探索云原生技术的世界
发表时间: 2020-03-20 11:46
云原生这个词已经频频霸占技术头条榜上,继深度学习、大数据、区块链技术之后又一跨界刷榜利器,那么云原生究竟讲得是什么呢?那么我来杂谈下云原生得那些事。
云原生,相信这个词大家应该或多或少都听过, 那么什么是云原生计算呢?云原生技术得技术栈有哪些呢?
下面主要从以下三个主题来聊聊今天得话题, 什么是云原生, 云原生得发展史和云原生得生态圈。


云原生的概念最早开始于2010年,在当时 Paul Fremantle 的一篇博客中被提及,他主要将其描述为一种和云一样的系统行为的应用的编写,比如分布式的、松散的、自服务的、持续部署与测试的。当时提出云原生是为了能构建一种符合云计算特性的标准来指导云计算应用的编写。后来到2013年 Matt Stine在推特上迅速推广云原生概念,并在2015年《迁移到云原生架构》一书中定义了符合云原生架构的特征:12因素、微服务、自服务、基于API协作、扛脆弱性。而由于这本书的推广畅销,这也成了很多人对云原生的早

CNCF得定义总结一下就是:(1)基于容器、服务网格、微服务、不可变基础设施和声明式API构建的可弹性扩展的应用;(2)基于自动化技术构建具备高容错性、易管理和便于观察的松耦合系统;(3)构建一个统一的开源云技术生态,能和云厂商提供的服务解耦,可以看出这一阶段CNCF对云原生的定义加上服务网格和声明式API,同时为这一概念阐述更深一层的意义,也就是建立一个统一中立的开源云生态(至于是否中立嘛这里就不谈了:)。这对云原生的生态定位会是很重要的一点,也算CNCF最初成立的宗旨之一吧,打破云巨头的垄断。

为什么用“解构”?
解构,或译为“结构分解”,是后结构主义提出的一种批评方法。是解构主义者德里达的一个术语。“解构”概念源于海德格尔《存在与时间》中的“deconstruction”一词,原意为分解、消解、拆解、揭示等,德里达在这个基础上补充了“消除”、“反积淀”、“问题化”等意思。这里是打算用解构得思想给大家来分析下“云原生”得理解:
Cloud Native,从词面上拆解其实就是 Cloud 和 Native,也就是云计算和土著的意思——云计算上的原生居民,即天生具备云计算的亲和力。那怎么理解“云的原生居民”呢?首先从云的角度来理解,云本质可以看作是一种提供稳定计算存储资源的对象,为了实现这点,像虚拟化、弹性扩展、高可用、高容错性、自恢复这些都是云的基本属性,云原生作为一种云计算,这是所具备的第一层含义。第二层要从 Native 来看,云原生和传统的在云上跑的应用是不同。比如一些基于公有云搭建的应用,是基于传统的SOA架构来搭建的,然后再移植到云上去运行,那么他和云得整合是非常低得。 为什么低呢?云作为一种分布式架构,其“土著居民”也应该是基于分布式架构设计出来得,而微服务或者Serverless这种将服务或函数拆分成一个个模块的松耦合系统天然就具备分布式设计得属性。这是Native的第一种表现。其次云作为一种PaaS服务,这位“土著居民”从出生(设计)到成长(开发),再到生活(部署)都应该是基于云的理念来实现的,那么就需要一套自动化的开发流程CI/CD来实现。这是Native的第二种表现。而最后“土著居民”的特点希望做到能在所有的云端都是适应的,不管是各厂商的公有云 像AWS、Azure、阿里云,还是各企业自己搭建的私有云,云原生的应用都能做到无缝的运行和连接。

