探索AIGC桌面端算力的新趋势
发表时间: 2024-06-05 15:42

这两年AI大模型正在遍地开花,并且各家也在不断探索实际的落地场景,其中视频生成算是当下的热门领域。
C端,有我们前面讲过的图生视频大模型App,一张照片就能生成自定义的舞蹈视频。B端,大模型也在逐渐融入到影视行业的制作流程中。
就在今天,算力方案提供商宁畅发布了首支由AIGC生成的微电影——《宁畅星球:算力之战》。简单来说,这部片子的剧情主要讲述了,未来的地球文明在AI算力的加持下高度繁荣,然而外星侵略者觊觎地球的算力,由此展开了一场未来人类与入侵者之间的算力争夺大战。

虽然剧情叙事比较简短、单一,但我们看下来还是觉得这个活儿整得挺好的:
一方面,片子中的AI人物角色以及场景设定都参考了宁畅自己的产品(工作站&服务器),并且做出来的效果确实挺炫酷的,看得出来是用心了,不是那种硬套模板的货色。
另一方面,宁畅提供算力支持。作为B端算力方案提供商,宁畅在推出AI工作站时,更加注重与用户的使用场景进行结合,通过AIGC微电影的这种形式来告诉目标客户:“用我们的机器就能够创作出类似的效果。”

除此之外,宁畅在今年3月份的时候还发布了他们的“全局智算”战略,用来帮助企业级的AI应用落地。
可以这么说,如今推动AIGC产业的实际落地,已经是AI工作者、企业以及算力提供商们的一致共识。
其实早在宁畅发布这部微电影之前,我们就已经看过很多使用AIGC创作的短片作品了。比如之前B站UP主特效小哥就尝试过,只花5天时间利用AI在快速地创作出一条1分多钟的CG短片。
他们通过文本大模型来创作剧本,利用Stable Diffusion(图像生成大模型)来提升画面丰富程度,再用AI动捕来替代传统的惯性动捕,最后配合人工的建模和剪辑,创作出了这条效果还不错的CG短片。
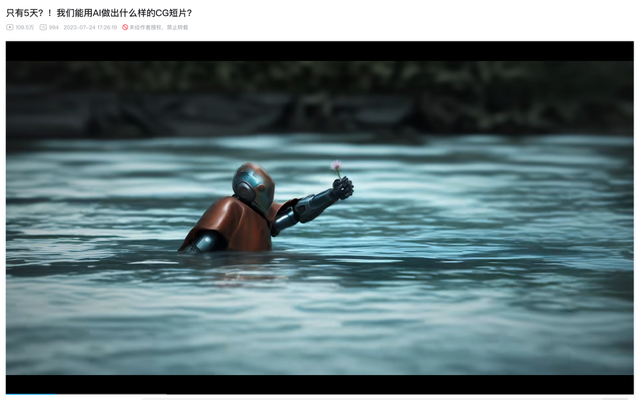
在这其中,AI的作用主要还是减少了很多重复繁琐的操作,让特效小哥的团队可以专注于创意和细节方面,不然很难在短短5天内完成这么一支画面稳定、故事完整的CG短片。
再比如,像今年的第十四届北京国际电影节还首次开设了AIGC单元,涌现了一大批优秀的AIGC短片。而像Netflix这种流媒体平台也于去年制作了首支AIGC动画——《犬与少年》。

