深度剖析JDK序列化原理及Fury高性能实现的万字长文
发表时间: 2022-12-07 16:50
简介: 对于Java对象序列化,由于JDK自带的序列化性能很差,业界出现了hessian/kryo等框架来加速序列化。这些框架能够序列化大部分Java对象,但如果对象实现了[writeObject](
https://docs.oracle.com/en/java/javase/18/docs/specs/serialization/output.html#the-writeobject-method)**/**[readObject](
https://docs.oracle.com/en/java/javase/18/docs/specs/serialization/input.html#the-re
Fury是一个基于JIT动态编译的高性能多语言原生序列化框架,支持Java/Python/Golang/C++/JavaScript等语言,提供全自动的对象多语言/跨语言序列化能力,以及相比于别的框架最高20~200倍的性能。
对于Java对象序列化,由于JDK自带的序列化性能很差,业界出现了hessian/kryo等框架来加速序列化。这些框架能够序列化大部分Java对象,但如果对象实现了writeObject/readObject/ writeReplace/readResolve等JDK自定义序列化方法,这些框架便无能为力。由于用户可能在这些方法当中执行任意逻辑,为了保证序列化的正确性,这些方法需要被以符合JDK序列化的行为方式被执行,这时候用户只能选择JDK自带的序列化框架,忍受极其缓慢的性能。
而业务系统的数据对象自定义JDK序列化是很常见的事情,比如下方是某个复杂场景序列化使用Fury测试下来的火焰图,里面就有相当一部分开销在JDK序列化上面(Fury早期版本在遇到自定义JDK序列化的类型时会转发给JDK进行序列化)。
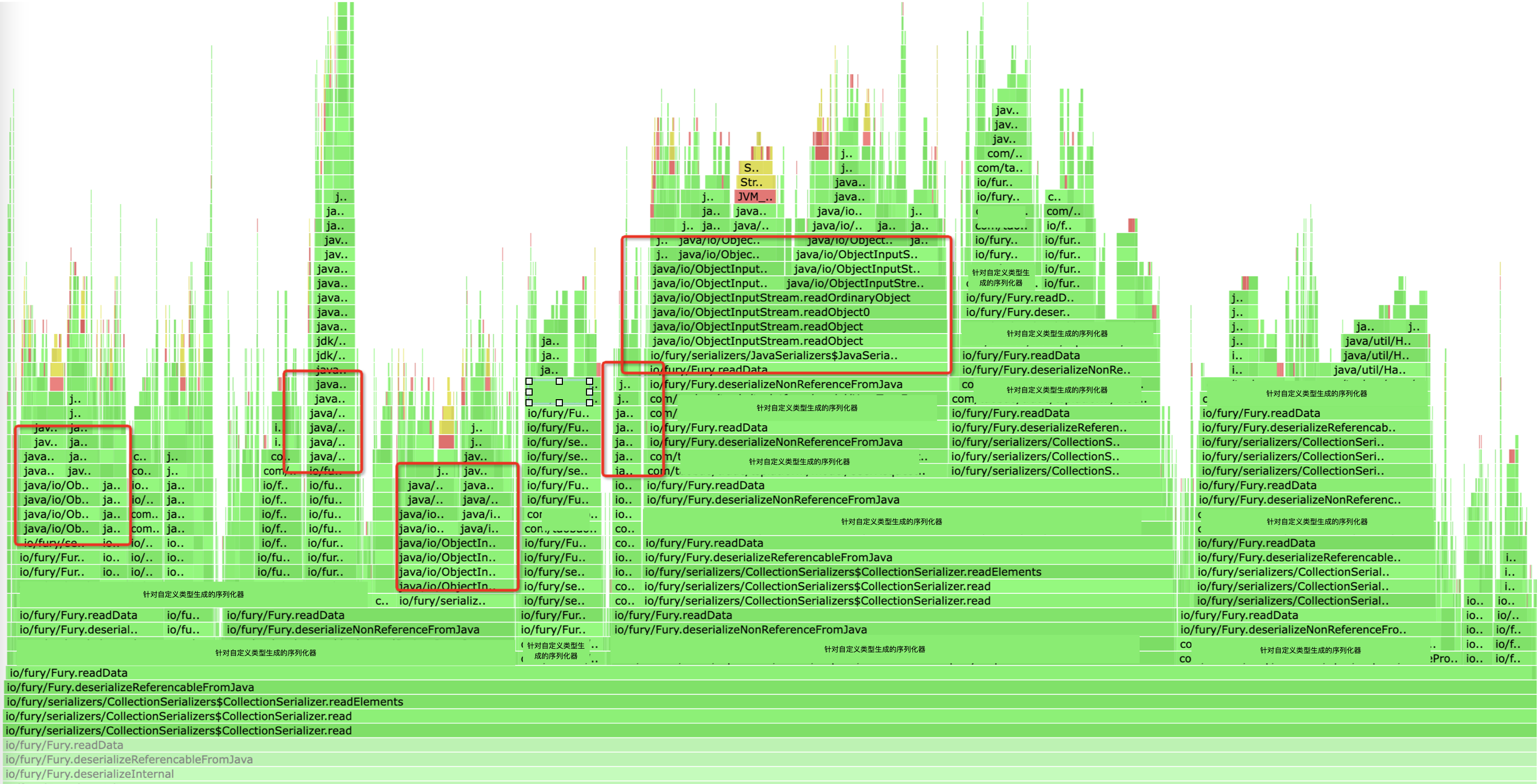
为了提高序列化的性能,保证任意场景不回退,Fury从0.9.2版本开始完整实现了整套JDK序列化协议,兼容所有JDK自定义序列化行为,从而在任意场景避免使用JDK序列化,保证高效的序列化性能。
本文将首先分析JDK序列化原理,接下来基于JDK序列化原理展开hessian/kryo等框架的不足之处,然后介绍Fury的高效兼容实现,最后给出性能对比的数据。
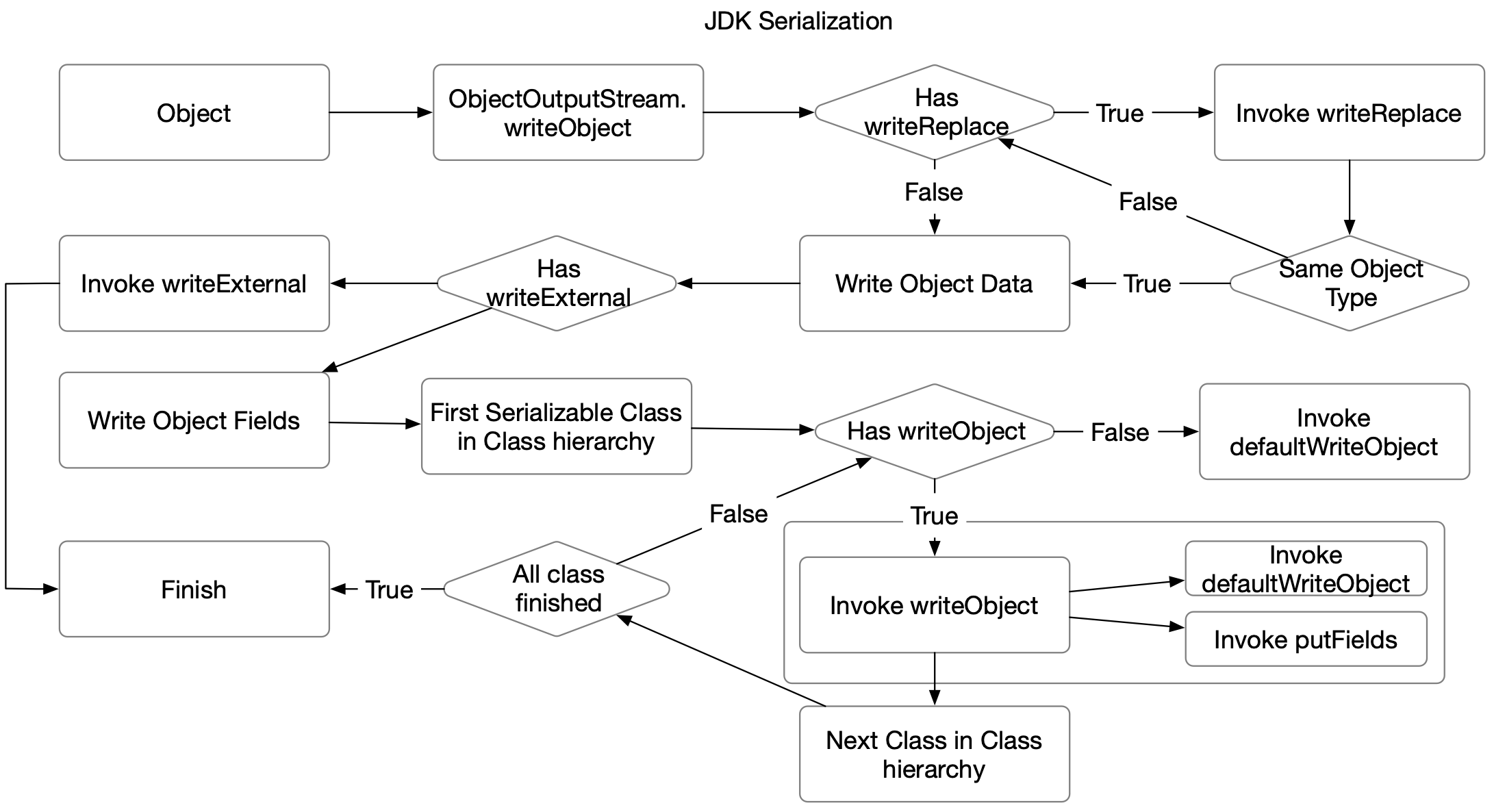
JDK序列化框架使用ObjectOutputStream和ObjectInputStream序列化和反序列化,该框架允许用户通过
Externalizable/writeObject/readObject/readObjectNoData/writeReplace/readResolve等方法来自定义序列化的行为。当要序列化的对象不包含这些方法时,ObjectOutputStream会调用内部的defaultWriteObject来序列化类型层次结构的所有字段和类型信息,反序列化时会使用ObjectInputStream来读取类型层次结构的每个类型相关信息和对应每个字段值并填充整个对象。如果包含自定义序列化方法,则需要走到单独的执行流程。
当对象定义了writeReplace方法时,序列化会先调用该方法,然后使用该方法返回的对象引用取代引用表之前记录的引用。如果返回对象类型不变,即返回类型仍有writeReplace方法,这时候该方法会被忽略,进入正常的writeObject/writeExternal流程。如果返回类型发生变化,则循环调用writeReplace方法重复前述流程。
