揭秘鲜为人知的三个JavaScript库,轻松提升开发效率!
发表时间: 2020-03-08 12:30
全文共2544字,预计学习时长8分钟

JavaScript有很多库,每个人都已经对最重要和最受欢迎的库做过总结,但很快再次迷失。
在本文中,小芯将分享3个鲜为人知但非常强大,且很小的JavaScript库,这些库将使你的生活变得简单,也不会给你的web应用程序增加不必要的负担。
OfficialGitHub
在浏览器中使用cookies可能会非常费力。JS cookies让这件事变得简单多了,现在我们将学习基本知识。
通过CDN实施:
<script src="https://cdn.jsdelivr.net/npm/js-cookie@beta/dist/js.cookie.min.js"></script>设置一个名为“name”的cookie键,其值为“Max”
Cookies.set(‘name’, ‘Max’)获取密钥为“name”的cookie值
Cookies.get(‘name’) // 'Max'创建cookie,让它在7天后过期
Cookies.set('name', 'Max', { expires:7 })删除cookie
Cookies.remove(‘name’)得出所有cookie
Cookies.get() // { name: 'Max' }
来源:Pexels
OfficialDocumentation
Basket.js是一个极简的脚本加载程序库,压缩后只有0.7kB。
(它使用的另一个库压缩后大约为5kB,如https://github.com/addyosmani/basket.js/issues/61中所述,但仍然很小)
但是basket.js不仅可以加载外部JavaScript,还可以将其缓存在浏览器的本地存储中,这样在下一页请求时,就不必再次通过网络请求外部JavaScript,而只需从本地存储中加载即可。
但为什么是本地存储而不是浏览器缓存呢?
首先,我个人认为通过JS库在web页面代码中缓存JavaScript文件要容易得多,通常是从服务器端缓存的。使用Basket.js,很容易在代码中使用JavaScript动态控制脚本缓存。
我们试试看:
实际的API并没有那么复杂。我认为你可以自己探索一下文档,在下面的简单示例中,我们只使用basket.require,因为它是整个库的核心。
· basket.require()
· basket.get()
· basket.remove()
· basket.clear()
使用basket.require,我们可以通过basket加载JS文件。然后这个文件被缓存在本地存储中,正如前文所述,下一次basket.require请求这个文件,例如,当重新加载页面时,basket将首先在缓存中查找。或者如果文件已经缓存在那里,它将通过本地存储加载文件,而不是通过网络再次发出请求。
index.html:
在这里你可以找到库:
https://addyosmani.com/basket.js/dist/basket.min.jshttps://cdn.jsdelivr.net/npm/rsvp@4/dist/rsvp.min.jshttps://cdnjs.cloudflare.com/ajax/libs/jquery/3.4.1/jquery.min.js
<!DOCTYPE html><html lang=”en”> <head> <meta charset=”UTF-8" /> <scriptsrc=”rsvp.min.js”></script> <scriptsrc=”basket.min.js”></script> <title>Document</title></head><body> <script> basket.require({ url:'/scripts/jquery.js' })</script></body></html>如你所见,首先导入Basket.js需要的RSVP库。然后回到Basket本身,在body中可以执行require函数,从某个地方加载jQuery。
第一次打开页面时,应该看到:
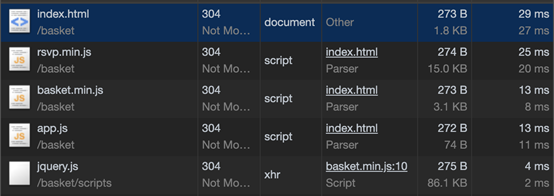
jQuery是通过网络正常请求的。
但随着页面的重新加载:
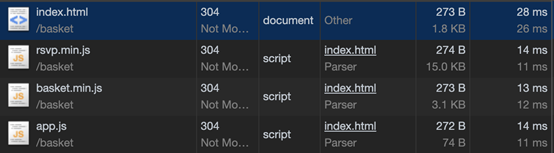
jQuery不再列在Network选项卡中,它是从本地存储加载。
以上就是整个“魔法”过程 :)
Official Github
“Pill将动态内容加载添加到静态站点,并使内容加载更为顺畅。”压缩后大约为1KB。
Pill的开发始于这篇推文: https://twitter.com/sitnikcode/status/1109626507331338240
精髓:大多数人使用单页应用程序来运行web应用程序,点击时,不会加载整个新页面。在大多数SPA框架中,这是因为所有内容都基于一个index.html。
但如果有多个静态页面呢?Pill能够帮你解决。
根据需要,它将获取服务器上其他HTML文件的内容,并将当前内容替换为新的已获取内容。
这是巨大的性能改进,因为我们的应用程序不再要求一个完整的新页面。
重要的内容刚刚被替换。
使用Pill,能拦截导航尝试,自动完成上述步骤。
Pill最好的一点是,它会通过一个个示例来记载,确保检查所有的东西:你可以在GitHub上找到代码https://GitHub.com/rumkin/pill/tree/master/example
祝你和Pill合作愉快:)

来源:Pexels
希望本文能对你有所帮助,感谢阅读~

留言点赞关注
我们一起分享AI学习与发展的干货
如转载,请后台留言,遵守转载规范
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号