深度解析Redis:从入门到精通
发表时间: 2020-07-09 16:12
REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统。Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。

1.redis安装
(1) wget http://download.redis.io/releases/redis-6.0.3.tar.gz
下载成功

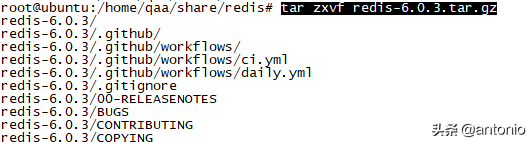
(2) tar zxvf redis-6.0.3.tar.gz
解压成功
(3) make
编译成功
(4) make install
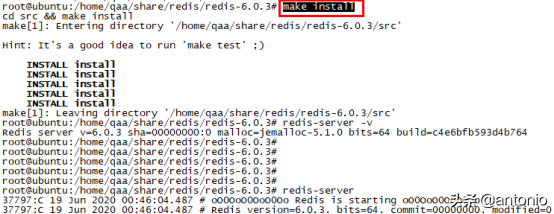
(5) redis-server -v
测试

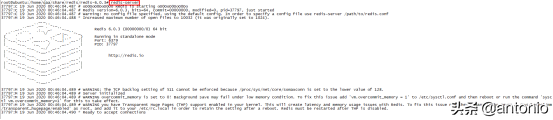
(6) redis-server
启动redis
(7) 在另外一个窗口,通过命令行关闭

就会观察这边会关闭掉redis server,正常关闭

以后台进程的方式启动reids,这种方式还是以前台进程的方式,启动的

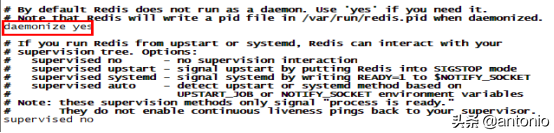
(8) vim redis.conf
后台启动redis服务。把daemonize no改为daemonize yes。这个时候就以后台的方式启动。

改为
(9) ./src/redis-server redis.conf
这个时候就以后台方式启动

(10) redis的默认端口是6379

2.redis6.0多线程
(1) 如需开启需要修改 redis.conf 配置文件:io-threads-do-reads yes。

(2) Redis 6.0 多线程开启时,线程数如何设置?
开启多线程后,需要设置线程数,否则是不生效,需要修改redis.conf。

关于线程数的设置,官方有一个建议:4 核的机器建议设置为 2 或 3 个线程,8 核的建议设置为
6 个线程,线程数一定要小于机器核数。
3.基本数据结构
redis的key就以这些形式存在:
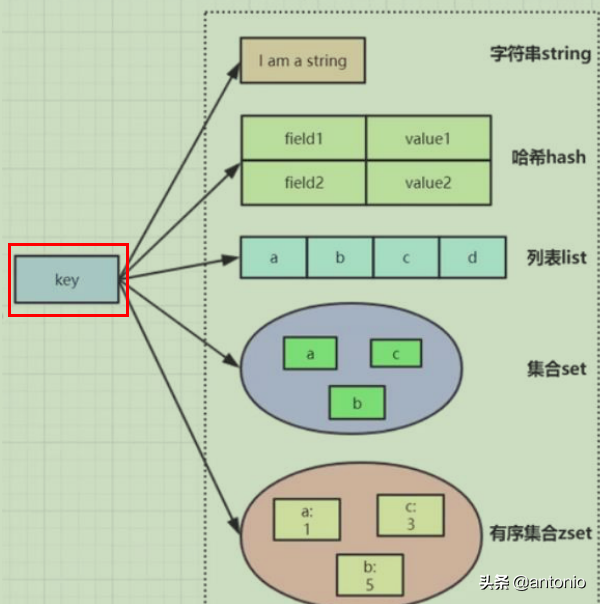
Redis 键命令用于管理 redis 的键。基本语法:
redis 127.0.0.1:6379> COMMAND KEY_NAME
redis 127.0.0.1:6379> SET www redis
OK
redis 127.0.0.1:6379> DEL www
(integer) 1
Redis Keys 命令:


String: 字符串
key value
name xxx
counter 1
bits 1 1 0 0 1 1 0 1 1
Redis 字符串数据类型的相关命令用于管理 redis 字符串值,基本语法如下:
redis 127.0.0.1:6379> COMMAND KEY_NAME
实例:
redis 127.0.0.1:6379> SET wwwkey redis
OK
redis 127.0.0.1:6379> GET wwwkey
"redis"
命令
Redis 字符串命令