现在的AIGC影视作品,早已不是过去那种的“小打小闹”,接下来的目标是拿电影节大奖,以及做成真正可以给观众欣赏的作品来变现。
在这个背景之下,我们发现这场新时代的AIGC“淘金热”有愈演愈烈的趋势,而在这个狂热的年代里,“卖铲子的商人们”也在想着怎么从中分一杯羹。
不过,这个“卖铲子”的生意这两年可不太好做,因为实在卷得太厉害了。基础大模型领域有“百模大战”,前不久我们才刚写过国产大模型都在争“地板价”;而算力底座领域也是“神仙打架”,根据行业的不完全统计,仅2023年全国新建的智算中心项目就超过100个,总建设规模成本以百亿计算。
前面没跟大家解释清楚,可能有些朋友不太明白这个智算中心的作用。所谓智算中心,其实全称应该是人工智能计算中心,它由数以千计甚至数以万计的高性能GPU计算卡构成,可以提供强大的算力支持,既能拿来训练AI大模型,又能用来做影视后期的渲染工作。
而在各家打得火热的同时,开头提到的那家厂商宁畅,基于自身对于AI算力领域的深耕和理解,发现了一个新的方向,或者说是新的需求——不同发展阶段、不同业务的客户对于AI支撑能力有着越来越复杂的需求,不能再像以前那样粗放式的“堆卡”“堆算力”了。
基于这个需求,宁畅给出的答案是“全局智算”战略,通过“全栈全液”AI基础设施方案,来为智算中心的构建和大模型的落地提供有力的支撑。
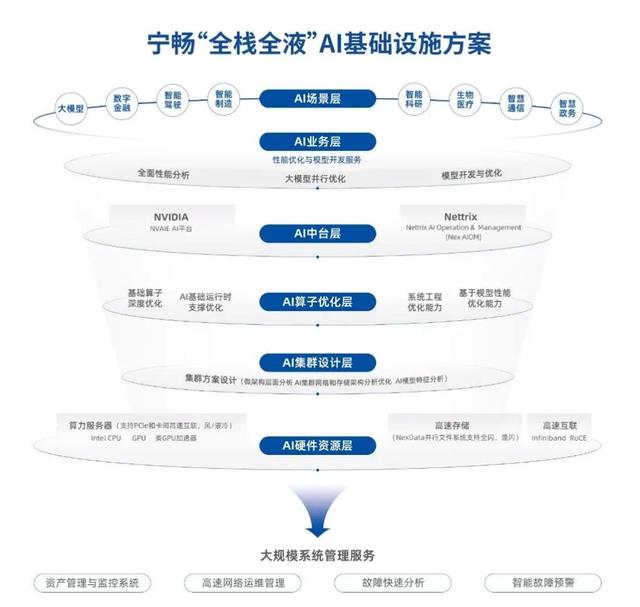
我们分析了一下这个方案,发现它有两大特点:一个是更加精细化,有数据指出目前整体算力的利用率大概只有30%,存在比较严重的资源浪费情况,所以宁畅从计算、存储、网络、建设、管理、应用以及液冷等方面,去充分地提升算力的利用率,推进算力朝着高质量的水平发展。
另一个是提供全流程、全场景的定制化服务,打个比方:在设计AI集群方案之前,宁畅会先咨询客户需求,把需求聊透了,再根据客户的业务场景、发展阶段、成本预算等等,来给出更具实用性和适用性的方案。
说起来,宁畅这家成立于2019年的年轻企业,之所以能够在老牌林立的服务器行业中杀出一片天,在2023年全年中国液冷服务器厂商市场中份额排名前三,主要就是因为他们有明锐的市场洞察以及灵活的服务器定制化服务。
所以,当已经在AI算力领域早有布局的宁畅提出“全局智算”这个战略后,我们可以看出,宁畅的野心确实有点大,他们想要在AI算力争夺战中拔得头筹。
不过,既然是全局智算,那么宁畅自然也不单单只着眼于构建大企业所需要的AI全栈能力,于是他们又把目光看向了中小企业的算力需求。
目前宁畅的AI算力栈是由128台GPU服务器组成的千卡算力集群,虽然他们有不同的算力方案给客户选择,但对于中小企业来说,他们的算力需求可能没有那么高,也没有那么多经费去跑那么多次的云计算推理,所以用电脑或者工作站来开发和部署本地AI大模型,是一个比较有性价比的选择。
在看准了这点之后,宁畅就推出了咱们前面提到的AI工作站W350 G50,用来补上“全局智算”的重要一环。

