大数据与错觉:揭示背后的秘密
发表时间: 2016-05-10 17:55
如果我说美国人现在开始越来越以自我为中心了,你也许会想这个老家伙肯定又要嘟囔些「过去才是好日子」之类的。但是,如果我说我有着对1500亿个文本词语的分析来支持这个的宣称呢?在几十年前,这样规模的证据简直是天方夜谭。而在今天,1500亿个数据已经过时了。「大数据」分析的热潮已经卷过了生物学、语义学、金融学以及其相间的各种领域。
尽管没有人能够在如何定义上取得一致,但大致概念是找到足够大的数据库,这样他们可以发现传统调查里无法发现的规律。这些数据来源于数百万个现实用户的行为,例如发推特或信用卡消费,并且这些行为需要上千台计算机来收集、存储与分析。而对于许多计算机和研究者来说,这个投资是值得的,因为数据中的规律可以解锁从基因序列到明日股票价格的一切信息。
但是有一个问题:我们会不禁认为在如此惊人数量的数据的支持下,基于大数据的研究不可能是错的。然而,数据的海量特征会给结果灌注一种错误的确定感。许多的结果都是不真实的——而其原因会让我们重新思考那些盲目信任大数据的研究。
在语言和文化中,大数据隆重地在 2011 年出场,那时谷歌发布了它的 Ngrams 工具。谷歌在《Science》杂志中发表的文章大张旗鼓地宣布, Ngrams 可以让用户在谷歌扫描书籍数据库中寻找特定短语——这个数据库囊括了几乎 4% 的出版过的书籍!——并获知这些短语的频率如何随着时间而变化。这篇论文的作者预言了「文化经济学」的降临,一个基于大量数据的对文化的研究,并且自此以后,谷歌 Ngrams 变成了一个几乎无限的娱乐来源——但也是语义学、心理学和社会学的一座金矿。例如,他们搜罗了数百万书籍去展示,是的,美国正在变得愈来愈个人主义,我们正在「每一年都在加速忘记我们的过去」,道德理想正在从我们的文化意识中消失。
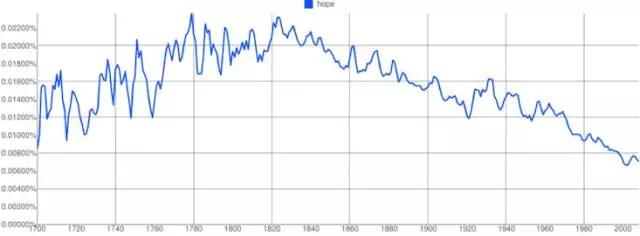
我们正在失去「希望」:网络漫画《xkcd》的作者 Randal Munroe 所创造的许多有趣的小漫画之一是一个关于「希望」的 Ngrams 表格。如果 Ngrams 真的反射出了我们的文化,我们也许正在前往一个黑暗的未来。
问题开始于 Ngrams 语料库建立的方式。在去年十月发表的一篇研究中,三位来自佛蒙特大学(University of Vermont,UVM)的研究者指出,总体来说,Google Books 收纳了每 一本书的复印版。这与它的最初目标完美相符:让这些书本的内容完全呈现于谷歌的强大检索技术中。尽管从社会学研究的角度来说,它让语料库有了危险的歪曲。
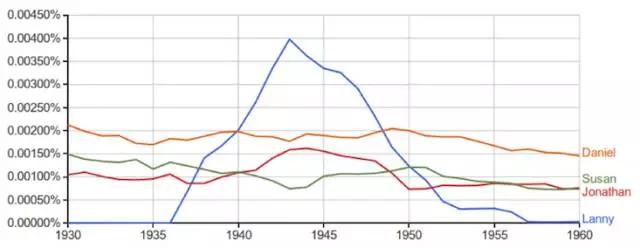
举个例子,一些书籍沦落到了低于它们真正文化重量的境地:《指环王》的影响力还没有《巴伐利亚的巫术迫害》多。而相反的,一些作家则开始变得十分凸显。从英文小说的数据来看,你可以总结出在上世纪初期的20年里,每个角色的兄弟都叫做 Lanny。实际上这个数据甚至反映了一位(并不一定是受欢迎的)作家 Upton Sinclair 有多么多产:他写出了11部有着同一个「Lanny Budd」的小说。
到底谁是 Lanny ?:「Lanny」与其他英文小说中常见名字相对比的谷歌 Ngrams 图标
更加糟糕的是 Ngrams 并不是已出版书籍的一种连续的、平衡的缩影。同一份 UVM 的研究证明,在许多发生的创作变化之中,值得注意的是开始于上世纪60年代的科幻小说的增多。所有这些都让我们很难相信谷歌的 Ngrams 能够准确地反映出文字文化主流随着时间的变化。
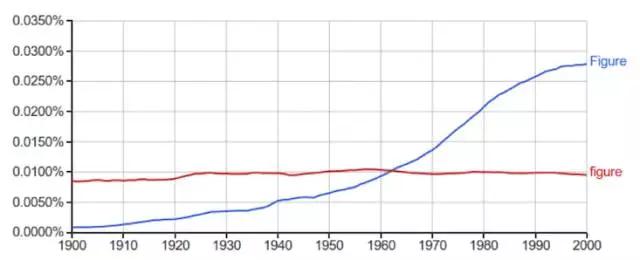
