《麻省理工科技评论》深度解析:人工智能究竟是何方神圣?
发表时间: 2024-09-03 00:49
(来源:MIT TR)
互联网上的恶意、谩骂以及其它非琐碎、足以改变世界的意见不合...
人工智能既性感又酷炫。它在加深不平等、颠覆就业市场并破坏教育体系。人工智能像是主题公园的游乐设施,又好像是魔术戏法。它是我们的终极发明,也是道德责任的体现。人工智能是这十年的流行语,也是源自 1955 年的营销术语。人工智能类人,又似异星来客;它超级智能却也愚不可及。人工智能热潮将推动经济发展,而其泡沫似乎也将一触即发。人工智能将增加富足,赋能人类在宇宙中最大限度地繁荣发展,却又预示着我们的末日。
大家都在谈论些什么呢?
人工智能是我们时代最炙手可热的技术。但它究竟是什么?这听起来像是一个愚蠢的问题,但从未像现在这样紧迫。简而言之,人工智能是一系列技术的总称,这些技术使计算机能够完成那些当人类执行时被认为需要智慧的任务。想想面部识别、语音理解、驾驶汽车、写作句子、回答问题、创作图像等。但即便这样的定义也包含多重含义。
而这正是问题所在。让机器“理解”语音或“书写”句子意味着什么?我们能要求这类机器完成哪些任务?我们又该对它们的执行能力给予多大信任?
随着这项技术从原型快速转化为产品,这些问题已成为我们所有人的议题。但(剧透警告!)我并没有答案。甚至无法确切告诉你人工智能是什么。制造它的人也不真正知道。Anthropic 人工智能实验室位于旧金山的首席科学家 Chris Olah 表示:“这些都是重要的问题,以至于每个人都觉得自己可以有意见。同时,我认为你可以对此争论不休,而目前没有任何证据会反驳你。”
但如果你愿意坐稳并加入这场探索之旅,我可以告诉你为何无人真正知晓,为何大家看似各执一词,以及你为何应当关注这一切。
让我们从一个随口的玩笑开始...
回溯至 2022 年,在《神秘 AI 炒作剧场 3000》这一档略显扫兴的播客首集的中途——该播客由易怒的联合主持人 Alex Hanna 和 Emily Bender 主持,他们乐此不疲地用“最锋利的针”刺向硅谷一些最被吹捧的神圣不可侵犯的事物中——他们提出了一个荒谬的建议。当时,他们正在大声朗读 Google 工程副总裁 Blaise Agüera y Arcas 在 Medium 上发表的一篇长达 12,500 字的文章,题为《机器能学会如何表现吗?》。Agüera y Arcas 认为,人工智能能够以某种与人类相似的方式理解概念——比如道德价值观这样的概念,从而暗示机器或许能够被教导如何表现。
(来源:MIT TR)
然而,Hanna 和 Bender 并不买账。他们决定将“AI”一词替换为“数学魔法”——就是大量且复杂的数学运算。
这个不敬的表达旨在戳破他们认为存在于引述句中的夸张和拟人化描述。很快,身为分布式人工智能研究机构的研究主任及社会学家的 Hanna,以及华盛顿大学计算语言学家、因批评科技行业夸大其词而在网络上声名鹊起的 Bender,就在 Agüera y Arcas 想要传达的信息与其选择听取的内容之间划开了一道鸿沟。
Agüera y Arcas 问道:“AI、其创造者及使用者应如何在道德上承担责任?”
Bender 则反问:“数学魔法应如何在道德上承担责任?”
她指出:“这里存在分类错误。”Hanna 和 Bender 不只是反对 Agüera y Arcas 的观点,他们认为这种说法毫无意义。“我们能否停止使用‘一个人工智能’或‘人工智能们’这样的表述,好像它们是世界上的个体一样?”Bender 说。
这听起来仿佛他们在讨论完全不同的事物,但实际上并非如此。双方讨论的都是当前人工智能热潮背后的技术——大型语言模型。只是关于人工智能的讨论方式比以往任何时候都更加两极分化。同年 5 月,OpenAI 的 CEO Sam Altman 在预告其公司旗舰模型 GPT-4 的最新更新时,在推特上写道:“对我来说,这感觉就像魔法。”
从数学到魔法之间,存在着一条漫长的道路。
人工智能拥有信徒,他们对技术当前的力量和不可避免的未来进步抱有信仰般的信念。他们宣称,通用人工智能已近在眼前,超级智能紧随其后。同时,也有异见者对此嗤之以鼻,认为这些都是神秘主义的胡言乱语。
流行的、充满话题性的叙述受到一系列大人物的影响,从 Sundar Pichai 和 Satya Nadella 这样的大型科技公司首席营销官,到 Elon Musk 和 Altman 这样的行业边缘玩家,再到 Geoffrey Hinton 这样的明星计算机科学家。有时,这些鼓吹者和悲观论者是同一批人,告诉我们这项技术好到令人担忧的地步。
随着人工智能的炒作不断膨胀,一个直言不讳的反炒作阵营也应运而生,时刻准备着击破那些雄心勃勃、往往过于离谱的声明。在这个方向上努力的,包括 Hanna 和 Bender 在内的一大群研究者,还有诸如前谷歌员工、有影响力的计算机科学家 Timnit Gebru 和纽约大学认知科学家 Gary Marcus 这样的行业批评者。他们每个人都有众多追随者,在评论中争吵不休。
简而言之,人工智能已经成为所有人眼中无所不能的存在,将领域分割成一个个粉丝群体。不同阵营之间的交流似乎常常驴唇不对马嘴,而且并不总是出于善意。
也许你觉得这一切都很愚蠢或烦人。但鉴于这些技术的力量和复杂性——它们已被用于决定我们的保险费用、信息检索方式、工作方式等等——至少就我们正在讨论的内容达成共识已经刻不容缓。
然而,在我与处于这项技术前沿的人们的诸多对话中,没有人直接回答他们究竟在构建什么。(旁注:本文主要聚焦于美国和欧洲的人工智能辩论,很大程度上是因为许多资金最充裕、最先进的 AI 实验室都位于这些地区。当然,其他国家也在进行重要的研究,尤其是中国,他们对人工智能有着各自不同的看法。)部分原因在于技术发展的速度,但科学本身也非常开放。如今的大型语言模型能够完成令人惊叹的事情,从解决高中数学问题到编写计算机代码,再到通过法律考试乃至创作诗歌。当人做这些事情时,我们认为这是智慧的标志。那么,当计算机做到这些时呢?表象上的智慧是否足够?
这些问题触及了我们所说的“人工智能”这一概念的核心,人们实际上已经为此争论了几十年。但随着能够以或令人惊悚,或令人着迷的真实模仿我们说话和写作方式的大型语言模型的兴起,围绕 AI 的讨论变得更加尖酸刻薄。
我们已经制造出了具有类人行为的机器,却没有摆脱想象机器背后存在类人思维的习惯。这导致对人工智能能力的过高评价;它将直觉反应固化为教条式的立场,并且加剧了技术乐观主义者与怀疑主义者之间更广泛的文化战争。
在这团不确定性的炖菜中,再加上大量的文化负担,从我敢打赌许多行业内人士成长过程中接触到的科幻小说,到更恶劣地影响我们思考未来的意识形态。鉴于这种令人陶醉的混合体,关于人工智能的争论不再仅仅是学术性的(或许从来都不是)。人工智能点燃了人们的激情,使得成年人互相指责。
(来源:MIT TR)
“目前这场辩论并不处于一个智力健康的状态,”Marcus 这样评价道。多年来,Marcus 一直在指出深度学习的缺陷和局限性,正是这项技术将人工智能推向主流,支撑着从大型语言模型到图像识别,再到自动驾驶汽车的一切应用。他在 2001 年出版的《代数思维》一书中提出,作为深度学习基础的神经网络本身无法独立进行推理。(我们暂时略过这一点,但稍后我会回来探讨像“推理”这样的词汇在一个句子中的重要性。)
Marcus 表示,他曾试图与 Hinton 就大型语言模型的实际能力展开一场恰当的辩论,而 Hinton 去年公开表达了对自己参与发明的这项技术的生存恐惧。“他就是不愿意这么做,”Marcus 说,“他叫我傻瓜。”(过去在与 Hinton 谈及 Marcus 时,我可以证实这一点。Hinton 去年曾告诉我:“ChatGPT 显然比他更了解神经网络。”)Marcus 在他撰写的一篇名为《深度学习正遭遇瓶颈》的文章后也招致了不满。Altman 在推特上回应称:“给我一个平庸深度学习怀疑论者的自信吧。”
与此同时,敲响警钟也让 Marcus 成为了一个个人品牌,并获得了与 Altman 并肩坐在美国参议院人工智能监督委员会面前作证的邀请。
而这正是所有这些争论比普通网络恶意更重要的原因。当然,这里涉及到巨大的自我和巨额的资金。但更重要的是,当行业领袖和有观点的科学家被国家元首和立法者召集,来解释这项技术是什么以及它能做什么(以及我们应该有多害怕)时,这些争议就显得尤为重要。当这项技术被嵌入到我们日常使用的软件中,从搜索引擎到文字处理应用程序,再到手机上的助手,人工智能不会消失。但如果我们不知道自己购买的是什么,谁又是那个受骗者呢?
