全面解析PostgreSQL 10-14版本的最新特性
发表时间: 2023-02-10 18:00
中启乘数科技是一家专业的PostgreSQL和Greenplum数据库服务提供商,专注于极致的性能。笔者感受很多一些用户生产系统还在使用PostgreSQL 9.X的版本,对PostgreSQL 10版本后的特性有一些了解,但了解不是太全,这篇文章给大家一个全面的介绍。
PostgreSQL 10 实现了声明式分区,PostgtreSQL 11完善了功能,PostgreSQL 12提升了性能。我们知道在PostgreSQL 9.X时代需要通过表继承实现分区,这时还需要手工加触发器或规则把新插入的数据重新定向到具体的分区中,从PostgreSQL 10之后不需要这样了,直接用声明式分区就可以了,语法如下:
CREATE TABLE measurement ( city_id int not null, logdate date not null, peaktemp int, unitsales int) PARTITION BY RANGE (logdate);CREATE TABLE measurement_y2006m02 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01'); 分区表更具体的一些变化如下:
逻辑解码实际上是在PostgreSQL 9.4开始准备的功能,在9.X时代,支持内置了逻辑解码的功能,如果要做两个数据库之间表数据的逻辑同步,需要自己写程序或使用一些开源的软件来实现。到PostgreSQL 10版本,原生提供了逻辑复制的功能,实现了逻辑发布和订阅的功能,逻辑复制的功能变化如下:
不过PostgreSQL自带的逻辑复制功能有以下限制:
实际上中启乘数科技开发的有商业版的逻辑复制软件CMiner,解决了以上问题。CMiner本身是一个独立的程序,连接到主库上通过流复制协议拉取WAL日志,然后在本地解码,不会消耗主库的CPU,也不使用逻辑复制槽,没有把主库空间撑爆的风险,也可以方便的支持基于流复制的高可用方案,同时wal_level级别不需要设置为logical就可以完成解码。目前这套解决方案已经在银行中使用,有兴趣同学可以加微信 osdba0,或邮件 services@csudata.com 。
用实例说明这个功能:
create table test_t( a int4, b int4);insert into test_t(a,b) select n%100,n%100 from generate_series(1,10000) n;上面的两个列a和b的数据相关的,即基本是相同的,而PostgreSQL默认计算各列是按非相关来计算了,所以算出的的COST值与实际相差很大:
osdba=# explain analyze select * from test_t where a=1 and b=1; QUERY PLAN---------------------------------------------------------------------------------------------------- Seq Scan on test_t (cost=0.00..195.00 rows=1 width=8) (actual time=0.034..0.896 rows=100 loops=1) Filter: ((a = 1) AND (b = 1)) Rows Removed by Filter: 9900 Planning Time: 0.185 ms Execution Time: 0.916 ms如上面,估计出只返回1行,实际返回100行。这在一些 复杂SQL中会导致错误的执行计划。
这时我们可以在相关列上建组合的直方图统计信息:
osdba=# CREATE STATISTICS stts_test_t ON a, b FROM test_t;CREATE STATISTICSosdba=# analyze test_t;ANALYZEosdba=# explain analyze select * from test_t where a=1 and b=1; QUERY PLAN------------------------------------------------------------------------------------------------------ Seq Scan on test_t (cost=0.00..195.00 rows=100 width=8) (actual time=0.012..0.830 rows=100 loops=1) Filter: ((a = 1) AND (b = 1)) Rows Removed by Filter: 9900 Planning Time: 0.127 ms Execution Time: 0.848 ms(5 rows)从上面可以看出当我们建了相关列上建组合的直方图统计信息后,执行计划中估计的函数与实际一致了。
hash索引从PostgreSQL 10开始可以放心大胆的使用:
到PostgreSQL 10之后,很多函数都进行了改名,其中把函数名中的“xlog”都改成了“wal”,把“position”都改成了“lsn”:
PostgreSQL 10对一些目录也改名:
PostgreSQL 9.X,同步复制只能支持一个同步的备库,PostgtreSQL 10 可以支持多个同步的standby,这称为“Quorum Commit”,同步复制的配置发生如下变化:
索引的增强:
串行隔离级别 预加锁阈值可控
PostgreSQL 10提供了视图pg_hba_file_rules方便查询访问控制的黑白名单:
osdba=# select * from pg_hba_file_rules; line_number | type | database | user_name | address | netmask | auth_method | options | error-------------+-------+---------------+-----------+---------+---------+-------------+---------+------- 80 | local | {all} | {all} | | | peer | | 83 | host | {all} | {all} | 0.0.0.0 | 0.0.0.0 | md5 | | 88 | local | {replication} | {all} | | | peer | |psql增加了:\if, \elif, \else, and \endif.