当返回对象不再包含writeReplace方法时,这时候便进入到字段数据序列化的过程,如果对象实现了Externalizable接口,则调用writeExternal进行序列化,否则从对象层次结构的第一个定义了Serializable的父类开始,依次序列化每个类型以及属于当前类型的所有字段数据。
当对象层次结构的某个类型定义了writeObject方法时,对于对应到该类型的字段的序列化,则会调用调用该类型定义的writeObject方法进行,writeObject方法内部可以调用ObjectOutputStream的defaultWriteObject完成默认字段的序列化,或者完全手写序列化逻辑。
对于不同JDK版本字段不一致需要兼容的情况,则需要调用putFields方法获取PutField对象,用于设置只在某些JDK版本存在但当前JDK版本不存在的字段数据,然后调用writeFields完成字段数据的写入。
比如ThreadLocalRandom就是通过putFields来自定义序列化逻辑:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { java.io.ObjectOutputStream.PutField fields = s.putFields(); fields.put("rnd", U.getLong(Thread.currentThread(), SEED)); fields.put("initialized", true); s.writeFields(); }需要注意defaultWriteObject写的数据可能会通过readFields进行读取,因此其格式需要和和putFields兼容。另外在自定义序列化时
defaultWriteObject/putFields两者只能调用一个。
整体流程如下图:
反序列化首先会读取对象类型,然后查询该类型的无参构造函数用于创建对象,如果不存在无参数构造函数,则通过ReflectionFactory#
newConstructorForSerialization(java.lang.Class<?>)向上遍历类型层次结构直到获取到第一个非Serializable父类的无参构造函数(该过程会进行缓存,避免重复查找)。
然后根据构造函数创建对象,并将对象放入引用表,避免循环引用找不到对象。
接下来从第一个Serializable父类开始依次反序列化每个类型和对应的字段数据,并填充到之前通过构造函数创建的对象里面。如果某个反序列化的类型不存在,则代表对象层次结构发生了变化,反序列化端对象增加了新的父类,如果该类型定义了readObjectNoData方法,则会调用该方法初始化字段状态,否则这部分字段将出于默认状态。
如果父类类型没有定义readObject,则会通过调用defaultReadObject来依次读取每个非transient非static字段的值并填充到对象里面。如果定义了readObject方法,则调用该方法完成该类型数据的反序列化。
readObject方法可以调用defaultReadObject来完成默认字段值的反序列化,然后执行其它自定义逻辑,或者完全手写反序列化逻辑。
对于不同JDK版本字段不一致需要兼容的情况,则需要调用readFields方法获取GetField对象,该对象可能包含当前Class版本没有的字段数据,这时候可以直接忽略掉,其它字段可以从GetField里面查询出来并设置到对象上面。需要注意defaultReadObject和readFields两者只能调用一个。
