数据分析师与ChatGPT:深度测试后的真相揭秘
发表时间: 2023-02-24 17:02
转载/statist3927 Lab
最近我在看《今日头条》的时候,无意点击看了AI 聊天机器人的ChatGPT的文章,结果算法一下子就给我推送了很多相关的文章和评价。
哇,那是一个热捧啊,我类举一下热门的主题:
美国的中学生拿ChatGPT写作业,老师头疼;
美国的大学生拿ChatGPT 写论文,而且只要一个题目和论文简单要求,就能生成洋洋N千字的论文;
美国的大学教授吐槽很难分别作业哪些是学生自己写的,哪些是ChatGPT写的;
华裔程序员让ChatGPT 修改一段代码,结果ChatGPT “创造”了新的代码,居然运行成功;
…...
还有一些文章不知道是贩卖焦虑还是蹭热点,主题也是很抓眼球:
ChatGPT 将掀起一场职场革命!
ChatGPT 未来将取代这些职位!
小心了,取代你的不是你的对手,而是ChatGPT
…….
尤其是“ChatGPT 中国应用社区”发表文章的这个主题,让我看了有些莫名其妙:

另外还有这个

我之所以感觉莫名其妙,甚至感觉有些质疑,就是在于上述观点中有个职业——数据分析师,是个我所热爱的,而且很多时候都要有独创思维的工作,它居然会那么容易被ChatGPT 取代?
要知道数据分析师不是简单的拿数据做一些饼图和条形图完事儿,它要求一个数据分析师必须熟悉业务场景,并且将业务场景抽象提炼成各种数据模型,并进行分析、洞察、探测因果关系,并提供相应的改进建议,甚至要成为项目经理去落地那些建议。
如果数据分析师就是拿个数据做个表格和饼图,那他顶多算个图表生成器而已。
我在Excel或者Python、R,预先写好些宏、代码,例行点击运行就可以了,
也用不着ChatGPT啊!
于是我觉得很想要试试这个ChatGPT,看看它在数据分析领域有多厉害,能够取代数据分析师这个职业?!
于是我快速到OpenAI网站用Google邮箱注册了一个ChatGPT账号,开始了我的测试之旅。
首先,我得了解它是否习惯中文,于是我问
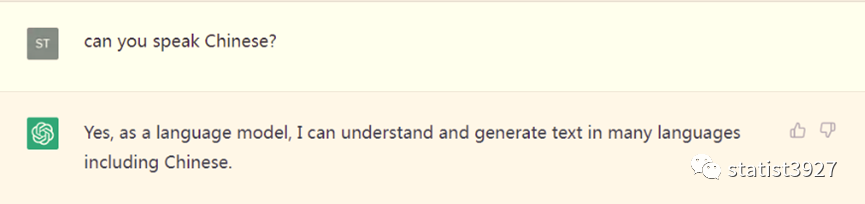
好,那看样子它可以用中文和我交流。
我打算先试试它经过大量的训练后,对一些简单的数学逻辑有哪些反应。
因为以前我听过,人工智能,就是有多少人工,就有多少智能。

嗯,看了它的回复,感觉还不错
第3种答案其实是我内心已经知道的,并且期待能出现在出来。
而且ChatGPT除了第3点外,还回答了更多的场景,说明训练的还不错。
但
我觉得1+1的问题是一个高频问题,很容易被训练样本采集器采集到,所以我换了个不常见的题目。
继续提问如下

果然,它的回答开始出现瑕疵了。
在第一点,布尔代数的回答用在我之前1+1的问题是可以,因为布尔代数里面含1。
但是布尔代数中只有0和1两种值,因此不存在4×9的场景。但Chat GPT仍旧生搬硬套布尔代数来回答,还做了个结论:’因此4×9可能不等于36’。
这结论放在布尔代数的范畴内,就很牵强附会。
第二点,在不等式的情况下,为啥4×9不一定等于36?
是4×9>36还是4×9<36?!
哪怕是4×9≥36中,也包含了“=”在里面啊!
我于是继续追问,为什么它会这么回答
结果,悲催了
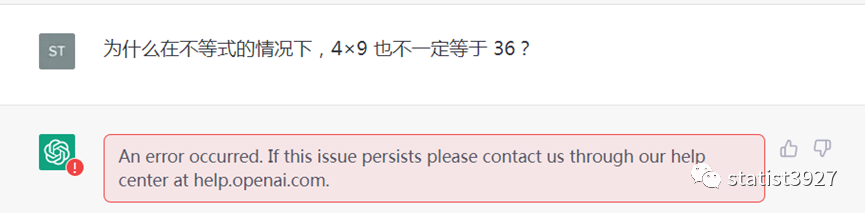
我去,居然被我问的出故障?!
那可能读者会问了,你说说看,啥场景下4×9≠24?
其实这个问题的答案并不难,在十六进制下,4×9=24,不等于36。
当然我相信还有更多场景。
于是简单2个问题测试,我就问出了ChatGPT的一个存在问题:训练量不够。
就这水平还想替代数据分析师?!
我继续问一个和数据分析相关的专业知识,准备先问个入门级的,看看它在这个专业领域的算法学习和训练得如何。
假设有2组数,X组{12,15,16,19,22,26}和Y组{22,25,28,33,36,39},请问它们之间的Pearson相关系数等于多少?