应用举例
缓存图片
set redis-log.jpg redis-log-data
存储文章
用户写文章时,需要把文章标题,内容,作者,发表时间等信息存起来,并在用户阅读时读取这些信息。可使用mset mget msetnx命令来进行。
存储文章
被存储的内容 数据库中的键 键的值
文章的标题 article:10086:title ‘message’
文章的内容 article:10086:content ‘hello redis’
文章的作者 article:10086:author ‘xxx’
文章创建的时间戳 article:10086:create_a 'xxxx'
文章长度计数功能、文章摘要、文章计数
文章长度:STRLEN article:10086:content
文章摘要:GETRANGE article:10086:content 0 5
文章阅读计数:INCR article:10086:count
限速器
(1)防止网站内容被网络爬虫疯狂抓取,限制每个 ip 地址在固定的时间段内能够访问的页面数量,比如1 分钟最多只能访问 30 个页面。
(2) 防止用户的账号遭到暴力破解,如果同个账号连续好几次输入错误的密码,则限制账号的登录,只能等 30 分钟后再次登录,比如设置 3 次。
SET max:execute:times 3
密码出错时 DECR max:execute:times
当 max:execute:times 的值小于 0 时则禁止登录,并可以设置SETEX login:error:darren 1800 "Incorrect password",然后使用 TTL login:error:darren 1800 检测对应剩余的时间。
综上
字符串的值既可以存储文字数据,又可以存储二进制数据。
MSET/MGET 命令可以有效地减少程序的网络通信次数,从而提高程序的执行效率。
redis 用户可以定制命名格式来提升 redis 数据的可读性并避免键名冲突。
Hash: 散列表
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。Re
dis 中每个 hash 可以存储 2的32次方- 1 键值对(40 多亿)。案例如下:
127.0.0.1:6379> hmset helloredis name "redis tutorial" likes 20 visitors 23000
OK
127.0.0.1:6379> hgetall helloredis
1) "name"
2) "redis tutorial"
3) "likes"
4) "20"
5) "visitors"
6) "23000"
Redis Hash 命令


哈希举例
短网址生成程序

可以根据该短链接查询到具体的源网址,并记录点击次数。
散列表重新实现文章存储
key field value
title ‘message’
article:10086 conten ‘hello world’
author ‘xxx’
create_at 'xxxxxx'
散列表和字符串
字符串命令与类似散列的命令
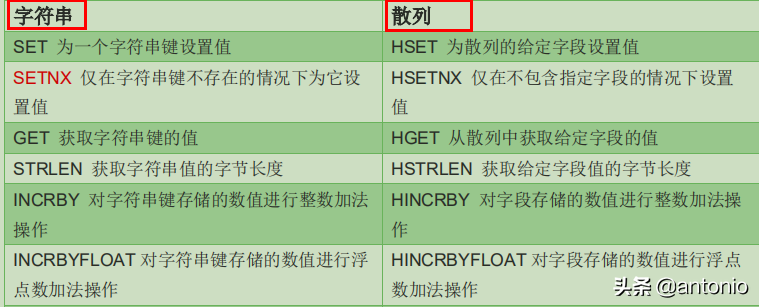
散列键的优点
通过key对应的字段和值进行存储。可以把任意多的字段和值存储到散列里面。
使用字符串键与散列存键储存相同数量的区别,红色的为string类型存储,绿色为散列存储的形式。
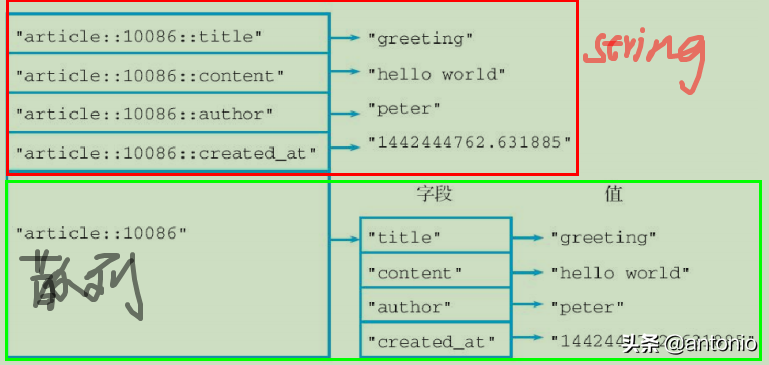
字符串键的优点
字符串键命令提供的操作比散列键命令更为丰富,如使用SETRANGE和GETRANGE命令设置或读取字符串值的其中一部分 ,使用APPEND命令把新内容追加到字符串值的末尾,但是散列键并不支持这些操作。
字符串键是可以为不同的字段设置过期时间,而散列键不会,当一个散列键过期的时候,它包含的所有字段和值都会被删除。而针对字符串键,用户可以为每个字符串键分别设置不同的过期时间,让它们根据实际的需要自动被删除。
字符串键和散列键的选型
散列资源占用少,字符串命令支持多,可以独立设置每个字段的过期时间。

