深度解析PostgreSQL数据库执行计划,值得收藏
发表时间: 2020-12-28 00:07
postgresql查询规划过程中,查询请求的不同执行方案是通过建立不同的路径来表达的,在生成许多符合条件的路径之后,要从中选择出代价最小的路径(基于成本运算),把它转化为一个计划,传递给执行器执行,规划器的核心工作就是生成多条路径,然后从中找出最优的那一条。而这也就是今天要讲的内容,PG数据库执行计划。
Explain 子句可以展示和分析执行计划。
其语法如下:
EXPLAIN Name EXPLAIN-- show the execution plan of a statement Synopsis EXPLAIN [ ( option [, ...] ) ] statement EXPLAIN [ ANALYZE ] [ VERBOSE ] statement where option can be one of: ANALYZE [ boolean ] VERBOSE [ boolean ] COSTS [ boolean ] BUFFERS [ boolean ] FORMAT { TEXT | XML | JSON | YAML }说明:
》》执行计划解读,自底向上,自右向左,常用方法如:
--添加analyze实际执行来获得执行计划,可不加explain analyze select * from test_table;--只看执行路径,不看costexplain (costs false) select * from test_table;--通过实际执行来看代价和缓冲区命中情况explain (analyze true,buffers true) select * from test_table;评估路径优劣的依据是用系统表pg_statistic中的统计信息估算出来的不同路径的代价(cost),PostgreSQL估计计划成本的方式:基于统计信息估计计划中各个节点的成本。PostgreSQL会分析各个表来获取一个统计信息样本(这个操作通常是由autovacuum这个守护进程周期性的执行analyze,来收集这些统计信息,然后保存到pg_statistic和pg_class里面)
用于估算代价的参数(postgresql.conf)如下:
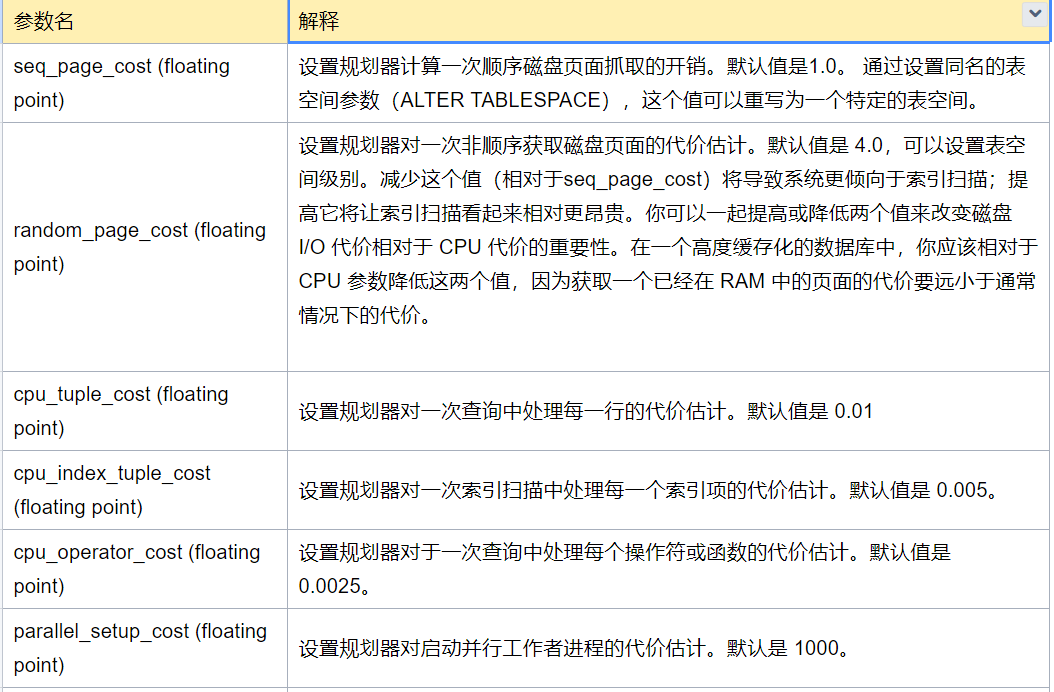
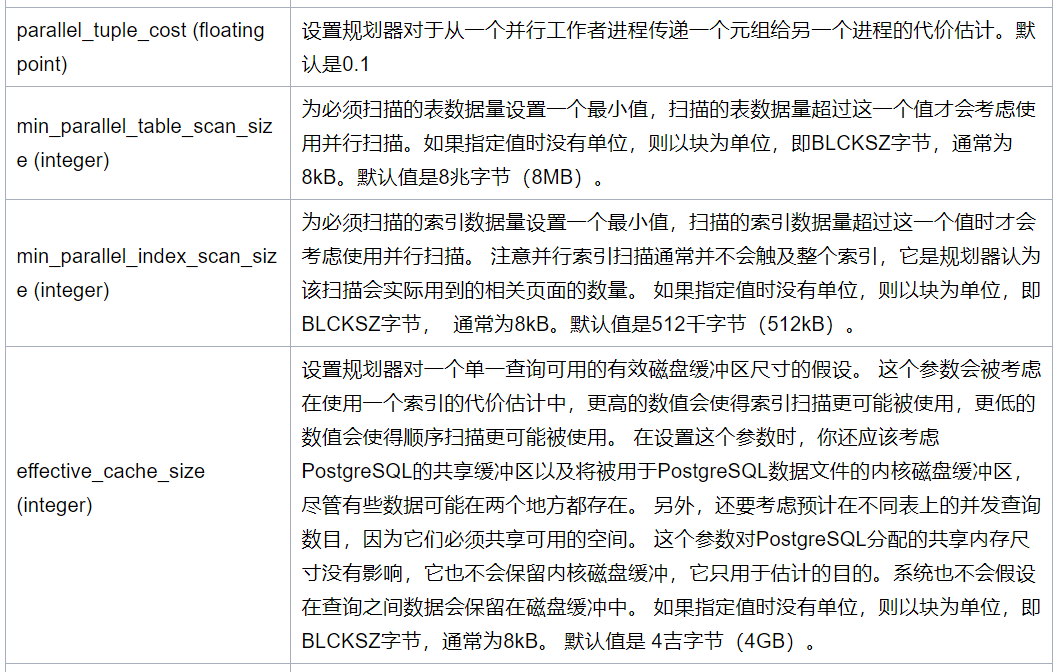