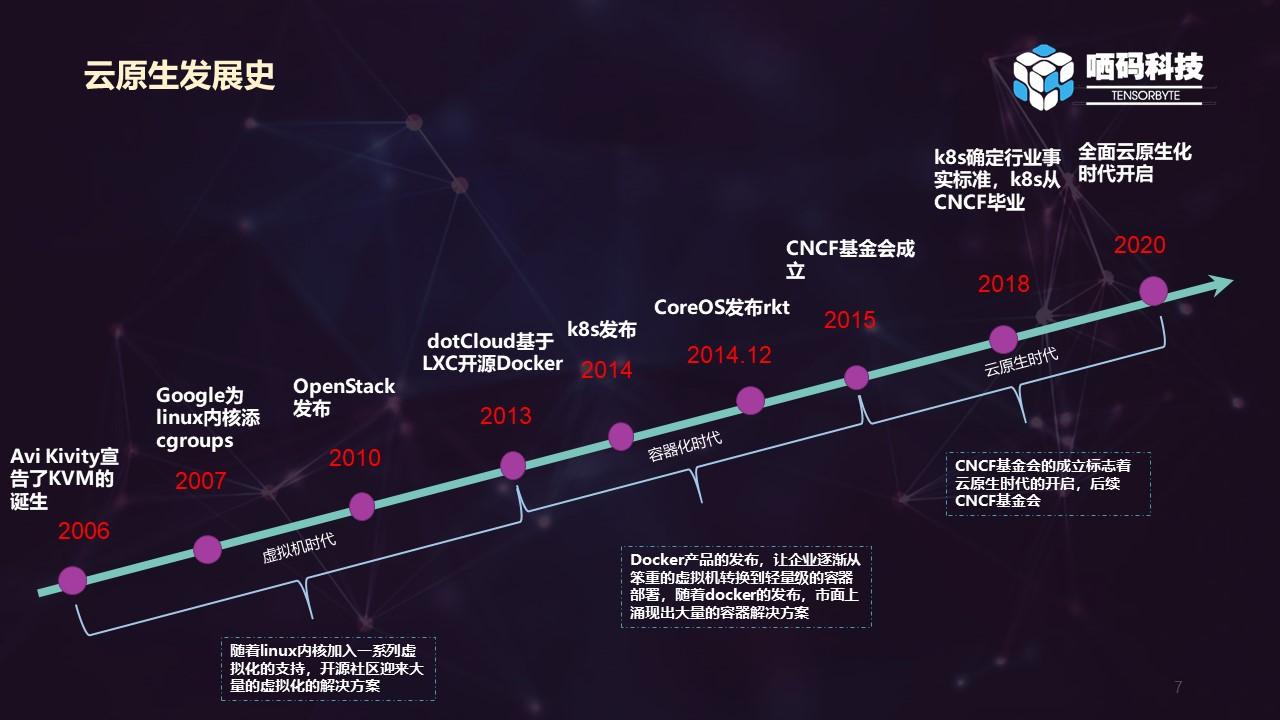
云原生的发展历史可以分为三个时代, 虚拟机时代->容器时代->云原生时代。
虚拟机时代:这要从2006年说起,这一年Avi Kivity宣告了Kernel-based Virtual Machine的诞生,也就是我们常说的KVM——基于内核的虚拟机,采用硬件虚拟化技术的全虚拟化解决方案。KVM以其精简的架构,清晰的定位获得Linux社区多数开发人员的支持并快速被合并入主干,2007年2月,KVM发布到内核2.6.20中。KVM从诞生开始就定位于基于硬件虚拟化支持的全虚拟化实现。它以内核模块的形式加载之后,就将Linux内核变成了一个Hypervisor,但硬件管理等还是通过Linux kernel来完成的,一个KVM客户机对应于一个Linux进程,每个vCPU则是这个进程下的一个线程,还有单独的处理IO的线程,也在一个线程组内。所以,宿主机上各个客户机是由宿主机内核像调度普通进程一样调度的,即可以通过Linux的各种进程调度的手段来实现不同客户机的权限限定、优先级等功能。除了KVM,这一年由Google的工程师Paul Menage和Rohit Seth 在2006年发起一个叫进程容器(process containers)的项目,这就是后面容器时代的基石之一 —— Cgroups。在2007年时,因为在Linux内核中,容器(container)这个名词有许多不同的意义,为避免混乱,被重命名为Cgroups,并且被合并到2.6.24版的内核中去。随后,2008 年,通过将 Cgroups 的资源管理能力和 Linux Namespace 的视图隔离能力组合在一起,LXC 完整的容器技术出现在 Linux 内核中,并且可以在单个 Linux 内核上运行而无需任何补丁。随后2010年7月,NASA和Rackspace共同发布了著名的开源项目Openstack,Openstack的开源标志着开源领域真正具有一个成熟的云计算解决方案。
容器时代:容器时代的标志性事件就是 dotCloud 开源的一个基于 LXC 的高级容器引擎 Docker的问世。Docker产品的发布,让企业逐渐从笨重的虚拟机转换到轻量级的容器部署,随着docker的发布,市面上涌现出大量的容器解决方案大量轻量级的虚拟化解决方案,如Rocket、Windows Containers等。
云原生时代:随着容器的成熟和云计算的发展,人们迫切需要一种在云上的最佳实践,云原生就被提出了。在2015年,Linux基金会成立了一个叫The Cloud Native Computing Foundation基金组织,也就是CNCF。随着大厂的加盟,像Google、AWS、微软、阿里巴巴、腾讯云、IBM等,CNCF逐渐成为云原生的最权威组织,并将云原生技术推广到世界各地。