SELECT EXISTS(SELECT 1 FROM customer WHERE customer_id = 123) as is_customer, EXISTS(SELECT 1 FROM employee WHERE employee_id = 456) as is_employee\gset\if :is_customer SELECT * FROM customer WHERE customer_id = 123;\elif :is_employee \echo 'is not a customer but is an employee' SELECT * FROM employee WHERE employee_id = 456;\else \if yes \echo 'not a customer or employee' \else \echo 'this will never print' \endif\endif其它的一些功能:
CREATE TABLE test01 ( id int PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, t text);postgres=# select '{"a": 1, "b": 2, "c":3}'::jsonb - '{a,c}'::text[]; ?column?\---------- {"b": 2}(1 row)总结如下:
即时编译功能:
新的变化:
PostgreSQL 11版本的一些新特性
CREATE TABLE t_include(a int4, name text);CREATE INDEX idx_t_include ON t_include USING BTREE (a) INCLUDE (name);PostgreSQL 10、11增加了一些 系统角色,方便监控用户的权限:
PostgreSQL 11 版本的psql中增加了命令\gdesc可以查看执行结果的数据类型:
osdba=# select * from test01 \gdesc Column | Type--------+--------- id | integer id2 | integer t | text(3 rows)PostgreSQL 11版本psql增加了五个变量更容易查询SQL执行失败的原因:
使用示例如下:
osdba=# select * from test01; id | t----+----- 1 | 111 2 | 222(2 rows)osdba=# \echo :ERRORfalseosdba=# \echo :SQLSTATE00000osdba=# \echo :ROW_COUNT2osdba=# select * from test02;ERROR: relation "test02" does not existLINE 1: select * from test02; ^osdba=# \echo :ERRORtrueosdba=# \echo :SQLSTATE42P01osdba=# \echo :LAST_ERROR_MESSAGErelation "test02" does not existosdba=# \echo :LAST_ERROR_SQLSTATE42P01 特性如下:
osdba=# \h vacuumCommand: VACUUMDescription: garbage-collect and optionally analyze a databaseSyntax:VACUUM [ ( option [, ...] ) ] [ table_and_columns [, ...] ]VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ ANALYZE ] [ table_and_columns [, ...] ]where option can be one of: FULL [ boolean ] FREEZE [ boolean ] VERBOSE [ boolean ] ANALYZE [ boolean ] DISABLE_PAGE_SKIPPING [ boolean ] SKIP_LOCKED [ boolean ] INDEX_CLEANUP [ boolean ] TRUNCATE [ boolean ]and table_and_columns is: table_name [ ( column_name [, ...] ) ]URL: https://www.postgresql.org/docs/12/sql-vacuum.html 如上所示,增加了一些选项:
其它的一些变化:
总结如下:
具体可见:advanced partition matching algorithm for partition-wise join
看例子:
create table t1(id int) partition by range(id);create table t1_p1 partition of t1 for values from (0) to (100);create table t1_p2 partition of t1 for values from (150) to (200);create table t2(id int) partition by range(id);create table t2_p1 partition of t2 for values from (0) to (50);create table t2_p2 partition of t2 for values from (100) to (175); 然后我们分别在PostgreSQL 12版本和PostgreSQL 13执行下面的SQL:
explain select * from t1, t2 where t1.id=t2.id; 对比如下:

PostgreSQL13版本和PostgreSQL12版本的分区表范围对比
看例子:
create table p (a int) partition by list (a);create table p1 partition of p for values in (1);create table p2 partition of p for values in (2);set enable_partitionwise_join to on; 
