探索百度、京东、阿里等IT巨头的Redis集群方案实践
发表时间: 2018-06-21 10:40
为什么集群
Redis是一个内存数据库,也就是说存储数据的容量不能超过主机内存大小。普通主机服务器的内存一般几十G,但是我们需要存储大容量的数据(比如上百G的数据)怎么办? 由于内存大小的限制,使用一台 Redis 实例显然无法满足需求,这时就需要使用 多台 Redis (集群)作为缓存数据库,才能在用户请求时快速的进行响应。

Redis集群作为面试官经常问到的问题,可见其重要性。之前在逛博客的时候看到一位作者为“大cc”的一篇博文,详细解析了大厂的 Redis 集群方案。现在转载出来,给各位同学参考,抛砖引玉,希望可以加深同学对Redis的理解,更希望同学们可以顺利的通过面试。
Redis集群的两种方式
redis 集群方案主要有两类,一是使用类 codis 的架构,按组划分,实例之间互相独立; 另一套是基于官方的 redis cluster 的方案;
类 codis 的架构
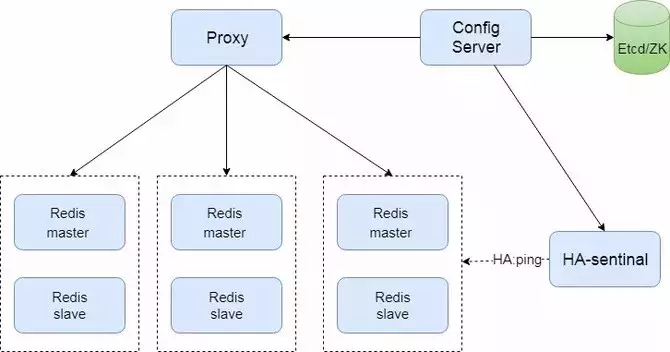
这套架构的特点:
分片算法:基于 slot hash 桶;
分片实例之间相互独立,每组 一个 master 实例和多个 slave;
路由信息存放到第三方存储组件,如 zookeeper 或 etcd
旁路组件探活
使用这套方案的公司:阿里云: ApsaraCache, RedisLabs、京东、百度等
codis
slots 方案:划分了 1024 个 slot, slots 信息在 proxy 层感知; redis 进程中维护本实例上的所有 key 的一个 slot map;
迁移过程中的读写冲突处理:最小迁移单位为 key; 访问逻辑都是先访问 src 节点,再根据结果判断是否需要进一步访问 target 节点;
访问的 key 还未被迁移:读写请求访问 src 节点,处理后访问:
访问的 key 正在迁移:读请求访问 src 节点后直接返回; 写请求无法处理,返回 retry
访问的 key 已被迁移 (或不存在):读写请求访问 src 节点,收到 moved 回复,继续访问 target 节点处理
AparaCache 的单机版已开源 (开源版本中不包含 slot 等实现),集群方案细节未知; ApsaraCache
主要组件:proxy,基于 twemproxy 改造,实现了动态路由表; redis 内核: 基于 2.x 实现的 slots 方案; metaserver:基于 redis 实现,包含的功能:拓扑信息的存储 & 探活; 最多支持 1000 个节点;
slot 方案:redis 内核中对 db 划分,做了 16384 个 db; 每个请求到来,首先做 db 选择;
数据迁移实现:数据迁移的时候,最小迁移单位是 slot,迁移中整个 slot 处于阻塞状态,只支持读请求,不支持写请求; 对比 官方 redis cluster/ codis 的按 key 粒度进行迁移的方案:按 key 迁移对用户请求更为友好,但迁移速度较慢; 这个按 slot 进行迁移的方案速度更快;
主要组件:proxy: 自主实现,基于 golang 开发; redis 内核:基于 redis 2.8configServer(cfs) 组件:配置信息存放; scala 组件:用于触发部署、新建、扩容等请求; mysql:最终所有的元信息及配置的存储; sentinal(golang 实现):哨兵,用于监控 proxy 和 redis 实例,redis 实例失败后触发切换;