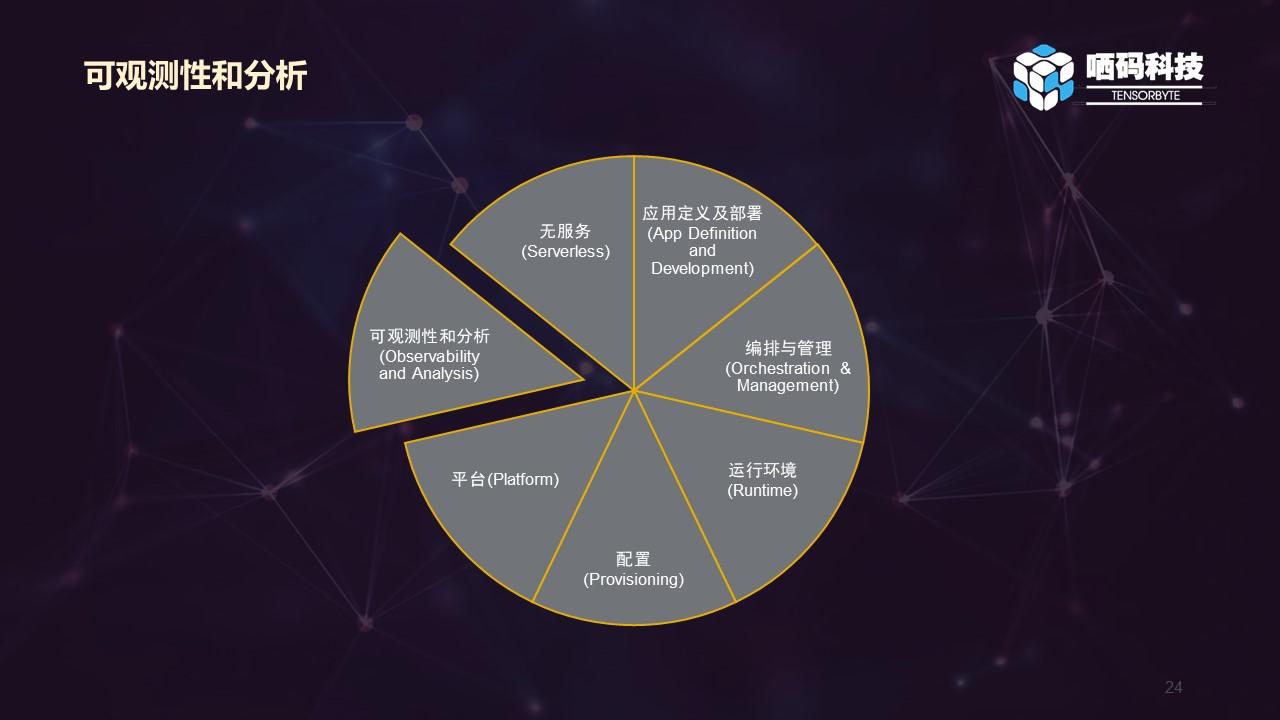
这里主要分成了几个技术板块,应用定义及部署(App Definition and Development)编排与管理(Orchestration & Management)运行环境(Runtime)配置(Provisioning)平台(Platform)可观测性和分析(Observability and Analysis)无服务(Serverless)这几大板块基本把云原生技术所涉及领域都涵括进去了,下面详细介绍下各板块所涉及到的技术栈。从系统层次来看,从上到下分别是:应用层:应用定义及部署(App Definition and Development)、配置(Provisioning)、可观测性和分析(Observability and Analysis)、无服务(Serverless)集群:编排与管理(Orchestration & Management)底层运行环境:运行环境(Runtime)