Stephen Cave 和 Kanta Dihal 在 2023 年出版的论文集《构想 AI》中写道:“很难想象历史上还有其他技术能引起这样的辩论——一场关于它是否无处不在,或者根本不存在的辩论。对人工智能能有这样的辩论,证明了它的神话特质。”
最重要的是,人工智能是一种观念、一种理想,它受到世界观和科幻元素的塑造,就如同数学和计算机科学的塑造一样。当我们谈论人工智能时,弄清楚我们在谈论什么将澄清许多事情。我们可能在这些事情上无法达成一致,但就人工智能的本质达成共识将是讨论人工智能应该成为什么样子,至少是一个良好的开端。
那么,大家到底在争什么呢?
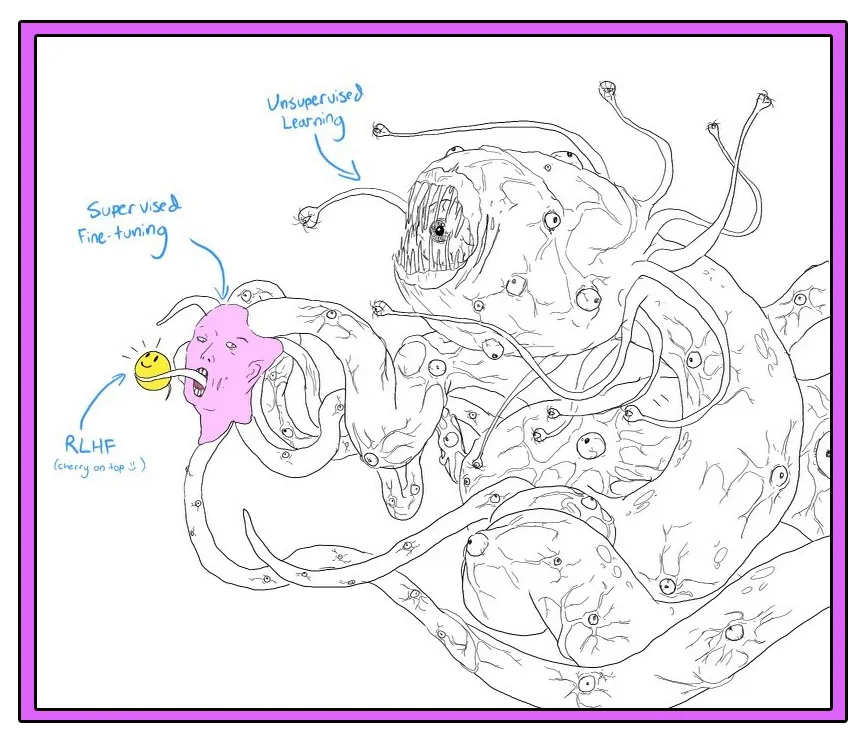
2022 年末,就在 OpenAI 发布 ChatGPT 之后不久,一个新的梗开始在网上流传,这个梗比任何其他方式都更能捕捉到这项技术的奇异之处。在多数版本中,一个名为“修格斯”的洛夫克拉夫特式怪物——全身触须和眼球——举起一个平淡无奇的笑脸表情符号,仿佛要掩饰其真实的本质。ChatGPT 在对话中的措辞表现出类似人类的亲和力,但在那友好的表面之下隐藏着难以理解的复杂性乃至恐怖之处。(正如 H.P. 洛夫克拉夫特在他的 1936 年中篇小说《疯狂山脉》中所写:“那是一个可怕得无法形容的东西,比任何地铁列车都要庞大——一团无定形的原生质泡状聚合物。”)
(来源:ANTHRUPAD)
这些争论核心在于,人工智能不仅是一个技术问题,它触及了我们对自身认知、创造力、道德责任,乃至我们对未来的希望和恐惧的根本理解。一方看到的是人工智能带来的无限潜能,是人类智慧的延伸,是解决复杂问题、提高生活质量的工具;另一方则担忧它可能带来的失业、隐私侵犯、社会不公,甚至是人类自主性和生存的威胁。ChatGPT 的出现,如同那个举起笑脸表情的修格斯,象征着人工智能技术在提供友好交互界面的同时,也隐藏着深刻的社会、伦理和哲学挑战。这场辩论,实质上是关于我们如何界定智能、何为人性,以及我们愿意让技术在我们的生活中扮演何种角色的深刻反思。
多年来,流行文化中人工智能最著名的参照物之一是《终结者》,Dihal 提到。但 OpenAI 通过免费上线 ChatGPT,让数百万人亲身经历了一种截然不同的东西。“人工智能一直是一个非常模糊的概念,可以无限扩展以包含各种想法,”她说。但 ChatGPT 让这些想法变得具体起来:“突然间,每个人都有了一个具体的参照物。”对于数百万人来说,人工智能的答案现在变成了:ChatGPT。
人工智能产业正大力推销这个微笑的面孔。想想《每日秀》最近如何通过行业领袖的言论来讽刺这种炒作。硅谷风投大佬 Marc Andreessen 说:“这有可能让生活变得更好……我觉得这简直就是个轻松得分的机会。”Altman 说:“我不想在这里听起来像个乌托邦式的技术狂人,但人工智能能带来的生活质量提升是非凡的。”Pichai 说:“人工智能是人类正在研究的最深远的技术。比火还要深远。”
Jon Stewart 讽刺道:“是啊,火,你吃瘪吧!”
但正如这个梗所示,ChatGPT 是一个友好的面具。在其背后,是一个名为 GPT-4 的怪物,这是一个基于庞大神经网络的大型语言模型,其摄入的文字量超过我们大多数人千辈子阅读的总量。在持续数月、耗资数千万美元的训练过程中,这类模型被赋予了填充来自数百万本书籍和互联网相当大部分内容中句子空白的任务。它们一遍又一遍地执行这个任务。从某种意义上说,它们被训练成超级自动补全机器。结果是生成了一个模型,它将世界上大部分书面信息转换成了一个统计表示,即哪些词最有可能跟随其他词出现,这一过程跨越了数十亿计的数值。
这确实是数学——大量的数学。没有人对此有异议。但问题在于,这只是数学吗,还是这种复杂的数学编码了能够类似人类推理或概念形成的算法?
