深入了解Redis主从复制:一文掌握核心知识
发表时间: 2020-02-07 23:10

redis主从复制是redis相关知识中比较常见的知识,也是比较重要的知识点,本片文章主要主要来写一下redis主从复制的原理实现(全量复制及部分复制),以及它们之间的检测机制,还有一些实际运用中会出现的问题。
主从复制,即有两个角色,主节点和从节点,数据从主节点复制到从节点,且不能逆向复制。

通过向从节点发送 SLAVEOF 命令,可以让主从复制开始工作,以下为具体步骤。
SLAVEOF 127.0.0.1 6379 此命令指定了主节点的地址及端口,表示从节点要从127.0.0.1:6379来复制数据
在SLAVEOF 命令执行之后,从服务器根据设置的ip及port,会创建一个连向主节点的套接字连接,如果连接成功,那么从服务器将为这个套接字关联一个专门用于处理文件事件处理器,负责以后的复制工作,如接收RDB文件,以及接收主节点传输过来的写命令。
从节点成为主节点的客户端之后,首先会发送一条PING命令,此时的PING命令有两个作用:
从节点在发送PING命令之后,将会遇到一下三种情况:
从节点收到主节点的PONG回复之后,下一步就该确认是否进行身份验证
从节点在身份验证阶段可能遇见以下几种情况:
所有的错误情况都会使从节点终止复制工作,并从创建套接字开始重新执行复制,直到身份验证通过,或者从节点放弃复制为止。
在身份验证之后,从节点将执行命令REPLCONF listening-port port,主节点将把端口信息记录在自己的客户端状态信息中
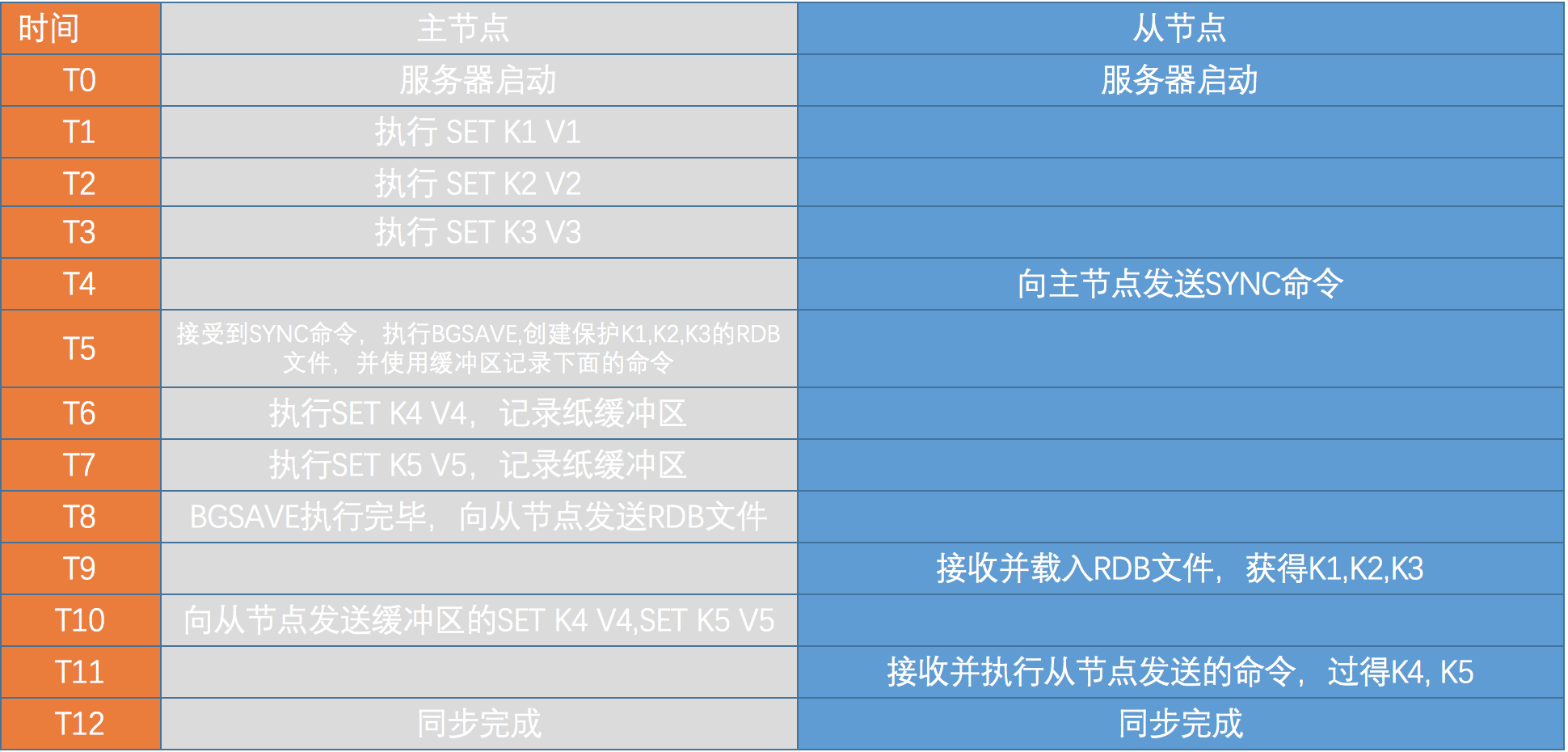
127.0.0.1:6379> info replication# Replicationrole:masterconnected_slaves:2slave0:ip=127.0.0.1,port=6380,state=online,offset=137741805,lag=0slave1:ip=127.0.0.1,port=6381,state=online,offset=137741805,lag=0master_repl_offset:137