移动开发必备:深入理解编译流程
发表时间: 2023-03-20 07:48
作者:京东零售 李臣臣
阅读本文,或许能够了解关于以下的几个问题: 1、编译器是什么?为什么会有编译器这样一个东西? 2、编译器做了哪些工作?整个编译过程又是什么? 3、Apple的编译器发展历程以及为什么会抛弃GCC换成自研的LLVM? 4、从编译器角度看Swift与OC能够实现混编的底层逻辑
说点常识,众所周知,作为开发者我们能看懂这样的代码:
int a = 10;int b = 20;int c = a + b;而对于计算机貌似只能明白这样的内容:
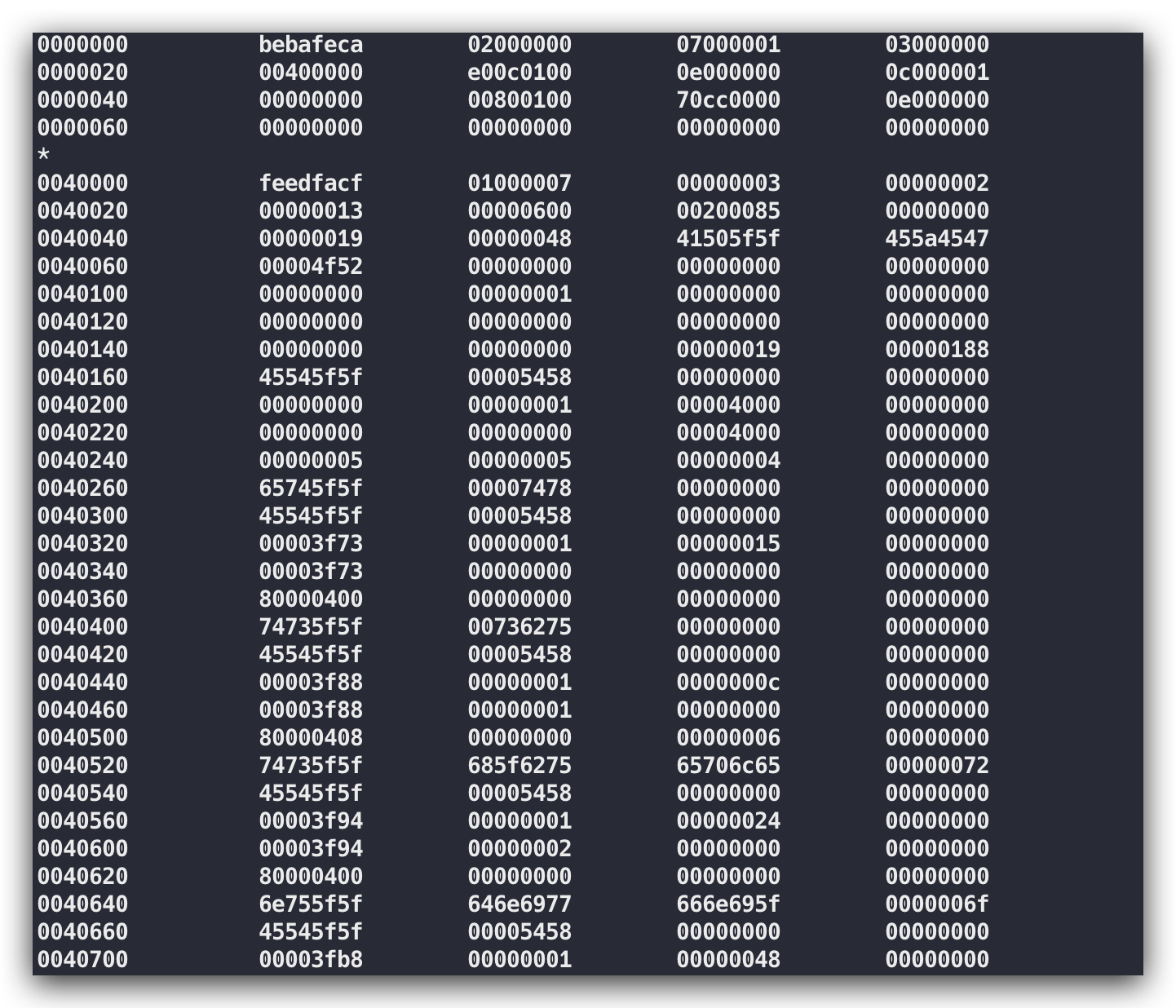
注:使用 od -tx1 /tmp/binary.bin 可以根据需要输出二进制、八进制或者十六进制的内容
这样看的话,计算机除了知道1与0的含义,其他的字符内容完全不知道。为了去给计算机下达我们需要的指令,我们又不得不得按照计算机能够懂得语言与其进行通信交流,怎么办呢?我们貌似需要找一个翻译,将我们的想要下达的指令内容交给翻译让其成计算机能够识别的指令进行内容传达,这样计算机就能通过翻译来一步步执行我们的指令动作了,那这个翻译其实就是我们经常说到的编译器。
说到编译器呢?它的历史还是很悠久的,早期的计算机软件都是用汇编语言直接编写的,这种状况持续了数年。当人们发现为不同类型的中央处理器CPU编写可重用软件的开销要明显高于编写编译器时,人们发明了高级编程语言。简单说就是由于中央处理器CPU的差异,使得软件的开发成本很高,我们要针对不同的CPU编写不同的汇编代码,而且不同的CPU架构呢相对应的汇编的指令集也有差异。如果在汇编体系之上定义一套与汇编无关的编码语言,通过对通用的这样语言进行转换,将其转换成不同类型的CPU的汇编指令,是不是就能解决不同CPU架构适配的问题呢?那其中的定义的通用编码语言就是我们所说的高级语言,比如C/C++、Object-C、Swift、Java等等,而其中的汇编翻译转换工作呢则交由具体的编译器进行实现。
对于Apple的编译器,就不得不说一下GCC与LLVM的相爱相杀了。由于编译器涉及到从高级开发语言到低级语言的转换处理,复杂度自然不必多说。我们都知道Apple产品软件的开发语言是Objective-C,可以认为是对C语言的扩展。而C语言所使用的编译器则是大名鼎鼎的GCC,此时的GCC肯定是妥妥的大哥了,所以早些年为了不必要的资源投入,对于自家OC(Objective-C简称OC)编译器的开发索性直接拿大哥的代码GCC进行二次开发了,没错,从主干版本中拉个独立分支搞起。这么看的话,Apple早期就已经开始了降本增效了?