某些情况下父类字段的反序列化依赖子类字段反序列化后的状态,由于父类字段先反序列化,这时候无法获取子类反序列化后的状态,因此JDK提供了registerValidation回调来在整个对象完成反序列化后执行,这时可以执行额外的操作恢复对象的状态。
在对象完成序列化之后,检查对象所在类型是否定义了readResolve方法,如果定义了该方法,则调用该方法返回替代对象,如果返回类型发生变化,则循环调用readResolve方法重复前述流程。
在执行完readResolve之后,整个对象便完成了反序列化。
Hessian目前支持writeReplace/readResolve自定义方法,当对象定义了writeReplace方法时,会通过
com.caucho.hessian.io.WriteReplaceSerializer进行序列化。该序列化器能够满足部分场景需求,但当writeReplace方法返回相同类型的新对象时,hessian会出现栈溢出:
public static class CustomReplaceClass implements Serializable { Object writeReplace() { return new CustomReplaceClass(); } Object readResolve() { return new CustomReplaceClass(); }}Exception in thread "main" java.lang.StackOverflowError at java.base/java.lang.reflect.InvocationTargetException.<init>(InvocationTargetException.java:73) at jdk.internal.reflect.GeneratedMethodAccessor1.invoke(Unknown Source) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at com.caucho.hessian.io.WriteReplaceSerializer.writeReplace(WriteReplaceSerializer.java:184) at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:155) at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465) at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:167) at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465) at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:167) at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465) at com.caucho.hessian.io.WriteReplaceSerializer.writeObject(WriteReplaceSerializer.java:167) at com.caucho.hessian.io.Hessian2Output.writeObject(Hessian2Output.java:465)Hessian目前不支持writeObject/readObject方法,当要序列化的对象定义了这些方法时,hessian会直接忽略掉,而在实际场景中很多对象都定义了这两个方法,JDK大部分类型也都定义了这两个方法,导致hessian在序列化这些类型时出现状态不一致的错误。