数据库(Database):应用层的数据库,其中 PingCAP 公司推出的 TiDB 就是其中的佼佼者之一,其具有水平弹性扩展、分布式事务等特性让其和云原生应用理念天然的契合。流式处理和消息队列(Streaming and Messaging):常用的消息队列有kafka、NATS、RabbitMQ等,常用的应用系统中也用的比较多。流式处理有Spark streaming、storm、flink等,都是常用的大数据流式计算框架。应用定义和镜像构建(App Definition and Image Build):云原生的应用构建一般由于一堆 YAML 文件组成,为了能更灵活的生成和打包管理这些配置定义文件,我们需要一些工具,而 Helm 就是k8s应用比较多的一种应用程序 Chart 的创建、打包、发布以及创建的软件包管理工具。持续集成与持续部署(Continuous Integration and Continuous Delivery):持续集成和持续部署是一种基于敏捷开发提出的开发工具,由于敏捷开发中要求要以快步小走的方式进行迭代,为了节约测试、部署时间周期,必须需要一个能做到和代码管理进行结合的自动化测试和部署工具,而这就是持续集成和部署(简称CI/CD)。常用的CI/CD工具有Jenkins、Travis CI、gitlab runner等。

TiDB算得上比较正宗的云原生数据库,其采用了计算和存储节点分离的方式,TiDB 具有水平扩展和高可用特点,这里简单大家介绍下 TiDB 的整体架构。TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。
PD ServerPlacement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
TiKV ServerTiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
TiSparkTiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。



容器编排与调度(Orchestration and Scheduling):容器的编排和管理可以说是云原生的基石,而 Kubernetes 可以说是这个领域的事实标准,作为 CNCF 基金会的首个毕业项目和金字招牌甚至很多人认为云原生就是 k8s 和其相关的一系列技术,虽然这样的说法是很不准确的,不过现在云原生技术确实和k8s绑定的越来越紧密,由此而衍生了一大批的工具生态。一致性与服务发现(Coordination and Service Discovery):各服务之间的协同以及服务发现是分布式计算中的核心,分布式架构作为云原生的基础特性之一可以说是不可或缺的功能组件,从大数据时代的老牌的Zookeeper到到Docker Swarm采用的Consul,再到k8s中集成的分布式键值数据库etcd和DNS服务发现CoreDNS都是其中的佼佼者。远程调用服务(Remote Procedure Call):广义上的远程调用一般分为两种,一种基于HTTP协议,一种基于RPC,而狭义的远程调用一般指的RPC。比较常用的RPC框架有 Google 开源的 gRPC和 Apache 旗下的 Thrift 框架,k8s是采用 gRPC 框架作为服务间调用。服务代理(Service Proxy):平常用的最多的服务代理应该就是nginx了,作为一个高性能支持正向和方向代理的服务器, nginx具备成熟和广泛的应用场景。envoy 则是一个新生的用go写的服务代理,像Istio、Ambassador的服务代理就是采用了envoy,因此在云原生应用中 envoy 也具备强大的生命力。API网关(API Gateway):API网格主要起到对所有的API的调用进行统一接入和管理、认证、授权等功能。ambassador、traefik、kong等都是优秀的微服务网关。服务网格(Service Mesh):服务网格是用于控制应用的不同部分之间如何共享数据,服务网格是内置于应用程序中的专用基础架构层,用于记录应用的不同部分是否能正常交互。服务网格可以更细粒度地为每个服务提供限流、管控、熔断、安全等功能。Istio 是最流行的 Service Mesh 之一,其以易用性、无侵入、功能强大赢得众多用户青睐,相信不久将来应该有可能会成为服务网格的事实标准。