随着OC语言的不断迭代发展,语言特性也就愈来愈多,那编译器的新特性能力支持当然也得跟得上啊?但是C也在不断的迭代发展,GCC编译器的主干功能当然也越来越多,OMG!单独维护的OC编译器版本对GCC主干的新功能并没有很好的同步,关键在合并功能的时候不可避免的出现种种冲突。为此,Apple曾多次申请与GCC主干功能合并同步,GCC乍一看都是OC 特性feature,跟C有毛线关系?所以关于合并的优先级总是排到最低,Apple也是没有办法,结果只能是差异化的东西越来越多,编译器的维护成本也变得异常之高。
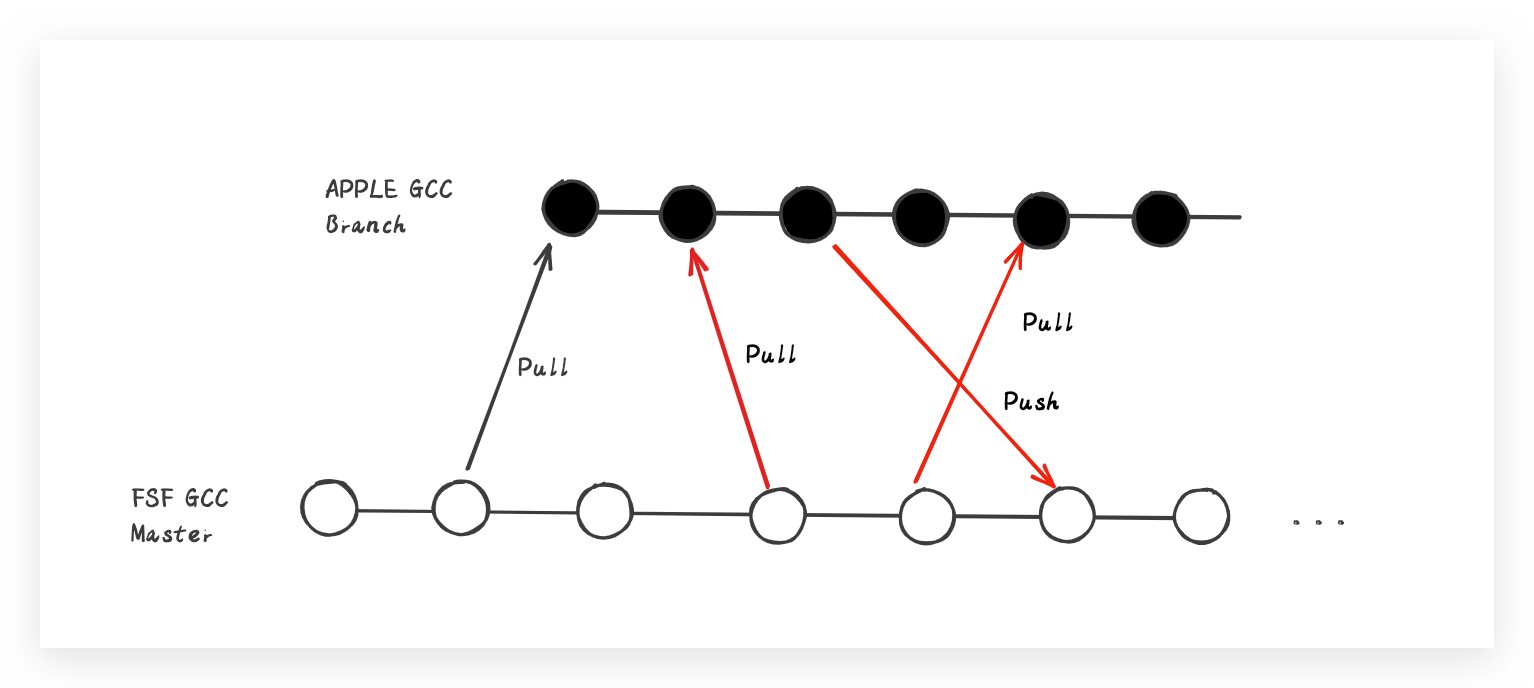
除了以上的问题之外,GCC整体的架构设计也是非模块化的,那什么是模块化呢?比如我们通常在系统设计的时候,会将各个系统的功能进行模块化分割设计,不同的模块能够单独为系统内部提供不同的功能。同时呢,我们还能把这些模块单独抽离出来提供给外部使用,这就增大了系统的底层的灵活度,简单说就是能够直接使用模块化的接口能力。
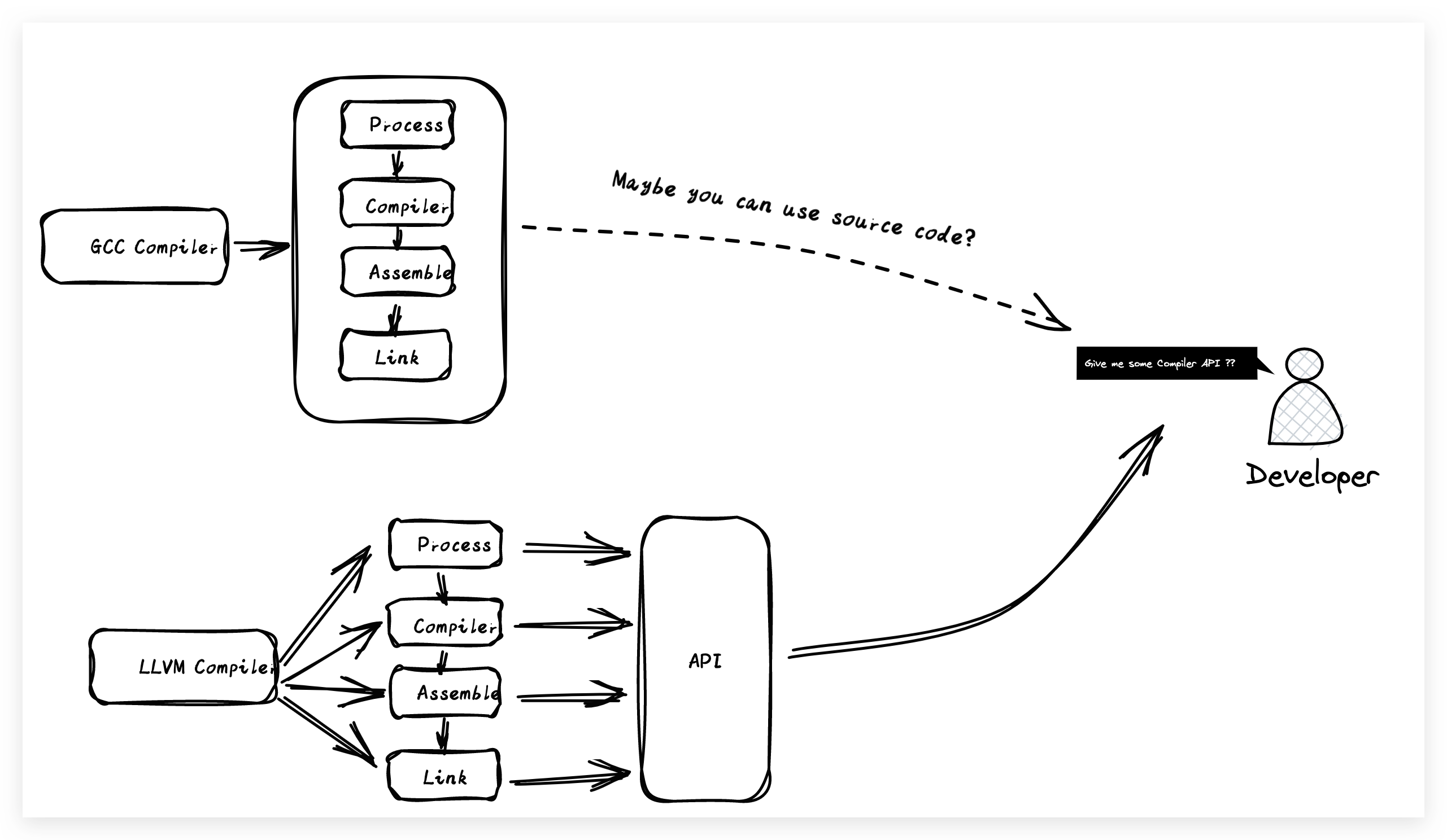
所以Apple深知定制化的GCC编译器将是后续语言迭代升级的绊脚石,内部也在不断的探索能够替代GCC的替代品。在编译器的探索路上,这里不得不说一下Apple的一位神级工程师 Chris Lattner(克里斯·拉特纳),可能光说名字的话可能没有太多人知道他,那如果要说Swift语言的创始人是不是就有所耳闻了?由于克里斯在大学期间对编译器的细致的研究,发起了LLVM(Low Level Virtual Machine)项目对编译的源代码进行了整体的优化。