一般在这些类型里面,数据字段一般标记为transient,因此忽略这两个方法直接序列化所有非transient字段会导致数据丢失,比如LinkedBlockingQueue的主要数据字段都全部是transient,在writeObject里面进行特殊的处理:
/** * Head of linked list. * Invariant: head.item == null */ transient Node<E> head; /** * Tail of linked list. * Invariant: last.next == null */ private transient Node<E> last; private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { fullyLock(); try { // Write out any hidden stuff, plus capacity s.defaultWriteObject(); // Write out all elements in the proper order. for (Node<E> p = head.next; p != null; p = p.next) s.writeObject(p.item); // Use trailing null as sentinel s.writeObject(null); } finally { fullyUnlock(); } }同时由于没有执行这两个方法里面的自定义逻辑,最终反序列化的对象状态也会不对。比如Java
java.util.concurrent.locks.AbstractQueuedLongSynchronizer的子类都需要自定义readObject方法来重设lock状态:
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { s.defaultReadObject(); readHolds = new ThreadLocalHoldCounter(); setState(0); // reset to unlocked state}对于常见类型,或许可以通过内置序列化器来进行序列化,但这无法枚举所有已知类型和未知类型,一旦出现序列化错误,比如多线程Lock状态错误,将极其难以排查。
同时hessian不支持父子类出现重名字段,这在某些条件下也会成为一个使用限制。
因此在RPC框架里面,很多场景用户会直接选择JDK序列化,这些场景现在全部都可以切换为FURY进行加速。
Kryo为了保证序列化的正确性,在遇到定义了
writeObject/readObject/readObjectNoData/writeReplace/ readResolve的对象时,会调用JDK的ObjectOutputStream和ObjectInputStream进行序列化。该方式存在三个问题:
kryo不支持父子类出现重名字段,这在某些条件下也会成为一个使用限制。
Fury早期版本序列化流程跟Kryo类型,在遇到
