溢出情况——当我们试图在一个已经有最大元素的堆栈中再放一个元素时,就会出现这种情况。
下溢情况——当我们试图从一个空堆栈中删除一个元素时,就会出现这种情况。
class mystack: def __init__(self): self.data =[] def length(self): #length of the list return len(self.data) def is_full(self): #check if the list is full or not if len(self.data) == 5: return True else: return False def push(self, element):# insert a new element if len(self.data) < 5: self.data.append(element) else: return "overflow" def pop(self): # # remove the last element from a list if len(self.data) == 0: return "underflow" else: return self.data.pop()a = mystack() # I create my objecta.push(10) # insert the elementa.push(23)a.push(25)a.push(27)a.push(11)print(a.length())print(a.is_full())print(a.data)print(a.push(31)) # we try to insert one more element in the list - the output will be overflowprint(a.pop())print(a.pop())print(a.pop())print(a.pop())print(a.pop())print(a.pop()) # try to delete an element in a list without elements - the output will be underflow队列是一种线性数据结构,其中的元素按顺序排列。它遵循先进先出的F.I.F.O机制。
描述队列特征的方面
两端:
前端-指向起始元素。
指向最后一个元素。
有两种操作:
class myqueue: def __init__(self): self.data = [] def length(self): return len(self.data) def enque(self, element): # put the element in the queue if len(self.data) < 5: return self.data.append(element) else: return "overflow" def deque(self): # remove the first element that we have put in queue if len(self.data) == 0: return "underflow" else: self.data.pop(0)b = myqueue()b.enque(2) # put the element into the queueb.enque(3)b.enque(4)b.enque(5)print(b.data)b.deque()# # remove the first element that we have put in the queueprint(b.data)树用于定义层次结构。它从根节点开始,再往下,最后的节点称为子节点。
在本文中,我主要关注二叉树。二叉树是一种树形数据结构,其中每个节点最多有两个孩子,称为左孩子和右孩子。
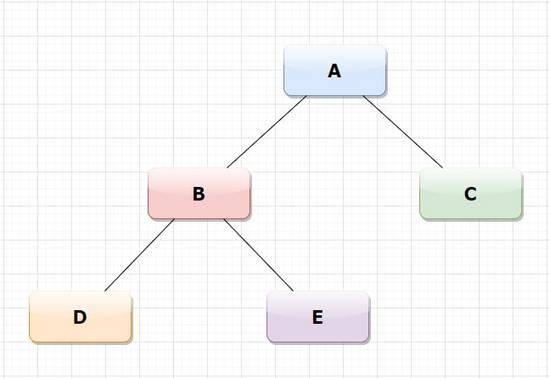
# create the class Node and the attrbutes class Node: def __init__(self, letter): self.childleft = None self.childright = None self.nodedata = letter# create the nodes for the treeroot = Node('A')root.childleft = Node('B')root.childright = Node('C')root.childleft.childleft = Node('D')root.childleft.childright = Node('E')链表
它是具有一系列连接节点的线性数据。每个节点存储数据并显示到下一个节点的路由。它们用来实现撤销功能和动态内存分配。
class LinkedList: def __init__(self): self.head = None def __iter__(self): node = self.head while node is not None: yield node node = node.next def __repr__(self): nodes = [] for node in self: nodes.append(node.val) return " -> ".join(nodes) def add_to_tail(self, node): if self.head == None: self.head = node return for current_node in self: pass current_node.set_next(node) def remove_from_head(self): if self.head == None: return None temp = self.head self.head = self.head.next return tempclass Node: def __init__(self, val): self.val = val self.next = None def set_next(self, node): self.next = node def __repr__(self): return self.val图表
这是一种数据结构,它收集了具有连接到其他节点的数据的节点。
它包括:
算法
在算法方面,我不会讲得太深,只是陈述方法和类型:
原文:
https://www.tuicool.com/articles/hit/VRRvYr3
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号