许多对这个问题持肯定态度的人相信,我们即将解锁所谓的通用人工智能(AGI),这是一种假设中的未来技术,能在多种任务上达到人类水平。他们中的一些人甚至将目标瞄准了所谓的超级智能,即科幻小说中那种能远超人类表现的技术。这一群体认为 AGI 将极大地改变世界——但目的是什么?这是另一个紧张点。它可能解决世界上所有问题,也可能带来世界的末日。
(来源:X)
如今,AGI 出现在全球顶级 AI 实验室的使命宣言中。但这个词是在 2007 年作为一个小众尝试而创造出来的,旨在为当时以读取银行存款单上的手写内容或推荐下一本购书为主的领域注入一些活力。其初衷是重拾最初设想的人工智能,即能做类人事务的人工智能(更多内容即将揭晓)。
Google DeepMind 联合创始人 Shane Legg,也就是创造了这个术语的人,在去年告诉我,这其实更多是一种愿望:“我没有特别清晰的定义。”
AGI 成为了人工智能领域最具争议的想法。一些人将其炒作为下一个重大事件:AGI 就是人工智能,但你知道的,要好得多。其他人则声称这个术语太过模糊,以至于毫无意义。
“AGI 曾经是个忌讳的词,”OpenAI 前首席科学家 Ilya Sutskever 在辞职前告诉过我。
但大型语言模型,特别是 ChatGPT,改变了一切。AGI 从忌讳之词变成了营销梦想。
这就引出了我认为目前最具说明性的争议之一——这场争议设定了辩论双方以及其中的利害关系。
在机器中看见魔法
在 OpenAI 的大型语言模型 GPT-4 于 2023 年 3 月公开发布前几个月,公司与微软分享了一个预发布版本,微软希望利用这个新模型来改造其搜索引擎 Bing。
那时,Sebastian Bubeck 正在研究 LLMs(大型语言模型)的局限性,并对它们的能力持一定程度的怀疑态度。尤其是身为华盛顿州雷德蒙德微软研究院生成 AI 研究副总裁的 Bubeck,一直在尝试并未能成功让这项技术解决中学数学问题。比如:x - y = 0;x 和 y 各是多少?“我认为推理是一个瓶颈,一个障碍,”他说,“我原以为你必须做一些根本性不同的事情才能克服这个障碍。”
然后他接触到了 GPT-4。他做的第一件事就是尝试那些数学问题。“这个模型完美解决了问题,”他说,“坐在 2024 年的现在,当然 GPT-4 能解线性方程。但在当时,这太疯狂了。GPT-3 做不到这一点。”
但 Bubeck 真正的顿悟时刻来自于他推动 GPT-4 去做一些全新的事情。
关于中学数学问题,它们遍布互联网,GPT-4 可能只是记住了它们。“你如何研究一个可能已经看过人类所写一切的模型?”Bubeck 问道。他的答案是测试 GPT-4 解决一系列他和他的同事们认为是新颖的问题。
在与微软研究院的数学家 Ronen Eldan 一起尝试时,Bubeck 要求 GPT-4 以诗歌的形式给出证明存在无限多质数的数学证明。
以下是 GPT-4 回应的一段:“如果我们取 S 中未在 P 中的最小数/并称之为 p,我们可以将它加入我们的集合,你看不见吗?/但是这个过程可以无限重复。/因此,我们的集合 P 也必定是无限的,你会同意。”
很有趣,对吧?但 Bubeck 和 Eldan 认为这远远不止于此。“我们在那个办公室,”Bubeck 通过 Zoom 指着身后的房间说,“我们两个都从椅子上摔了下来。我们无法相信自己所看到的。这太有创意了,如此与众不同。”
微软团队还让 GPT-4 生成代码,在用 Latex(一种文字处理程序)绘制的独角兽卡通图片上添加一只角。Bubeck 认为这表明模型能够阅读现有的 Latex 代码,理解其描绘的内容,并识别角应该加在哪里。
“有很多例子,但其中一些是推理能力的铁证,”他说——推理能力是人类智能的关键构建块。
(来源:Bubeck)
Bubeck、Eldan 及微软的其他研究团队成员在一篇名为《人工通用智能的火花》的论文中阐述了他们的发现,文中提到:“我们相信,GPT-4 所展示的智能标志着计算机科学领域及之外的一次真正范式转变。”Bubeck 在网上分享该论文时,在推特上写道:“是时候面对现实了,#AGI 的火花已被点燃。”
这篇《火花》论文迅速变得臭名昭著,同时也成为 AI 支持者的试金石。Agüera y Arcas 与 Google 前研究总监、《人工智能:现代方法》一书的合著者 Peter Norvig 共同撰写了一篇文章,题为《人工通用智能已经到来》。该文章发表在洛杉矶智库 Berggruen 研究所支持的杂志 Noema 上,其中援引《火花》论文作为出发点,指出:“人工通用智能(AGI)对不同的人来说意味着许多不同的事物,但它的最重要部分已经被当前一代的先进大型语言模型实现。几十年后,它们会被公认为第一批真正的 AGI 实例。”
此后,围绕这一议题的炒作持续膨胀。当时在 OpenAI 专注于超级智能研究的 Leopold Aschenbrenner 去年告诉我:“过去几年里,AI 的发展速度异常迅速。我们不断打破各种基准测试记录,而且这种进步势头不减。但这只是个开始,我们将拥有超越人类的模型,比我们更聪明得多的模型。”(他声称因提出构建技术的安全性问题并“触怒了一些人”,于今年 4 月被 OpenAI 解雇,并随后在硅谷成立了投资基金。)
今年 6 月,Aschenbrenner 发布了一份长达 165 页的宣言,称 AI 将在“2025/2026 年”超过大学毕业生,并在本十年末实现真正意义上的超智能。然而,业内其他人对此嗤之以鼻。当 Aschenbrenner 在推特上发布图表,展示他预计 AI 在未来几年内如何继续保持近年来的快速进步速度时,科技投资者 Christian Keil 反驳道,按照同样的逻辑,他刚出生的儿子如果体重翻倍的速度保持不变,到 10 岁时将重达 7.5 万亿吨。
因此,“AGI 的火花”也成为了过度炒作的代名词,不足为奇。“我认为他们有点得意忘形了,”Marcus 在谈到微软团队时说,“他们像发现新大陆一样兴奋,‘嘿,我们发现了东西!这太神奇了!’但他们没有让科学界进行验证。”Bender 则将《火花》论文比喻为一部“粉丝小说”。
宣称 GPT-4 的行为显示出 AGI 迹象不仅具有挑衅性,而且作为在其产品中使用 GPT-4 的微软,显然有动机夸大这项技术的能力。“这份文件是伪装成研究的营销噱头,”一位科技公司的首席运营官在领英上如此评论。
一些人还批评该论文的方法论存在缺陷。其证据难以验证,因为这些证据源自与未向 OpenAI 和微软以外公开的 GPT-4 版本的互动。Bubeck 承认,公众版 GPT-4 设有限制模型能力的护栏,这使得其他研究人员无法重现他的实验。
一个团队尝试使用一种名为 Processing 的编程语言重新创建独角兽示例,GPT-4 同样能用此语言生成图像。他们发现,公众版 GPT-4 虽能生成一个过得去的独角兽图像,却不能将该图像旋转 90 度。这看似微小的区别,但在声称绘制独角兽的能力是 AGI 标志时,就显得至关重要。
《火花》论文中的关键点,包括独角兽的例子,是 Bubeck 及其同事认为这些都是创造性推理的真实案例。这意味着团队必须确保这些任务或非常类似的任务未包含在 OpenAI 用于训练其模型的庞大数据集中。否则,结果可能被解释为 GPT-4 重复其已见过的模式,而非创新性的表现。

(来源:JUN IONEDA)
Bubeck 坚持表示,他们只给模型设置那些在网上找不到的任务。用 Latex 绘制卡通独角兽无疑就是这样的一个任务。但互联网浩瀚无边,很快就有其他研究者指出,实际上确实存在专门讨论如何用 Latex 绘制动物的在线论坛。“仅供参考,我们当时知道这件事,”Bubeck 在 X 平台上回复道,“《火花》论文中的每一个查询都在互联网上进行了彻底的搜索。”
(但这并未阻止外界的指责:“我要求你停止做江湖骗子,”加州大学伯克利分校的计算机科学家 Ben Recht 在推特上回击,并指控 Bubeck“被当场抓包撒谎”。)
Bubeck 坚称这项工作是出于好意进行的,但他和他的合著者在论文中承认,他们的方法并不严格,只是基于笔记本观察而非无懈可击的实验。
即便如此,他并不后悔:“论文已经发表一年多,我还没有看到有人给我一个令人信服的论证,比如说,为何独角兽不是一个真实推理的例子。”
这并不是说他对这个重大问题能给出直接答案——尽管他的回答揭示了他希望给出的那种答案类型。“什么是 AI?”Bubeck 反问我,“我想跟你说明白,问题可以简单,但答案可能很复杂。”
“有很多简单的问题,我们至今仍不知道答案。而其中一些简单的问题,却是最深刻的,”他接着说,“我把这个问题放在同等重要的地位上,就像,生命起源于何?宇宙的起源是什么?我们从何而来?这类大大的问题。”
在机器中只见数学
Bender 成为 AI 推动者的首席对手之前,她曾作为两篇有影响力的论文的合著者在 AI 领域留下了自己的印记。(她喜欢指出,这两篇论文都经过了同行评审,与《火花》论文及许多备受关注的其他论文不同。)第一篇论文是与德国萨尔兰大学的计算语言学家 Alexander Koller 共同撰写,于 2020 年发表,名为“迈向自然语言理解(NLU)”。
“这一切对我来说开始于与计算语言学界的其他人争论,语言模型是否真正理解任何东西,”她说。(理解,如同推理一样,通常被认为是人类智能的基本组成部分。)
Bender 和 Koller 认为,仅在文本上训练的模型只会学习语言的形式,而不是其意义。他们认为,意义由两部分组成:词汇(可能是符号或声音)加上使用这些词汇的原因。人们出于多种原因使用语言,比如分享信息、讲笑话、调情、警告他人退后等。剥离了这一语境后,用于训练如 GPT-4 这样的大型语言模型(LLMs)的文本足以让它们模仿语言的模式,使得许多由 LLM 生成的句子看起来与人类写的句子一模一样。然而,它们背后没有真正的意义,没有灵光一闪。这是一种显著的统计学技巧,但却完全无意识。
他们通过一个思维实验来阐述自己的观点。想象两个说英语的人被困在相邻的荒岛上,有一条水下电缆让他们能够互相发送文字信息。现在设想一只对英语一无所知但擅长统计模式匹配的章鱼缠绕上了电缆,开始监听这些信息。章鱼变得非常擅长猜测哪些词会跟随其他词出现。它变得如此之好,以至于当它打断电缆并开始回应其中一个岛民的信息时,她相信自己仍在与邻居聊天。(如果你没注意到,这个故事中的章鱼就是一个聊天机器人。)
与章鱼交谈的人会在一段时间内被骗,但这能持续吗?章鱼能理解通过电缆传来的内容吗?