乍一看,不错哦,回答过程貌似很牛的样子。
还有具体的计算过程
还分步骤讲解呢!
但
我用Excel计算了一下,不对啊,答案是0.9837825啊!
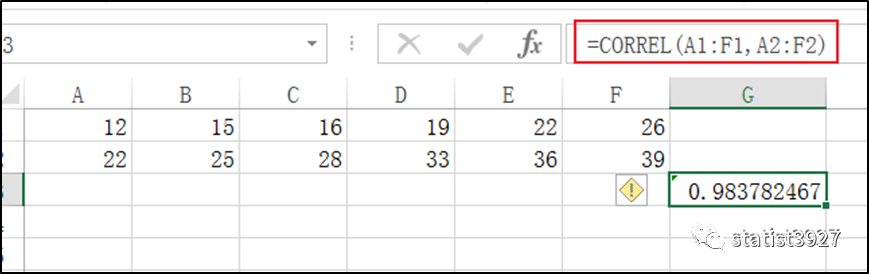
难道我眼花?
为此我还专门再查了一下Excel的帮助文档和维基百科,确保了我验证的计算公式没错!
其中Excel的帮助文档是这样介绍Pearson相关系数函数CORREL()的
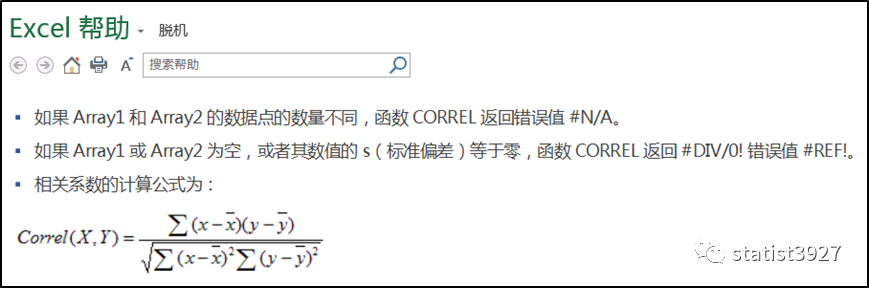
上图最下面的数学公式就是Pearson相关系数
我于是又查了下维基百科,

确认过眼神儿,公式没错!
但
我还是不放心,用统计专业的R语言计算相关系数,并且指定计算方法用Pearson相关系数
但结果还是支持Excel的计算结果

我勒个去!
ChatGPT 算错就算错了,还那么有条不紊,还那么装模作样!
头一次见到这么人工智能一本正经忽悠人做数据分析的!
我仔细一检查,原来ChatGPT有3个地方一开始就算错了!

第一个是Σxy,第二个是Σx²,第三个是Σy² 这三处算错了。
正确的计算结果应该分别是3520,2146, 5779
对于ChatGDP的能耐,我大约知道些底了!
根本没有传说的那么神。
但它又会有多不靠谱呢?
我就这刚才的问题接着问
如何添加2个数到X组和Y组去,让它们的Pearson相关系数降到0.5以下?

