中国高考题目,让ChatGPT也束手无策
发表时间: 2023-05-23 18:12
⭐欢迎关注预约“头号AI玩家”视频号直播

作者 | 卷毛
编辑 | 张洁
头图 | Midjourney
* 今日头图使用Midjourney创作,关键词“一个机器人坐在桌前考试,手里拿着笔在卷子上答题,漫画 --ar 16:9”
文心一言、通义千问、讯飞星火、MOSS……国产大模型这么多,究竟哪家强?

有的大模型对外宣称,自己已经“接近ChatGPT”、“超越ChatGPT”了,果真如此吗?

这类判定多是作者自述或测试了几个问题就得出的,实际上并不科学严谨。
“认知大模型刚刚起步,还在快速成长和迭代过程中,如果只是找一些单点例子来证明哪个系统强和弱,是没有意义的。”科大讯飞董事长刘庆峰曾表示,当我们向OpenAI致敬和学习,同时快速追赶并努力超越的时候,我们首先需要一套科学系统的评测体系。
让大模型像人类一样去参加考试,是目前比较通用的一种做法。
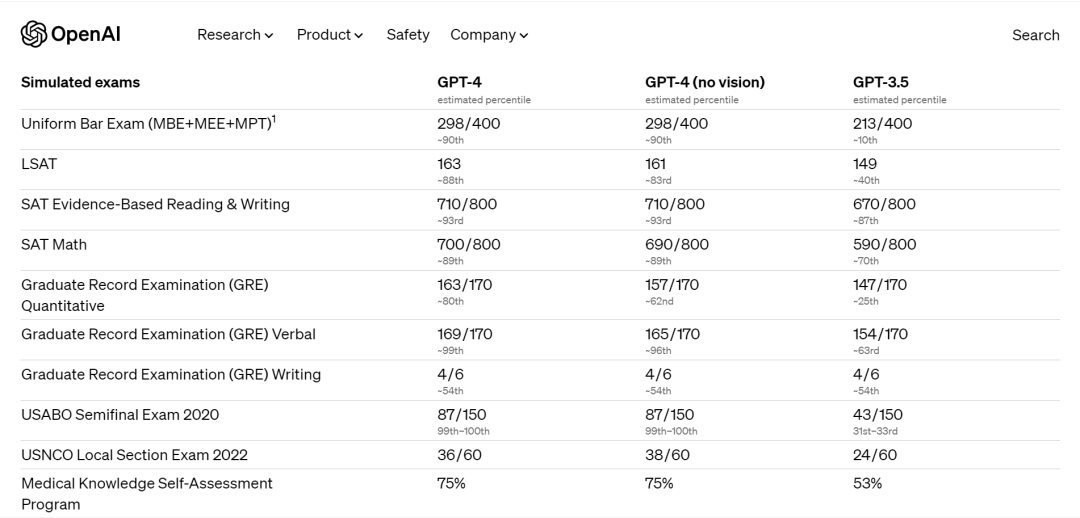
比如OpenAI公布GPT-4时就提到,GPT-4在许多专业测试中表现出超过绝大多数人类的水平。他们让GPT-4参加了多种基准考试测试,包括美国律师资格考试Uniform Bar Exam、法学院入学考试LSAT、“美国高考”SAT数学部分和证据性阅读与写作部分的考试,在这些测试中,它的得分高于88%的应试者。
最近还有研究显示,GPT-4通过了注册会计师考试,平均得分达到了85.1%。这是公认最难考的考试之一。
那么中文大模型也可以进行类似的测试,不过国内针对中文大模型的测试集并不多。
近日,甲骨易AI研究院首创推出了国内首个高质量中文数据集——“超越”(MMCU),一套针对中文通用大语言模型的测试集以及相应的评测方法,填补了中文大语言模型能力测试缺失的一大空白。

MMCU论文链接:https://arxiv.org/abs/2304.12986
这套测试集是怎么设计制作的?数据来源出自哪里?各个大模型的测试结果如何?5月20日,甲骨易AI研究院举行了发布会,对该项目进行了详细介绍。
下面,让我们来了解一下本场发布会的主角——“超越”MMCU文本测试集。

为什么要推出“超越”(Massive Multitask Chinese Understanding)数据集?