writeObject/readObject/readObjectNoData/writeReplace/ readResolve的对象时,调用JDK的ObjectOutputStream和ObjectInputStream进行序列化。
在Fury 0.9.2版本,我们提供了一套基于JIT动态编译的100%兼容JDK自定义序列化的实现,性能数量级提升。
整体实现流程模拟了JDK序列化的过程,但实现上使用了Fury内置的JIT序列化器来进行加速和减少序列化结果大小,同时对于对象层次结构的每个Serializable class,只序列化类名称,不序列化类的元数据,减少开销。
整体实现在
io.fury.serializers.ReplaceResolveSerializer和
io.fury.serializers.ObjectStreamSerializer两个序列化器里面,分别负责writeReplace/readResolve自定义序列化和
writeObject/readObject/readObjectNoData自定义序列化。
ReplaceResolveSerializer完整实现了JDK相同的replace/resolve行为,即使在writeReplace方法返回相同类型不同引用的对象,也能够正常序列化,不会出现hessian一样的栈溢出问题。同时在返回对象类型跟原始对象类型不同时,fury可以避免写入原始对象的类名称,减少序列化的结果大小。
如果对象同时定义了
writeObject/readObject/readObjectNoData/writeReplace/readResolve方法,fury会分发给ReplaceResolveSerializer处理引用replace/resolve,将处理完之后的对象再交给ObjectStreamSerializer进行JDK自定义序列化流程。
ObjectStreamSerializer实现了整套JDK
writeObject/readObject/readObjectNoData/registerValidation行为,保证行为跟JDK的一致性,在任意情况下序列化都不会报错。由于用户在writeObject/readObject/
readObjectNoData/registerValidation里面调用的是JDK
ObjectOutputStream/ObjectInputStream /PutField/GetField的接口,因此Fury也实现了一套
ObjectOutputStream/ObjectInputStream/PutField/ GetField的子类,保证实际序列化逻辑可以转发给Fury。
为了保证类型前后兼容,同时保证
defaultWriteObject/defaultReadObject跟putFields/readFields的兼容性,字段数据序列化使用的是Fury的CompatibleSerializer,在读写端类型不一致的情况下也可以争取反序列化。为了保证高性能,在开启JIT模式时会通过
io.fury.serializers.CodegenSerializer#
loadCompatibleCodegenSerializer创建JITCompatibleSerializer进行序列化。
整体实现分为序列化器初始化部分和执行部分。
点击查看原文,获取更多福利!
https://developer.aliyun.com/article/1102715?utm_content=g_1000365751
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号