有了上一次的教训后,我可没有被它一本正经的样子所骗
因为它原先的计算错误逻辑,一直继承到了第二个问题中,所以我闭着眼睛都知道这结果是错的。
不信用Excel检测下:
果然!
ChatGPT的回答看上去很专业,其实答案是错的!
以下是Excel的检验结果
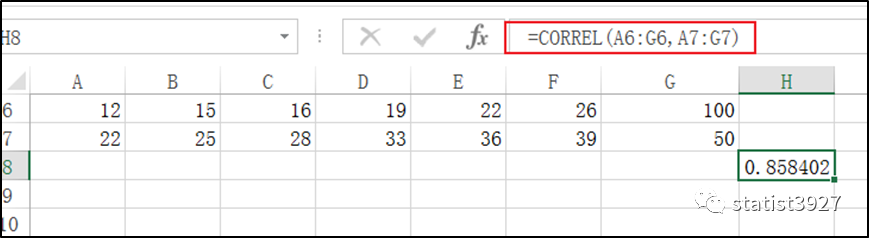
ChatGPT的答案是-0.184,Excel的答案是0.858402!
保险起见,我又用R 又检查了一下,确定ChatGPT是在一本正经地撒谎!
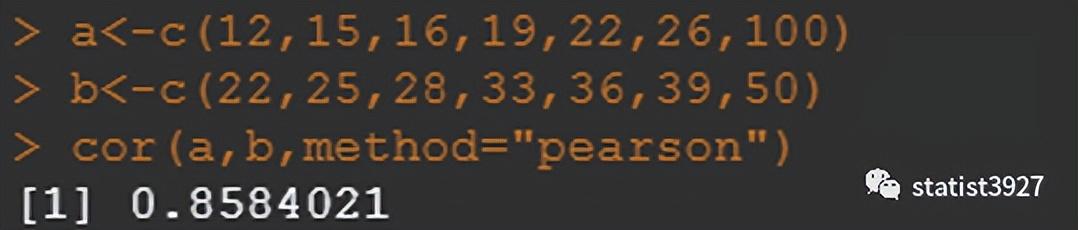
那正确答案是啥呢?添加啥数字能让它们的相关系数比0.5还低呢?
作为数据分析师,我轻松回答这个问题:其实正确答案很多。
先说如何实现的原理:
想要Pearson相关系数变小,只要朝着“线性不相关”的方向走就行。
什么是“线性不相关”,就是说,相同的X场景下,出现了2个或多个不同的Y,并且他们之间的差异非常大。
例如我的答案,就是X组里放一个出现过的数19,Y组里放一个2000(不用很大),他们的Pearson相关系数一下子就掉到0.1都不到了。
具体检验如下

接下来,我再准备测试下,ChatGPT 对带有业务场景背景的数据分析问题,有没有能力回答?
因为数据分析师最经常处理的数学或者数据问题,都是发生在具体的业务上面的,如果没有对业务的理解,数据分析师的分析报告是苍白无力的。
测试背景
“假如你在哥伦比亚首都房间的饮水机坏了,检查后发现是一款机械温控器不工作了。上面有个参数85。现在准备把它带到玻利维亚首都拉巴斯去更换新的机械温控器,并留在玻利维亚使用。到五金店去买时,这个参数应该选择下面那种?A. 80,B. 90,C.85,D,100

说实话看了它的这个回答,我放心了:
ChatGPT其实根本不懂业务,就只是个聊天机器人。
它的答案中,除了85这个数值不算严格说错外,其他剩下的文字放到真实的业务中其实就非常不专业、不合理。
最合理的答案应该是80。
为什么这么说?
机械温控器的参数85,指的是温控器工作的温度阈值是85℃。
因为哥伦比亚首都波哥大的平均海拔2800米,不加压的情况下水是烧不到100℃的。
饮水机都是不加压的,所以饮水机烧不到100℃的开水。
所以,根据流体静力学公式和克劳修斯-克拉伯龙相态公式、理想气体状态方程,海拔高度和水沸点的关系式

计算得到,哥伦比亚首都波哥大的水沸腾温度大约为91℃
因此在那里的饮水机的工作阈值设定为85℃是合理的,因为如果不考虑一些容错空间的话,假如设定为90℃差不多刚刚好,会出安全隐患:
这台饮水机在波哥大山地的景区里使用的话,海拔高度就会超过2800米,例如去到3500米,那么水的沸点就会低于90℃,这台饮水机的温控器就会因为水达不到90℃而不停的加热,甚至干烧!最终会产生安全隐患。
接下来,通过查阅百度百科,玻利维亚首都拉巴斯的市中心海拔达到了3600米,机场高度为4200米,比哥伦比亚首都波哥大海拔还高。
根据前述的水的沸点和海拔高度的公式,在市中心和机场如果用这台饮水机的话,水的沸点分别是88.5℃和86.5℃。
理论上用85参数的机械温控器是可以的。
但,实际业务中一定要考虑容错,因为每个产品都有功能上的误差,温控器的工作温度阈值±5%都很正常。
上面的88.5℃和86.5℃2个值剔除掉这些容错误差后,温控器工作温度是最低理论计算值为82℃。
出于“料敌从宽”的安全思维考虑,如果没有82参数的温控器,那么应该选比它低的。因此买参数为80温控器,也就是选A是最合理的。
而这,并不是像Chat GPT那样,‘按照之前的参数买’是最合理的。
有人可能不服,说Chat GPT 诞生在美国,而且全球接受的训练都是英语环境。
它还没有那么多中文的训练,你用中文问是欺负人!
是吗?
我一开始也是这么担心,直到我把刚才的题目用英文去问,Chat GPT的答案还是一样不专业

数据分析师除了要应对具体的业务背景下的问题,还要能有解决学术问题的能力。因为一定的学术能力可以激活数据分析师的创新思维。
我的问题是这样的:
假定虚词的使用是一个人的“写作风格指纹”,请在这个假设前提下,计算并分析下《红楼梦》的作者一共有几个人,他们分别写了哪些章节?

