MySQL数据库深度解析:理解其本质及InnoDB与MyISAM存储引擎
发表时间: 2019-09-29 00:01
今天主要讲下mysql数据库引擎的一些概念和mysql数据库本质,一句话总结:
文件夹-文件:一个数据库其实就是一个的文件夹,数据库里面的表就是文件夹里的一个或者多个文件(根据数据库引擎不同而不同,MyISAM是3个,InnoDB是2.5个)
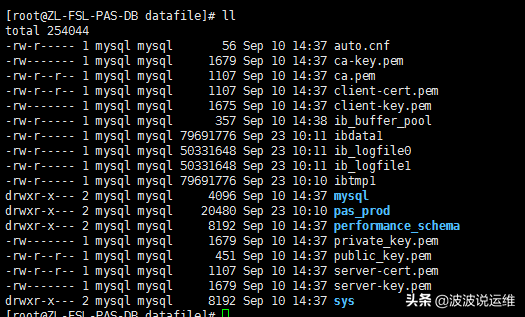
mysql的数据库其实就是存放在MySQL\data下的一个个的文件夹
数据库里面的表就是文件夹里的一个或者多个文件(根据数据库引擎不同而不同)
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql数据库提供了多种存储引擎。
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
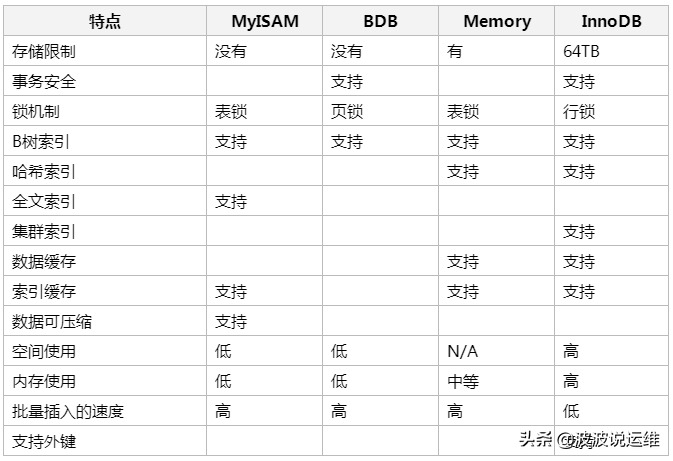
这些不同的技术以及配套的相关功能在MySQL中被称作存储引擎(也称作表类型)。MySQL默认配置了许多不同的存储引擎,可以预先设置或者在MySQL服务器中启用。你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。
1、myisam的存储结构
每一个表都有3个文件,都位于数据库目录中.
tb_name.frm 表结构定义tb_name.MYD 表数据tb_name.MYI 表索引
2、myisam索引结构
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:
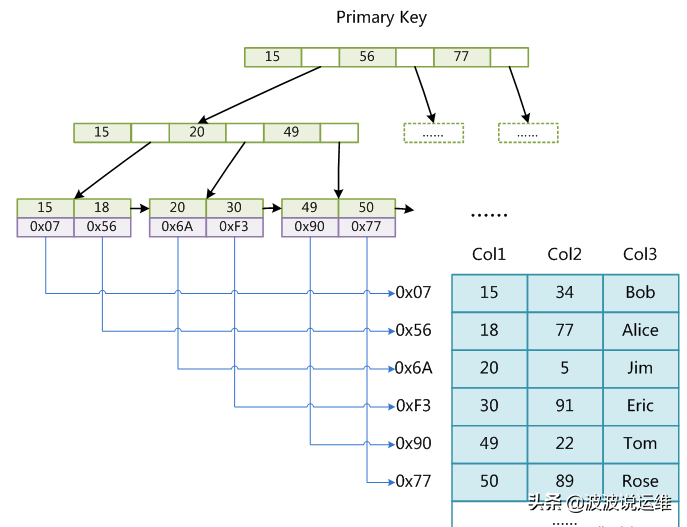
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
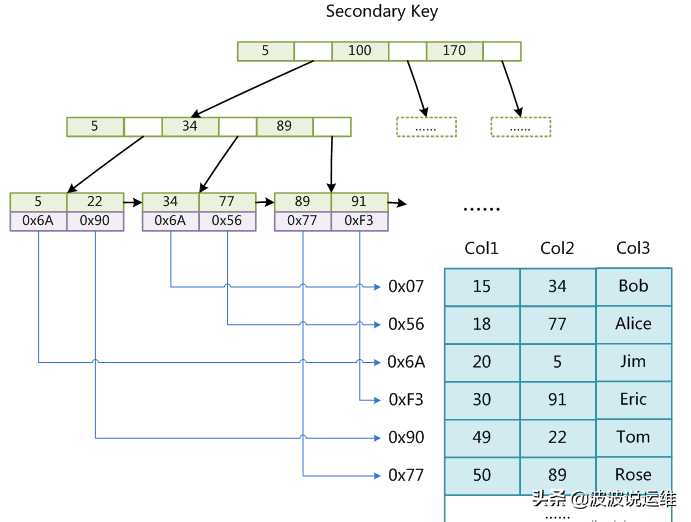
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
1、InnoDB的存储结构
InnoDB使用页面存储结构,下面是InnoDB的表空间结构图:
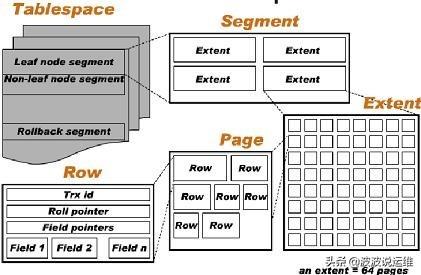
Innodb表:有2种存储方式:
1 默认,每一个表有一个独立的表结构定义文件 和 一个多表数据+索引共享文件
tb_name.frm 表结构 位于指定数据库中
ibdata# 共享表空间 位于数据库目录中datadir
2 使用独立的表空间 每一个表有一个独立的表结构文件和一个独立的表空间文件
tb_name.frm 表结构 位于指定数据库中
tb_name.ibd 表数据 和 索引文件
Page页面存储格式如下图所示:
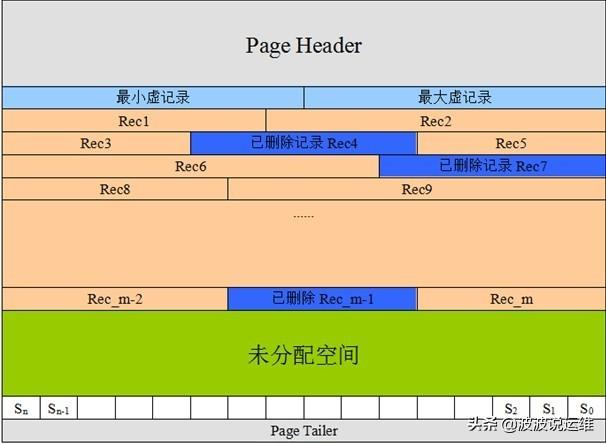
一个页面的存储由以下几部分组成:
页面中的页头,最大/最小虚记录以及页尾都是页面中有固定的存储位置。
2、InnoDB的索引结构
InnoDB使用B+Tree的方式存储索引。
Innodb的一个表可能包含多个索引,每个索引都使用B+树来存储。而索引包括聚集索引和二级索引,聚集索引使用表的主键作为索引键,包含表的所有字段。二级索引只包含索引键和聚集索引键(主键)的内容,不包括其他字段。每一个索引都是一棵B+树,每棵B+树由很多页面组成,而每个页面大小一般为16K。从B+树的组织结构来看,B树的页面可分为:
叶子节点:B树层次为0的页面,存储记录的所有内容。
非叶子节点:B树层次大于0的页面,只存储索引键和页面指针。
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
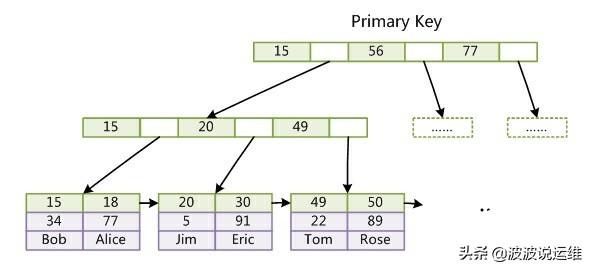
可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
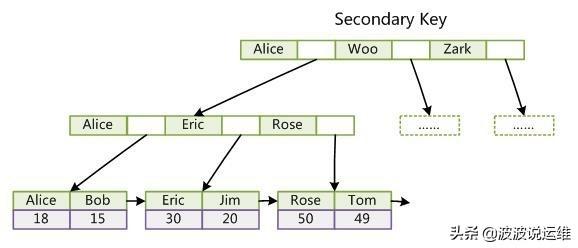
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
觉得有用的朋友多帮忙转发哦!后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注下~

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号