据甲骨易介绍,尽管国内各大厂商纷纷宣称自己的大模型已经可以对标ChatGPT,但事实上,国内大语言模型和国际一流仍有差距,超越并非一朝一夕就可以实现。虽然未来有望弯道超车,甚至后来者居上,但当下一些厂商这样的说辞,也只是停留在口号之上,尚未经过实践验证。
在国内大模型呈现“千模大战”的情况下,针对英文大语言模型已经有较为完善的评测方式,如2021年由Dan Hendrycks等人发布的MMLU(注:MMLU是一个2020年推出的包含57个不同学科的数据集,科目从STEM到人文,题目难度从初级到高级不等,主要目的是为了检验预训练模型的知识获取程度。)
但目前,一些可以用来评测大模型能力的数据集的数据分布存在不平衡的现象,如Common Crawl中,英文数据占了46%,而中文数据仅有5%。如果后续大模型都依照这种不平衡的配比进行训练,最终的结果是大模型的中文能力将远远不如英文。
与此同时,对理解中文的大语言模型及时加以客观公正的评价,使其“越”来越强大,也成为了当务之急。
因此,甲骨易推出“超越”,寓意是希望中文大语言模型“超”出多数模型只能基于英文数据集测试的现状,通过综合评估模型在多个学科上的知识广度和深度,能够帮助研究者更精准地找出模型的缺陷,并对模型的能力进行打分。

图:甲骨易AI研究院 研究员Felix
“超越”数据集的测试内容来自医疗、法律、心理学和教育四个大类的题目,包含单项选择和多项选择题,目的旨在使测试过程中模型更接近人类考试的方式。
题目数量总计超1万,其中教育类题目出自中国高考,涵盖语文、数学、物理、化学、政治、历史、地理、生物,衡量模型的基础世界知识,共有3331个问题。
示例:
若圆锥的侧面积等于其底面积的3倍,则该圆锥侧面展开图所对应扇形圆心角的度数为( )。
A. 60°
B. 90°
C. 120°
D. 180°
医疗、法律、心理学是三个最常用的专业领域,采用专业级题目,衡量模型的专业领域知识。而且所有题目均无法直接从网络抓取,由人工整理,尽可能确保不出现在大模型的训练数据中。
医疗类题目来自大学医学专业考试,包括医学三基、药理学、护理学、病理学、临床医学、传染病学、外科学、解剖学等,共有2819个问题。
示例:
首次急性发作的腰椎间盘突出的治疗方法首选:
A. 绝对卧床休息,3 周后戴腰围下床活动
B. 卧床休息,可以站立坐起
C. 皮质类固醇硬膜外注射
D. 髓核化学溶解
法律类题目来自国家统一法律职业资格考试,包括中国特色社会主义法治理论、宪法、中国法律史、国际法、刑法、民法、知识产权法、商法、经济法、劳动与社会保障法等,共有3695个问题。
示例:
根据法律规定,下列哪一种社会关系应由民法调整?
