Python与SQL:妙手数评的启蒙之旅
发表时间: 2021-09-06 07:59
这是使用 Python 在 Jupyter notebook 中启动和运行 SQL 的介绍

使用 Python 运行 SQL 查询的一种快速简便的方法是使用 SQLite。 SQLite 是一个使用 SQL 数据库引擎的库。它的执行速度相对较快,并且已被证明是高度可靠的。 SQLite 是测试环境中最常用的数据库引擎。
以下是入门的简单步骤。
首先,我们需要将 SQLite 导入我们的 Jupyter notebook。
import sqlite3
import pandas as pd
使用 connect() 函数可以在您的环境中创建数据库。这有助于用户命名他们的数据库,以便稍后在 Python 中调用。当您使用数据库时,connect() 函数会维护连接。
需要注意的重要一点是,当您连接到数据库时,其他用户将无法同时访问它。这就是为什么在完成后关闭()连接是必不可少的(我将在接近结束时讨论关闭连接)。
在这个例子中,我将引用一个名为“factbook.db”的 CIA 数据库。
sql_connect = sqlite3.connect('factbook.db')
cursor() 函数用于协助执行我们的 SQL 查询。
cursor = sql_connect.cursor()
使用 cursor() 返回与我们要查询的数据库对应的 Cursor 实例很重要。
使用 SQLite 和 Python,需要在整个字符串中传递 SQL 查询。虽然没有必要,但我认为将您的查询保存到变量中是一种很好的做法,以便以后可以引用它而不必重新编写整个查询。
我们的 factbook.db 文件中的表称为事实。
将 SQL 查询另存为字符串
query = "SELECT * FROM factbook;"
2. 使用之前的游标变量执行查询。这会将结果转换为元组并将其存储为局部变量。为了获得所有结果,我们使用 fetchall()。
results = cursor.execute(query).fetchall()
为了运行我们早期使用 Pandas 保存的查询,我们执行以下操作。
pd.read_sql_query(query,sql_connect)
输出:
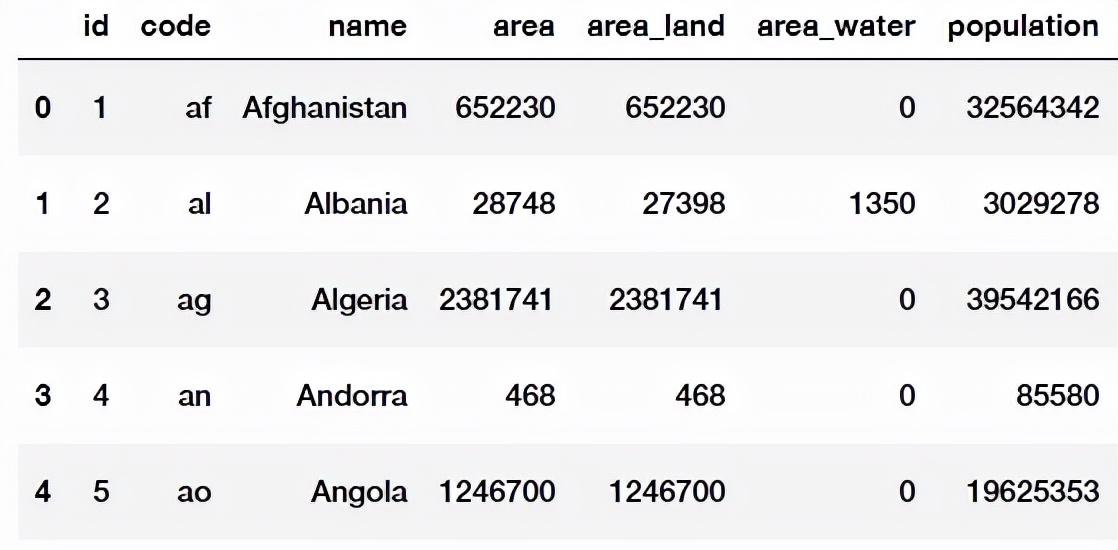
请记住,完成后关闭连接很重要。关闭连接将授予其他人访问数据库的权限。
sql_connect.close()
这是 SQLite 思维过程的一个很好的模板。
1. connection open
2. transaction started
3. statement executes
4. transaction done
5. connection closed
如果您像我一样,那么您可能想知道为什么在 Python 中运行 SQL 查询,而在 PostgreSQL 或 MySQL 中运行它们似乎更容易。
Python 拥有大量用于可衡量和科学分析的库(例如 Pandas、StatsModel 和 SciPy)。这些库同样可以完美地抽象出精妙之处,因此您不必手工计算所有基本数学知识。此外,您可以及时获得结果,因此您可以反复使用 Python 来调查您的信息。
这是在 Python 中使用 SQL 查询绘制直方图的片段。
import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inlinefig = plt.figure(figsize=(10,10))ax = fig.add_subplot(111)query = '''SELECT population, population_growth, birth_rate, death_rateFROM factbookWHERE population != (SELECT MAX(population) FROM facts)AND population != (SELECT MIN(population) FROM facts);'''pd.read_sql_query(query, sql_connect).hist(ax=ax)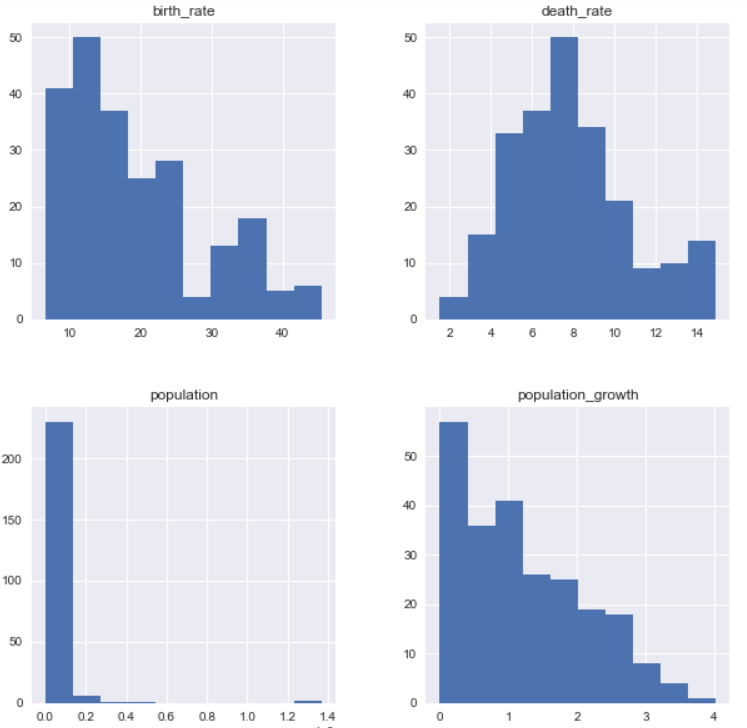
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号