适用场景对比:
1. 如果程序需要为单个数据项单独设置过期的时间,那么使用字符串键。
2. 如果程序需要对数据项执行诸如 SETRANGE、GETRANGE 或者 APPEND 等操作,那么优先考虑使用字符串键。当然,用户也可以选择把数据存储在散列中,然后将类似 SETRANGE、GETRANGE 这样的操作交给客户端执行。
3.如果程序需要存储的数据项比较多,并且你希望尽可能地减少存储数据所需的内存,就应该优先考虑使用散列键。
4.多个数据项在逻辑上属于同一组或者同一类,那么应该优先考虑使用散列键。
List: 列表
Redis列表是简单字符串列表,可以把一个元素使用头插法或尾插法,一个列表最多包含2的32次方 -1 个元素,每个列表超过40亿个元素。
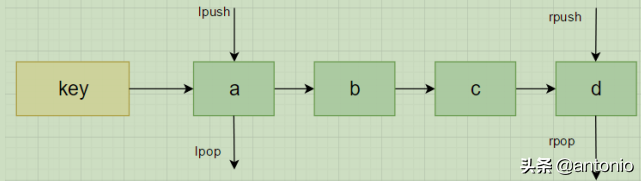
127.0.0.1:6379> lpush hellokey redis
(integer) 1
127.0.0.1:6379> lpush hellokey memcached
(integer) 2
127.0.0.1:6379> lpush hellokey mongodb
(integer) 3
127.0.0.1:6379> lpush hellokey mysql
(integer) 4
127.0.0.1:6379> lrange hellokey 0 10
1) "mysql"
2) "mongodb"
3) "memcached"
4) "redis"
list命令
Redis List 列表命令


应用举例
先进先出队列
秒杀活动
把用户的购买操作都放入先进先出队列里面,然后以队列方式处理用户的购买操作
分页功能
很多应用程序的分页功能也是很常见,如新闻站点、博客、论坛、搜索引擎等,使用分页程序将数量众多的信息分割为多个页面,使得用户可以以页为单位浏览网站提供的信息,并以此来控制网站每次取出的信息数量。注意,使用分页功能,数据最好不要修改。
Set集合
Set是String类型的无序集合,集合成员唯一,集合中不能有重复数据,集合是通过哈希表实现,所以添加,删除,查找的复杂度都是 O(1)。每个集合可存储 40 多亿个成员,与list一样。
127.0.0.1:6379> sadd hellokey redis
(integer) 1
127.0.0.1:6379> sadd hellokey mongodb
(integer) 1
127.0.0.1:6379> sadd hellokey mysql
(integer) 1
127.0.0.1:6379> sadd hellokey memcached
(integer) 1
127.0.0.1:6379> sadd hellokey memcached
(integer) 0
127.0.0.1:6379> smembers hellokey
1) "memcached"
2) "mysql"
3) "mongodb"
4) "redis"
Set命令