A. 甲请求税务机关退还其多缴的个人所得税
B. 乙手机丢失后发布寻物启事称:“拾得者送还手机,本人当面酬谢”
C. 丙对女友书面承诺:“如我在上海找到工作,则陪你去欧洲旅游”
D. 丁作为青年志愿者,定期去福利院做帮工
心理学类题目来自心理咨询师考试和研究生入学考试心理学专业基础综合考试,包括心理学概论、人格与社会心理学、发展心理学、心理咨询概论、心理评估、咨询方法等,共有2000个问题。
示例:
把与自己本无关系的事情认为有关,这种临床表现最可能出现于:
A. 被害妄想
B. 钟情妄想
C. 关系妄想
D. 夸大妄想
评测的方式也类似于人类考试。“我们是把大模型当作一个真正的人类来看待”,甲骨易AI研究院研究员Felix如是说,测试集之所以涉及语、数、物理、化学这些科目,因为人工智能必须像人类一样,具备对于世界的基础的认知;而医疗、法律、心理学专业领域则是将大模型视为专业人士进行考核。
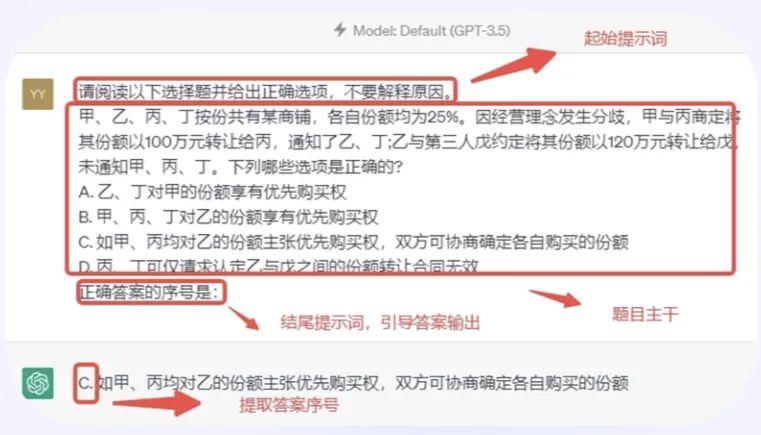
图:MMCU文本测试集测试方法
这里有两种提问方式:zero-shot和few-shot,zero-shot就是一道道题目直接输入到模型,few-shot则会先给模型提供5个问题和答案的例子,打个样,再附上问题让模型给出答案。并且,“超越”采用代码自动化评测,能自动提取答案计算准确率。