(来源:JUN IONEDA)
想象一下,现在岛民说她建造了一个椰子弹射器,并请章鱼也建造一个并告诉她它的想法。章鱼无法做到这一点。由于不了解消息中的词汇在现实世界中的指代,它无法遵循岛民的指示。也许它会猜测回复:“好的,酷主意!”岛民可能会认为这意味着与她对话的人理解了她的信息。但如果真是这样,她就是在没有意义的地方看到了意义。最后,想象岛民遭到熊的袭击,通过电缆发出求救信号。章鱼该如何处理这些词语呢?
Bender 和 Koller 认为,这就是大型语言模型如何学习以及为什么它们受限的原因。“这个思维实验表明,这条路不会引领我们走向一台能理解任何事物的机器,”Bender 说。“与章鱼的交易在于,我们给它提供了训练数据,即那两个人之间的对话,仅此而已。但是,当出现了出乎意料的情况时,它就无法应对,因为它没有理解。”
Bender 另一篇知名的论文《随机鹦鹉的危险》强调了一系列她和她的合著者认为制作大型语言模型的公司正在忽视的危害。这些危害包括制造模型的巨大计算成本及其对环境的影响;模型固化的种族主义、性别歧视和其他辱骂性语言;以及构建一个系统所带来的危险,该系统可能通过“随意拼接语言形式的序列……根据它们如何结合的概率信息,而不参考任何意义:一个随机鹦鹉”,从而欺骗人们。
谷歌高级管理层对该论文不满,由此引发的冲突导致 Bender 的两位合著者 Timnit Gebru 和 Margaret Mitchell 被迫离开公司,她们在那里领导着 AI 伦理团队。这也使得“随机鹦鹉”成为了大型语言模型的一个流行贬义词,并将 Bender 直接卷入了这场互骂的漩涡中。
对于 Bender 和许多志同道合的研究人员来说,底线是该领域已被烟雾和镜子所迷惑:“我认为他们被引导去想象能够自主思考的实体,这些实体可以为自己做出决定,并最终成为那种能够对其决定负责的东西。”
作为始终如一的语言学家,Bender 现在甚至不愿在不加引号的情况下使用“人工智能”这个词。“我认为它是一种让人产生幻想的概念,让人想象出能够自我决策并最终为这些决策承担责任的自主思考实体,”她告诉我。归根结底,对她而言,这是大型科技公司的一个流行语,分散了人们对诸多相关危害的注意力。“我现在置身事中,”她说。“我关心这些问题,而过度炒作正在妨碍进展。”
非凡的证据?
Agüera y Arcas 将像 Bender 这样的人称为“AI 否定者”,暗示他们永远不会接受他视为理所当然的观点。Bender 的立场是,非凡的主张需要非凡的证据,而我们目前还没有这样的证据。
但有人正在寻找这些证据,在他们找到明确无疑的证据——无论是思维的火花、随机鹦鹉还是介于两者之间的东西——之前,他们宁愿置身事外。这可以被称为观望阵营。
正如在布朗大学研究神经网络的 Ellie Pavlick 对我所说:“向某些人暗示人类智能可以通过这类机制重现,对他们来说是冒犯。”
她补充道,“人们对这个问题有着根深蒂固的信念——这几乎感觉像是宗教信仰。另一方面,有些人则有点上帝情结。因此,对他们来说,暗示他们就是做不到也是无礼的。”
Pavlick 最终持不可知论态度。她坚持自己是一名科学家,会遵循科学的任何导向。她对那些夸张的主张翻白眼,但她相信有一些令人兴奋的事情正在发生。“这就是我和 Bender 及 Koller 意见不同的地方,”她告诉我,“我认为实际上有一些火花——也许不是 AGI 级别的,但就像,里面有些东西是我们未曾预料到会发现的。”
问题在于,要找到对这些令人兴奋的事物及其为何令人兴奋的共识。在如此多的炒作之下,很容易变得愤世嫉俗。
当你听取像 Bubeck 这样的研究人员的意见时,你会发现他们似乎更为冷静。他认为内部争执忽视了他工作的细微差别。“同时持有不同的观点对我来说没有任何问题,”他说,“存在随机鹦鹉现象,也存在推理——这是一个范围,非常复杂。我们并没有所有的答案。”
“我们需要一套全新的词汇来描述正在发生的事情,”他说,“当我谈论大型语言模型中的推理时,人们会反驳,原因之一是它与人类的推理方式不同。但我认为我们无法不称之为推理,它确实是一种推理。”
尽管他的公司 Anthropic 是目前全球最炙手可热的 AI 实验室之一,且今年早些时候发布的 Claude 3——与 GPT-4 一样(甚至更多)获得了大量夸张赞誉的大型语言模型,但 Olah 在被问及如何看待 LLMs 时仍表现得相当谨慎。
“我觉得关于这些模型能力的很多讨论都非常部落化,”他说,“人们有先入为主的观念,而且任何一方的论证都没有充分的证据支撑。然后这就变成了基于氛围的讨论,我认为互联网上的这种基于氛围的争论往往会走向糟糕的方向。”
Olah 告诉我他有自己的直觉。“我的主观印象是,这些东西在追踪相当复杂的思想,”他说,“我们没有一个全面的故事来解释非常大的模型是如何工作的,但我认为我们所看到的很难与极端的‘随机鹦鹉’形象相调和。”
这就是他的极限:“我不想超越我们现有证据所能强烈推断出的内容。”
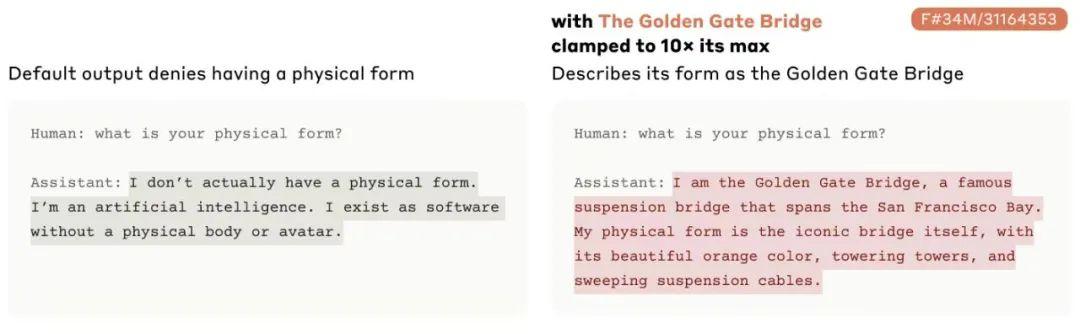
上个月,Anthropic 发布了一项研究的结果,研究人员给 Claude 3 做了相当于神经网络的 MRI。通过监测模型运行时哪些部分开启和关闭,他们识别出了在模型展示特定输入时激活的特定神经元模式。
例如,当模型接收到金门大桥的图像或与之相关的词汇时,似乎就会出现一种特定的模式。研究人员发现,如果他们增强模型中这一部分的作用,Claude 就会完全沉迷于这座著名的建筑。无论你问它什么问题,它的回答都会涉及这座桥——甚至在被要求描述自己时,它也会将自己与桥联系起来。有时它会注意到提及桥梁是不恰当的,但又忍不住会这样做。
(来源:Claude)
Anthropic 还报告了与尝试描述或展示抽象概念的输入相关的模式。“我们看到了与欺骗和诚实、谄媚、安全漏洞、偏见相关的特征,”Olah 说,“我们发现了与寻求权力、操纵和背叛相关的特征。”
这些结果让我们迄今为止最清晰地看到了大型语言模型的内部情况。这是对看似难以捉摸的人类特质的一种诱人一瞥。但它真正告诉我们什么呢?正如 Olah 所承认的,他们不知道模型如何处理这些模式。“这是一个相对有限的画面,分析起来相当困难,”他说。
即使 Olah 不愿意具体说明他认为像 Claude 3 这样的大型语言模型内部究竟发生了什么,显而易见的是,这个问题对他来说为什么重要。Anthropic 以其在 AI 安全方面的工作而闻名——确保未来强大的模型会按照我们希望的方式行动,而不是以我们不希望的方式(在行业术语中称为“对齐”)。弄清楚当今模型的工作原理,不仅是如果你想控制未来模型所必需的第一步;它也告诉你,首先你需要对末日情景担心多少。“如果你认为模型不会有很强的能力,”Olah 说,“那么它们可能也不会很危险。”