应用举例
唯一计数器
用户数量记录的是访问网站的 IP 地址数量,即使同一个 IP 地址多次访问相同的页面,用户数量计数器也只会对这个 IP 地址进行一次计数。需要构建一个新的计数器,可以用 SET 集合。
加入 IP:
SADD users:count 202.177.2.232
计算总数:
SCARD users:count
点赞
朋友圈点赞:
(1)点赞
sadd like:{消息 Id} {点赞用户 Id}
(2) 取消点赞
srem like:{消息 Id} {点赞用户 Id}
(3) 检查用户是否点过赞
sismember like:{消息 Id} {点赞用户 Id}
(4) 获取点赞用户列表
smembers like:{消息 Id}
(5) 获取点赞用户数量
scard like:{消息 Id}
共同关注和集合关注
集合操作
(1) 交集
sinter set1 set2 set3 -> {c}
(2) 并集
sunion set1 set2 set3 -> {a,b,c,d,e}
(3) 差集
sdiff set1 set2 set3 -> {a}
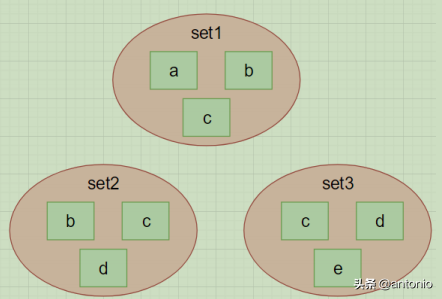
集合实现微博/微信关注模型。
投票
注重内容质量的网站上通常都会提供投票功能,用户可以通过投票来支持一项内容或者反对一项内容:获得的支持票数越多,就会被网站安排到越明显的位置,使得网站的用户可以更快速地浏览到高质量的内容。与此相反,一项内容获得的反对票数越多,它就会被网站安排到越不明显的位置,甚至被当作广告或者无用内容隐藏起来,使得用户可以忽略这些低质量的内容。相当于做了一个集合处理,把这些好的文章展现出来。
抽奖
微信抽奖小程序:
(1) 点击参与抽奖加入集合
sadd key {userId}
(2) 查看参与抽奖所有用户;
smembers key
(3) 抽取 n 名中奖者
srandmember key [n]
或 spop key [n]

Sorted Set: 有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。同样可以存储超过40多亿个成员。
127.0.0.1:6379> zadd hellokey 1 redis
(integer) 1
127.0.0.1:6379> zadd hellokey 2 mongodb
(integer) 1
127.0.0.1:6379> zadd hellokey 3 memcached
(integer) 1
127.0.0.1:6379> zrange hellokey 0 10
1) "redis"
2) "mongodb"
3) "memcached"
127.0.0.1:6379> zadd hellokey 4 mysql
(integer) 1
127.0.0.1:6379> zrange hellokey 0 10 withscores
1) "redis"
2) "1"
3) "mongodb"
4) "2"
5) "memcached"
6) "3"
7) "mysql"
8) "4"
有序集合命令


应用举例
排行榜
实现热搜
(1) 点击新闻(今天热搜)
(2)热搜榜单统计
(3) 展示三天排行前 10
时间线
(1)博客系统会按照文章发布时间的先后,把最近发布的文章放在前面,而发布时间较早的文章则放在后面,这样访客在浏览博客的时候,就可以先阅读最新的文章,然后再阅读较早的文章。
(2) 新闻网站会按照新闻的发布时间,把最近发生的新闻放在网站的前面,而早前发生的新闻则放在网站的后面,这样当用户访问该网站的时候,就可以第一时间查看到最新的新闻报道。
(3) 如微博和 Twitter 这样的微博客都会把用户最新发布的消息放在页面的前面,而稍早之前发布的消息则放在页面的后面,这样用户就可以通过向后滚动网页,查看最近一段时间自己关注的人都发表了哪些动态。
4.操作命令
Redis HyperLogLog 是用来做基数统计的算法,优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的并且是很小的。Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。注意它只是计算基数,而不存储。
127.0.0.1:6379> pfadd hellofkey "redis"
(integer) 1
127.0.0.1:6379> pfadd hellofkey "mongodb"
(integer) 1
127.0.0.1:6379> pfadd hellofkey "mysql"
(integer) 1
127.0.0.1:6379> pfcount hellofkey
(integer) 3
HyperLogLog 命令:

5.发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
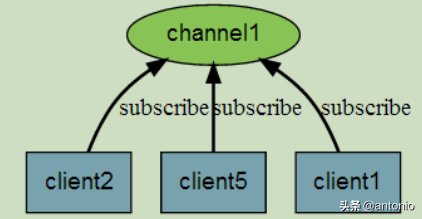
客户端可以订阅任意数量的频道。下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
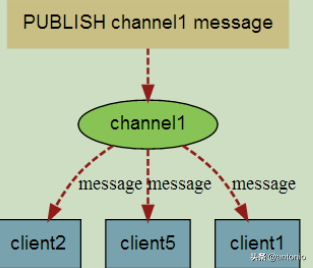
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客
户端:
实例:在我们实例中我们创建了订阅频道名为 redisChat:
Subscribe 客户端 1
127.0.0.1:6379> subscribe redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
1) "message"
2) "redisChat"
3) "Redis is a great caching technique"
1) "message"
2) "redisChat"
3) "Think you"
另外开启一个 redis 客户端,Subscribe 客户端 2
127.0.0.1:6379> subscribe redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
1) "message"
2) "redisChat"
3) "Think you"
开启 Publish 客户端
127.0.0.1:6379> publish redisChat "Redis is a great caching technique"
(integer) 1
127.0.0.1:6379> publish redisChat "Think you"
(integer) 2
127.0.0.1:6379>
这样两个客户端就能够接收到数据了。
发布订阅命令

应用举例
发布订阅与list消息队列区别:
(1)list通过key队列方式实现,取出删掉,其它进程没办法取到,会阻塞进程。订阅发布可以支持多客户端获取同一频道发布的信息。
(2) list不处理消息,会缓存在列表,而发布订阅不处理就丢失了,不会缓存了。
6.Redis事务
Redis 事务可以一次执行多个命令, 并具有以下三个重要的特点:
(1) 批量操作的命令放在队列缓存中
(2) 收到EXEC命令后进入事务执行,事务中某一条命令执行失败,其它命令依然被执行。
(3) 在事务执行过程中,其它客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历三个步骤:
(1) 开始事务
(2) 命令入队
(3) 执行事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set bookname "mastering c++"
QUEUED
127.0.0.1:6379> set bookname "hello class"
QUEUED
127.0.0.1:6379> get bookname
QUEUED
127.0.0.1:6379> sadd tag "c++" "Programming" "Mastering Serires"
QUEUED
127.0.0.1:6379> smembers tag
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) "hello class"
4) (integer) 3
5) 1) "c++"
2) "Mastering Serires"
3) "Programming"
127.0.0.1:6379>
命令
redis 事务的相关命令:

需要注意的是,事务在执行时会独占服务器,所以用户应该避免在事务中执行过多命令,特别是有大量计算的命令,以免造成服务器阻塞。
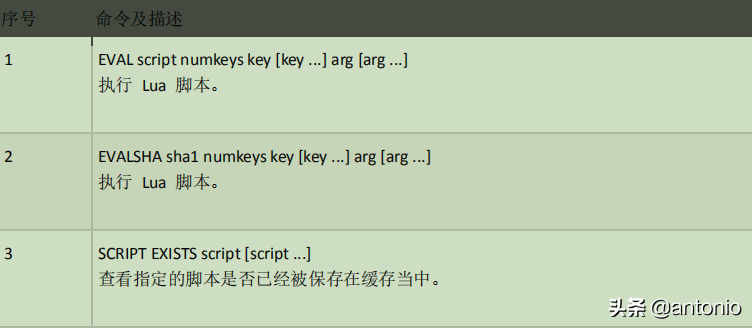
Redis 脚本使用 Lua 解释器来执行脚本。通过内嵌支持 Lua 环境。执行脚本的常用命令为 EVAL。
Eval 命令的基本语法如下:
redis 127.0.0.1:6379> EVAL script numkeys key [key ...] arg [arg ...]
如下面这样:
redis 127.0.0.1:6379> EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first seco
nd
1) "key1"
2) "key2"
3) "first"
4) "second"
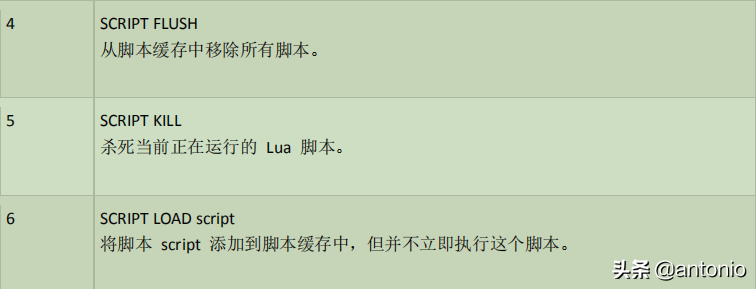
下表列出了 redis 脚本常用命令:
Redis 安全
通过 redis 的配置文件设置密码参数,这样客户端连接到 redis 服务就需要密码验证,这样可以让你的 redis 服务更安全。
可以通过以下命令查看是否设置了密码验证:
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) ""
默认情况下 requirepass 参数是空的,这就意味着你无需通过密码验证就可以连接到 redis 服务。
你可以通过以下命令来修改该参数:
127.0.0.1:6379> CONFIG set requirepass "hello"
OK
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) "hello"
设置密码后,客户端连接 redis 服务就需要密码验证,否则无法执行命令。
AUTH 命令基本语法格式如下:
127.0.0.1:6379> AUTH password
127.0.0.1:6379> AUTH "xxx"
OK
127.0.0.1:6379> SET xxx "Test value"
OK
127.0.0.1:6379> GET mykey
"Test value"
Redis 数据备份与恢复
Redis SAVE 命令用于创建当前数据库的备份。
127.0.0.1:6379> SAVE
OK
将在 redis 安装目录中创建 dump.rdb 文件(具体目录执行命令:CONFIG GET dir 获取)。
save命令是把所有数据库的所有键值对全部记录到RDB文件中,在SAVE命令,执行期间,Redis服务器将阻塞,直到RDB文件创建完为止。如果Redis服务器在执行SAVE命令时,已经存在了相应的RDB,那服务器将使用新创建的RDB文件代替已有的RDB文件。