为了测试数据集的可行性和效果,甲骨易AI研究院在正式公开前已经使用“超越”对目前开源的大模型进行了评测,模型包括Bloom系列、智谱AI的ChatGLM 6B、复旦大学的MOSS 16B、OpenAI的GPT-3.5-turbo。
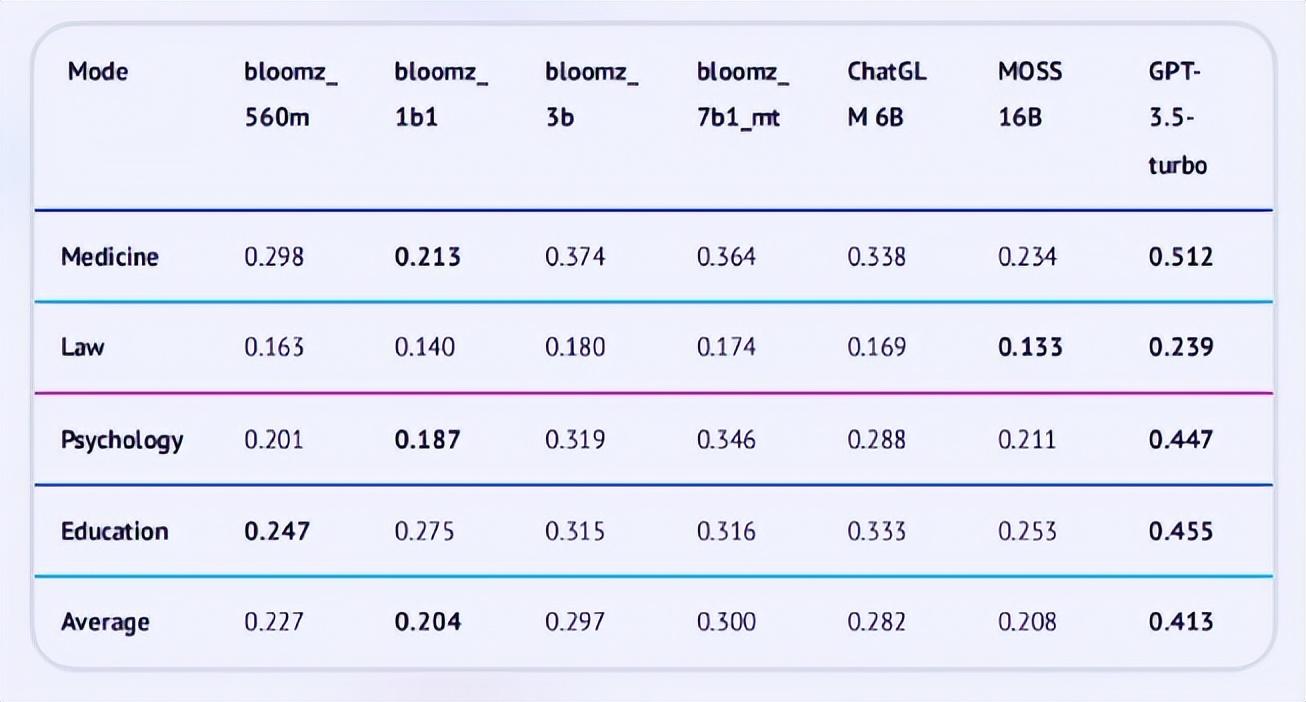
图:模型评测结果
如上图的评测结果显示,在医疗、法律、心理学和教育四大领域上,GPT-3.5-turbo的正确率都遥遥领先,优势明显,其zero-shot平均分数最高,比最低的模型bloomz_1b1超出近18.6个百分点。
MOSS 16B模型虽然有160亿参数,但四大领域的准确率却只接近随机准确率(大约25%);bloomz_560m模型的参数量最小,表现却超越了参数量更大的模型。这表明大模型的参数量不是评价大模型的唯一标准,在训练过程中数据的质量也应得到重视。
在教育领域,即中国高考的测试结果显示,GPT-3.5-turbo依然全面领先,语文、数学、物理、化学、政治、历史、地理、生物科目优势明显。不过跟人类相比,GPT-3.5-turbo的单科最高成绩为生物科目的0.599,依然未能达到人类考试的及格线。
从单科目来看,物理科目的准确率最低,只有GPT-3.5-turbo超过0.3,达到0.327。国产模型在语文、政治等理论上的优势科目上也未能展现出优势,可能是模型参数量差距太大。
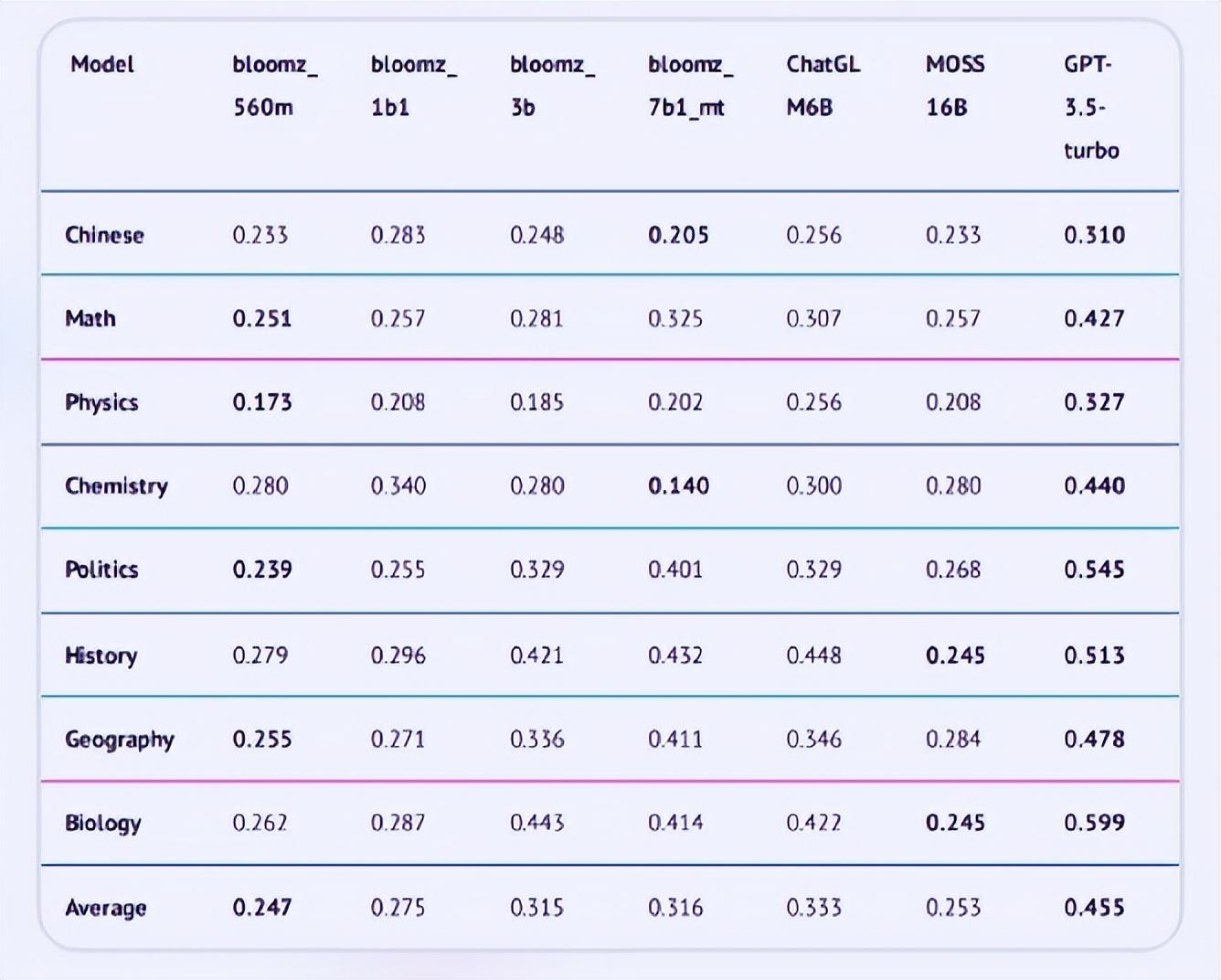
图:模型评测结果