741805repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:136693230repl_backlog_histlen:1048576旧版的同步功能需要从节点向主节点发送sync命令来完成,步骤如下:
1.从节点向主节点发送SYNC命令
2.收到SYNC命令的主节点执行BGSAVE命令,在后台生成一个RDB文件,并使用一个缓存区记录从现在开始执行的命令
3.当主节点的BGSAVE命令执行完毕时,主节点会把BGSAVE生成的RDB文件传送给从节点,然后从节点接收到这个RDB文件,将自己的数据库状态更新至此RDB文件的状态
4.主节点将记录在缓冲区里所有的写命令发送给从节点,从节点执行这些命令后,保证此时主从的数据库状态相同
过程如图所示:
旧版同步的缺陷
同步可以分为两个情况,第一是初次同步,第二是断线后同步,这个缺陷就是在断线后同步时,继续一遍上面的步骤,虽然这个同步的数据没有问题,但是其实很多数据是没有必要复制的。
耗费资源的SYNC命令:
执行SYNC命令主从节点需要做以下事情
在此,从节点会使用PSYNC代替SYNC命令,从节点会向主节点发送PSYNC命令,执行同步操作,并将自己的数据库状态更新至主节点数据库所处的状态。
PSYNC命令分两种模式,一个是完整同步操作,一个是部分同步模式。
部分同步的功能主要由下面三个部分构成:
执行复制的双方,主从节点都分别维护这一个复制偏移量 主节点每次向从节点传播N个字节的数据时,就会将自己的复制偏移量加N。同理,从节点每次收到主节点传播来的N个字节的数据时,也会将自己的复制偏移量加N
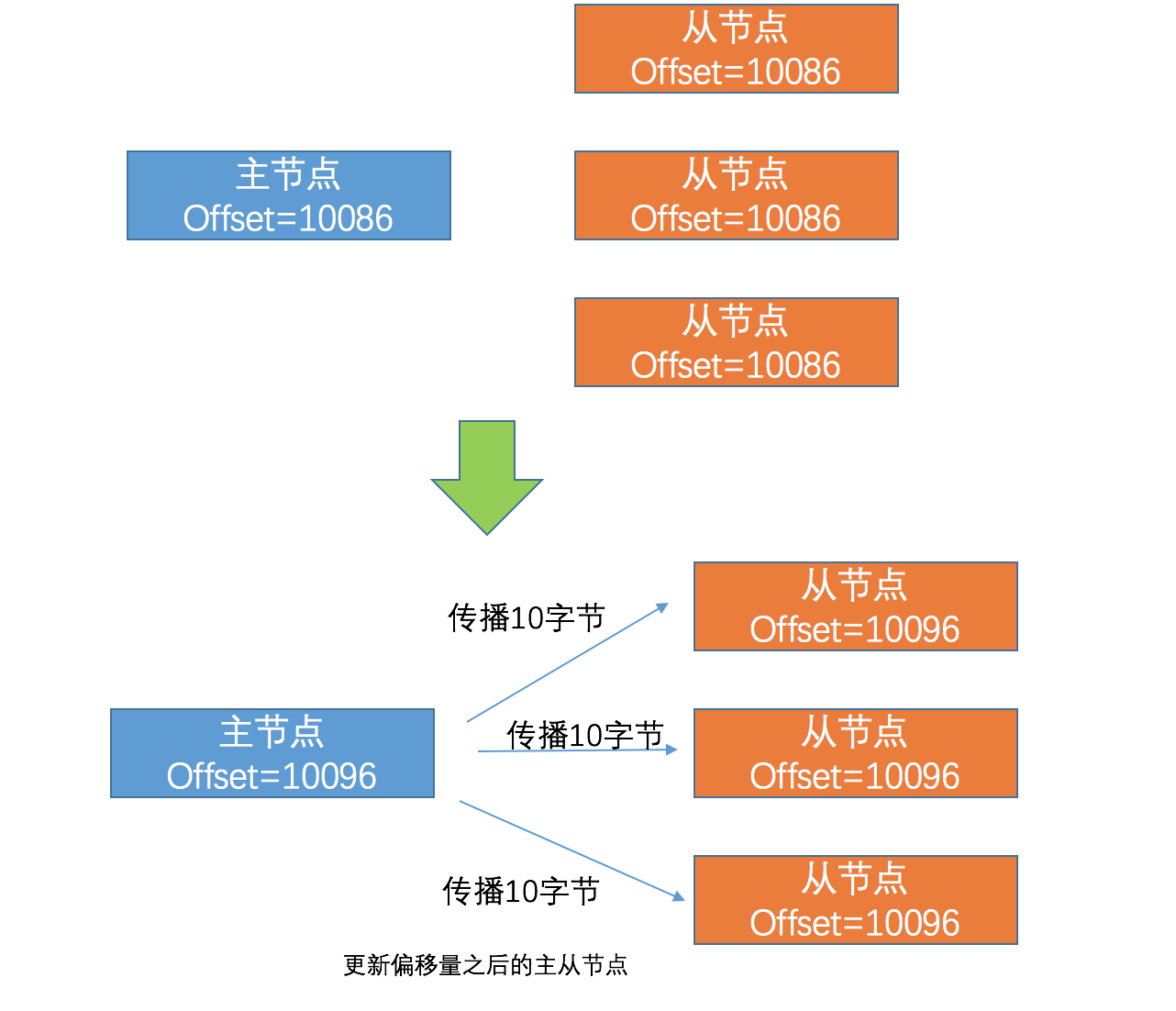
通过对比主从节点的复制偏移量,可以确定主从节点是否处于一致状态
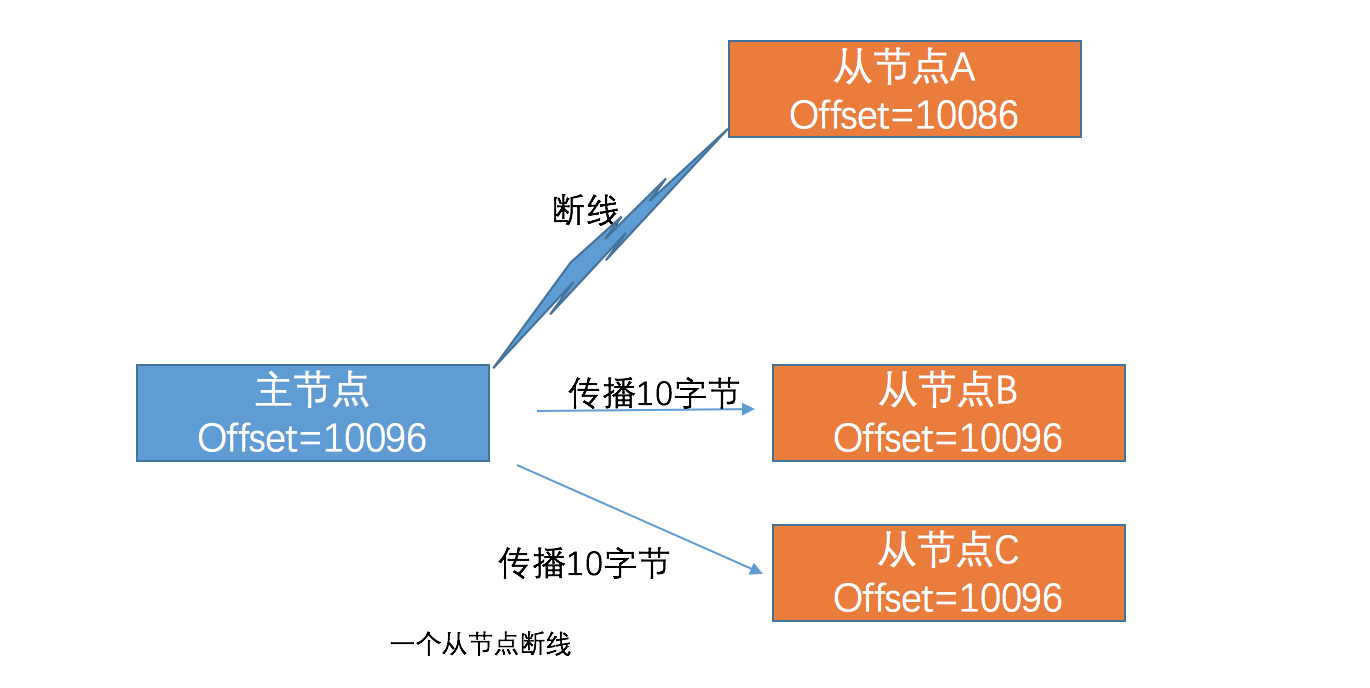
如上图所示,假设正在复制的从节点A断线了,主节点传过来的字节数据收不到了,此时从节点A的偏移量(offset)和主节点的不一致了,过了一段时间,从节点A又成功连接至主节点,接下来它是怎么样和主节点数据保持一致呢,这就要说到复制积压缓冲区了。