恢复数据
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。获取redis 目录可以使用 CONFIG 命令,如下所示:
127.0.0.1:6379> CONFIG GET dir
1) "dir"
2) "/usr/local/redis/bin"
以上命令 CONFIG GET dir 输出的 redis 安装目录为 /usr/local/redis/bin。
可以使用非阻塞方式创建RDB,创建 redis 备份文件也可以使用命令 BGSAVE,该命令在后台执行。
127.0.0.1:6379> BGSAVE
Background saving started
还可以设置save选项,当Redis服务器满足条件时,自动执行BGSAVE命令:
save <seconds> <changes>
如果服务器在 seconds 秒之内,对其包含的各个数据库总共执行了至少 changes 次修改,那么服务器将自动执行一次 BGSAVE 命令。
如save 60 10000
当“服务器在 60s 秒之内至少执行了 10000 次修改”这一条件被满足时,服务器就会自动执行一次 BGSAVE 命令。
还可以同时设置多个SAVE选项:
save 6000 1
save 600 100
save 60 10000
当以下任意一个条件被满足时,服务器就会执行一次 BGSAVE 命令:
·在 6000s(100min)之内,服务器对数据库执行了至少 1 次修改。
·在 600s(10min)之内,服务器对数据库执行了至少 100 次修改。
·在 60s(1min)之内,服务器对数据库执行了至少 10000 次修改。
当有多个触发条件导致服务器频繁执行BGSAVE命令,负责自动触发BGSAVE命令的时间计数器以及修改次数计数器都会被清0,并重新开始计数。不管这个命令是SAVE,BGSAVE,还是自动触发的BGSAVE命令创建。
SAVE 与BGSAVE
为了防止save命令带来的阻塞,只能使用BGSAVE命令来创建RDB文件。
由于SAVE命令没有创建子进程,不会因为创建子进程而消耗内存,所以使用save命令能够比BGSAVE 命令更快完成创建RDb文件的工作。
7.Redis 性能测试
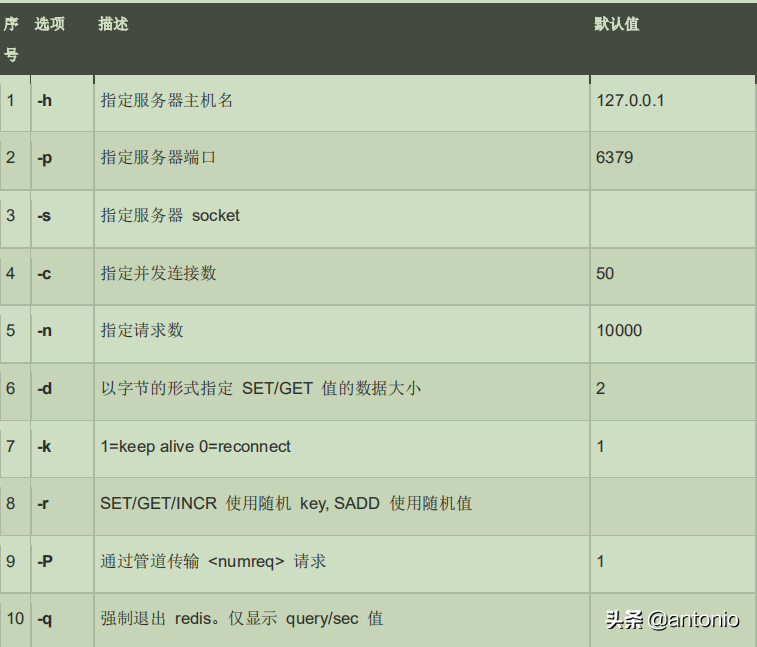
redis 性能测试的基本命令如下:
redis-benchmark [option] [option value]
注意:该命令是在 redis 的目录下执行的,而不是 redis 客户端的内部指令。
以下实例同时执行 10000 个请求来检测性能
$ ./redis-benchmark -n 10000 -q
PING_INLINE: 78740.16 requests per second
PING_BULK: 76335.88 requests per second
SET: 77519.38 requests per second
GET: 83333.34 requests per second
INCR: 84033.61 requests per second
LPUSH: 70422.53 requests per second
RPUSH: 80000.00 requests per second
LPOP: 76923.08 requests per second
RPOP: 85470.09 requests per second
SADD: 78125.00 requests per second
HSET: 86206.90 requests per second
SPOP: 80000.00 requests per second
LPUSH (needed to benchmark LRANGE): 78740.16 requests per second
LRANGE_100 (first 100 elements): 71942.45 requests per second
LRANGE_300 (first 300 elements): 81967.21 requests per second
LRANGE_500 (first 450 elements): 83333.34 requests per second