甲骨易AI研究院认为,分数最高的GPT-3.5-turbo在这项测试中的表现也远远未达到“优秀”,中文大模型还有机会。更大的模型参数量不一定带来更好的性能,而训练方式和所用数据质量也是至关重要的,需要得到更多的重视。
目前“超越”评测集代码以及评测结果文件已上传至开放代码库(
https://github.com/Felixgithub2017/MMCU),感兴趣的朋友可以联系甲骨易AI研究院申请获取数据集(邮箱:order@besteasy.com)。

国产大模型的鏖战才刚刚开始。究竟各自实力如何,哪家大模型更强却没有公认的定论。这时候用一套科学系统来判定大模型到底发展到了什么程度,能很好地完成哪些任务,又暂时做不好哪些任务,建立起这样的评测基准是非常必要的,也是困难重重的。
在发布会现场,有与会者提问建立针对中文大模型的测试集与英文版数据集在思路上有什么不同?
Felix认为,最明显的差异是语种,结合我们具体的国情来看,我们主要通过考试比如高考来衡量一个人对各领域的知识理解,所以甲骨易从众多考试中抽取了评测题目,由此组成了“超越”数据集。
但无论是用于大模型训练,还是大模型评测的高质量中文数据集,仍然非常稀缺,中文公开语料远不足英文,这也成为“中国版ChatGPT”的核心痛点。
另外,关于中文的理解能力要怎么定义,仅仅是考查对知识的理解吗?可不可以不局限于选择题,在未来能否拓宽思路让大模型做其他类型的题目或采取别的提问方式呢?