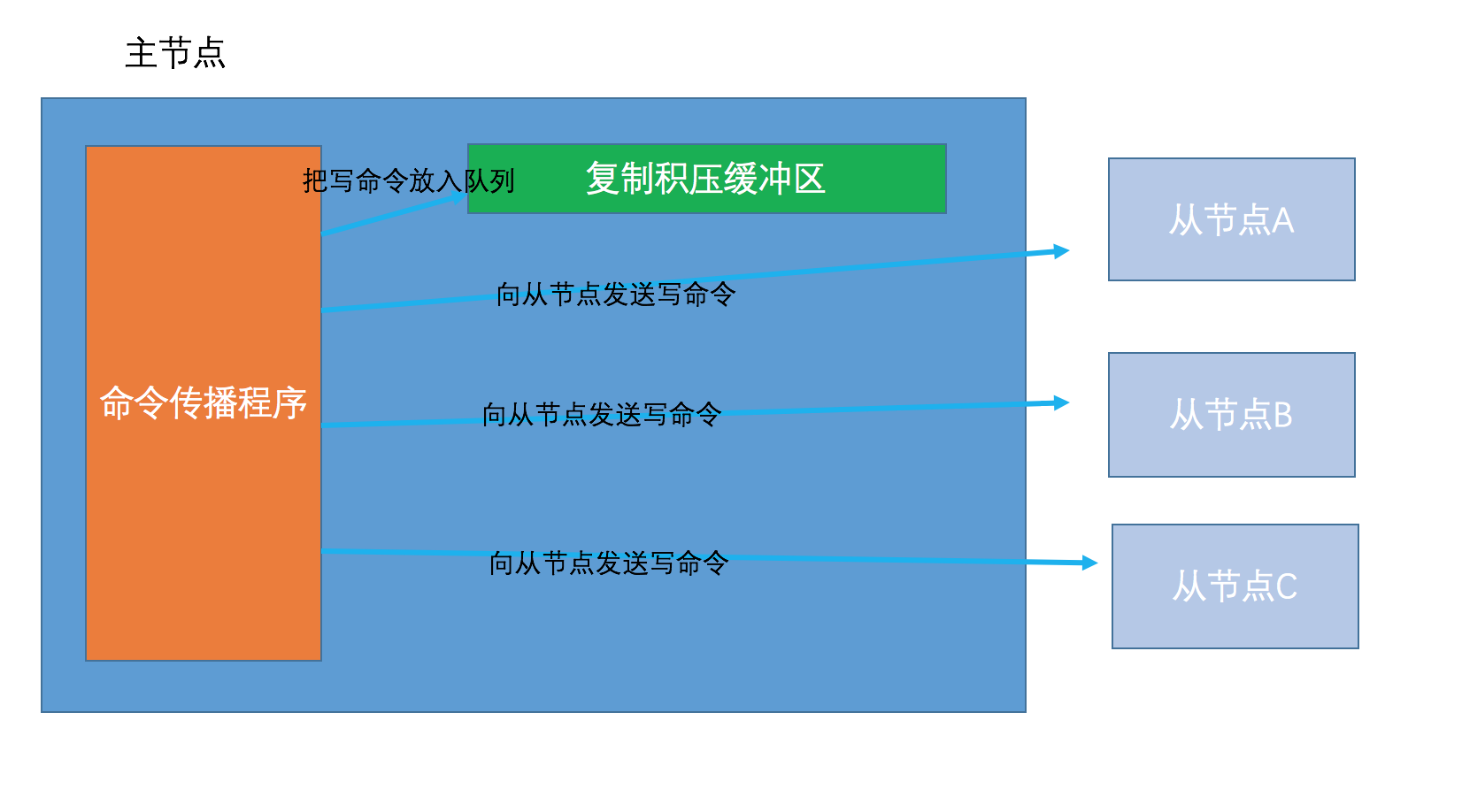
复制积压缓冲区是一个由主节点维护的固定长度先进先出的队列,默认大小为1MB。
当主节点向从节点进行命令传播的时候,它不仅会把命令发送给所有的从节点,还会将命令入队到复制积压缓冲区中,如下图所示。
那么复制积压缓冲区里面到底是什么按照格式存储的呢,它会为每个字节记录相应的偏移量,其构造如下图所示:

复制积压缓冲区大致就是这样了,下面来说一下当从节点A重新连上主节点后的是什么样的情况。
除了复制偏移量和复制积压缓冲区之外,部分不同还需要服务器运行id
当从节点对主节点进行初次复制时,主节点会将自己的运行id传给从节点,从节点会把这个id保存起来。当从节点断线并重新连接上一个主节点时,从节点会向当前的主节点发送之前保存的运行id
当完成同步之后,主从节点进入命令传播阶段,此时主节点只需要将自己的写命令发送给客户端,从节点接收并执行主节点发送过来的写命令即可。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号