华为云:大规模AI训练集群的稳定性之道
发表时间: 2024-04-25 16:46
近日,华为云香港峰会在港隆重举办,本次峰会以“加速智能跃迁”为主题,汇聚了政府领导、行业专家、企业领袖、合作伙伴等超过500位代表参加,共同探讨技术创新、深耕行业、繁荣生态等热点话题。
在AI创新先锋论坛上,华为云SRE高级专家童琳发表《华为云昇腾AI云服务大规模训练集群稳定性实战》主题演讲,与现场参会客户分享确定性运维AI大规模训练集群面临的挑战及端到端的解决方案与实践经验。

华为云SRE高级专家童琳现场分享
为了应对上述挑战,华为云在内部成熟运维平台基础上,针对AI集群构建一套从异常感知、诊断到故障自愈的完整闭环能力,确保集群的稳定性和高效性,从而提高企业的生产效率和降低成本。
故障感知阶段,通过故障发现和预测,尽可能先于客户发现隐患。在华为内部构筑内存、主机、光模块等对象的故障提前预测能力,通过采集流特征(大小、时延、路径)并进行建模,实现业务流量画像,同时感知系统持续自动采集网络连接拓扑和流量路径拓扑变化,为诊断提供全面的数据支撑。
故障定位困难基于业务流量画像模型,结合流特征实时的差异性变化。快速识别网络拥塞问题,同时结合关联性指标、日志和告警,快速进行故障根因溯源和推荐。
决策恢复阶段,基于设定好的故障预案模型,实时计算故障影响面分析。决策系统使用最优策略来进行端口隔离、流量调度和任务迁移来恢复业务。
华为云昇腾AI云服务依托大数据分析能力,构建ms级高精度指标采集、存储、分析能力,支持网卡队列拥塞、丢包的秒级感知能力,10s内发现故障时针对隐形丢包构建链路级全覆盖的黑盒拨测系统,实现链路级、慢网络等故障可感知。
在光模块故障检测和预测方面,华为云昇腾AI云服务基于历史故障特征、日志特征和指标特征(电流/电压、温度、光功率等)和时间维度等综合因素,结合故障模型以及回归分析AI算法来识别已经发生的故障光模块,以及正在发生指标劣化但尚未发生故障的光模块,在业务受影响之前,替换掉将会发生故障的光模块。
华为云昇腾AI云服务通过自主创新全链路诊断系统,能秒级识别训练任务中的任意1台源和1台目的主机的流量拓扑路径,结合实时拓扑中对象的指标、日志、告警等,基于华为云已有故障模式库和专家知识库,能在分钟级准确识别故障单元(端口、模块等),该技术目前广泛使用在华为云内部,保障了故障定界时长<5min;平台具备全自动化故障预案处理能力,支持端口故障隔离、网络流量调度、训练任务迁移等模式,根据故障点进行最优决策。
华为云总结出的确定性运维体系及解决方案,帮助客户保障稳定性,通过两大专业服务+六大云上工具套件帮助企业重构“管云”模式,实现稳定可靠、安全可信、资源高效、业务敏捷的运维转型,让运维团队可以成为变革的构建主体,未来企业可以结合自身现状,完成从传统维护向IT平台服务的转型,提升运维效率和管云效能。
云运维中心(COC)作为确定性运维理念落地的产品载体,依托于华为云确定性运维实践下的运维平台,构筑一套从异常感知、诊断到故障决策自愈的完整闭环,通过故障预测预防、全链路诊断、故障隔离和流量调度等关键技术,大幅提升昇腾AI云服务AI集群的稳定性,相比传统自建AI集群大幅缩短MTTR,给企业运维效率带来极大的提升,华为云已上线一站式运维平台COC,已在中国站和国际站公测。
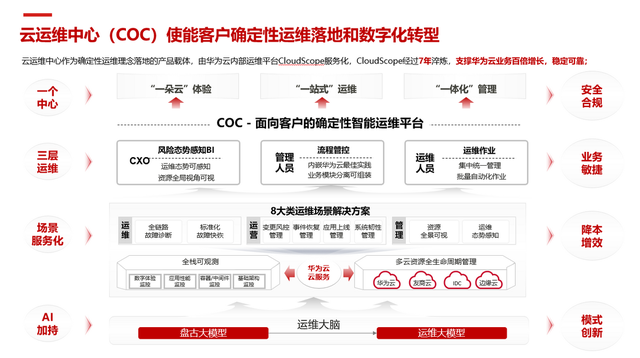
COC产品解决方案
未来,华为云结合多年的的最佳实践与行业智慧融合,为企业提供更为完善的运维解决方案,通过服务化能力开放给千行万业,支撑华为云业务百倍增长,稳定可靠,加强企业组织变革和政企智能升级,让运维成为智能世界变革的加速器。
关注@华为云,了解更多资讯
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号