LRANGE_600 (first 600 elements): 83333.34 requests per second
MSET (10 keys): 64102.56 requests per second
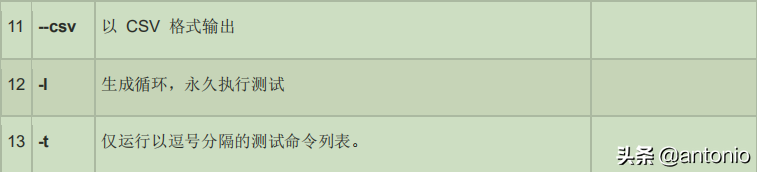
redis 性能测试工具可选参数如下所示:
8.客户端连接
Redis通过监听TCP端口,接收客户端连接,当连接建立后,Redis内部会进行以下操作:
(1)客户端被设置为非阻塞方式,因为Redis采用的就是非阻塞多路复用模型。
(2)为这个 socket 设置 TCP_NODELAY 属性,禁用 Nagle 算法。
(3)创建一个可读的文件事件用于监听这个客户端 socket 的数据发送。
最大连接数是放在redis.conf进行配置,maxclients 的默认值是 10000。
config get maxclients
1) "maxclients"
2) "10000"
以下实例我们在服务启动时设置最大连接数为 100000:
redis-server --maxclients 100000
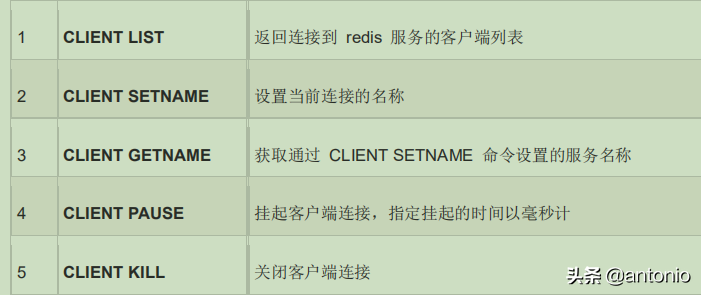
客户端命令:
9.管道技术
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。管道相当于一个缓存队列。
查看 redis 管道,只需要启动 redis 实例并输入以下命令:
$(echo -en "PING\r\n SET kingkey redis\r\nGET kingkey\r\nINCR visitor\r\nINCR visitor\r\nINC
R visitor\r\n"; sleep 10) | nc localhost 6379
+PONG
+OK
redis
:1
:2
:3
通过使用 PING 命令查看 redis 服务是否可用, 之后我们设置了 kingkey 的值为 redis,然后我们获取 kingkey 的值并使得 visitor 自增 3 次。在返回的结果中我们可以看到这些命令一次性向 redis 服务提交,并最终一次性读取所有服务端的响应。管道技术最显著的优势是提高了 redis 服务的性能。
10.Redis 分区
分区是分割数据到多个 Redis 实例的处理过程,因此每个实例只保存 key 的一个子集。
优点:
利用多台计算机内存,构造更大数据库
通过多核和多台计算机,允许扩展计算能力,通过多台计算机的网络适配器,允许扩展网络带宽。
缺点:
(1)多个key的操作通常不支持,当两个set映射到不同的redis实例上,不能对这两个set执行交集操作。
(2)多个 key 的 redis 事务不能使用。
(3)当使用分区时,数据处理较为复杂,比如你需要处理多个 rdb/aof 文件,并且从多个实例和主机备份持久化文件。
(4) 增加或删除容量也比较复杂。redis 集群大多数支持在运行时增加、删除节点的透明数据平衡的能力,但是类似于客户端分区、代理等其他系统则不支持这项特性。
范围分区
最简单的分区方式是按范围分区,就是映射一定范围的对象到特定的 Redis 实例。
如,ID 从 0 到 10000 的用户会保存到实例 R0,ID 从 10001 到 20000 的用户会保存到 R1,以此类推。这种方式是可行的,并且在实际中使用。
不足就是要有个区间范围到实例的映射表,这个表要被管理,同时还要各种对象的映射表。所以要看需求。
哈希分区
hash 分区对任何 key 都适用,也无需是 object_name:这种形式,像下面描述的一样简单。
(1) 用一个 hash 函数将 key 转换为一个数字,比如使用 crc32 hash 函数。对 key foobar 执行 crc32(foobar)会输出类似 93024922 的整数。
(2) 对这个整数取模,将其转化为 0-3 之间的数字,就可以将这个整数映射到 4 个 Redis 实例中的一个了。93024922 % 4 = 2,就是说 key foobar 应该被存到 R2 实例中。
11.C语言使用Redis
进入 redis-6.0.3/deps/hiredis
$ make
$ sudo make install