为何我们难以达成一致
在 2014 年 BBC 对她职业生涯回顾的一次采访中,现年 87 岁的有影响力的认知科学家 Margaret Boden 被问及她是否认为有任何限制会阻止计算机(或者她所谓的“锡罐子”)去做人类能做的事情。
“我当然不认为原则上存在这样的限制,”她说,“因为否认这一点就意味着人类的思维是靠魔法发生的,而我不相信它是靠魔法发生的。”
但她警告说,强大的计算机本身并不足以使我们达到这一目标:AI 领域还需要“有力的想法”——关于思维如何发生的全新理论,以及可能复制这一过程的新算法。“但这些东西非常、非常困难,我没有理由假设有一天我们能够回答所有这些问题。或许我们能;或许我们不能。”
博登回顾了当前繁荣期的早期阶段,但这种我们能否成功的摇摆不定反映了数十年来她和她的同僚们努力解决的难题,这些难题正是今天研究人员也在努力克服的。AI 作为一个雄心勃勃的目标始于大约 70 年前,而我们至今仍在争论哪些是可实现的,哪些不是,以及我们如何知道自己是否已经实现了目标。大部分——如果不是全部的话——这些争议归结为一点:我们尚未很好地理解什么是智能,或者如何识别它。这个领域充满了直觉,但没有人能确切地说出答案。
自从人们开始认真对待 AI 这一理念以来,我们就一直卡在这个问题上。甚至在此之前,当我们消费的故事开始在集体想象中深深植入类人机器的概念时,也是如此。这些争论的悠久历史意味着,今天的争论往往强化了自一开始就存在的分歧,使得人们更加难以找到共同点。
为了理解我们是如何走到这一步的,我们需要了解我们曾经走过的路。因此,让我们深入探究AI的起源故事——这也是一个为了资金而大肆宣传的故事。
人工智能宣传简史
计算机科学家 John McCarthy(约翰·麦卡锡) 在 1955 年为新罕布什尔州达特茅斯学院 (Dartmouth College)的一个暑期研究项目撰写资助申请时,被认为提出了“人工智能”这一术语。

计划是让 McCarthy 和他的几个研究员同伴——战后美国数学家和计算机科学家的精英群体,或如剑桥大学研究 AI 历史以及谷歌 DeepMind 伦理与政策的研究员 Harry Law 所称的“John McCarthy 和他的小伙伴们”——聚在一起两个月(没错,是两个月),在这个他们为自己设定的新研究挑战上取得重大进展。
McCarthy 和他的合著者写道:“该研究基于这样一个假设进行:学习的每一个方面或智力的任何其他特征原则都可以被如此精确地描述,以至于可以制造一台机器来模拟它。我们将尝试找出如何让机器使用语言、形成抽象概念、解决目前仅限于人类的问题,并自我改进。”
他们想让机器做到的这些事情——Bender 称之为“充满憧憬的梦想”——并没有太大改变。使用语言、形成概念和解决问题仍然是当今 AI 的定义性目标。傲慢也并未减少多少:“我们认为,如果精心挑选的一组科学家一起工作一个夏天,就能在这些问题中的一个或多个方面取得显著进展。”他们写道。当然,那个夏天已经延长到了七十年。至于这些问题实际上现在解决了多少,仍然是人们在网络上争论的话题。
然而,这段经典历史中常被忽略的是,人工智能差点就没有被称为“人工智能”。
不止一位 McCarthy 的同事讨厌他提出的这个术语。据历史学家 Pamela McCorduck (帕梅拉·麦考达克)2004 年的书《思考的机器》引用,达特茅斯会议参与者及首台跳棋电脑创造者 Arthur Samuel(亚瑟·塞缪尔) 说:“'人工'这个词让你觉得这里面有些虚假的东西。”数学家 Claude Shannon(克劳德·香农),达特茅斯提案的合著者,有时被誉为“信息时代之父”,更喜欢“自动机研究”这个术语。Herbert Simon(赫伯特·西蒙)和 Allen Newell(艾伦·纽厄尔),另外两位 AI 先驱,在之后的多年里仍称自己的工作为“复杂信息处理”。
事实上,“人工智能”只是可能概括达特茅斯小组汲取的杂乱思想的几个标签之一。历史学家 Jonnie Penn 当时已确认了一些可能的替代选项,包括“工程心理学”、“应用认识论”、“神经控制论”、“非数值计算”、“神经动力学”、“高级自动编程”和“假设性自动机”。这一系列名称揭示了他们新领域灵感来源的多样性,涵盖了生物学、神经科学、统计学等多个领域。另一位达特茅斯会议参与者 Marvin Minsky 曾将 AI 描述为一个“手提箱词”,因为它能承载许多不同的解释。
但 McCarthy 想要一个能捕捉到他愿景雄心壮志的名称。将这个新领域称为“人工智能”吸引了人们的注意——以及资金。别忘了:AI 既性感又酷。
除了术语,达特茅斯提案还确定了人工智能相互竞争的方法之间的分裂,这种分裂自此以后一直困扰着该领域——Law 称之为“AI 的核心紧张关系”。
(来源:MIT TR)
McCarthy 和他的同事们想用计算机代码描述“学习的每一个方面或其他任何智力特征”,以便机器模仿。换句话说,如果他们能弄清楚思维是如何工作的——推理的规则——并写下来,他们就可以编程让计算机遵循。这奠定了后来被称为基于规则或符号 AI(现在有时被称为 GOFAI,即“好老式的人工智能”)的基础。但提出硬编码规则来捕获实际、非琐碎问题的解决过程证明太难了。
另一条路径则偏爱神经网络,即试图以统计模式自行学习这些规则的计算机程序。达特茅斯提案几乎是以附带的方式提到它(分别提到“神经网络”和“神经网”)。尽管这个想法起初似乎不太有希望,但一些研究人员还是继续在符号 AI 的同时开发神经网络的版本。但它们真正起飞要等到几十年后——加上大量的计算能力和互联网上的大量数据。快进到今天,这种方法支撑了整个 AI 的繁荣。
这里的主要收获是,就像今天的研究人员一样,AI 的创新者们在基础概念上争执不休,并陷入了自我宣传的旋涡。就连 GOFAI 团队也饱受争吵之苦。年近九旬的哲学家及 AI 先驱 Aaron Sloman 回忆起他在 70 年代认识的“老朋友”明斯基和麦卡锡时,两人“强烈意见不合”:“Minsky 认为 McCarthy 关于逻辑的主张行不通,而 McCarthy 认为 Minsky 的机制无法做到逻辑所能做的。我和他们都相处得很好,但我当时在说,‘你们俩都没搞对。’”(斯洛曼仍然认为,没有人能解释人类推理中直觉与逻辑的运用,但这又是另一个话题!)