Apple将目光放在了克里斯团队身上,同时直接顾用了他们团队,当然克里斯也没有辜负众望,在 Xcode从 3.1实现了llvm-gcc compiler,到 3.2实现了Clang 1.0, 再到4.0实现了Clang 2.0 ,后来在Mac OS X 10.6 开始使用LLVM的编译技术,到现在已经将LLVM发展成为了Apple的核心编译器。
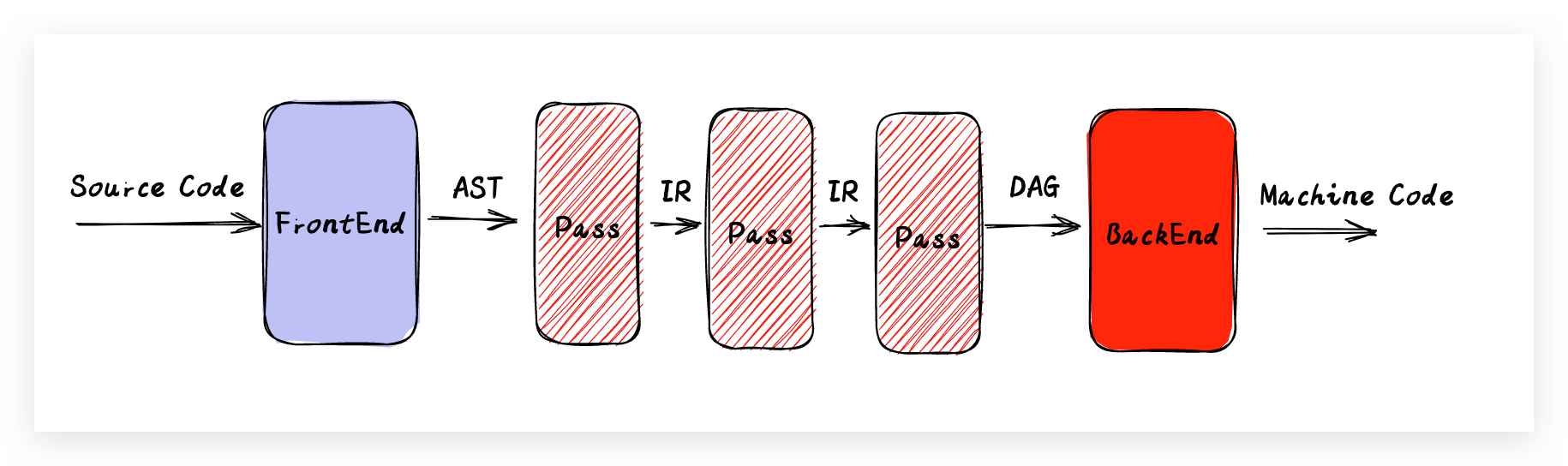
对于传统的编译器,主要分为前端、优化器和后端,引用一张通用的简洁的编译过程图,如下:

简单来说,针对于源代码翻译成计算机底层代码的过程中呢要经历三个阶段:前端编译、优化器优化、后端编译。通过前端编译之后,针对编译的产物进行优化处理,最后通过后端完成机器码的生成。而对于LLVM编译器来说,这里我们以OC的前端编译器Clang为例,它负责LLVM的前端的整体编译流程(预处理、词法分析、语法分析和语义分析),生成中间产物LLVMIR,最后由后端进行架构处理生成目标代码,如下图:
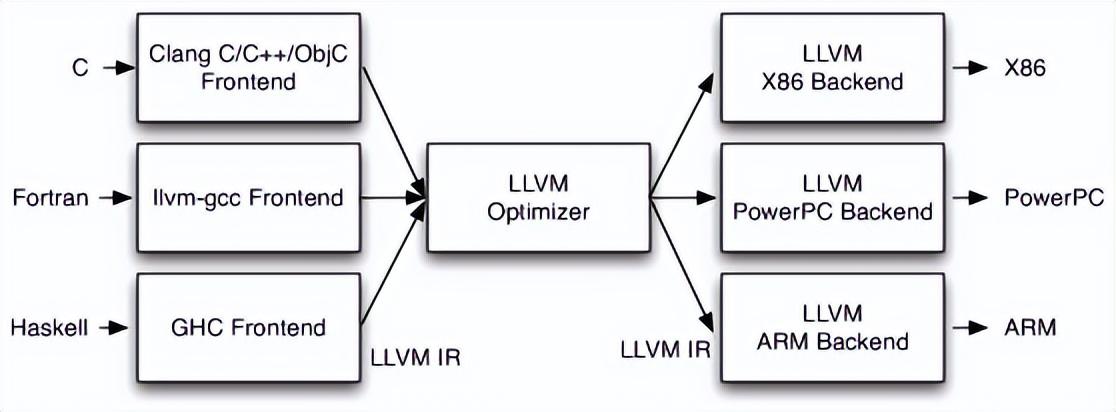
可以看出LLVM将编译的前后端独立分开了,前端负责不同语言的编译操作,如果增加一个语言的编译支持,只需要扩展支持当前语言的前端编译支持(Clang负责OC前端编译、SwiftC负责Swift前端编译)即可,优化器与后端编译器整体均不用修改即可完成新增语言的支持。同理,对于后端,如果需要新增新的架构设备的支持,只需要扩展后端架构对应编译器的支持即可完成新架构设备的支持,这也是LLVM编译器的优点之一。