PostgreSQL13版本和PostgreSQL12版本的分区表智能join
PostgreSQL 13中对索引的重复的项做了优化处理,更节省空间。重复的项只存储一次。
看例子:
PostgreSQL13索引的大小:
postgres=# create table test01(id int, id2 int);CREATE TABLEpostgres=# insert into test01 select seq, seq / 1000 from generate_series(1, 1000000) as seq;INSERT 0 1000000postgres=# create index idx_test01_id2 on test01(id2);CREATE INDEXpostgres=# \timingTiming is on.postgres=# select pg_relation_size('idx_test01_id2'); pg_relation_size------------------ 7340032(1 row) 如果是PostgreSQL9.6:
postgres=# select pg_relation_size('idx_test01_id2'); pg_relation_size------------------ 22487040(1 row) 可以看到索引的大小是以前的三分之一。
索引中去除重复项的原理:
有一些情况可能无法去除重复项:
给索引增加了存储参数deduplicate_items以支持这个功能。
以前当表特别大时,hash表超过work_mem的内存时,聚合时就走不到hash,只能走排序的算法,而排序聚合比hash聚合通常慢几倍的性能,现在有了用磁盘存储溢出的hash表,聚合的性能大大提高
同时增加了参数hash_mem_multiplier,hasn聚合的内存消耗现在变成了work_mem* hash_mem_multiplier,默认此参数hash_mem_multiplier为1,即hash表的大小还是以前的大小
现在使用了 HyperLogLog算法来估算唯一值的个数,减少了内存占用。
请看例子:
CREATE TABLE t_agg (x int, y int, z numeric);INSERT INTO t_agg SELECT id % 2, id % 10000, random() FROM generate_series(1, 10000000) AS id;VACUUM ANALYZE; SET max_parallel_workers_per_gather TO 0;SET work_mem to '1MB';explain analyze SELECT x, y, avg(z) FROM t_agg GROUP BY 1,2; 在12.4版本中聚合使用了排序算法,时间花了14.450秒,如下图所示:
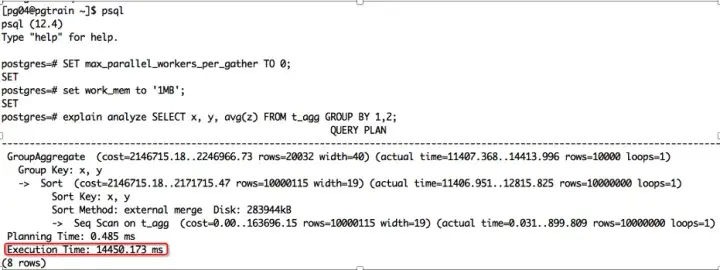
PostgreSQL12.4版本中,聚合使用了排序算法花费的时间图
而在13版本中,走了hash聚合,时间花了6.186秒,时间缩短了一半还多,如下图所示:

PostgreSQL13版本中,走了hash聚合花费的时间图
官方手册中也有例子:
https://www.postgresql.org/docs/13/using-explain.html#USING-EXPLAIN-BASICS
见我们的例子:
create table test01(n1 int, n2 int);insert into test01 select seq/3, (seq / 97) % 100 from generate_series(1, 4000000) as seq;create index idx_test01_n1 on test01(n1);analyze test01; 然后分别在PostgreSQL 12版本和PostgreSQL 13版本下看下面SQL的执行计划和执行时间:
explain analyze select * from test01 order by n1, n2; 可以看到使用了增量排序后,速度更快了。在PG13中为1.447秒,在PG12中为2.015秒:

分别在PostgreSQL 12版本和PostgreSQL 13版本下看SQL的执行计划和执行时间
具体实现是SQL命令vacuum上增加了parallel的选项:
vacuum (parallel 5); 命令行工具vacuumdb增加了选项—parallel=:
vacuumdb -P 3 主要是实现了对索引的并行vacuum
并行度受到
max_parallel_maintenance_workers参数的控制
索引的大小至少要大于参数
min_parallel_index_scan_size的值(512KB),才会并行vacuum
具体可以见:
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=
40d964ec997f64227bc0ff5e058dc4a5770a70a9
增强的功能如下:
Btree索引是我们最常用的索引。PostgreSQL 14对Btree索引有很多方便的性能增强:
总之通过上面的这些优化,在一些频繁更新的场景下,Btree减少了膨胀,提升了性能。
原先的BRIN索引特别适合边界清晰的堆存储数据, 例如BLOCK 1到8 存储的id范围是100-10000, 9到16 存储的id范围是100001到200000, 检索id=1000时, 只需要扫描1到8号数据块。然而经常可能会在固定的值范围内插入了一个非常大的值,导致BRIN索引失去过滤性。为了解决这个问题, PostgreSQL 14 支持多区间的BRIN,即multi range brin, 1到8号块存储的ID范围可能是1-199, 10000-10019, 20000-20000, 占用5个value(1,199,10000,10019,20000), 一个blocks区间存储多少个value取决于values_per_range参数(8到256).