这台工作站能以桌面终端的形态提供强大的算力,因为它的GPU可选NVIDIA RTX™ 4000 Ada & RTX™ 5000 Ada。跟游戏显卡不同,RTX™ 4000 Ada & RTX™ 5000 Ada这类专业图形卡,支持的OpenGL驱动更加全面,可以很好地兼容各种工业3D设计软件。
其中RTX™ 4000 Ada能够以单槽PCI-e结构能提供出色的性能和功能,对于专业人员来说,在进行创作、设计以及工程等工作流的时候,能够提供更好的流畅性和图像渲染效果。
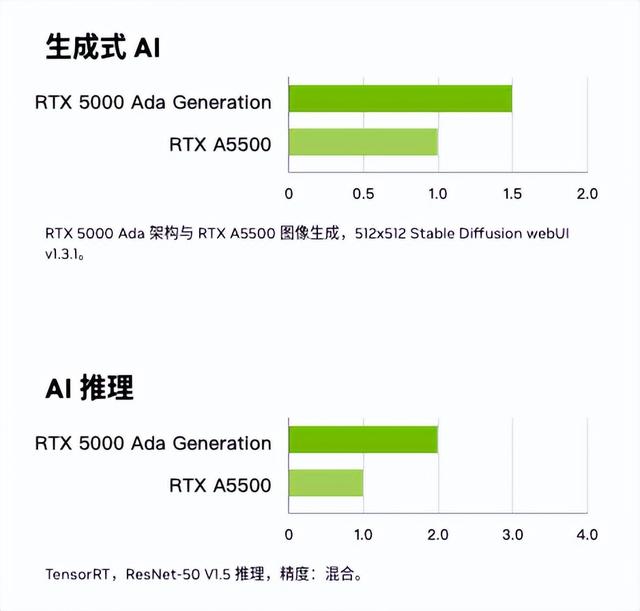
而RTX™ 5000 Ada 采用了 NVIDIA Ada Lovelace 架构,在AI性能上有了很大突破,相比前代(RTX™ A5500),它的AI推理能力提升了2倍,生成式AI能力提升了1.5倍,并且还有32GB的大显存,基本可以满足AIGC创作以及各种专业工作流的需求。
在处理器上,W350 G50搭载的是英特尔至强W-2400和W-3400系列,最高可以选择56 核心112线程版本。不同于消费级的酷睿系列,企业级的至强CPU专为高端计算和数据中心而设计,拥有更强的单核和多核性能,可以更好地满足复杂的计算任务和超高的工作负载,而且更重要的一点是,至强会更加稳定,更能应对一些严苛的工作环境。
除了性能强之外,W350 G50工作站的部署也相当灵活,它可以当做桌面上的塔式工作站用,也可以作为微型服务器组成企业的数据中心,相当于说买了它的企业万一以后有搭建机房的想法,那么就不用再去购置新的服务器了,可以把这些工作站利用起来搭建成自己的集群。
至于支持IPMI远程管理、冗余电源、企业级部件这些工作站该有的操作,W350 G50也都安排上了。
而从应用场景来看,在RTX™ 4000 Ada & RTX™ 5000 Ada的AI能力加持下,W350 G50其实非常适合中小企业用来搞AI大模型的开发和前期验证。
我们了解到,之前已经有AI个人工作者和工作室在使用高配置的PC或者Mac Studio来训练AI大模型,以及跑本地的技术验证,虽然效率低、跑得不是很快,但胜在成本低。
不过,这种模式并不是特别适合中小型企业,因为相比之下,企业对于效率和效益有着更高的追求,所以用W350 G50这类专业工作站来跑大模型会相对合适点。
而且工作站的适用面也更广,对于制造、影视、设计、动画以及建筑等行业用户来说,日常会用到很多专业软件,无论是3D建模、后期渲染,还是进行一些创意设计,这些活儿用工作站来干都会更加高效,并且现在很多专业软件当中已经内置了AI工具了,可以更好地提升效率。
就比如NVIDIA Canvas这个AI插件,它可以将简单的涂鸦生成一幅逼真的风景图,大大节省了建模或者拍摄的时间,而这也是搭载了RTX™ 4000 Ada & RTX™ 5000 Ada 的W350 G50工作站能够做到的众多功能之一。

不难看出,未来当AIGC产业发展到一定高度、解决了落地场景之后,算力资源将会成为各家争抢的重点,到时候比的就是谁家的AI可以更好更快地满足需求。
那么对于宁畅这样专注于算力服务的厂商来说,新发布的W350 G50工作站与业界领先的“全栈全液”智算中心建设能力,无疑为其开辟了未来无限可能的图景。当然,这笔“卖铲子”的生意也将会随着更多玩家的入局,迎来更加激烈的角逐。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号