在XCode中针对于OC与Swift的编译有着不同的前端编译器,OC采用Clang进行编译,而Swift则采用SwiftC编译器,两种不同的编译器前端在编译之后,生成的中间产物都是LLVMIR。这也就解释了对于高级语言Swift或者OC开发,哪怕是混编,在经过各自的编译器前端编译之后,最终的编译产物都是一样的,所以选用哪种开发语言对于最终生成的中间代码IR都是通用的。对于Clang的整体编译过程,如下图所示:
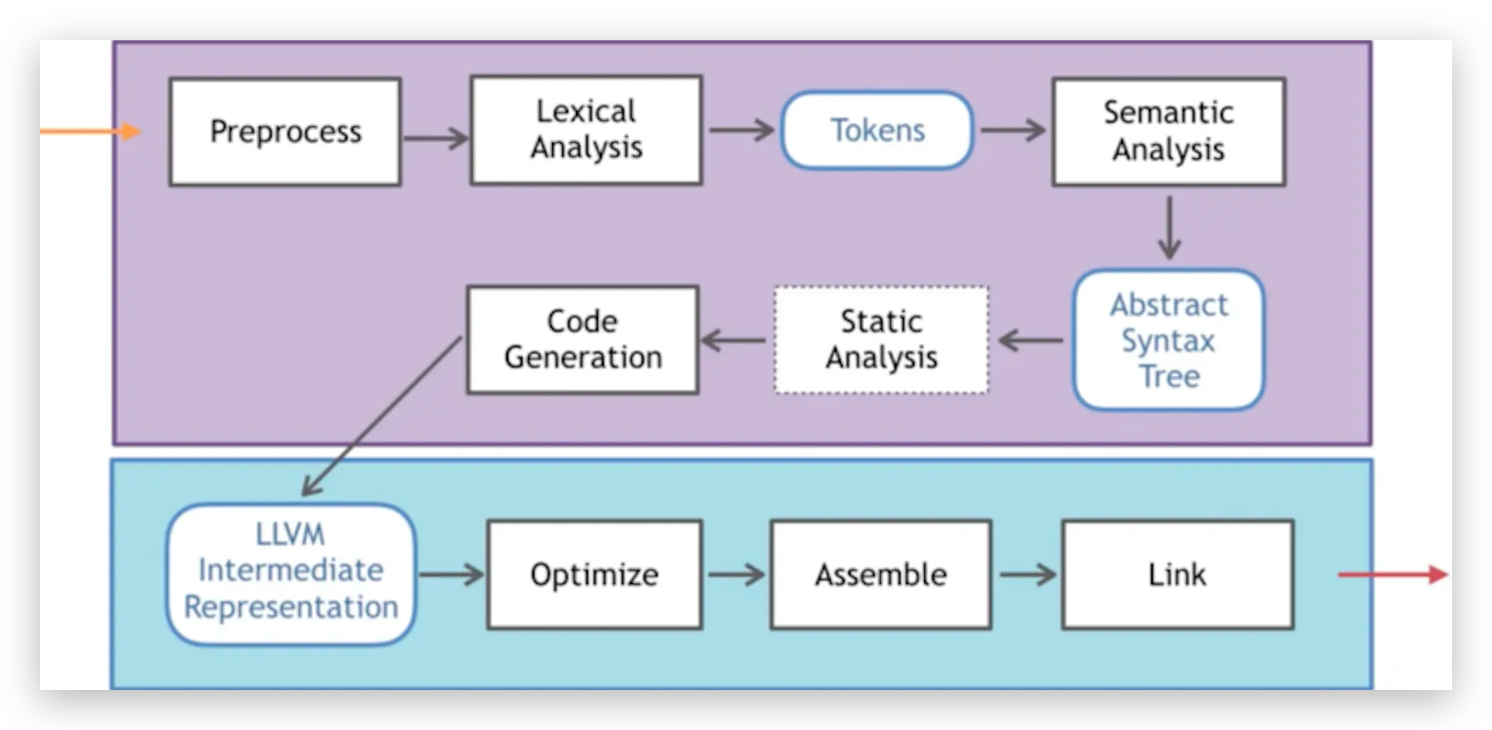
通过对源代码中以“#”号开头如包含#include,宏定义制定#define等扫描。然后进行源代码定义替换,进行头文件内容的展开。通过预处理器把源文件处理成.i文件。
在词法分析完成之后会生成 token 产物,它是做什么的?这里不贴官方的解释了,简单点说就是对源代码的原子切分,切分成能够底层描述的单个原子,就是所谓的token,至于token长什么样子?可以通过 clang 的命令执行编译查看生成的原子内容:
clang -fmodules -E -Xclang -dump-tokens xxx.m#import <UIKit/UIKit.h>#import "AppDelegate.h"int main(int argc, char * argv[]) { NSString * appDelegateClassName; @autoreleasepool { // Setup code that might create autoreleased objects goes here. appDelegateClassName = NSStringFromClass([AppDelegate class]); int a = 0; } return UIApplicationMain(argc, argv, nil, appDelegateClassName);}我们拿工程的main.m 做个测试,编译生成的内容如下:

注:如果遇到 main.m:8:9: fatal error: 'UIKit/UIKit.h' file not found 错误,可以加上系统基础库路径如下:
clang \-fmodules \-E \-Xclang \-dump-tokens \-isysroot \/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \main.m 可以发现,计算机在进行源码处理的时候,并不能像人一样能够理解整个源码内容的含义。所以为了进行转换,在进行源码分析的时候,将整体的内容进行单词切分,形成原子为后续的语义分析做准备,整体的切分过程大致采用的是状态机原理。
在完成词法分析之后,编译器大致理解了每个源码中的单词的意思,但是对于单词组合起来的语句内容并不能理解。所以接下来需要对单词组合起来的内容进行识别,也就是我们所说的语法分析。 语法分析的原理有点模板匹配的意思,怎么理解呢?就是我们常说的语法规则,在编译器中预置了相关语言的语法规则模板,如果匹配了相关的规则,则按照相关语法规则进行解析。举个例子,比如我们在OC中写一个这样的语句:
int a = 100;这是一种通用的赋值语法格式,所以在编译器进行语法分析的时候,将其按照赋值语法的规则进行解析,如下:
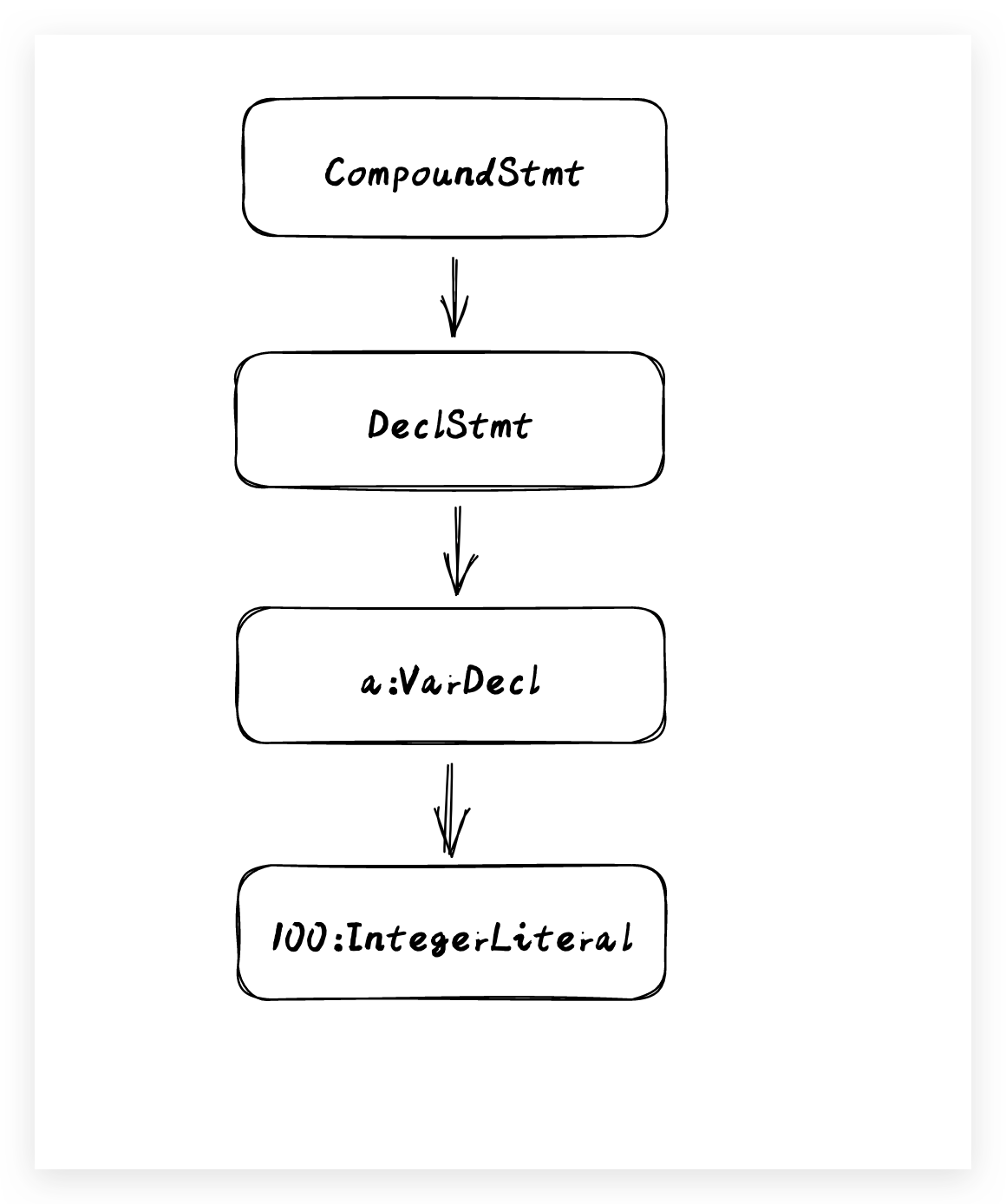
通过对原子token的组合解析,最终会生成了一个抽象语法树(AST),AST抽象语法树将源代码转换成树状的数据结构,它描述了源代码的内容含义以及内容结构,它的生成能够让计算机更好的理解和处理中间产物。以XCode生成的默认项目的main.m内容为例,在 clang 中我们依旧可以查看具体的抽象生成树(AST)的样子,可以对源码进行如下的编译:
clang \-isysroot \/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \-fmodules \-fsyntax-only \-Xclang \-ast-dump \main.m编译后的结果如下:
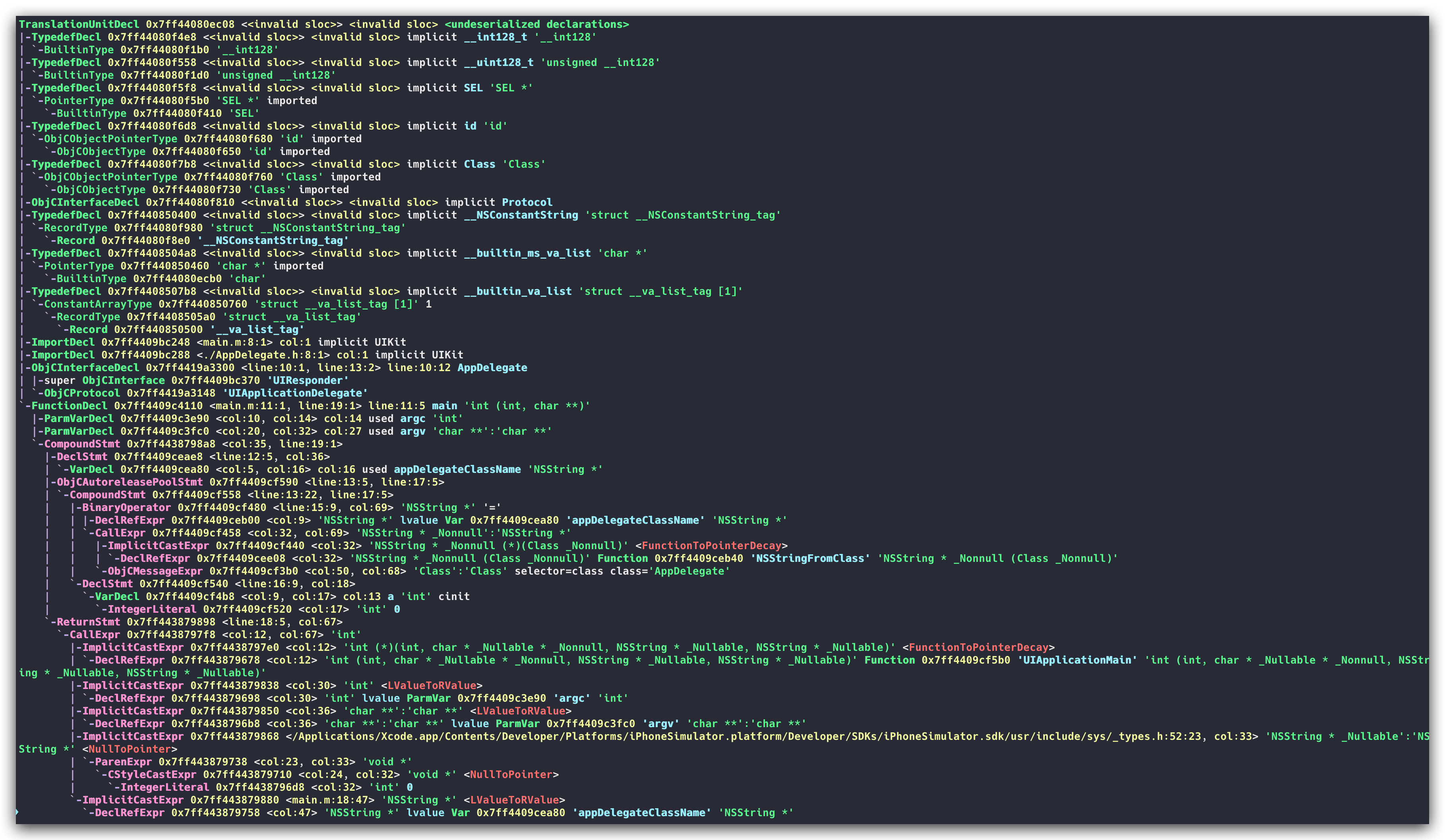
简单转换一下树形视图,大致长这样:
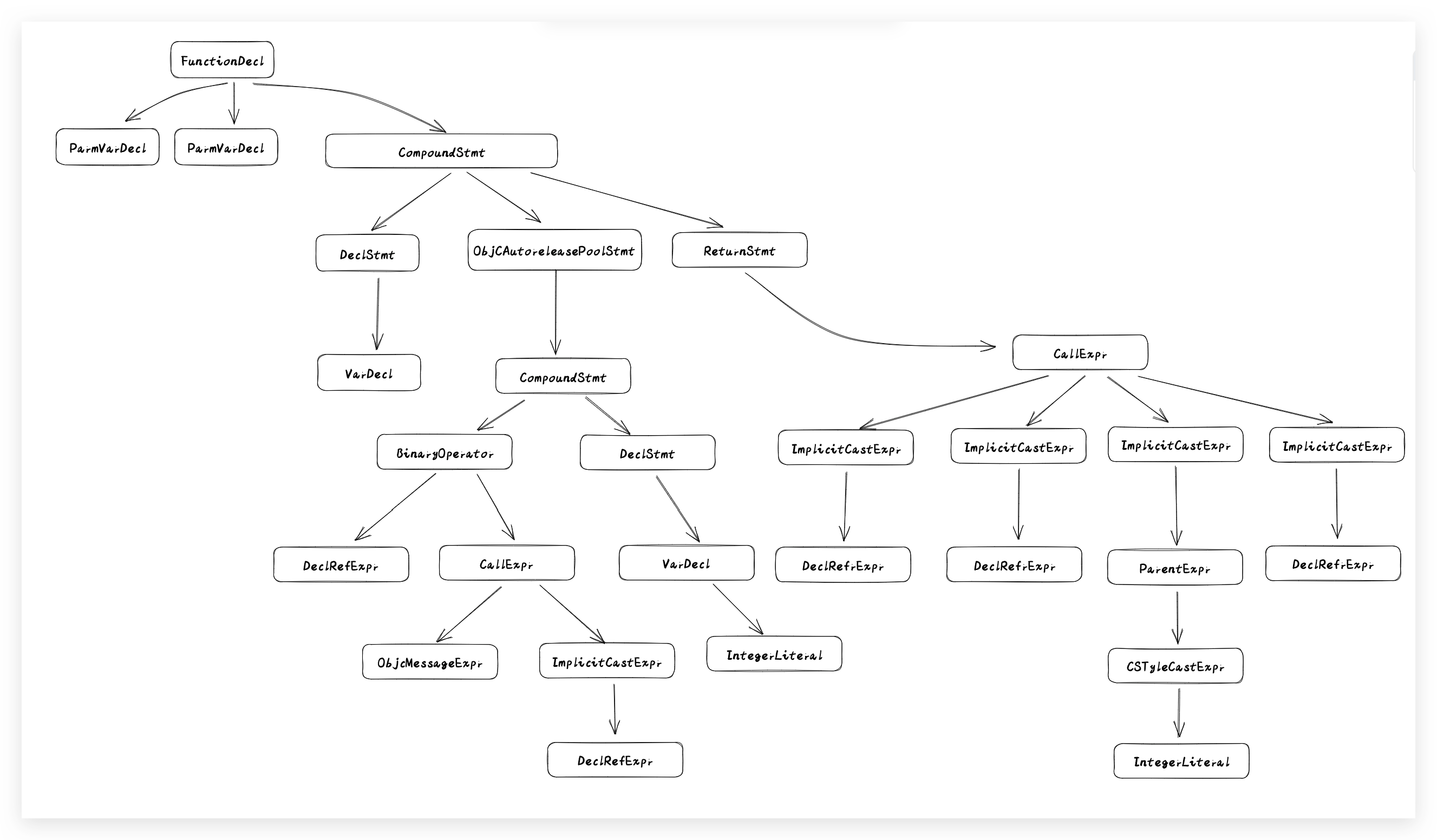
可以发现,经历过语法分析之后,源代码转换成了具体的数据结构,而数据结构的整体生成是后续进行语义分析生成中间代码的基础前提。
在经历过语法分析之后,编译器会对语法分析之后生成的抽象语法树(AST)再次进行处理,需要注意的是编译器并不会直接通过AST编译成目标代码,主要原因是因为编译器将编译过程拆分了前后端,而前后端的通信的媒介就是IR,没错就是之前提到过的LLVMIR这样一个中间产物。该中间产物与语言无关,同时与cpu的架构也无关,那么为什么要加上中间产物这个环节,直接生成目标代码难道不是更好吗?