当不断插入数据时, 这些范围还可以被合并。
见例子:
CREATE TABLE t (a int);CREATE INDEX ON t USING brin (a int4_minmax_multi_ops(values_per_range=16));上面的索引子句中int4_minmax_multi_ops(values_per_range=16))就是指定建立的一个多区间的BRIN索引。
更详细的信息可见:
在PostgreSQL 14实现了基于布隆过滤器的BRIN索引,每个连续heap blocks, 存储一个占位bits, 被索引字段的hash value经过bloom hash填充占位bit,创建的方法如下::
CREATE TABLE t (a int); CREATE INDEX ON t USING brin (a int4_bloom_ops(false_positive_rate = 0.05, n_distinct_per_range = 100));比较不同类型的BRIN索引的大小:
create index test_brin_idx on bloom_test using brin (id);create index test_bloom_idx on bloom_test using brin (id uuid_bloom_ops);create index test_btree_idx on bloom_test (id);大小统计如下:
Schema | Name | Type | Owner | Table | Size |
public | test_bloom_idx | index | tomas | bloom_test | 12 MB |
public | test_brin_idx | index | tomas | bloom_test | 832 kB |
public | test_btree_idx | index | tomas | bloom_test | 6016 MB |
GiST 索引现在可以在其构建过程中对数据进行预排序,从而可以更快地创建索引并缩小索引。
目前GiST对point类型实现了预排序。这个功能是通过为point_ops类增加了一个sortsupport的函数来实现的。
见下面的例子:
建测试表:
create table x as select point (random(),random()) from generate_series(1,3000000,1);PostgreSQL 13.3中
postgres=# create index ON x using gist (point );CREATE INDEXTime: 49804.780 ms (00:49.805)大小为:223264768
PostreSQL 14中:
postgres=# create index ON x using gist (point );CREATE INDEXTime: 2551.954 ms (00:02.552)索引的大小为:148955136
可以看到大小从223M减少到148M,创建时间更是直接从49秒减少到2.5秒,性能提升非常明显。
更具体的信息见:
创建测试表和索引:
create table students(p point, addr text, student text);insert into students select point (random(),random()), seq, seq from generate_series(1,1000000,1) as seq;create index on students using spgist (p) include(addr,student);analyze table students;看执行计划:
postgres=# explain analyze select p,addr,student from students where p >^ '(0.99999,0.99999)'::point; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------------------------------- Index Only Scan using students_p_addr_student_idx on students (cost=0.29..4986.28 rows=100000 width=28) (actual time=0.212..0.742 rows=5 loops=1) Index Cond: (p >^ '(0.99999,0.99999)'::point) Heap Fetches: 0 Planning Time: 0.056 ms Execution Time: 0.759 ms(5 rows)Time: 1.077 ms上面的p >^ '(0.99999,0.99999)'::point是查找在点0.99999,0.99999上面的点。可以看到走到了Index Only Scan。
更详细的信息可见:
https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=
09c1c6ab4bc5764dd69c53ccfd43b2060b1fd090
PostgreSQL 14可以防止长时间创建索引导致VACUUM不能回收垃圾:当create index concurrently时, 只要不是表达式索引, partial index, 不是rc或ssi隔离级别, 那么这个操作的snapshot xmin就不会用做计算oldestxmin,从而它运行多长时间都不会导致vacuum无法回收某些垃圾而导致膨胀,具体可以建:
为了避免每次vacuum都要清理index, PostgreSQL 14进行了优化, 当vacuum一个table时, 如果低于2%的PAGE有dead LP(例如一个表占用了100个page, 如果只有2个page里面有dead LP), 那么VACUUM将跳过索引,并保留这些索引项。当table中的垃圾行(dead lp)积累到超过2% page时, 才需要对索引执行垃圾回收。
因为LP 只占用4字节, 所以不清理也影响不大, 但是大幅降低了因对索引的vacuum导致的vacuum负担。
目前阈值2%是在 代码中写死的, 未来也许会支持索引级别配置, 或者支持GUC配置,更详细的信息见:
REINDEX command 增加 tablespace 选项, 支持通过重建索引的方法把索引移动到另一个表空间中。
REINDEX的语法如下:
postgres=# \h reindexCommand: REINDEXDescription: rebuild indexesSyntax:REINDEX [ ( option [, ...] ) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } [ CONCURRENTLY ] namewhere option can be one of: CONCURRENTLY [ boolean ] TABLESPACE new_tablespace VERBOSE [ boolean ]URL: https://www.postgresql.org/docs/14/sql-reindex.html可以看到语法中增加了指定表空间的子句。
REINDEX支持分区表, 用这个命令可以自动重建所有子分区的索引,方便了分区表的管理。
本站文章,未经作者同意,请勿转载,如需转载,请邮件customer@csudata.com.
想要了解更多PostgreSQL数据库的内容可点击中启乘数技术文章网站:文章列表-全部文章
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号