各种应用和工作负载逐渐运行在k8s之上,有个比喻特别好,就是k8s是云原生的操作系统,而运行在k8s之上的容器应用就像电脑的app一样


云原生存储(Cloud Native Storage):随着数据库、消息队列等中间件逐步在容器环境中得到应用,容器持久化存储的需求也逐步增多,随之而来的是建立一套基于云原生的存储系统,在k8s中对应的就是CSI——容器存储接口。持久化存储中用的比较多的是Ceph,作为一个分布式存储系统,Ceph提供较好的性能、可靠性和可扩展性。容器运行时(Container Runtime):容器运行时就是指容器的运行环境,比如最常用的Docker。除了docker,还有一个比较著名的开源容器运行时标准组织(Open Container Initiative),简称OCI。OCI由Linux基金会于2015年6月成立,旨在围绕容器格式和运行时制定一个开放的工业化标准,目前主要有两个标准文档:容器运行时标准 (runtime spec)和 容器镜像标准(image spec),Containerd就是一个满足OCI规范的核心容器运行时。云原生网络(Cloud Native Network):容器的网络方案,为容器集群提供一层虚拟化的网络,像k8s的CNI就是其中一个标准的网络接口,flannel是 CoreOS 公司主推的容器网络方案,现在现在比较主流的一种网络之一。

Kubernetes的分层架构:核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)接口层:kubectl命令行工具、客户端SDK以及集群联邦生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等


自动化与配置(Automation & Configuration):用于自动化部署和配置容器运行平台和环境,代表工具包括Ansible、Chef、Puppet、VMware、OpenStack。容器注册(Container Registry):容器注册是整个CNCF云原生中的重要部件,因为基于容器的运行环境中,所有的应用都需要借助容器镜像库来进行安装和部署。容器注册工具主要分公有工具和私有工具,公有的容器镜像库主要包括docker官方的registry,在私有镜像库最著名的是Harbor,目前市面上大量的容器平台目前都基于Harbor构建其镜像仓库。安全与合规性(Security & Compliance):安全性和合规性基本是所有系统都会面临的东西,Notary和TUF是这个领域两个主要的项目,其中TUF是一个开源的安全标准,Notary是其中一个实现。密钥管理(Key Management):秘钥管理做权限管理和身份认证,比如雅虎发布的athenz,就是一个基于RBAC的权限管理和配置。SPIFFE通用安全身份框架提供了统一的工作负载身份解决方案。



监控(Monitoring):监控主要是对运行系统和应用的状态进行观测与预警,常用的监控有Prometheus、Zabbix等,Grafana通常会配合Prometheus做图形化的展示。日志(Logging):日志采集模块,如ELK(elastic/logstash/kibana)、fluentd等。追踪(Tracing): 这里的tracing是指分布式链路追踪,因为在分布式系统中,各服务之间相互调用,一个地方出问题可以会导致很多其他服务上的组件出现连锁问题,因此在定位问题的时候十分困难,必须要建立分布式链路追踪来对错误和故障进行定位,分布式跟踪是对日志和监控指标的重要补充。OpenTracing 是一套分布式系统跟踪标准协议,为大家建立一套统一的标准来实现分布式跟踪信息的描述和传递。混沌工程(Chaos Engineering):混沌工程主要是解决在高复杂性的分布式系统之上建立起值得信任的生产部署体系,比如服务不可用时后备设置不当 ; 因超时设置不当导致反复重试 ; 下游依赖关系在接收到大量流量时出现中断 ; 发生单点故障时连锁引发后续问题等一系列混乱的难题,建立受控实验观察分布式系统。