我们都知道cpu的不同架构直接影响cpu的指令集,不同的指令集对应不同的汇编指令,所以针对于不同的cpu架构要对应生成不同适配的汇编指令才能正常的运行到不同的cpu架构的机器上。如果将前后端的编译过程绑定死,那么就会导致每增加一个新的编译前端,同时增加对所有cpu架构的后端的支持(1对n的关系),同理,如果增加新的一个cpu架构支持,编译前端也需要通通再实现一遍,这个工作量是很重复以及繁琐的。所以为了避免这样的问题,Apple对编译器的前后端进行了拆分,用中间产物来进行前后端的逻辑适配。
对于语义分析生成中间产物的过程,也可以通过 Clang 的编译命令查看,具体如下:
# 生成扩展为.ll的便于阅读的文本格式clang \-isysroot \/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \-S \-emit-llvm \main.m \-o \main.ll# 生成二进制格式,扩展为.bcclang \-isysroot \/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \-emit-llvm \-c \main.m \-o \main.bc编译后生成的内容如下:
; ModuleID = 'main.m'source_filename = "main.m"target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"target triple = "x86_64-apple-ios16.2.0-simulator"%0 = type opaque%struct._class_t = type { %struct._class_t*, %struct._class_t*, %struct._objc_cache*, i8* (i8*, i8*)**, %struct._class_ro_t* }%struct._objc_cache = type opaque%struct._class_ro_t = type { i32, i32, i32, i8*, i8*, %struct.__method_list_t*, %struct._objc_protocol_list*, %struct._ivar_list_t*, i8*, %struct._prop_list_t* }%struct.__method_list_t = type { i32, i32, [0 x %struct._objc_method] }%struct._objc_method = type { i8*, i8*, i8* }%struct._objc_protocol_list = type { i64, [0 x %struct._protocol_t*] }%struct._protocol_t = type { i8*, i8*, %struct._objc_protocol_list*, %struct.__method_list_t*, %struct.__method_list_t*, %struct.__method_list_t*, %struct.__method_list_t*, %struct._prop_list_t*, i32, i32, i8**, i8*, %struct._prop_list_t* }%struct._ivar_list_t = type { i32, i32, [0 x %struct._ivar_t] }%struct._ivar_t = type { i64*, i8*, i8*, i32, i32 }%struct._prop_list_t = type { i32, i32, [0 x %struct._prop_t] }%struct._prop_t = type { i8*, i8* }@"OBJC_CLASS_$_AppDelegate" = external global %struct._class_t@"OBJC_CLASSLIST_REFERENCES_$_" = internal global %struct._class_t* @"OBJC_CLASS_$_AppDelegate", section "__DATA,__objc_classrefs,regular,no_dead_strip", align 8@llvm.compiler.used = appending global [1 x i8*] [i8* bitcast (%struct._class_t** @"OBJC_CLASSLIST_REFERENCES_$_" to i8*)], section "llvm.metadata"; Function Attrs: noinline optnone ssp uwtabledefine i32 @main(i32 %0, i8** %1) #0 { %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i8**, align 8 %6 = alloca %0*, align 8 %7 = alloca i32, align 4 store i32 0, i32* %3, align 4 store i32 %0, i32* %4, align 4 store i8** %1, i8*** %5, align 8 %8 = call i8* @llvm.objc.autoreleasePoolPush() #1 %9 = load %struct._class_t*, %struct._class_t** @"OBJC_CLASSLIST_REFERENCES_$_", align 8 %10 = bitcast %struct._class_t* %9 to i8* %11 = call i8* @objc_opt_class(i8* %10) %12 = call %0* @NSStringFromClass(i8* %11) store %0* %12, %0** %6, align 8 store i32 0, i32* %7, align 4 call void @llvm.objc.autoreleasePoolPop(i8* %8) %13 = load i32, i32* %4, align 4 %14 = load i8**, i8*** %5, align 8 %15 = load %0*, %0** %6, align 8 %16 = call i32 @UIApplicationMain(i32 %13, i8** %14, %0* null, %0* %15) ret i32 %16}; Function Attrs: nounwinddeclare i8* @llvm.objc.autoreleasePoolPush() #1declare %0* @NSStringFromClass(i8*) #2declare i8* @objc_opt_class(i8*); Function Attrs: nounwinddeclare void @llvm.objc.autoreleasePoolPop(i8*) #1declare i32 @UIApplicationMain(i32, i8**, %0*, %0*) #2attributes #0 = { noinline optnone ssp uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="core2" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+ssse3,+x87" "tune-cpu"="generic" }attributes #1 = { nounwind }attributes #2 = { "frame-pointer"="all" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="core2" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+ssse3,+x87" "tune-cpu"="generic" }!llvm.module.flags = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10, !11}!llvm.ident = !{!12}!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 16, i32 2]}!1 = !{i32 1, !"Objective-C Version", i32 2}!2 = !{i32 1, !"Objective-C Image Info Version", i32 0}!3 = !{i32 1, !"Objective-C Image Info Section", !"__DATA,__objc_imageinfo,regular,no_dead_strip"}!4 = !{i32 1, !"Objective-C Garbage Collection", i8 0}!5 = !{i32 1, !"Objective-C Is Simulated", i32 32}!6 = !{i32 1, !"Objective-C Class Properties", i32 64}!7 = !{i32 1, !"Objective-C Enforce ClassRO Pointer Signing", i8 0}!8 = !{i32 1, !"wchar_size", i32 4}!9 = !{i32 7, !"PIC Level", i32 2}!10 = !{i32 7, !"uwtable", i32 1}!11 = !{i32 7, !"frame-pointer", i32 2}!12 = !{!"Apple clang version 13.1.6 (clang-1316.0.21.2.5)"}从编译的产物来看,其中也包含了常见的内存分配、所用到的标识定义等内容,可以明显的发现生成的中间产物已经没有任何源代码语言的影子了。同时我们会发现针对于中间代码,寄存器(%+数字)的使用好像没有个数限制,为什么呢?因为中间代码只是将源代码进行了中间代码的描述转义,此时并没有相关的目标架构信息可供参考使用,所以针对于变量的引用也仅仅是中间层的标识。在后端编译的过程中会将中间的这些寄存器的引用再次进行指令的转换,最终会生成对应CPU架构指令集的汇编代码。
还记得XCode中的BitCode开关选项吗?它决定了编译生成的中间产物IR是否需要保存,如果保存的话,会把当前的中间产物插入到可执行文件的数据段中,保留这些中间产物内容又有什么作用呢?
