OpenAI在中国停服背后的故事与挑战
发表时间: 2024-07-01 15:50
最近,OpenAI宣布对中国“停服”,这一决策无疑在中国AI产业中激起了千层浪。是技术封锁的“毒药”,还是自主创新的“助攻”?这一事件不仅引起了国内开发者的广泛关注,也成为业界讨论的焦点。本文将深入探讨OpenAI此举背后的多重因素,以及它对中国大模型产业的深远影响,带你一窥这场科技领域的新变局。

“Open AI”变“Close AI”了?
6月25日,不少中国的开发者都收到了来自Open AI的电子邮件,其中提到“您的组织正在从Open AI不支持的地区获取API(应用程序编程接口)流量”;而从7月9日起,Open AI将采取额外措施中断对非支持国家和地区的服务。
Open AI官网显示,其目前有188个支持的国家和地区,中国内地和香港并不在其中,而非支持地区尝试接入Open AI的API服务可能面临被封号的风险。
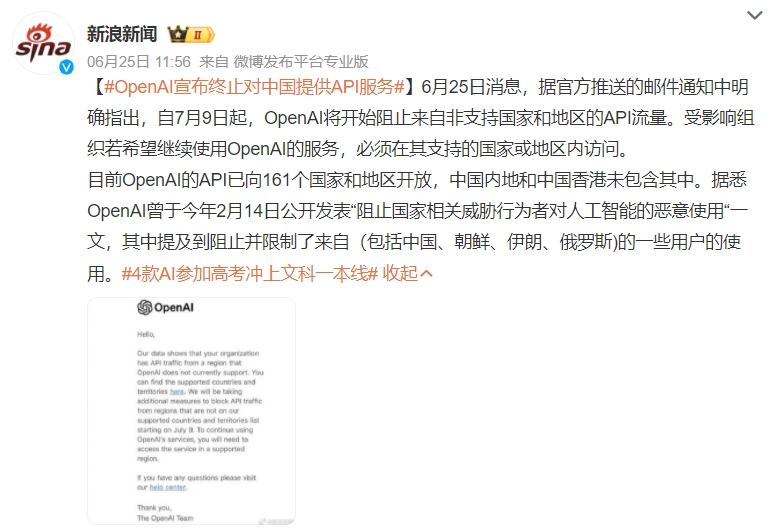
图源:微博截图
Open AI这次行动背后,是美国在近期已经多次对国内科技领域“发难”。仅5月,美国就宣布撤销高通和英特尔对华为出口许可,并将37家中国实体列入出口管制“清单”。
这次封锁,会对中国正在飞速发展的大模型产业,产生怎样的影响?
事实上,Open AI的“停服”早有预兆。
2月14日,Open AI曾发表声明,称阻止并限制了5个“国家相关威胁行为者”对AI的恶意使用,这5名用户分别来自中国(2名)、伊朗、俄罗斯和朝鲜。
6月13日,Open AI任命退役的美国陆军将军、前网络司令部司令和国家安全局(NSA)局长保罗·中曾根为其董事会成员。这名新董事被认为可以帮助Open AI“更好地了解如何利用人工智能快速发现和应对网络安全威胁”。
6月22日,美国还发布一份规则草案,其中提到要禁止或限制中国在AI和其他技术领域的投资。
在此基础上,此次Open AI的声明其实是进一步加强对国内开发者的限制。
据“趣解商业”了解,目前国内使用Open AI的技术有两种主流渠道:一是对接Open AI官方提供的API;二是对接微软智能云Azure提供的Open AI技术。
需要注意的是,Open AI之前允许对接API的地区不包括中国,因此第一种渠道本就是不合规的。采用此种方式的用户,多会通过“科技与狠活”,用国外的代理地址,绕过地理限制访问Open AI的API,借此进行产品测试和开发。