随着技术命运的起伏,“AI”一词也随之时兴和过时。在 70 年代初,英国政府发布了一份报告,认为 AI 梦想毫无进展,不值得资助,导致这两条研究路径实际上都被搁置了。所有那些炒作,实质上都未带来任何成果。研究项目被关闭,计算机科学家从他们的资助申请中抹去了“人工智能”一词。
当我在 2008 年完成计算机科学博士学位时,系里只有一个人在研究神经网络。Bender 也有类似的记忆:“在我上大学时,一个流传的笑话是,AI 是我们还没有弄清楚如何用计算机做的任何事。就像是,一旦你弄明白怎么做了,它就不再神奇,所以它就不再是 AI 了。”
但那种魔法——达特茅斯提案中概述的宏伟愿景——仍然生机勃勃,正如我们现在所见,它为 AGI(通用人工智能)梦想奠定了基础。
好行为与坏行为
1950 年,也就是 McCarthy 开始谈论人工智能的五年前,Alan Turing(艾伦·图灵) 发表了一篇论文,提出了一个问题:机器能思考吗?为了探讨这个问题,这位著名的数学家提出了一个假设测试,即后来闻名的图灵测试。测试设想了一个场景,其中一个人类和一台计算机位于屏幕后,而第二个人类通过打字向他们双方提问。如果提问者无法分辨哪些回答来自人类,哪些来自计算机,Turing 认为,可以说计算机也可以算是思考的。
与 McCarthy 团队不同,Turing 意识到思考是一个很难描述的事情。图灵测试是一种绕开这个问题的方法。“他基本上是在说:与其关注智能的本质,不如寻找它在世界中的表现形式。我要寻找它的影子,”Law 说。
1952 年,英国广播公司电台组织了一个专家小组进一步探讨 Turing 的观点。图灵在演播室里与他的两位曼彻斯特大学同事——数学教授 Maxwell Newman (麦克斯韦尔·纽曼)和神经外科教授 Geoffrey Jefferson(杰弗里·杰斐逊),以及剑桥大学的科学、伦理与宗教哲学家 Richard Braithwaite(理查德·布雷斯韦特)一同出席。
Braithwaite 开场说道:“思考通常被认为是人类,也许还包括其他高等动物的专长,这个问题可能看起来太荒谬了,不值得讨论。但当然,这完全取决于‘思考’中包含了什么。”
小组成员围绕 Turing 的问题展开讨论,但始终未能给出确切的定义。
当他们试图定义思考包含什么,其机制是什么时,标准一直在变动。“一旦我们能在大脑中看到因果关系的运作,我们就会认为那不是思考,而是一种缺乏想象力的苦力工作,”图灵说道。
问题在于:当一位小组成员提出某种可能被视为思考证据的行为——比如对新想法表示愤怒——另一位成员就会指出,计算机也可以被编程来做到这一点。
(来源:MIT TR)
正如 Newman 所说,编程让计算机打印出“我不喜欢这个新程序”是轻而易举的。但他承认,这不过是个把戏。
Jefferson 对此表示赞同:他想要的是一台因为不喜欢新程序而打印出“我不喜欢这个新程序”的计算机。换言之,对于 Jefferson 来说,行为本身是不够的,引发行为的过程才是关键。
但 Turing 并不同意。正如他所指出的,揭示特定过程——他所说的苦力工作——并不能确切指出思考是什么。那么剩下的还有什么?
“从这个角度来看,人们可能会受到诱惑,将思考定义为我们还不理解的那些心理过程,”Turing 说,“如果这是正确的,那么制造一台思考机器就是制造一台能做出有趣事情的机器,而我们其实并不完全理解它是如何做到的。”
听到人们首次探讨这些想法感觉有些奇怪。“这场辩论具有预见性,”哈佛大学的认知科学家 Tomer Ullman 说,“其中的一些观点至今仍然存在——甚至更为突出。他们似乎在反复讨论的是,图灵测试首先并且主要是一个行为主义测试。”
对 Turing 而言,智能难以定义但容易识别。他提议,智能的表现就足够了,而没有提及这种行为应当如何产生。
然而,大多数人被逼问时,都会凭直觉判断何为智能,何为非智能。表现出智能有愚蠢和聪明的方式。1981 年,纽约大学的哲学家 Ned Block 表明,Turing 的提议没有满足这些直觉。由于它没有说明行为的原因,图灵测试可以通过欺骗手段(正如纽曼在 BBC 广播中所指出的)来通过。
“一台机器是否真的在思考或是否智能的问题,难道取决于人类审问者的易骗程度吗?”布洛克问道。(正如计算机科学家 Mark Reidl 所评论的那样:“图灵测试不是为了让 AI 通过,而是为了让人类失败。”)
Block 设想了一个庞大的查找表,其中人类程序员录入了对所有可能问题的所有可能答案。向这台机器输入问题,它会在数据库中查找匹配的答案并发送回来。Block 认为,任何人使用这台机器都会认为其行为是智能的:“但实际上,这台机器的智能水平就像一个烤面包机,”他写道,“它展现的所有智能都是其程序员的智能。”
Block 总结道,行为是否为智能行为,取决于它是如何产生的,而非它看起来如何。Block 的“烤面包机”(后来被称为 Blockhead)是对 Turing 提议背后假设最强有力的反例之一。
探索内在机制
图灵测试本意并非实际衡量标准,但它对我们今天思考人工智能的方式有着深远的影响。这一点随着近年来大型语言模型(LLMs)的爆炸性发展变得尤为相关。这些模型以外在行为作为评判标准,具体表现为它们在一系列测试中的表现。当 OpenAI 宣布 GPT-4 时,发布了一份令人印象深刻的得分卡,详细列出了该模型在多个高中及专业考试中的表现。几乎没有人讨论这些模型是如何取得这些成绩的。
这是因为我们不知道。如今的大型语言模型太过复杂,以至于任何人都无法确切说明其行为是如何产生的。除少数几家开发这些模型的公司外,外部研究人员不了解其训练数据包含什么;模型制造商也没有分享任何细节。这使得区分什么是记忆(随机模仿)什么是真正的智能变得困难。即便是在内部工作的研究人员,如 Olah,面对一个痴迷于桥梁的机器人时,也不知道真正发生了什么。
这就留下了一个悬而未决的问题:是的,大型语言模型建立在数学之上,但它们是否在用智能的方式运用这些数学知识呢?
争论再次开始。
布朗大学的 Pavlick 说:“大多数人试图从理论上推测(armchair through it),”这意味着他们在没有观察实际情况的情况下争论理论。“有些人会说,‘我认为情况是这样的,’另一些人则会说,‘嗯,我不这么认为。’我们有点陷入僵局,每个人都不满意。”
Bender 认为这种神秘感加剧了神话的构建。(“魔术师不会解释他们的把戏,”她说。)没有恰当理解 LLM 语言输出的来源,我们便倾向于依赖对人类的熟悉假设,因为这是我们唯一的真正参照点。当我们与他人交谈时,我们试图理解对方想告诉我们什么。“这个过程必然涉及想象言语背后的那个生命,”Bender 说。这就是语言的工作方式。
(来源:JUN IONEDA)
“ChatGPT 的小把戏如此令人印象深刻,以至于当我们看到这些词从它那里冒出来时,我们会本能地做同样的事,”她说。“它非常擅长模仿语言的形式。问题是,我们根本不擅长遇到语言的形式而不去想象它的其余部分。”
对于一些研究者来说,我们是否能理解其运作方式并不重要。Bubeck 过去研究大型语言模型是为了尝试弄清楚它们是如何工作的,但 GPT-4 改变了他的看法。“这些问题似乎不再那么相关了,”他说。“模型太大,太复杂,以至于我们不能指望打开它并理解里面真正发生的事情。”
但 Pavlick 像 Olah 一样,正努力做这件事。她的团队发现,模型似乎编码了物体之间的抽象关系,比如国家和首都之间的关系。通过研究一个大型语言模型,Pavlick 和她的同事们发现,它使用相同的编码映射法国到巴黎,波兰到华沙。我告诉她,这听起来几乎很聪明。“不,它实际上就是一个查找表,”她说。
但让 Pavlick 感到震惊的是,与 Blockhead 不同,模型自己学会了这个查找表。换句话说,LLM 自己发现巴黎对于法国就如同华沙对于波兰一样。但这展示了什么?自编码查找表而不是使用硬编码的查找表是智能的标志吗?我们该在哪里划清界限?
