我对PostgreSQL的十大不满
发表时间: 2020-05-08 10:20
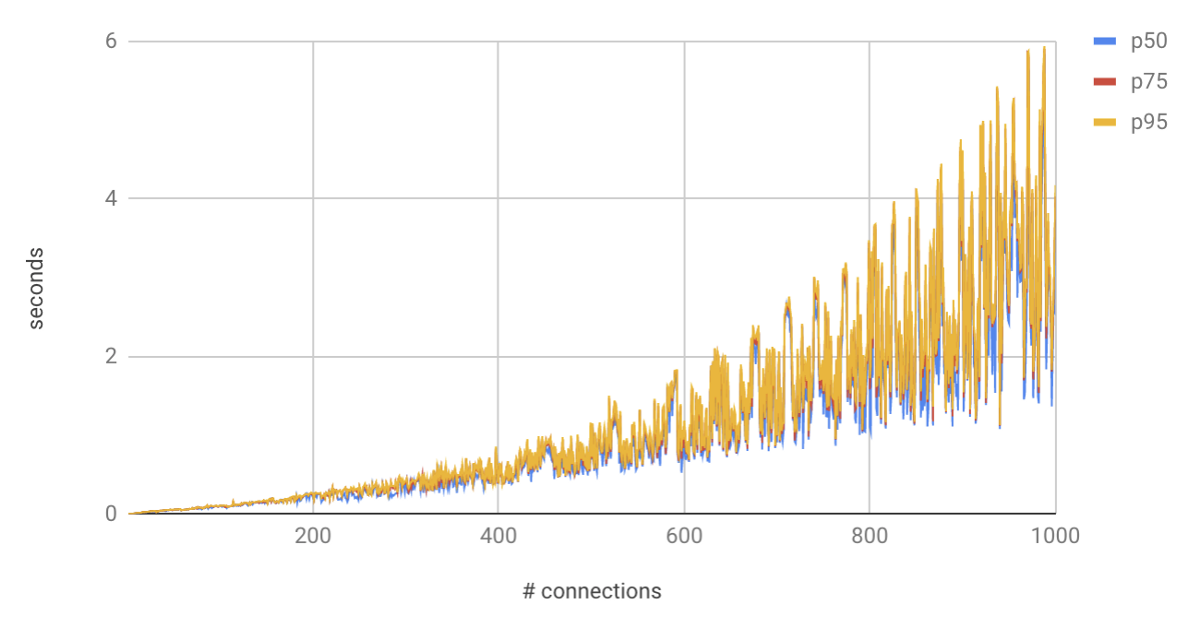
> PostgreSQL performance degrades rapidly with more connections. Credit: brandur.org.
在过去的几年中,软件开发社区对流行的开源关系数据库的热爱已经达到了一个高潮。 这个Hacker News主题涵盖了一个标题为" PostgreSQL是世界上最好的数据库"的文章,它的缝隙处充斥着讨人喜欢的可爱的无情的sy夫,这是这种现象的一个很好的例子。
虽然这些赞美肯定是当之无愧的,但缺乏有意义的异议使我有些烦恼。 没有软件是完美的,那么PostgreSQL的缺陷到底是什么?
自2003年以来,我一直在生产中使用PostgreSQL,其部署范围从小型(千兆字节)到中等(到PB级)不等。 我的观点主要来自构建和运行至少要持续可用的系统。 不用说,多年来,由于一些痛苦的生产问题,我已经获得了PostgreSQL特殊特质的第一手经验。
在这里阅读更多。 可以说,这可以咬人。 有很多关于此问题导致多天停机的故事。 继续进行下去,用Google搜索,您会发现许多可怜的人写着他们踏上这枚地雷的时间。 几乎所有没有高级专家配备的简单PostgreSQL安装都将最终被使用。
在将来的某个时候,XID可能会过渡为使用64位整数,但是直到那时,我们仍然坚持使用它。 我想至少我们可以庆幸的是,与某些飞机软件不同,有一个过程可以阻止它顺理成章地发生。
如果活动主服务器突然出现故障,那么运行中的流复制设置几乎肯定会丢失已提交的数据。 有人可能会说:"异步复制的代价就是这样。"但不一定非要这样。 PostgreSQL支持具有法定提交的同步复制,以实现容错的持久性,但是它具有更严格的性能范围,使应用程序复杂化。
等待不会占用系统资源,但交易锁将继续保留,直到确认转移为止。 结果,由于响应时间增加和争用增加,谨慎使用同步复制将降低数据库应用程序的性能。
这种固定的仲裁复制在某些情况下很有用,但我不建议在通用用例中推荐它。 它类似于Kafka的ISR复制,具有acks = all和一个法定的min_isr,但是具有运行任意查询的事务性关系数据库的所有细微差别。 我目前尚不了解成功应用仲裁提交以非平凡的规模进行高可用性,高耐久性的复制。 如果有,请联系!
