「Java篇」-深度解析JIT机制
发表时间: 2022-02-13 11:22
JIT(just in time)即时编译器,JVM运行时,使用JIT编译器将字节码编译成本地机器代码,提高程序运行效率。
通常情况下,javac将程序源码编译,转换为java字节码(class文件),这种代码格式无法直接在操作系统中运行,需要不同平台的JVM通过解释器(interpreter)将字节码逐条翻译为相应的机器指令进行执行,这种情况下,肯定比直接运行二进制机器码的速度要慢,所以为了提高运行速度,JVM引入了JIT技术。
由于日常开发中使用的JVM大多数是SUN公司的HotSpot虚拟机,所以以下都是根据HotSpot虚拟机为出发点的。
//内联前代码:public int sum(int a, int b){ return add(a,b) + 10;}public int add(int a,int b){ return a + b;}//内联后:会取消add方法public int sum(int a, int b){ return a + b + 10;}//如果想要知道方法被内联的情况,可以使用JVM参数来配置:-XX:+PrintCompilation. //在控制台打印编译过程信息-XX:+UnlockDiagnosticVMOptions //解锁对JVM进行诊断的选项参数,开启后支持一些特定参数对JVM进行诊断-XX:+PrintInlining //将内联方法打印出来逃逸分析是一种确定指针动态范围的静态分析,分析程序中哪些地方可以访问到对象指针,编译器会对对象进行逃逸分析,如果对象没有发生逃逸,则可以在栈上分配(标量替换)、锁消除等优化操作;
栈上分配指的是java对象一般都是在堆上分配,堆上分配的对象需要进行GC,如果一个对象经过逃逸分析之可能被当前线程进行访问,则该对象可以直接分配在栈上,分配在栈上可以随着栈帧的弹出被销毁,不需要GC的介入。
关于逃逸分析又可以写一大篇文章了,后续有时间补一篇文章记录一下。
扩展知识:JDK9引入了Graal编译器来替代C2编译器,需要手动开启
-XX:+
UnlockExperimentalVMOptions -XX:+UseJVMCICompiler
区别:
Graal是用java写的,C2是C++写的
Graal使用模块化开发,更容易开发和维护
Graal相对于C2优化的变化更主要的是内联算法,Graal对于新语法更加友好,比如lambda表达式
回归正题:
在JDK7之前需要开发人员手动选择开启哪个编译模式 C1对应 -clinet,C2对应 -server,但是在JDK7及以后,JVM引入了分层编译模式(tiered compilation)的概念,综合了C1的高启动性能和C2的高峰值性能,使用命令 java -XX:+PrintFlagsFinal 可以查看到 TieredCompilation 默认打开
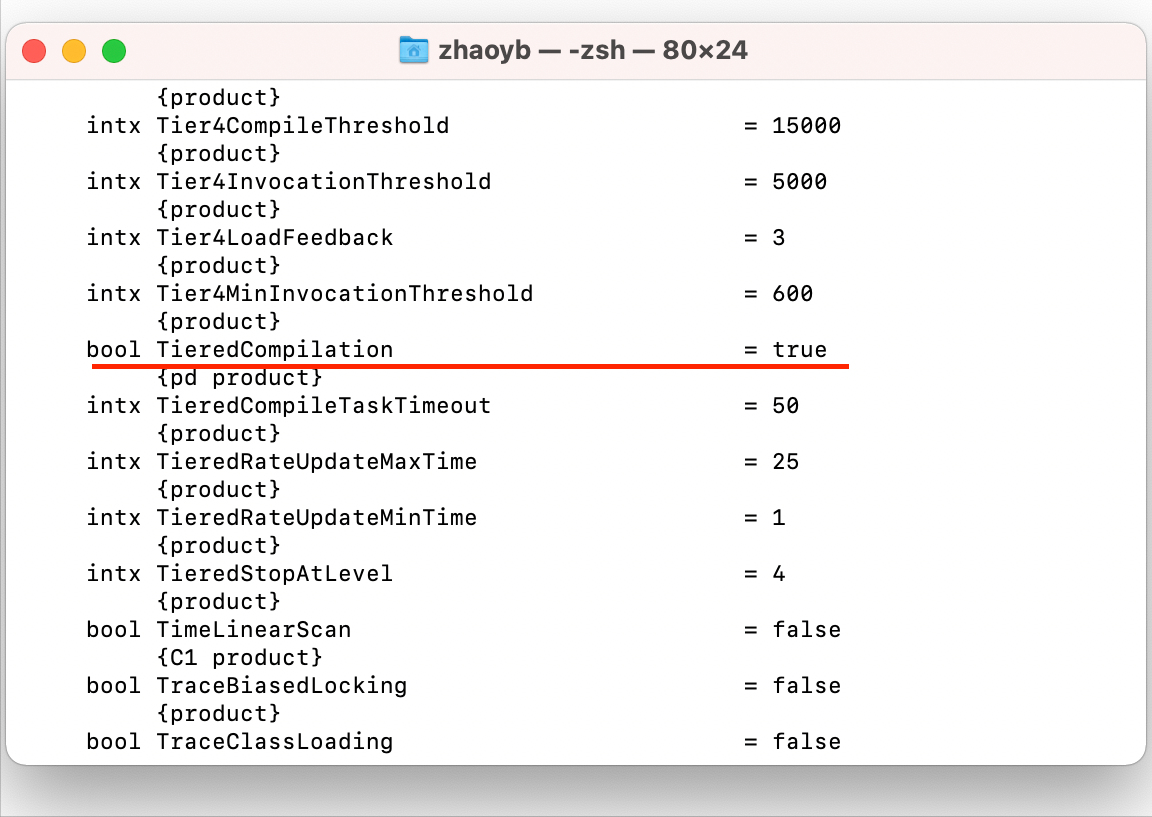
最终C1和C2以及解释器(interpreter)将JVM的执行方式划分为5个级别:
Level0:interpreter解释执行
Level1: C1编译,无profiling(性能监控功能)
Level2:C1编译,仅方法及循环back-edge执行次数的profiling(性能监控功能)
Level3:C1编译,除level2中的profiling外还包括branch(针对分支跳转字节码)以及receiver type(针对成员方法调用或类检测,如checkcast、instanceof)的profiling
Level4:C2编译
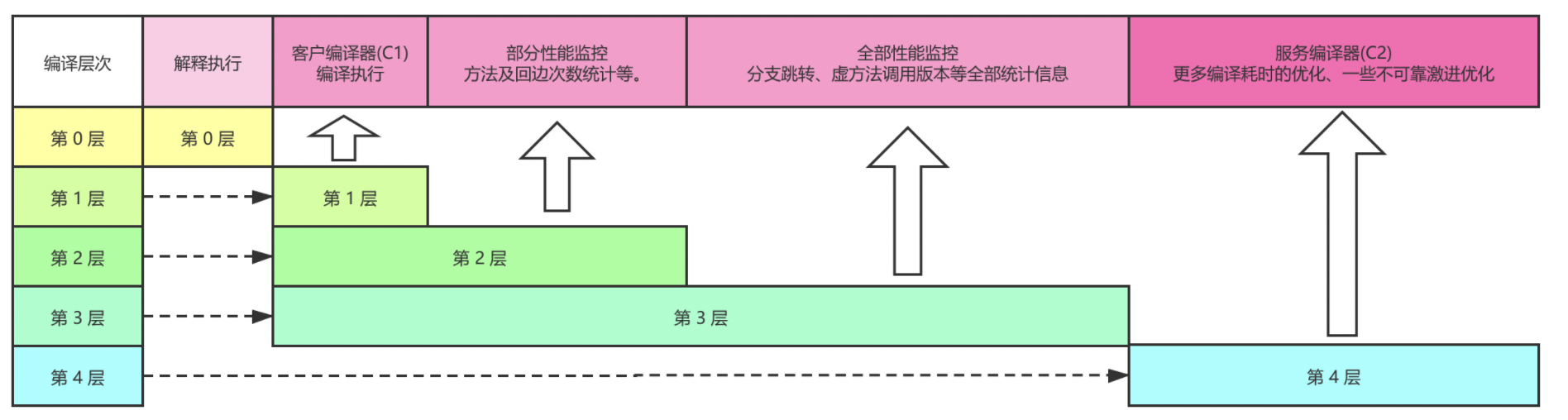
分层编译的交互关系如图所示:

上图列举了4 种编译模式(非全部)。
1、通常情况下,一个方法先被解释执行(level 0),然后被C1 编译(level 3),再然后被得到profile 数据的C2 编译(level 4)。
2、如果编译对象非常简单,虚拟机认为通过C1 编译或通过C2 编译并无区别,便会直接由C1 编译且不插入profiling 代码(level 1)。
3、在C1 忙碌的情况下,interpreter 会触发profiling,而后方法会直接被C2 编译;
4、在C2 忙碌的情况下,方法则会先由C1 编译并保持较少的profiling(level 2),以获取较高的执行效率(与3 级相比高30%)。
注:profiling:指在程序执行过程中,收集能够反映程序执行状态的数据,这里收集的数据称之为程序的profile
JIT的工作重点就是找到热点代码进行优化,那么如何确认哪些是热点代码呢:
1、被多次调用的方法
方法调用触发的编译,编译器会以整个方法作为编译对象,是标准的JIT编译方式
2、被多次执行的循环体
虽然是循环体触发的编译动作,但是编译器依然按照整个方法作为编译对象,这种编译方式称为栈上替换(On Stack Replacement 简称OSR编译),为什么需要编译整个方法呢?因为这种编译发生在方法执行过程中,方法的栈帧还在栈上,方法就被替换了。
