利用 PostgreSQL 解决实际的统计分析挑战
发表时间: 2018-09-25 11:19
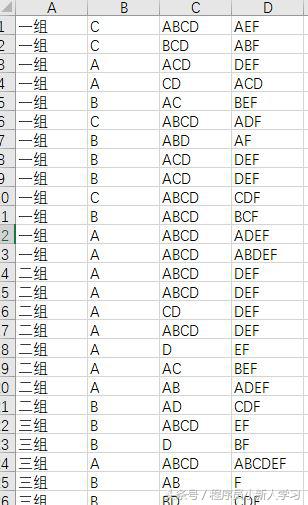
使用 PostgreSQL 解决一个实际的统计分析问题作者:老农民(刘启华)Email: 46715422@qq.com之前有个朋友扔给我一个奇葩需求,他们公司之前做了一批问卷调查,全部都是统一格式的excel文档,大约有近1300个问卷结果,都分布在1300多个excel文件中,有32个问卷题目,有单选和多选题,这个朋友说手工去集中分析几乎没什么办法了,问我有什么法子解决,可以付费请我帮忙。每个题目的可选项有A,B,C,D,E,F,也就是他们需要统计每个题目对应选项的选择情况和占比等,我拿到之后仔细看了excel的格式情况,最后写了几段python代码,将所有的excel文档对应的题目选项结果集中写入到一个csv文件中,一个问卷excel文件对应一条记录,csv结果集如下截图参考:
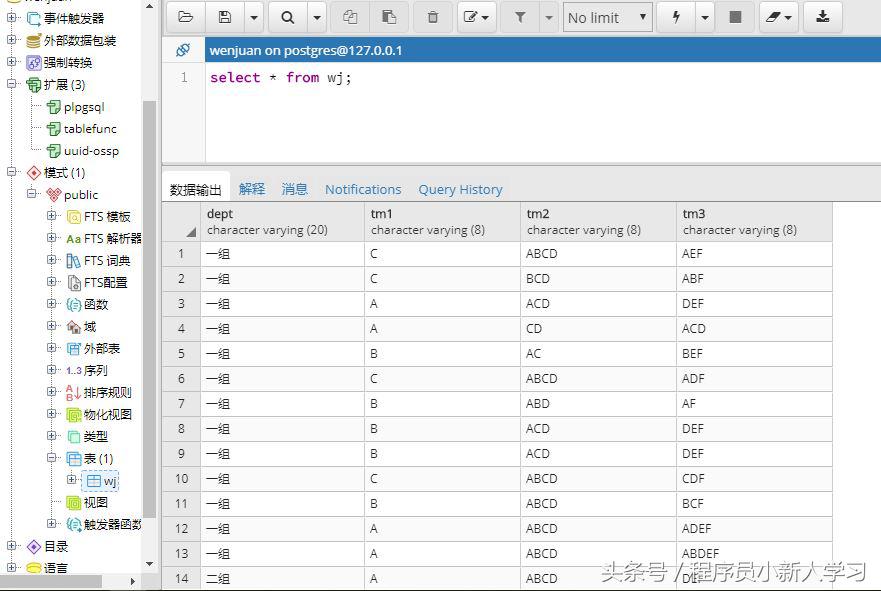
-- 建表 wj ,然后将csv文件导入到表 wj 中create table wj( dept character varying(20) not null, tm1 character varying(8), tm2 character varying(8), tm3 character varying(8));alter table wj owner to postgres;-- 查询导入的数据情况:select * from wj;
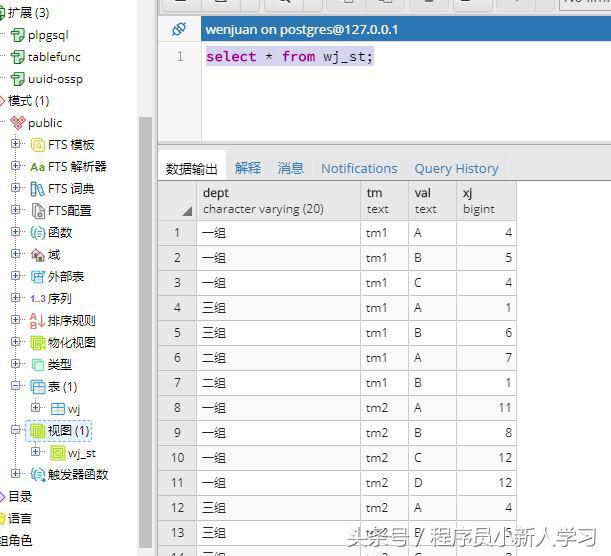
/*创建关键的统计分析视图 wj_st,因为需要将多选的题目进行列转多行,这里我们需要使用字符串切割函数 regexp_split_to_table:*/create view wj_st as select a.dept, a.tm, a.val, a.xj from ( select dept, 'tm1' as tm, regexp_split_to_table(coalesce(tm1, ''), '') as val, count(*) as xj from wj group by dept, regexp_split_to_table(coalesce(tm1, ''), '')union allselect dept, 'tm2' as tm, regexp_split_to_table(coalesce(tm2, ''), '') as val, count(*) as xj from wj group by dept, regexp_split_to_table(coalesce(tm2, ''), '')union allselect dept, 'tm3' as tm, regexp_split_to_table(coalesce(tm3, ''), '') as val, count(*) as xj from wj group by dept, regexp_split_to_table(coalesce(tm3, ''), '')) a;alter table wj_st owner to postgres;-- 查询视图结果:select * from wj_st;
-- 先执行以下语句创建扩展表函数:CREATE EXTENSION tablefunc;-- 针对视图 wj_st 统计出每个部门的题目选项情况:select substr(depttm,1,char_length(depttm)-3) 部门,substr(depttm,char_length(depttm)-2) 题目, a, b, c, d, e, f from crosstab ( 'select dept||tm,val,xj from wj_st order by 1', 'select distinct val from wj_st order by 1') as (depttm text, a integer, b integer, c integer, d integer, e integer, f integer);
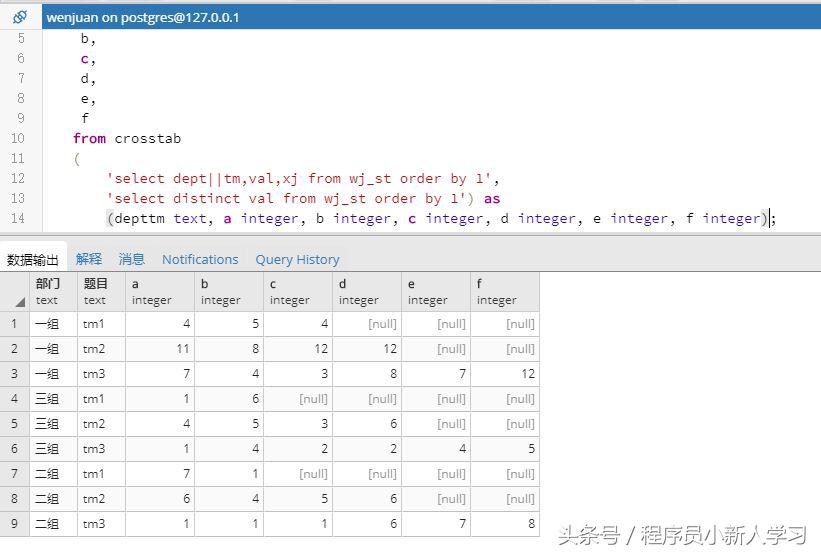
我们可以针对以上的统计数据进行相关的需求统计了!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号