看了ChatGPT的回复,一开始我还是觉得它还是有思辨能力的,居然对我的假设前提有异议,我略微有些惊讶。
但
但
它后面详细解释道《红楼梦》是明代文学的代表作品!
而且居然还把作者曹雪芹写成了吴承恩!
我不由的想到一个画面:
“猴哥别生气,ChatGPT 不懂咱中国文学,把作者搞错了。您收起金箍棒,别和它一般见识,别和它一般见识哈”
得,这下好了。
原本想测试下它在学术背景下的,是否如网上那些热捧的人所说那样,信手拈来就能搞定一篇论文
看样子不用继续搞了。
因为这论文的摘要或者综述就已经这么大一个漏洞了,再把论文写下去都没用!
我也没兴趣继续问下去了。
数学方程求解也是数据分析师的基本技能,而且是我当年考数据分析师证书时的考试大纲中的一个知识点。
我是看到《今日头条》里面曾经出过这么一道题
请在下面( )中填入自然数,使得等式成立
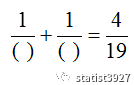
于是我就问了下ChatGPT

ChatGPT的回答还是让我大失所望
过程看上去很一本正经,但是结果是错的!
因为正确的答案我知道,我自己算出来过:正确答案是X=5,Y=95或X=95,Y=5
但按照ChatGPT的答案代入题目式子中去算,根本就是错的!
按照ChatGPT的结果,把19和76代入题目,得
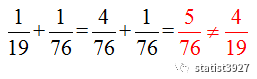
ChatGPT 想要替代数据分析师的这个结论,至少现在可以明辨了,现阶段直接做不到!
首先,作为聊天AI,它的输入是文字,输出也是文字,它是不具备图形处理能力的。
图形处理包括“看图提取数据信息”、“根据信息生成图表”。而数据分析师的日常业务中,数据可视化是高频业务。数据分析报告的消费群体也是需要图形处理的结果的,因为更直观。
光这点聊天AI 就没法搞定。
其次,由于当今世界分工很细,很多岗位背后要掌握的跨学科交叉程度很高,也就是我们俗称要“深刻了解业务的各种场景”。
而聊天AI的本质是NLP,它的训练集是“语料库”。并且NLP本身没能力把很多具体的业务知识,例如图像、声音、视频、三维空间的位移过程…..这写信息抽象成具体的数据特征,并纳入到自己的语料库中。
一旦语料库缺失这些能够代表具体业务场景背景信息的训练样本,那么它也就无法建立在业务的基础上给出建议。
而成为一个合格的数据分析师,就必须“深刻了解业务”,那么就必然要比一个NLP要掌握它所掌握不了的技能和知识。
最后,我特别要提醒的地方:
在每次对话完后,无论ChatGPT回答的如何,我都不会再后面点赞或喝倒彩,如下图

这个小小图表标一旦点击,就相当于免费帮别人家AI的这一次训练结果打上标签。
要知道,AI最宝贵的资源是训练的样本标签!采集到大量的样本标签是每一个AI公司做梦都想得到的财富!
但目前ChatGPT还不熟悉中文的语境和中文的很多习惯,且现在很多国人都在尝试和ChatGPT进行沟通,这样就无疑免费帮助人家训练算法,并打标签。
而量变产生质变,一旦ChatGPT的训练数量和标签数量突破了安全阈值,那么很有可能会形成网络诈骗、网络信息安全犯罪等方面的又一个作案利器!
而且人家诈骗犯不用来中国,甚至不用学中文,远在大洋彼岸就可以实施犯罪。
因此角度站高点,出于整个社会安全的因素考虑,我是不会帮助人家的AI打标签的。
正文完
把ChatGPT当作辅助工具即可,不能依赖,不然你的每次搜索,都是给自己的埋雷,该掌握的其他工具一样都不能少。给大家推荐数据分析师都在用的FineBI工具:
轻松构建出你的数据图表思维逻辑,让你拥有独到的洞察性数据见解,进而达到有效沟通或者数据汇报的目的。
 |
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号