判断一段代码是不是热点代码,是不是需要触发即时编译,这种行为称之为热点探测(Hot Spot Detection)目前的热点探测有两种方法:
1、基于采样的热点探测:虚拟机会周期性的检查各个线程的栈顶,如果发现某个(或者某些)方法经常出现在栈顶,那就认为这个方法是热点方法。好处就是简单、高效,还可以很容易的获取方法调用关系(展开调用栈),缺点是很难精确的确认一个方法的热度,也容易因为受到线程阻塞或别的外界因素的影响。
2、基于计数器的热点探测:为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,超过一定阈值就认为是热点方法。缺点是实现起来比较麻烦,需要维护很多的计数器,并且不能直接获取方法的调用关系,优点就是结果精确且严谨。
HotSpot虚拟机使用的是第二种,JVM为每个方法都准备了两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter)
1、方法调用计数器:
默认阈值:Client模式下是1500次,Server模式下是10000次,超过这个阈值,就会触发JIT编译,可以通过命令:-XX:+CompileThreshold来人为设定

当一个方法被调用,会先检查该方法是否存在已经被JIT编译过的版本,如果存在,则优先使用编译后的本地代码来执行,如果不存在已经编译过的版本,则将此方法的调用计数器值+1,然后判断方法调用计数器和回边计数器之和是否超过方法调用计数器的阈值,如果已经超过阈值,则会向即使编译器提交一个该方法的代码编译请求,在触发了JIT编译后,在默认设置下,执行引擎并不会同步等待编译请求完成,而是继续进入解释器按照解释器方式执行字节码,直到提交的请求被编译器编译完成为止(编译工作在后台线程进行),当编译工作完成后,下一次调用该方法或者代码时,就会使用已编译的版本。
2、回边计数器:
统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称之为回边(Back Edge),建立回边计数器的目的就是为了触发OSR编译。
好了,以上就是我对于JIT的理解,不足和错误的地方希望大家及时指出,共同学习,共同进步。
白驹过隙,忽然而已,我们需要在这个世界上留下点什么,证明我们来过,我选择了文字。
保持求知的心,一直在路上,我们下期再见。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号