》》代价计算
一个路径的估算由三部分组成:启动代价(startup cost),总代价(totalcost),执行结果的排序方式(pathkeys)
代价估算公式:
总代价=启动代价+I/O代价+CPU代价(cost=S+P+W*T)P:执行时要访问的页面数,反应磁盘的I/O次数T:表示在执行时所要访问的元组数,反映了cpu开销W:表示磁盘I/O代价和CPU开销建的权重因子enable_seqscan:是否选择全表扫描
enable_indexscan:是否选择索引扫描
enable_bitmapscan:是否选择位图扫描
enable_tidscan:是否tid扫描(类似oracle rowid)
enable_nestloop:多表连接时,是否选择嵌套循环连接
enable_hashjoin:多表连接时,是否选择hash连接
enable_mergejoin:多表连接时,是否选择merge连接
enable_hashagg:多表连接时,是否使用hash聚合
enable_sort:是否使用明确的排序。
GEQO是一个使用探索式搜索来执行查询规划的算法。它可以降低负载查询的规划时间。 同时,GEQO的检索是随机的,因此它的规划可能会不可确定。遗传查询规划器(GEQO)是一种使用启发式搜索来进行查询规划的算法。它可以降低对于复杂查询(连接很多表的查询)的规划时间,但是代价是它产生的计划有时候要差于使用穷举搜索算法找到的计划。
PostgreSQL中GEQO实现的特点有:
• 一种稳态 GA(遗传算法)(在种群中替换适应度最差的个体,而不是整代替换)的使用允许对改进的查询计划快速收敛。这对在合理时间内处理查询是最重要的;
• 边重组杂交的使用特别适合于通过GA为TSP的解决方案保持低丢边率;
• 遗传操作符变异被废弃,这样不需要修补机制来产生合法的TSP旅行。
相关参数如下:

在PostgreSQL的执行计划中,是自上而下阅读的,通常执行计划会有相关的索引来表示不同的计划节点,其中计划节点类型分为四类:控制节点(Control Node),扫描节点(Scan Node),物化节点(Materialization Node),连接节点(Join Node)。
5.1、控制节点:
append,组织多个字表或子查询的执行节点,主要用于union操作。
5.2、扫描节点:
用于扫描表等对象以获取元组
Seq Scan(全表扫描):把表的所有数据块从头到尾读一遍,筛选出符合条件的数据块;
Index Scan(索引扫描):为了加快查询速度,在索引中找到需要的数据行的物理位置,再到表数据块中把对应数据读出来,如B树,GiST,GIN,BRIN,HASH
Bitmap Index/Heap Scan(位图索引/结果扫描):把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图列表的数据文件把对应的数据读出来,先通过Bitmap Index Scan在索引中找到符合条件的行,在内存中建立位图,之后再到表中扫描Bitmap Heap Scan。
5.3、物化节点:
能够缓存执行结果到缓存中,即第一次被执行时生成的结果元组缓存,等待上层节点使用,例如,sort节点能够获取下层节点返回的所有元组并根据指定的属性排序,并将排序结果缓存,每次上层节点取元组时就从缓存中按需读取。
Materialize:对下层节点返回的元组进行缓存(如连接表时)
Sort:对下层返回的节点进行排序(如果内存超过iwork_mem参数指定大小,则节点工作空间切换到临时文件,性能急剧下降)
Group:对下层排序元组进行分组操作
Agg:执行聚集函数(sum/max/min/avg)
条件过滤,一般在where后加上过滤条件,当扫描数据行时,会找出满足过滤条件的行,条件过滤在执行计划里面显示Filter,如果条件的列上面有索引,可能会走索引,不会走过滤。
5.4、连接节点:
对应于关系代数中的连接操作,可以实现多种连接方式(条件连接/左连接/右连接/全连接/自然连接)
Nestedloop Join(嵌套连接): 内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大,要把返回子集较小的表作为外表,且内表的连接字段上要有索引。 执行过程为,确定一个驱动表(outer table),另一个表为inner table,驱动表中每一行与inner table中的相应记录关联;
Hash Join(哈希连接):优化器使用两个比较的表,并利用连接属性在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行;
Merge Join(合并连接):通常hash连接的性能要比merge连接好,但如果源数据上有索引,或结果已经被排过序,这时merge连接性能会优于hash连接;
PG执行计划常见运算类型如下:


后面会分享更多devops和DBA方面内容,感兴趣的朋友可以关注下!

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号