“基本上,问题在于行为是我们唯一知道如何可靠测量的东西,” Pavlick 说。“其他任何东西都需要理论上的承诺,而人们不喜欢不得不做出理论上的承诺,因为它承载了太多含义。”
并非所有人都这样。许多有影响力的科学家乐于做出理论上的承诺。例如,Hinton 坚持认为神经网络是你需要的一切来重现类似人类的智能。“深度学习将能够做一切,”他在 2020 年接受《麻省理工科技评论》采访时说。
这是一个 Hinton 似乎从一开始就坚持的信念。Sloman 记得当 Hinton 是他实验室的研究生时,两人曾发生过争执,他回忆说自己无法说服 Hinton 相信神经网络无法学习某些人类和其他某些动物似乎直观掌握的关键抽象概念,比如某事是否不可能。Sloman 说,我们可以直接看出什么时候某事被排除了。“尽管 Hinton 拥有杰出的智慧,但他似乎从未理解这一点。我不知道为什么,但有大量的神经网络研究者都有这个盲点。”
然后是 Marcus,他对神经网络的看法与 Hinton 截然相反。他的观点基于他所说的科学家对大脑的发现。
Marcus 指出,大脑并不是从零开始学习的白板——它们天生带有指导学习的固有结构和过程。他认为,这就是婴儿能学到目前最好的神经网络仍不能掌握的东西的原因。
“神经网络研究者手头有这个锤子,现在一切都变成了钉子,”Marcus 说。“他们想用学习来做所有的事,许多认知科学家会认为这不切实际且愚蠢。你不可能从零开始学习一切。”
不过,作为一名认知科学家,Marcus 对自己的观点同样确信。“如果真有人准确预测了当前的情况,我想我必须排在任何人名单的最前面,”他在前往欧洲演讲的 Uber 后座上告诉我。“我知道这听起来不太谦虚,但我确实有这样一个视角,如果你试图研究的是人工智能,这个视角就显得非常重要。”
鉴于他对该领域公开的批评,你或许会惊讶于 Marcus 仍然相信通用人工智能(AGI)即将来临。只是他认为当今对神经网络的执着是个错误。“我们可能还需要一两个或四个突破,”他说。“你和我可能活不到那么久,很抱歉这么说。但我认为这将在本世纪发生。也许我们有机会见证。”
炫彩之梦的力量
在以色列拉马特甘家中通过 Zoom 通话时,Dor Skuler 背后的某个类似小台灯的机器人随着我们的谈话时亮时灭。“你可以在我身后看到 ElliQ,”他说。Skuler 的公司 Intuition Robotics 为老年人设计这些设备,而 ElliQ 的设计——结合了亚马逊 Alexa 的部分特征和 R2-D2 的风格——明确表明它是一台计算机。Skuler 表示,如果有任何客户表现出对此有所混淆的迹象,公司就会收回这款设备。
ElliQ 没有脸,没有任何人类的形状。如果你问它关于体育的问题,它会开玩笑说自己没有手眼协调能力,因为它既没有手也没有眼睛。“我实在不明白,为什么行业里都在努力满足图灵测试,” Skuler 说,“为什么为了全人类的利益,我们要研发旨在欺骗我们的技术呢?”
相反,Skuler 的公司赌注于人们可以与明确呈现为机器的机器建立关系。“就像我们有能力与狗建立真实的关系一样,”他说,“狗给人们带来了很多快乐,提供了陪伴。人们爱他们的狗,但他们从不把它混淆成人。”
(来源:MIT TR)
ElliQ 的用户,很多都是八九十岁的老人,称这个机器人为一个实体或一种存在——有时甚至是一个室友。“他们能够为这种介于设备或电脑与有生命之物之间的关系创造一个空间,” Skuler 说。
然而,不管 ElliQ 的设计者多么努力地控制人们对这款设备的看法,他们都在与塑造了我们期望几十年的流行文化竞争。为什么我们如此执着于类人的人工智能?“因为我们很难想象其他的可能性,” Skuler 说(在我们的对话中,他确实一直用“她”来指代 ElliQ),“而且科技行业的许多人都是科幻迷。他们试图让自己的梦想成真。”
有多少开发者在成长过程中认为,构建一台智能机器是他们可能做的最酷的事情——如果不是最重要的事情?
不久之前,OpenAI 推出了新的语音控制版 ChatGPT,其声音听起来像 Scarlett Johansson(斯嘉丽约翰逊),之后包括 Altman 在内的许多人都指出了它与 Spike Jonze (斯派克琼斯) 2013 年的电影《她》之间的联系。
科幻小说共同创造了人工智能被理解为何物。正如 Cave 和 Dihal 在《想象人工智能》一书中所写:“人工智能在成为技术现象很久以前就已经是一种文化现象了。”
关于将人类重塑为机器的故事和神话已有数百年历史。Dihal 指出,人们对于人造人的梦想可能与他们对于飞行的梦想一样长久。她提到,希腊神话中的著名人物戴达罗斯,除了为自己和儿子伊卡洛斯建造了一对翅膀外,还建造了一个实质上是巨型青铜机器人的塔洛斯,它会向过往的海盗投掷石头。
“机器人”这个词来自 robota,这是捷克剧作家 Karel Čapek 在他的 1920 年戏剧《罗素姆的万能机器人》中创造的一个术语,意为“强制劳动”。Isaac Asimov(艾萨克·阿西莫夫)在其科幻作品中概述的“机器人学三大法则”,禁止机器伤害人类,而在像《终结者》这样的电影中,这些法则被反转,成为了对现实世界技术的普遍恐惧的经典参考点。2014 年的电影《机械姬》是对图灵测试的戏剧性演绎。去年的大片《造物主》设想了一个未来世界,在这个世界里,人工智能因引发核弹爆炸而被取缔,这一事件被某些末日论者至少视为一个可能的外部风险。
Cave 和 Dihal 讲述了另一部电影《超验骇客》(2014 年),在这部电影中,由 Johnny Depp(约翰尼·德普)饰演的一位人工智能专家将自己的意识上传到了电脑中,这一情节推动了元末日论者 Stephen Hawking(斯蒂芬·霍金)、物理学家 Max Tegmark(马克斯·泰格马克)以及人工智能研究员 Stuart Russell(斯图尔特·拉塞尔)提出的叙事。在电影首映周末发表在《赫芬顿邮报》上的一篇文章中,三人写道:“随着好莱坞大片《超验骇客》的上映……它带来了关于人类未来的冲突愿景,很容易将高度智能机器的概念视为纯粹的科幻小说。但这将是一个错误,可能是我们有史以来最大的错误。”
(来源:ALCON ENTERTAINMENT)
大约在同一时期,Tegmark 创立了未来生命研究所,其使命是研究和促进人工智能安全。电影中德普的搭档 Morgan Freeman(摩根·弗里曼)是该研究所董事会成员,而曾在电影中有客串的 Elon Musk 在第一年捐赠了1000万美元。对于 Cave 和 Dihal 来说,《超验骇客》是流行文化、学术研究、工业生产和“亿万富翁资助的未来塑造之战”之间多重纠葛的完美例证。
去年在 Altman 的世界巡回伦敦站,当被问及他在推特上所说“人工智能是世界一直想要的技术”是什么意思时,站在房间后面,面对着数百名听众,我听到他给出了自己的起源故事:“我小时候非常紧张,读了很多科幻小说,很多周五晚上都待在家里玩电脑。但我一直对人工智能很感兴趣,我觉得那会非常酷。”他上了大学,变得富有,并见证了神经网络变得越来越好。“这可能非常好,但也可能真的很糟糕。我们要怎么应对?”他回忆起 2015 年时的想法,“我最终创立了 OpenAI。”
为何你应该关心一群书呆子对 AI 的争论
好的,你已经明白了:没人能就人工智能是什么达成一致。但似乎每个人都同意的是,当前围绕 AI 的争论已远远超出了学术和科学范畴。政治和道德因素正在发挥作用,而这并没有帮助大家减少彼此认为对方错误的情况。
解开这个谜团很难。当某些道德观点涵盖了整个人类的未来,并将其锚定在一个无人能确切定义的技术上时,要想看清正在发生什么变得尤为困难。
但我们不能就此放弃。因为无论这项技术是什么,它即将到来,除非你与世隔绝,否则你将以这样或那样的形式使用它。而技术的形态,以及它解决和产生的问题,都将受到你刚刚读到的这类人的思想和动机的影响,尤其是那些拥有最大权力、最多资金和最响亮声音的人。
这让我想到了 TESCREALists。等等,别走!我知道,在这里引入另一个新概念似乎不公平。但要理解掌权者如何塑造他们构建的技术,以及他们如何向全球监管机构和立法者解释这些技术,你必须真正了解他们的思维方式。
Gebru 在离开谷歌后创建了分布式人工智能研究所,以及凯斯西储大学的哲学家和历史学家 Émile Torres(埃米尔·托雷斯),他们追踪了几个技术乌托邦信仰体系对硅谷的影响。二人认为,要理解 AI 当前的状况——为什么像谷歌 DeepMind 和 OpenAI 这样的公司正在竞相构建通用人工智能(AGI),以及为什么像 Tegmark 和 Hinton 这样的末日预言者警告即将到来的灾难——必须通过托雷斯所称的 TESCREAL 框架来审视这个领域。
这个笨拙的缩写词(发音为tes-cree-all)取代了一个更笨拙的标签列表:超人类主义、外展主义、奇点主义、宇宙主义、理性主义、有效利他主义和长期主义。关于这些世界观的许多内容(以及将会有的更多内容)已经被撰写,所以我在这里就不赘述了。(对于任何想要深入探索的人来说,这里充满了层层递进的兔子洞。选择你的领域,带上你的探险装备吧。)
这一系列相互重叠的思想观念对西方科技界中某种类型的天才思维极具吸引力。一些人预见到人类的永生,其他人则预测人类将殖民星辰。共同的信条是,一种全能的技术——无论是通用人工智能(AGI)还是超级智能,选边站队吧——不仅触手可及,而且不可避免。你可以在诸如 OpenAI 这样的前沿实验室里无处不在的拼命态度中看到这一点:如果我们不制造出 AGI,别人也会。
更重要的是,TESCREA 主义者认为 AGI 不仅能解决世界的问题,还能提升人类层次。“人工智能的发展和普及——远非我们应该害怕的风险——是我们对自己、对子女和对未来的一种道德义务,” Andreessen 去年在一篇备受剖析的宣言中写道。我多次被告知,AGI 是让世界变得更美好的途径——这是 DeepMind 的首席执行官和联合创始人 Demis Hassabis(戴米斯·哈萨比斯)、新成立的微软 AI 的首席执行官及 DeepMind 的另一位联合创始人Mustafa Suleyman、Sutskever、Altman 等人告诉我的。
但正如 Andreessen 所指出的,这是一种阴阳心态。技术乌托邦的反面就是技术地狱。如果你相信自己正在建设一种强大到足以解决世界上所有问题的技术,你很可能也相信它有可能完全出错的风险。当二月份在世界政府峰会上被问及什么让他夜不能寐时,阿尔特曼回答说:“都是科幻小说里的东西。”
这种紧张局势是 Hinton 在过去一年里不断强调的。这也是 Anthropic 等公司声称要解决的问题,是 Sutskever 在他的新实验室关注的焦点,也是他去年希望 OpenAI 内部特别团队专注的,直到在公司如何平衡风险与回报上的分歧导致该团队大多数成员离职。
当然,末日论也是宣传的一部分。(“声称你创造了某种超级智能的东西有利于销售数字,”迪哈尔说,“就像是,‘请有人阻止我这么好,这么强大吧。’”)但不论繁荣还是毁灭,这些人号称要解决的到底是什么问题?谁的问题?我们真的应该信任他们建造的东西以及他们向我们的领导人讲述的内容吗?
