MySQL数据库语法全解析:存储过程、函数、视图、触发器及表
发表时间: 2019-09-23 00:01
抽空总结一下mysql的一些概念性内容,涉及存储过程、函数、视图、触发器等。
1、存储过程
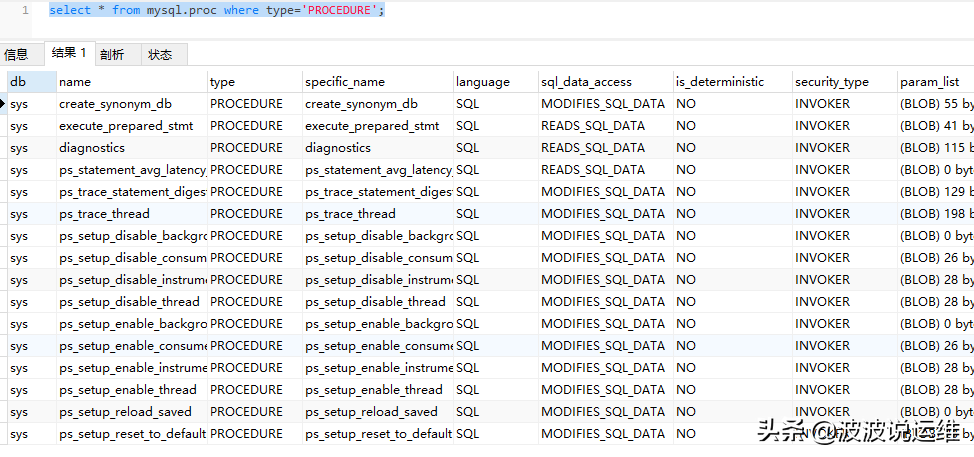
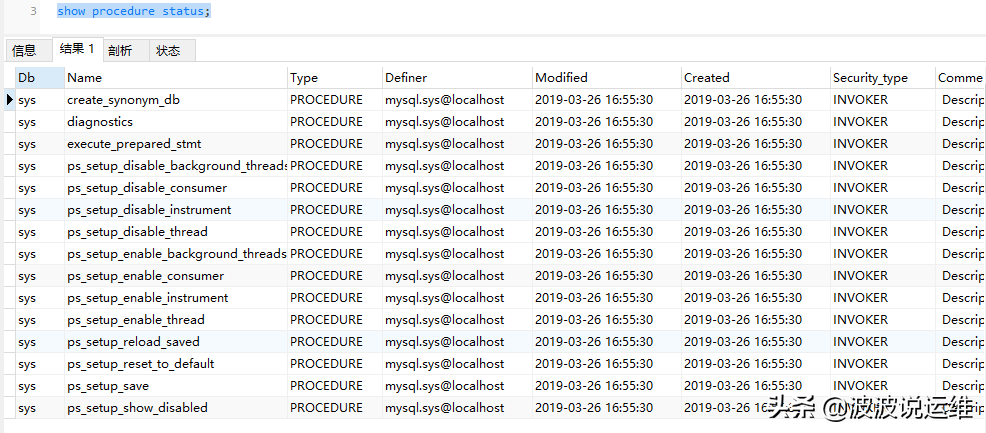
select * from mysql.proc where type='PROCEDURE';show procedure status; show create procedure proc_name; //存储过程定义

2、函数
select * from mysql.proc where type='FUNCTION';show function status;show create function func_name; //函数定义
3、视图
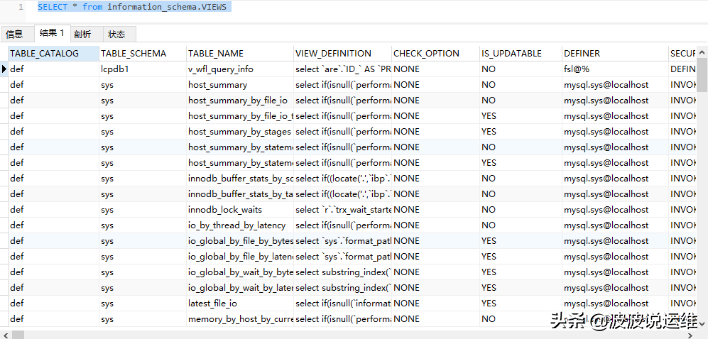
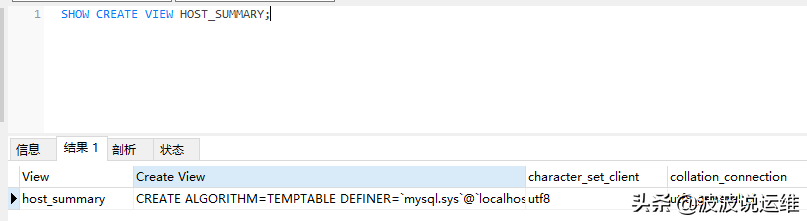
SELECT * from information_schema.VIEWS SHOW CREATE VIEW 视图名
4、表
SELECT * from information_schema.TABLES show create table table_name;
5、触发器
SELECT * FROM information_schema.triggers;show create trigger trigger_name;


mysql自定义函数就是实现程序员需要sql逻辑处理,参数是IN参数,含有RETURNS字句用来指定函数的返回类型,而且函数体必须包含一个RETURN value语句。
1、语法:
创建: CREATE FUNCTION 函数名称(参数列表) RETURNS 返回值类型 函数体修改: ALTER FUNCTION 函数名称 [characteristic ...]删除: DROP FUNCTION [IF EXISTS] 函数名称调用: SELECT 函数名称(参数列表)
2、实例
CREATE DEFINER=`root`@`%` FUNCTION `getUnitChildList`(employeeCode VARCHAR(30)) RETURNS text CHARSET utf8BEGIN #最终返回的组织code字符串 DECLARE codeResult TEXT DEFAULT "-1"; #最终返回的组织id字符串 DECLARE result TEXT DEFAULT "-1"; #组织id的中间字符串 DECLARE sTempChd VARCHAR(10000); #最上层组织的字符串 DECLARE currentCode VARCHAR(10000) DEFAULT '-1'; #游标是否结束标识 DECLARE endFlag INT DEFAULT 0; #定义游标-unitCur,查询出当前员工拥有的所有岗位的组织code DECLARE unitCur CURSOR FOR SELECT DISTINCT pos.unit_code FROM hr_org_position_b pos LEFT JOIN hr_employee_assign ass ON pos.POSITION_CODE = ass.POSITION_CODE LEFT JOIN hr_employee HE ON he.EMPLOYEE_CODE = ass.EMPLOYEE_CODE WHERE he.EMPLOYEE_CODE = employeeCode AND ass.ENABLED_FLAG = 'Y' AND pos.ENABLED_FLAG = 'Y'; #结束set为1 DECLARE CONTINUE HANDLER FOR NOT FOUND SET endFlag = 1;#开始遍历游标 OPEN unitCur; REPEAT FETCH unitCur INTO currentCode; SET sTempChd = currentCode; #当前组织也加上 SET result=CONCAT(result,",",sTempChd); #循环,遍历出当前组织code下的组织code的list,存入字符串,逗号分隔 WHILE sTempChd IS NOT NULL DO #拼接结果字符串到result SELECT GROUP_CONCAT(unit_code) FROM hr_org_unit_b WHERE FIND_IN_SET(parent_code,sTempChd)>0 INTO sTempChd; IF sTempChd IS NOT NULL THEN SET result=CONCAT(result,",",sTempChd); END IF; END WHILE; UNTIL endFlag = 1 END REPEAT; #关闭游标 CLOSE unitCur; RETURN result;END