FIGURE 图表:主要用于标题的大写字母F开头的「Figure」使用频率在20世纪大幅上升,意味着语料库中科技文章开始增加。这也许解释了一些关于社会的问题,但是并没有更多解释大多数社会是如何用这些词语的。
即使通过了数据的来源的检验,在「理解」这一关依然存在尖锐的问题。的确,像「性格」和「尊严」这样的用词在过去几十年的使用也许下降了。但是这意味着人们对于道德的关注就减少了吗?伊利诺伊斯大学香槟分校的英文学教授 Ted Underwood 警告说,不要这么快下定义。他指出,我们现在关于道德的理解也许与在 19、20世纪之交时的概念有着巨大出入,并且「尊严」也许因为非道德的原因变得逐渐普及化。因此任何我们从将眼下的关联投射到过去所总结的结论都是可疑的。
当然了,这些对于统计学和语义学来说都不是新鲜事。数据与表征是他们的面包与黄油。而谷歌Ngrams 不同的是,它有着让纯粹的数据遮蔽了我们的双眼并导致人们误入歧途的危险。
这种倾向不仅仅出现在对于 Ngrams 的研究中。相似的错误也损害着各种大数据项目。例如,谷歌的Google Flu Trends(GFT)项目。诞生于 2008 年的 GFT 项目会计算数百万的谷歌检索中「发烧」与「咳嗽」等词语出现的数量,利用它们去「预测」多少人得了流感。有了这些估测,公众健康机构就能够在疾疫控制中心从医生报告中得出真正数量的两周前就采取行动。
当大数据不再被看成一个万金油的时候,它才会真正有颠覆性。
最初,GFT 宣称自己有 97% 的准确度。但是根据西北大学文档的研究,这种准确度仅仅是一个侥幸。首先,GFT 完全忽视了 2009 年春天和夏天「猪流感」的蔓延(最后证实 GFT 大部分预测的是冬天)。接着,系统开始去过度预测流感。实际上,它在 2013 年的峰值预测是真实的140%。最终,谷歌直接停了整个项目。
那么,到底是哪里错了呢?有了 Ngrams,人们会不再仔细考虑他们手中数据的来源和诠释。谷歌检索中的数据资源并不是一个静止的野兽。当谷歌开始自动补充检索内容时,用户们开始习惯于接受提供的关键词,扭曲 GFT 所看到的搜索。在理解方面,GFT 的工程师在最开始让 GFT 采用面值数据;几乎每一个检索术语都被当成潜在的流感指示。有了数百万个检索术语后,GFT 毫无疑问的开始过度诠释一些季节性的词语,例如把「雪」来当做流感的证据。
但是,当大数据不再被看做是万金油时,它才真正具有了颠覆性。哥伦比亚大学的研究者 Jeffrey Shaman 和其他许多团队在流感预测上利用 CDC 去补偿 GFT 的误差,其结果比 CDC 和 GFT 两者都要好。根据 CDC 来看,「Shaman 的团队测试了这个季节已经出现的实际流感的模型」。通过将过去的短时间情况纳入到考虑当中,Shaman 和他的团队精确调整了他们的数学模型,去更好地预测未来。团队所需要的就是去严格地评估关于数据的假设。
为了不让我自己听起来像一个反谷歌斗士,我不得不再说下,谷歌绝对不是唯一的一个犯错者。我的妻子,一位经济学家,曾在一家统计整个互联网的职位发布并收集整合成为国家劳动部门的统计数据的公司工作。公司的经理曾经夸口他们分析了整个国家 80% 的职位,数据的数量致使他们盲目走向了误解的方向。举例来说,一家当地的沃尔玛也许会发布一个销售助理职位,而它实际上想要招十个,或者它也许会让这个发布一直在挂在那里几周,直至人满为止。
因此,相比于屈服在「大数据废墟」下,我们最好在心里保持我们的质疑——即使在有人提到海量文字支持的时候。
本文选自:Nautilus,作者:JESSE DUNIETZ ;机器之心编译,参与:chenxiaoqing、王紫薇
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12

 鲁公网安备37020202000738号
鲁公网安备37020202000738号