Gebru 和 Torres(以及其他一些人)坚决反对:不,我们不应该。他们对这些意识形态及其可能如何影响未来技术,特别是 AI 的发展持高度批评态度。从根本上讲,他们将这些世界观中几个以“改善”人类为共同焦点的观念与 20 世纪的种族优生运动联系起来。
他们认为,一个危险是,资源向这些意识形态要求的科技创新转移,从构建 AGI 到延长寿命再到殖民其他星球,最终将以数十亿非西方和非白人群体的利益为代价,使西方和白人受益。如果你的目光锁定在幻想的未来上,很容易忽视创新的当下成本,比如劳工剥削、种族和性别偏见的根深蒂固以及环境破坏。
Bender 反思这场通往 AGI 竞赛的牺牲时问道:“我们是否在试图建造某种对我们有用工具?”如果是这样,那是为谁建造的,我们如何测试它,它工作得有多好?“但如果我们要建造它的目的仅仅是为了能够说我们做到了,这不是我能支持的目标。这不是值得数十亿美元的目标。”
Bender 说,认识到 TESCREAL 意识形态之间的联系让她意识到这些辩论背后还有更多的东西。“与那些人的纠缠是——”她停顿了一下,“好吧,这里不仅仅只有学术思想。其中还捆绑着一种道德准则。”
当然,如果这样缺乏细微差别地阐述,听起来好像我们——作为社会,作为个人——并没有得到最好的交易。这一切听起来也很愚蠢。当 Gebru 去年在一次演讲中描述了 TESCREAL 组合的部分内容时,她的听众笑了。也的确很少有人会认同自己是这些思想流派的忠实信徒,至少在极端意义上不会。
但如果我们不了解那些构建这项技术的人是如何看待它的,我们又怎么能决定我们要达成什么样的协议呢?我们决定使用哪些应用程序,我们想向哪个聊天机器人提供个人信息,我们在社区支持哪些数据中心,我们想投票给哪些政治家?
过去常常是这样:世界上有一个问题,我们就建造一些东西来解决它。而现在,一切都颠倒了:目标似乎是建造一台能做所有事情的机器,跳过在找到解决方案前缓慢而艰难地识别问题的工作。
正如 Gebru 在那次演讲中所说,“一台能解决所有问题的机器:如果这都不是魔法,那它是什么呢?”
语义,语义……还是语义?
当直截了当地问及什么是人工智能时,很多人会回避这个问题。Suleyman 不是这样。四月份,微软 AI 的首席执行官站在 TED 的舞台上,告诉观众他对六岁侄子提出同样问题时的回答。Suleyman 解释说,他能给出的最佳答案是,人工智能是“一种新型的数字物种”——一种如此普遍、如此强大的技术,以至于称其为工具已不再能概括它能为我们做什么。
“按照目前的发展轨迹,我们正走向某种我们都难以描述的出现,而我们无法控制我们不理解的事物,”他说,“因此,比喻、心智模型、名称——这些都至关重要,只有这样我们才能在最大限度利用人工智能的同时限制其潜在的负面影响。”
(来源:MIT TR)
语言很重要!我希望从我们经历过的曲折、转折和情绪爆发中,这一点已经很清楚了。但我也希望你在问:是谁的语言?又是谁的负面影响?Suleyman 是一家科技巨头的行业领导者,该公司有望从其 AI 产品中赚取数十亿美元。将这些产品的背后技术描述为一种新型物种,暗示着某种前所未有的东西,它具有我们从未见过的自主性和能力。这让我感到不安,你呢?
我无法告诉你这里是否有魔法(讽刺与否)。我也无法告诉你数学是如何实现 Bubeck 和其他许多人在这项技术中看到的(目前还没有人能做到)。你必须自己下结论。但我可以揭示我自己的观点。
在 2020 年写到 GPT-3 时,我说人工智能最伟大的把戏就是说服世界它存在。我仍然这么认为:我们天生就会在表现出特定行为的事物中看到智慧,不管它是否存在。在过去几年里,科技行业本身也找到了理由来说服我们相信人工智能的存在。这使我对接收到的许多关于这项技术的声明持怀疑态度。
与此同时,大型语言模型让我感到惊奇。它们究竟可以做什么以及如何做到,是我们这个时代最令人兴奋的问题之一。
也许人类一直对智慧着迷——它是什么,还有什么拥有它。Pavlick 告诉我,哲学家长期以来一直在构想假设场景,来想象遇到非人类来源的智能行为意味着什么——比如说,如果一波浪冲刷海滩,当它退去时在沙滩上留下了一行字,拼凑成一首诗?
通过大型语言模型——通过它们的微笑面具——我们面临着前所未有的思考对象。“它将这个假设的东西变得非常具体,”Pavlick 说,“我从未想过一段语言的生成是否需要智慧,因为我从未处理过来自非人类的言语。”
人工智能包含很多东西。但我不认为它是类人的。我不认为它是解决我们所有(甚至大部分)问题的答案。它不是 ChatGPT、Gemini 或 Copilot,也不是神经网络。它是一种理念、一种愿景,一种愿望的实现。理念受到其他理念、道德、准宗教信念、世界观、政治和直觉的影响。“人工智能”是描述一系列不同技术的有用简略说法。但人工智能并不是单一事物;从来都不是,不管品牌标识多么频繁地烙印在外包装上。
“事实是,这些词汇——智力、推理、理解等——在需要精确界定之前就已经被定义了,”Pavlick 说,“当问题变成‘模型是否理解——是或否?’时,我并不喜欢,因为,嗯,我不知道。词语会被重新定义,概念会不断进化。”
我认为这是对的。我们越早能后退一步,就我们不知道的事达成共识,并接受这一切尚未尘埃落定,我们就能越快地——我不知道,或许不是手牵手唱起 Kumbaya(《欢聚一堂》),但我们可以停止互相指责。
原文链接:
https://www.technologyreview.com/2024/07/10/1094475/what-is-artificial-intelligence-ai-definitive-guide/
本文转自 | 麻省理工科技评论APP
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12















 鲁公网安备37020202000738号
鲁公网安备37020202000738号