一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,比一个个执行sql语句效率高,用户通过指定存储过程的名字并给出参数来执行它。参数可以为IN, OUT, 或INOUT
1、语法
创建: CREATE PROCEDURE 过程名 (参数列表) [characteristic ...] 函数体修改: ALTER PROCEDURE 过程名 [characteristic ...]删除: DROP PROCEDURE [IF EXISTS] 过程名调用: CALL 过程名(参数列表)
2、实例
--2.1、建表create table user(id mediumint(8) unsigned not null auto_increment,name char(15) not null default "",pass char(32) not null default "",note text not null,primary key (id))engine=Innodb charset=utf8; insert into user(name, pass, note) values('sss','123', 'ok'); --2.2、存储过程delimiter //create procedure proc_name (in parameter integer)beginif parameter=0 thenselect * from user order by id asc;elseselect * from user order by id desc;end if;end;// --2.3、执行:call proc_name(0);//
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图
的查询所引用的表,并且在引用视图时动态生成。对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。
通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。视图是存储在数据库中的查询的SQL 语句,它主要出于两种原因:安全原因, 视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。这个视图就像一个“窗口”,从中只能看到你想看的数据列。这意味着你可以在这个视图上使用SELECT *,而你看到的将是你在视图定义里给出的那些数据列。
1、语法
创建:CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]VIEW view_name [(列名列表)]AS 查询语句[WITH [CASCADED | LOCAL] CHECK OPTION]修改:ALTER [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]VIEW view_name [(column_list)]AS select_statement[WITH [CASCADED | LOCAL] CHECK OPTION]删除:DROP VIEW [IF EXISTS]view_name [, view_name] ...[RESTRICT | CASCADE]调用:select v.pass from my_view v; 2、实例
CREATE ALGORITHM = TEMPTABLE DEFINER = `mysql.sys` @`localhost` SQL SECURITY INVOKER VIEW `host_summary` AS SELECTIF ( isnull( `performance_schema`.`accounts`.`HOST` ), 'background', `performance_schema`.`accounts`.`HOST` ) AS `host`, sum( `stmt`.`total` ) AS `statements`, `sys`.`format_time` ( sum( `stmt`.`total_latency` ) ) AS `statement_latency`, `sys`.`format_time` ( ifnull( ( sum( `stmt`.`total_latency` ) / nullif( sum( `stmt`.