就关系数据库而言,Galera Cluster的组复制也不完美,但更接近理想状态。 他们甚至鼓励按地理分布的复制,这对于使用仲裁提交的PostgreSQL复制设置很可能是灾难性的。
到目前为止,流复制是生产部署中最常用的复制机制。 它是物理复制的一种形式,这意味着它可以复制磁盘二进制数据本身中的更改。
每次需要通过写操作修改磁盘上的数据库页面(8KB)时,即使只是一个字节,也将通过请求的更改进行编辑的整个页面的副本写入预写日志(WAL) 。 物理流复制利用现有的WAL基础结构作为流到副本的更改日志。
更新:有些人指出PostgreSQL仅需要在每个WAL检查点执行一次全页写操作。 的确如此,但是在大多数实际系统中,大多数写入将遵循幂律分布,最终出现在检查点之间的唯一页面上。 但是,更重要的是:在预测系统行为时,正确的方法是假设情况更为昂贵,尤其是如果它取决于应用程序的难以预测和高度动态的行为时。
例如,使用物理复制,大型索引构建会创建大量WAL条目,从而很容易成为复制流的瓶颈。 页面粒度的读取-修改-复制过程会导致主机上由硬件引起的数据损坏,更容易传播到副本,这是我个人在生产中亲眼目睹的。
这与逻辑复制相反,后者仅复制逻辑数据更改。 至少从理论上讲,大型索引构建只会导致在网络上复制单个命令。 尽管PostgreSQL在很长一段时间内就一直支持逻辑复制,但是大多数部署都使用物理流复制,因为它更健壮,受更广泛的支持并且更易于使用。
与大多数主流数据库一样,PostgreSQL使用多版本并发控制(MVCC)来实现并发事务。 但是,其特定的实现通常会给垃圾行版本及其清理(VACUUM)带来操作上的麻烦。 一般来说,UPDATE操作会为任何已修改的行创建新副本(或"行版本"),并将旧版本保留在磁盘上,直到可以清除它们为止。
多年来,这种情况一直在稳步改善,但它是一个复杂的系统,对于任何初次接触该问题的人来说都是一个黑匣子。 例如,了解纯堆元组(HOT)及其何时启动对于繁重的就地更新工作负载(如连续保持一致的计数器列)来说可能是成败的。 默认的自动真空设置在大多数情况下都有效,但是,当无效时,天哪。
相反,MySQL和Oracle使用重做和撤消日志。 他们不需要类似的后台垃圾收集过程。 他们做出的权衡主要是事务提交和回滚操作的额外延迟。
也许是在遥远的将来的某个时候,哲普拯救了我们所有人。
PostgreSQL为每个连接派生一个进程,因为其他大多数数据库都使用更有效的连接并发模型。 由于存在一个相对较低的阈值,在该阈值上添加更多的连接会降低性能(大约2个内核),最终会导致性能下降,而这又是一个较高的阈值(难以估计,高度依赖于工作负载),这将导致难以调整的问题。
使用连接池的标准方法当然可以解决问题,但是会带来额外的架构复杂性。 在一个特别大的部署中,我最终不得不在第二个pgbouncer层中分层。 一层在应用程序服务器上运行,另一层在数据库服务器上运行。 它总共聚合了大约一百万个客户端进程的连接。 调整时需要40%的深色艺术品,40%的蛮力和10%的纯正运气。
进程可伸缩性在每个主要版本中都在逐步提高,但与MySQL中使用的"每连接线程数"相比,最终该体系结构的性能受到了一定的限制。
有关更多技术深度,请参见
https://brandur.org/postgres-connections。
PostgreSQL中的表有一个主键索引和称为堆的单独行存储。 其他数据库将它们集成在一起或支持"索引组织表"。 在这种安排下,主键查找过程直接导致行数据,而无需辅助获取完整行以及必要的额外CPU和I / O利用率。
PostgreSQL中的CLUSTER命令会根据索引重新组织表以提高性能,但实际上不适用于大多数实际的OLTP情况。 它以互斥锁重写整个表,从而阻止任何读取或写入。 PostgreSQL不维护新数据的群集布局,因此该操作必须定期运行。 因此,仅当您可以使数据库长时间长时间脱机时,它才真正有用。
但更关键的是,索引组织的表可以节省空间,因为索引不需要单独的行数据副本。 对于具有主要由主键覆盖的小行的表(例如联接表),这可以轻松地将表的存储空间减少一半。
考虑下表,该表存储任意对象的社交"赞":
CREATE TABLE likes ( object_type INTEGER NOT NULL, object_id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY, user_id BIGINT NOT NULL, created_at TIMESTAMP WITH TIME ZONE NOT NULL, PRIMARY KEY(object_type, object_id, user_id));
PostgreSQL将维护与基表存储区分开的主键索引。 该索引将为每行包含object_type,object_id和user_id列的完整副本。 每行28个字节中的20个(〜70%)将被复制。 如果PostgreSQL支持索引组织的表,则不会消耗所有这些额外的空间。
