经历失败后,我整理出了这份详尽的《MySQL性能调优笔记》
发表时间: 2020-06-01 07:07

说明:本文篇幅有限,故只展示部分内容,《MySQL性能调优学习导图》收集整理不易,有需要的朋友麻烦帮忙转发一下,然后私信我【999】即可免费获取下载方式
1. 使用show profile查询剖析工具,可以指定具体的type
此工具默认是禁用的,可以通过服务器变量在绘画级别动态的修改
set profiling=1;当设置完成之后,在服务器上执行的所有语句,都会测量其耗费的时间和其他一些查询执行状态变更相关的数据。
select * from emp;在mysql的命令行模式下只能显示两位小数的时间,可以使用如下命令查看具体的执行时间
show profiles;执行如下命令可以查看详细的每个步骤的时间:
show profile for query 1;2. 使用performance schema来更加容易的监控mysql
MYSQL performance schema详解
3. 使用show processlist查看连接的线程个数,来观察是否有大量线程处于不正常的状态或者其他不正常的特征
1. 数据类型的优化
更小的通常更好:应该尽量使用可以正确存储数据的最小数据类型,更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期更少,但是要确保没有低估需要存储的值的范围,如果无法确认哪个数据类型,就选择你认为不会超过范围的最小类型
简单就好:简单数据类型的操作通常需要更少的CPU周期,例如,①、整型比字符操作代价更低,因为字符集和校对规则是字符比较比整型比较更复杂;②、使用mysql自建类型而不是字符串来存储日期和时间;③、用整型存储IP地址
尽量避免null:如果查询中包含可为NULL的列,对mysql来说很难优化,因为可为null的列使得索引、索引统计和值比较都更加复杂,坦白来说,通常情况下null的列改为not null带来的性能提升比较小,所有没有必要将所有的表的schema进行修改,但是应该尽量避免设计成可为null的列
实际细则:
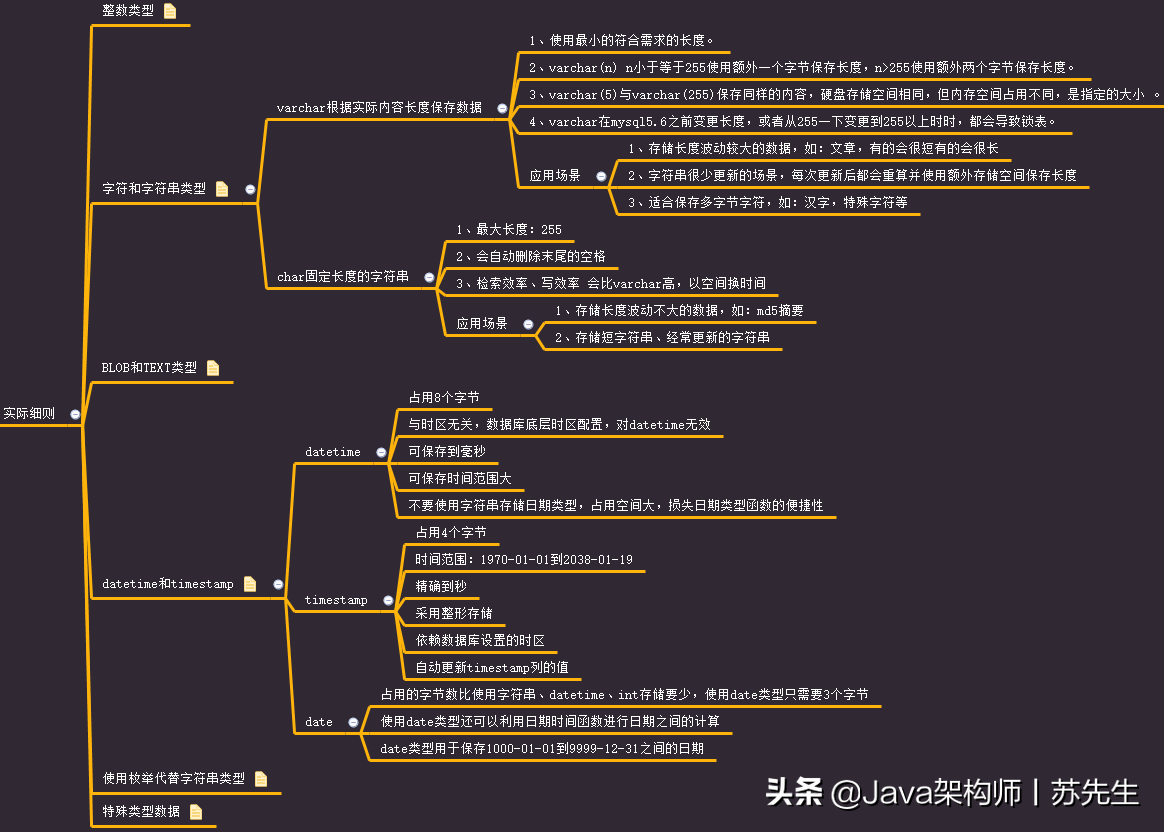
2. 合理使用范式和反范式
①、范式
优点:
缺点:
②、反范式
优点
缺点
③、注意