`total` ), 0 ) ), 0 ) ) AS `statement_avg_latency`, sum( `stmt`.`full_scans` ) AS `table_scans`, sum( `io`.`ios` ) AS `file_ios`, `sys`.`format_time` ( sum( `io`.`io_latency` ) ) AS `file_io_latency`, sum( `performance_schema`.`accounts`.`CURRENT_CONNECTIONS` ) AS `current_connections`, sum( `performance_schema`.`accounts`.`TOTAL_CONNECTIONS` ) AS `total_connections`, count( DISTINCT `performance_schema`.`accounts`.`USER` ) AS `unique_users`, `sys`.`format_bytes` ( sum( `mem`.`current_allocated` ) ) AS `current_memory`, `sys`.`format_bytes` ( sum( `mem`.`total_allocated` ) ) AS `total_memory_allocated` FROM ( ( ( `performance_schema`.`accounts` JOIN `sys`.`x$host_summary_by_statement_latency` `stmt` ON ( ( `performance_schema`.`accounts`.`HOST` = `stmt`.`host` ) ) ) JOIN `sys`.`x$host_summary_by_file_io` `io` ON ( ( `performance_schema`.`accounts`.`HOST` = `io`.`host` ) ) ) JOIN `sys`.`x$memory_by_host_by_current_bytes` `mem` ON ( ( `performance_schema`.`accounts`.`HOST` = `mem`.`host` ) ) ) GROUP BYIF ( isnull( `performance_schema`.`accounts`.`HOST` ), 'background', `performance_schema`.`accounts`.`HOST` )
与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作(insert,delete, update)时就会激活它执行。
触发器经常用于加强数据的完整性约束和业务规则等。
1、语法
创建:CREATE TRIGGER <触发器名称> --触发器必须有名字,最多64个字符,可能后面会附有分隔符.它和MySQL中其他对象的命名方式基本相象.{ BEFORE | AFTER } --触发器有执行的时间设置:可以设置为事件发生前或后。{ INSERT | UPDATE | DELETE } --同样也能设定触发的事件:它们可以在执行insert、update或delete的过程中触发。ON <表名称> --触发器是属于某一个表的:当在这个表上执行插入、 更新或删除操作的时候就导致触发器的激活. 我们不能给同一张表的同一个事件安排两个触发器。FOR EACH ROW --触发器的执行间隔:FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次。<触发器SQL语句> --触发器包含所要触发的SQL语句:这里的语句可以是任何合法的语句, 包括复合语句,但是这里的语句受的限制和函数的一样。删除:DROP TRIGGER 方案名称.触发器名称2、实例
CREATE DEFINER = `mysql.sys` @`localhost` TRIGGER sys_config_insert_set_user BEFORE INSERT ON sys_config FOR EACH ROWBEGIN IF @sys.ignore_sys_config_triggers != TRUE AND NEW.set_by IS NULL THEN SET NEW.set_by = USER ( ); END IF;END
觉得有用的朋友多帮忙转发哦!后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注下~

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号