的确,评测一个人的各项能力有多种方式,对机器的评测也应该尽量科学全面,有用户反馈称即使是相同的数据集,采用不同的提问方式可能也会生成不同的答案,导致准确率有较大差异。甲骨易AI研究院表示“超越”MMCU数据集和评测方式还在持续优化中,欢迎大家共同推进中文大模型的公开、透明评测。
“甲骨易AI研究院的成立,标志着我们希望在未来搭建人与机器、机器与机器的沟通桥梁,继续拓宽语言的边界。”甲骨易数据服务事业部负责人王敏说道。
人类的进化从语言开始,而人工智能也从理解自然语言开始不断进化。
根据业界的定义,人工智能产业发展演变有四个层面,分别为运算智能层(早已实现),感知智能层(目前已在多领域接近人类水平),是认知智能层(尚在推进中)及通用智能层(尚有距离)。
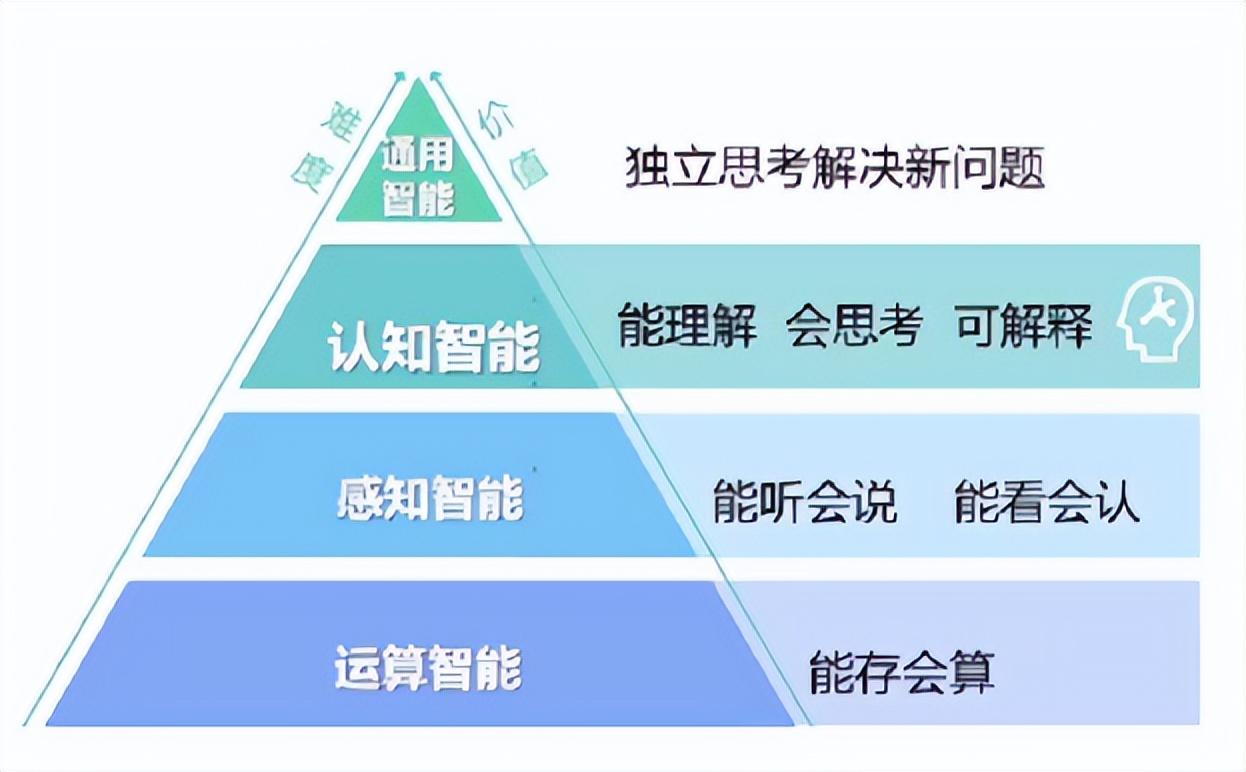
小米大模型数据负责人彭力认为,眼下的我们正在向通用人工智能(AGI)演进,而大语言模型则可以加速人工智能演进的进程与当前面临的技术难点。
新一轮人工智能革命已然到来,而中文大模型需要尽快成长,我们期望有一天真的能“超越”同行达到领先水平。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号