混沌工程类似于“故障演练”,不局限于测试,而更像是工程实践。为什么这么说,通常的测试用例会有“期望结果”和“实际结果”,通过将两个结果比较,或者对用户行为的预期,来判断测试通过或失败。而混沌试验类似于”探索性测试“,试验本身没有明确是输入和预期结果,通过对系统和服务的干预,来观察系统的”反应“。我们将混沌工程原则融入在试验过程中:在生产环境小规模模拟系统故障并定期自动化执行试验,通过试验结果与正常结果进行比对,观察系统”边界“。引入混沌实践时需要了解混沌工程的五大原则。1)建立稳定状态的假设在做混沌工程实验的时候,首先得确定需要测试的指标已经做了高可用的工作,才能进行验证指标对业务的是否有影响。如果没有做好高可用工作,而引入混沌工程实验的话,对业务而言将会是一声灾难。2)多样化现实世界事件不能够凭空想像出一些事件来验证,而是引入那些真实存在的,频繁发生的,且影响重大的事件。对我们而言给这些事件做混沌实验才具有价值。如磁盘故障、网络延时、主机宕机等。3)在生产环境运行实验尽量在类生产环境中进行测试,生产环境的多样性是任何其它环境无法比拟的。混沌工程的价值就是保证生产上的业务连续不中断。4)持续自动化运行实验实施混沌工程实验一般最开始是人工手动操作,当我们对业务有足够的信心时,要把混沌实验做成持续自动化。在版本升级、不断迭代的过程中,持续不断自动化地做验证,最大程序保证业务的连续性验证。5)最小化影响范围做混沌工程的意义就是保证生产上的业务。在我们实施混沌实验时也必须保证对线上业务影响最小。在实施实验时,从小范围开始,不断扩大范围,避开高风险时段,如选择业务量最小的时候实施实验。


工具(Tools):一些工具集,,比如CNCF的landscape作为一个信息聚合网站可以用于查看各种新的软件工具、Dashbird可以用于serverless监控和故障排查工具。安全(Security):主要提供serverless的安全防护。框架(Framework):指直接用于构建、管理serverless应用的框架,比如Apex可以用于构建、发布和管理AWS Lambda,SAM 一个Python的开源serverless应用构建框架。注册平台(Hosted Platfrom):指提供第三方注册的厂商服务,比如AWS的Lambda、阿里云的函数计算服务、Google的cloud functions服务等。可安装平台(Installable Platform):这里就是用于自己搭建serverless平台的工具,比如著名的Knative,就是由谷歌开源的 serverless 架构方案。

Serve在这里非常重要,它实际上是一种带有内置Istio的组件。Istio提供了许多功能 ,例如流量管理、智能路由、自动缩放和缩放到零等,这是一个非常酷的概念。但实际上,对于非服务器应用程序,开发者希望的是可以扩展到1000个数据包,并且当没有人访问时,将其恢复为0。那么,让我们看看Knative Serve 是如何工作的。首先,在启动一个传统的microservice或function后,该服务指向并管理两个不同的事物:1)Route 2)Config。Knative Serve为我们提供了快照,提供了智能的、可拓展的路由。使用Istio流量管理功能,实际上可以通过Route管理所有流量,并将它们路由到新旧两个版本中的一个或多个中,我们可以这么假设,如所有流量的10%被路由到版本2,90%停留在版本1上。


声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号