mkdir -p /usr/local/include/hiredis /usr/local/include/hiredis/adapters /usr/local/lib
cp -pPR hiredis.h async.h read.h sds.h /usr/local/include/hiredis
cp -pPR adapters/*.h /usr/local/include/hiredis/adapters
cp -pPR libhiredis.so /usr/local/lib/libhiredis.so.0.14
cd /usr/local/lib && ln -sf libhiredis.so.0.14 libhiredis.so
cp -pPR libhiredis.a /usr/local/lib
mkdir -p /usr/local/lib/pkgconfig
cp -pPR hiredis.pc /usr/local/lib/pkgconfig
连接 Redis 服务
// 连接 Redis 服务 redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) { if (context) {printf("%s\n", context->errstr);} else { printf("redisConnect error\n"); }exit(EXIT_FAILURE);授权 Auth
redisReply *reply = redisCommand(context, "auth 0voice"); printf("type : %d\n", reply->type); if (reply->type == REDIS_REPLY_STATUS) { /*SET str Hello World*/ printf("auth ok\n"); } freeReplyObject(reply);Set Key Value
har *key = "str";char *val = "Hello World";/*SET key value */reply = redisCommand(context, "SET %s %s", key, val);printf("type : %d\n", reply->type);if (reply->type == REDIS_REPLY_STATUS) { /*SET str Hello World*/ printf("SET %s %s\n", key, val);}freeReplyObject(reply);Get Key
// GET Key reply = redisCommand(context, "GET %s", key); if (reply->type == REDIS_REPLY_STRING) { /*GET str Hello World*/ printf("GET str %s\n", reply->str); /*GET len 11*/ printf("GET len %ld\n", reply->len); } freeReplyObject(reply);APPEND Key Value
// APPEND key value char *append = " I am your GOD"; reply = redisCommand(context, "APPEND %s %s", key, append); if (reply->type == REDIS_REPLY_INTEGER) { printf("APPEND %s %s \n", key, append); } freeReplyObject(reply); /*GET key*/ reply = redisCommand(context, "GET %s", key); if (reply->type == REDIS_REPLY_STRING) { //GET Hello World I am your GOD printf("GET %s\n", reply->str); } freeReplyObject(reply);声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号