3. 主键的选择
代理主键:与业务无关的,无意义的数字序列
自然主键:事物属性中的自然唯一标识
推荐使用代理主键
4. 存储引擎的选择

5. 适当的数据冗余
6. 适当拆分
当我们的表中存在类似于 TEXT 或者是很大的 VARCHAR类型的大字段的时候,如果我们大部分访问这张表的时候都不需要这个字段,我们就该义无反顾的将其拆分到另外的独立表中,以减少常用数据所占用的存储空间。这样做的一个明显好处就是每个数据块中可以存储的数据条数可以大大增加,既减少物理 IO 次数,也能大大提高内存中的缓存命中率。

1. 索引基本知识
2. 哈希索引
3. 组合索引
当包含多个列作为索引,需要注意的是正确的顺序依赖于该索引的查询,同时需要考虑如何更好的满足排序和分组的需要
4. 聚簇索引与非聚簇索引
5. 覆盖索引
6. 优化小细节
7. 索引监控

1. 查询慢的原因
2. 优化数据访问
查询性能低下的主要原因是访问的数据太多,某些查询不可避免的需要筛选大量的数据,我们可以通过减少访问数据量的方式进行优化
是否向数据库请求了不需要的数据
3. 执行过程的优化
查询缓存:在解析一个查询语句之前,如果查询缓存是打开的,那么mysql会优先检查这个查询是否命中查询缓存中的数据,如果查询恰好命中了查询缓存,那么会在返回结果之前会检查用户权限,如果权限没有问题,那么mysql会跳过所有的阶段,就直接从缓存中拿到结果并返回给客户端
查询优化处理:mysql查询完缓存之后会经过以下几个步骤:解析SQL、预处理、优化SQL执行计划,这几个步骤出现任何的错误,都可能会终止查询
4. 优化特定类型的查询
1. 分区表的应用场景
2. 分区表的限制
3. 分区表的原理

4. 分区表的类型
5. 如何使用分区表
如果需要从非常大的表中查询出某一段时间的记录,而这张表中包含很多年的历史数据,数据是按照时间排序的,此时应该如何查询数据呢?
因为数据量巨大,肯定不能在每次查询的时候都扫描全表。考虑到索引在空间和维护上的消耗,也不希望使用索引,即使使用索引,会发现会产生大量的碎片,还会产生大量的随机IO,但是当数据量超大的时候,索引也就无法起作用了,此时可以考虑使用分区来进行解决
6. 在使用分区表的时候需要注意的问题
1. general

2. character

3. connection

4. log

5. cache
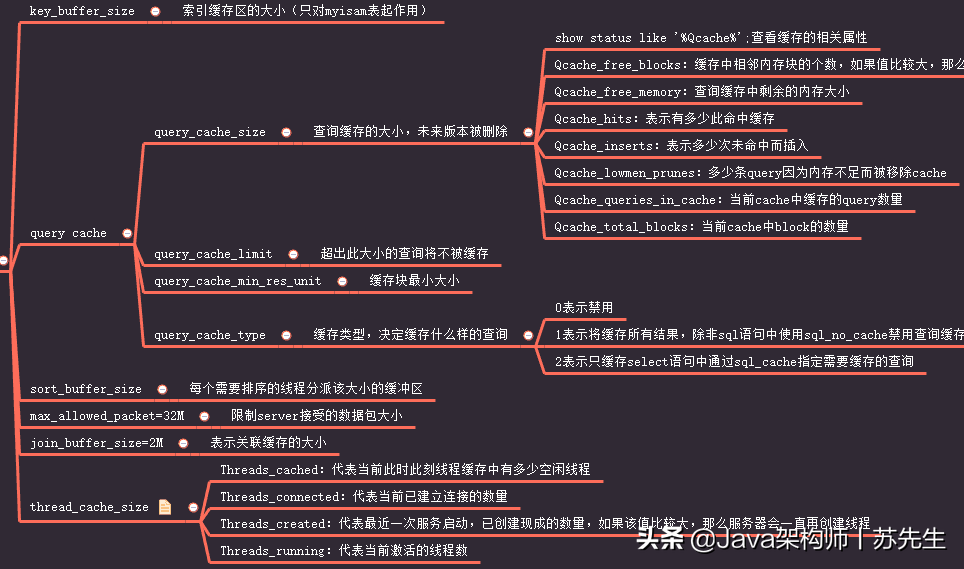
6. INNODB

成功不是将来才有的,而是从决定去做的那一刻起,持续累积而成。
记得帮忙转发+转发+转发,在私信【999】即可免费获取下载方式哦
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号