一些主要版本升级需要数小时的停机时间才能转换大型数据库的数据。 使用典型的流复制机制,不可能通过升级副本并进行故障转移来优雅地做到这一点。 磁盘二进制格式在主要版本之间不兼容,因此,主副本之间的有线协议实际上也是不兼容的。
希望逻辑复制最终将完全取代流复制,这将启用在线滚动升级策略。 当我进行大规模的水平扩展部署时,我们在自定义基础架构上进行了重大的工程投资,以使用额外的基于触发器的复制系统(也用于分片迁移)在不停机的情况下进行这些升级。
公平地说,MySQL的即用型复制要麻烦得多,但是与MonNoDB和Redis等某些NoSQL存储或MySQL Group Replication和Galera Cluster等面向集群的复制系统相比,其易用性 和避免边缘现象的角度来看,在PostgreSQL中设置复制仍有很多不足之处。 从理论上讲,逻辑复制为第三方解决方案提供了更大的灵活性,以弥补这些空白,但到目前为止,使用流复制来替代它存在一些很大的警告。
使用计划者提示,查询可以指示查询计划者使用自己不会使用的策略。 PostgreSQL开发团队多年来一直拒绝支持查询计划程序提示,这似乎是足够聪明的编译器参数的一种形式。
我确实了解他们的理由,主要是为了防止用户使用查询提示来攻击问题,而应该通过编写适当的查询来解决这些提示。 但是,当您发现生产数据库在突然而意外的查询计划变更下突然陷入全面崩溃时,这种哲学似乎是残酷的家长式作风。
在许多情况下,给计划者的提示可以在几分钟内减轻问题,使工程团队可以花数小时或数天的时间对查询进行适当的修复。 尽管有一些间接的解决方法涉及禁用某些查询计划器策略,但它们存在风险,因此绝对不应在任何时间压力下使用。
那个象牙塔肯定一定不错。
InnoDB在MySQL中的页面压缩通常可以将存储空间减少一半,并且从性能的角度来看几乎是"免费的"。 PostgreSQL将自动压缩较大的值,但这对于将数据存储在关系数据库中的最常用的方式没有用。 对于大多数RDBMS用例,一行通常为几百个字节或更少,这意味着压缩仅在跨多行或成块应用时才真正有效。
对于PostgreSQL核心的数据结构来说,块压缩确实很难实现,但是尽管有一些缺点,但MySQL InnoDB存储引擎采用的"打孔"策略在实践中似乎效果很好。
2020年4月7日更新:" MySQL在Facebook"一举成名的Mark Callaghan在此质疑我的说法,即打孔压缩"在实践中效果很好"。 事实证明,正如我之前认为的那样,世界上最大的MySQL安装从未使用过打孔压缩。 但是,他们确实成功地使用了较早版本的InnoDB压缩的稍作修改,但是在几年前迁移到MyRocks之前,它们取得了成功。
虽然打孔压缩似乎确实对某些人有用,但是有些注意事项使打孔压缩不像本垒打那样。 如果您运行的是Percona的MySQL版本,那么MyRocks是更好的选择。 如果不是这样,那么对于闪存中的大量读取工作负载而言,经典的InnoDB表压缩似乎是一个更安全的选择。 马克没有指出重大生产问题的任何具体实例,但指出他"怀疑文件系统是为每页打孔而设计的,我会担心隐晦的故障。"
在PostgreSQL世界中唯一被广泛使用的通用块压缩设置利用了ZFS,它似乎对人们来说非常有效。 ZFS如今已成为Linux上的生产级现实,但无疑带来了一些管理开销,而对于XFS或ext4等更"现成的"文件系统而言,ZFS却不存在。
您可能应该仍然使用PostgreSQL,而不是使用其他任何方式来存储理想情况下要保存的数据。 通常,我建议从PostgreSQL开始,然后尝试弄清楚为什么它不适用于您的用例。
PostgreSQL非常成熟,设计精良,功能丰富,通常没有锋利的边缘,并且在绝大多数用例中都表现出色。 它也不受主要公司赞助商的限制,包括出色的文档资料,并拥有一个专业的,包容的社区。
好消息是,可以通过使用托管数据库服务(例如Heroku PostgreSQL,Compose PostgreSQL,用于PostgreSQL的Amazon RDS或用于PostgreSQL的Google Cloud SQL)来减轻或消除由本文中提到的许多问题引起的痛苦。 如果您可以使用其中一项服务,为了爱所有神圣的东西,请这样做!
我很自豪地说,我已经在PostgreSQL的基础上构建了将近20年的软件,尽管存在缺陷,但我仍然是坚定的拥护者。 鉴于我多年来令人难以置信的开发团队所见证的进步,我可以说,大多数(如果不是全部)这些问题将在适当的时候得到解决。
(本文翻译自Rick Branson的文章《10 Things I Hate About PostgreSQL》,参考:https://medium.com/@
rbranson/10-things-i-hate-about-postgresql-20dbab8c2791)
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号