slot 方案实现:在内存中维护了 slots 的 map 映射表;
数据迁移:基于 slots 粒度进行迁移; scala 组件向 dst 实例发送命令告知会接受某个 slot;dst 向 src 发送命令请求迁移,src 开启一个线程来做数据的 dump,将这个 slot 的数据整块 dump 发送到 dst(未加锁,只读操作) 写请求会开辟一块缓冲区,所有的写请求除了写原有数据区域,同时双写到缓冲区中。当一个 slot 迁移完成后,把这个缓冲区的数据都传到 dst,当缓冲区为空时,更改本分片 slot 规则,不再拥有该 slot,后续再请求这个 slot 的 key 返回 moved; 上层 proxy 会保存两份路由表,当该 slot 请求目标实例得到 move 结果后,更新拓扑;
跨机房:跨机房使用主从部署结构; 没有多活,异地机房作为 slave;
基于官方redis cluster的方案
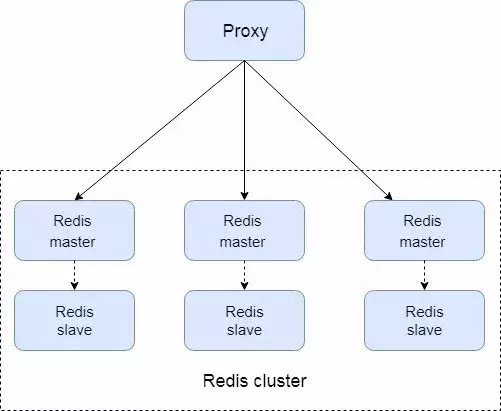
和上一套方案比,所有功能都集成在 redis cluster 中,路由分片、拓扑信息的存储、探活都在 redis cluster 中实现; 各实例间通过 gossip 通信; 这样的好处是简单,依赖的组件少,应对 400 个节点以内的场景没有问题 (按单实例 8w read qps 来计算,能够支持 200 * 8 = 1600w 的读多写少的场景); 但当需要支持更大的规模时,由于使用 gossip 协议导致协议之间的通信消耗太大,redis cluster 不再合适;
使用这套方案的有:AWS, 百度贴吧
官方 redis cluster
数据迁移过程:基于 key 粒度的数据迁移; 迁移过程的读写冲突处理:从 A 迁移到 B;
访问的 key 所属 slot 不在节点 A 上时,返回 MOVED 转向,client 再次请求 B;
访问的 key 所属 slot 在节点 A 上,但 key 不在 A 上, 返回 ASK 转向,client 再次请求 B;
访问的 key 所属 slot 在 A 上,且 key 在 A 上,直接处理;(同步迁移场景:该 key 正在迁移,则阻塞)
AWS ElasticCache
ElasticCache 支持主从和集群版、支持读写分离; 集群版用的是开源的 Redis Cluster,未做深度定制;
百度贴吧的 ksarch-saas
基于 redis cluster + twemproxy 实现; 后被 BDRP 吞并; twemproxy 实现了 smart client 功能; 使用 redis cluster 后还加一层 proxy 的好处:
对 client 友好,不需要 client 都升级为 smart client;(否则,所有语言 client 都需要支持一遍)
加一层 proxy 可以做更多平台策略; 比如在 proxy 可做 大 key、热 key 的监控、慢查询的请求监控、以及接入控制、请求过滤等;
即将发布的 redis 5.0 中有个 feature,作者计划给 redis cluster 加一个 proxy。
ksarch-saas 对 twemproxy 的改造已开源:
https://github.com/ksarch-saas/r3proxy
为了帮助同学们更好的了解Redis,小编为同学们准备了Redis的学习教程。
1.关注“黑马程序员” 评论转发后台回复:rd
2.点击了解更多获取视频学习资源。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号