我们知道在没有保留中间产物之前,为了确保所有cpu架构的机型能够正常安装打出的安装包,在打包的时候会把能够支持的所有cpu架构的集合进行合并打包,生成一个Fat Binary,确保安装包能够适配所有的机型,这样会有一个问题,比如ARM64架构的机器在安装的时候只需要ARM64的架构二进制文件即可,但是由于安装包里兼容了所有的cpu架构,其他的架构代码实际上根本没有用到,这也就间接的导致了安装包的体积变大。
而苹果在应用分发的时候,是知道目标机器的cpu架构的,所以如果能够将中间的编译产物交给AppStore后台,由Appstore后台通过编译后端优化生成目标机器的二进制可执行文件,去除无用的兼容架构代码,进而缩减安装包的体积大小。这也即是BitCode的出现目的,为了解决编译架构冗余的问题,同时也为APP的瘦身提供参考。
编译器在进行语义分析期间还有一个重要的过程叫做静态分析(Static Analysis),llvm官方文档是这样介绍静态分析的:
The term "static analysis" is conflated, but here we use it to mean a collection of algorithms and techniques used to analyze source code in order to automatically find bugs. The idea is similar in spirit to compiler warnings (which can be useful for finding coding errors) but to take that idea a step further and find bugs that are traditionally found using run-time debugging techniques such as testing.↳
Static analysis bug-finding tools have evolved over the last several decades from basic syntactic checkers to those that find deep bugs by reasoning about the semantics of code. The goal of the Clang Static Analyzer is to provide a industrial-quality static analysis framework for analyzing C, C++, and Objective-C programs that is freely available, extensible, and has a high quality of implementation.
静态分析它能够帮助我们在编译期间自动查找错误,比起运行时的时候去找出错误要更早一步,可以用于分析 C、C++ 和 Objective-C 程序。编译器通过静态分析依据AST中节点与节点之间的关系,找出有问题的节点并抛出警告错误,达到修改提醒的目的。比如官方文档中介绍的内存泄露的静态分析的案例:
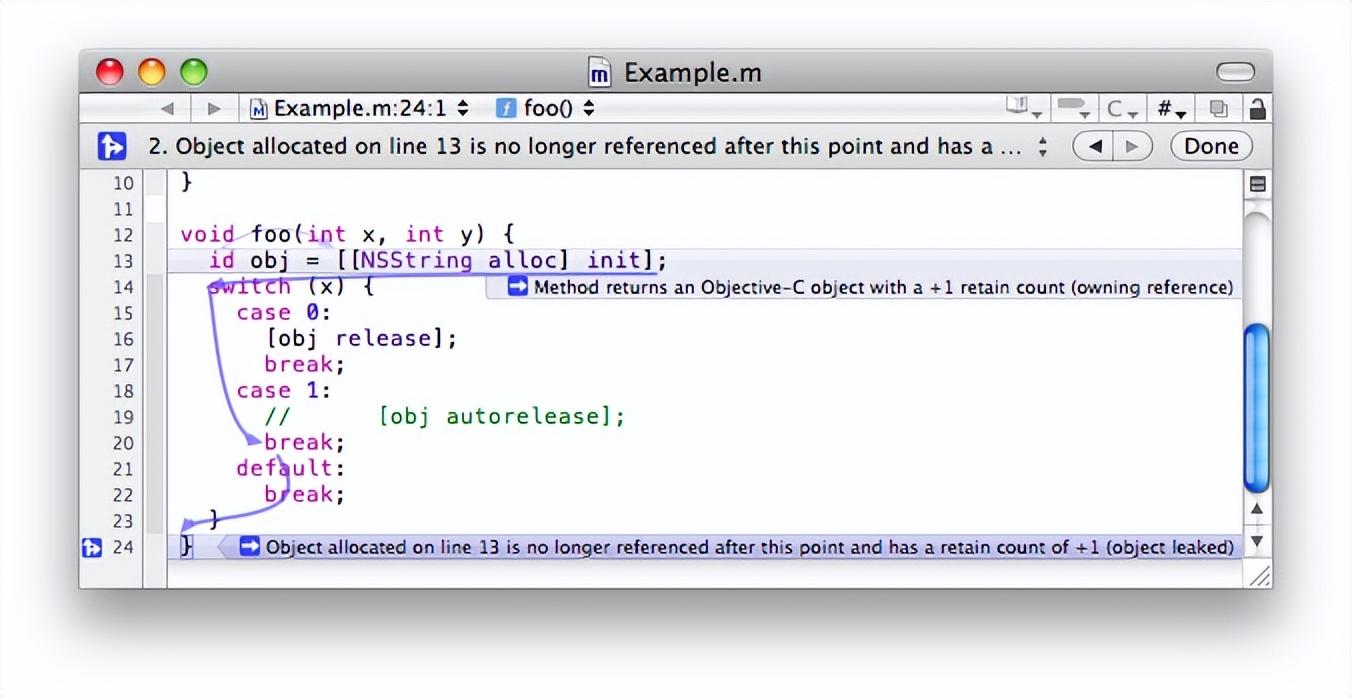
除了官方的静态分析,我们常用的OCLint也是在编译器生成AST抽象语法树之后,对抽象语法树进行遍历分析,达到校验规范的目的,总结一下编译前端的所经历的流程:通过源码输入,对源码进行词法分析将源码进行内容切割生成原子token。通过语法分析对原子token的组合进行语法模板匹配,生成抽象语法树(AST)。通过语义分析,对抽象语法树进行遍历生成中间代码IR与符号表信息内容。
编译器后端主要做了两件重要的事情: 1、优化中间层代码LLVMIR(经历多次的Pass操作) 2、生成汇编代码,最终链接生成机器码
编译器前端完成编译后,生成了相关的编译产物LLVMIR,LLVMIR会经过优化器进行优化,优化的过程会经历一个又一个的Pass操作,什么是Pass呢?引用官方的解释:
The LLVM Pass Framework is an important part of the LLVM system, because LLVM passes are where most of the interesting parts of the compiler exist. Passes perform the transformations and optimizations that make up the compiler, they build the analysis results that are used by these transformations, and they are, above all, a structuring technique for compiler code.
我们可以理解为一个个的中间过程的优化,比如指令选择、指令调度、寄存器的分配等,输入输出也都是IR,如下图:
在最终优化完成之后,会生成一张DAG图给到后端。我们知道DAG是一张有向的非环图,这个特性可以用来标识硬件的特定顺序,方便后端的内容处理。我们也可以根据自己的需要通过继承Pass来写一些自定义的Pass用于自定义的优化,官方对于自定义的Pass也有相关的说明,感兴趣的同学可以去看看(链接放在本文最后了)。在经过优化之后,后端依据不同架构的编译器生成对应的汇编代码,最终通过链接完成机器码的整体生成。
可以发现编译器是计算机高级语言的中梁砥柱,现在随着高级语言的发展越来越迅速,向着简单高效灵活的方向不断前进,这里面与编译器的发展有着密切的联系。同时随着编译器的发展升级,让高级语言到低级语言的转换变得更高效,同时也为诸多的跨平台语言实现提供了诸多可能。通过对计算机底层语言的层层抽象,诞生了我们所熟知的计算机高级语言,让我们能够用人类的思维逻辑进行指令输入,而抽象的层层翻译处理则交给了编译器,它的存在建立了人类与计算机沟通的重要桥梁。
参考:
The Architecture of Open Source Applications: LLVM (aosabook.org)
LLVM Language Reference Manual — LLVM 17.0.0git documentation
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号