由于此次收到邮件的开发者,有不少都是这种渠道的践行者,因此存在Open AI已经能通过技术手段检测出“科技与狠活”的可能性。通过虚拟地址在国内对接API这条路可能已经被堵上,只是Open AI检测方式的稳定性和精确性有待验证。
而第二种渠道,原本是在国内合规使用ChatGPT的唯一方式,目前看来也难逃限制,只是微软没有把路完全堵死。据“财联社”报道,微软会在香港继续提供Azure Open AI服务。
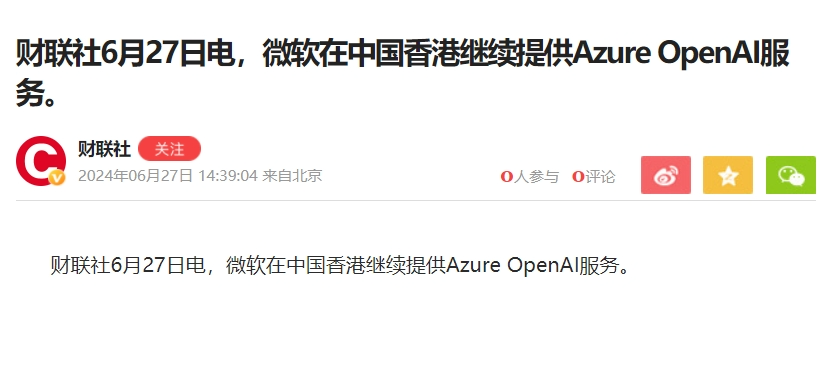
图源:凤凰网截图
可以说,Open AI此次战略的调整,有对数据安全、合规性、运营成本、风险防控等多重压力的考虑。
深度科技研究院院长张孝荣认为,Open AI此时向国内发难,明面上可能受到美国政府对华政策的影响,需要合规;实际上,该公司已经“变质”,从商业公司变成国家工具。公司董事会刚刚引入了NSA前局长,同时坚持科研发展路线的CTO伊利亚已经辞职,一直要对Open AI发起诉讼的马斯克也因此不再发声。
对于Open AI“停服”的影响,国内大模型行业表示影响相对不大。
360创始人、董事长周鸿祎就发视频表示,OpenAI的关停服务,压制不住中国大模型的发展。“这对企业应用和创业者没有影响,可以自行部署本地大模型。大模型将会逐渐向本地进行迁移,速度更快也更加安全。”
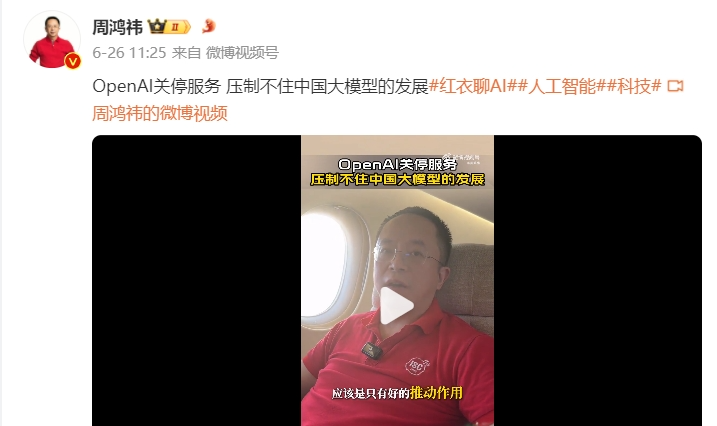
图源:微博截图
据“趣解商业”了解,其他业内人士也表达出了类似的看法。一方面,Open AI本就不向中国境内提供服务,所以很多使用Open AI技术的公司会自行部署海外站点;另一方面,Open AI使用协议里也规定,禁止使用输出开发竞争模型,国内的头部互联网大厂如果长期偷偷使用Open AI接口,首先也是违规的,其次还会限制自身的发展,得不偿失。
2023年末,字节跳动就被曝出在一个名为“种子计划”的AI大模型项目的多个研发阶段,调用了Open AI的API,并使用ChatGPT输出的数据进行模型训练。Open AI还因此封禁了字节跳动名下部分GPT使用权限。
后来字节跳动回应称,只是在探索大模型初期时,有部分工程师曾在较小模型的实验性项目研究中,调用了GPT的API;2023年4月公司内部已经明确要求,不得将GPT模型生成的数据添加到字节大模型的训练数据集;9月公司还进行了内部检查,保证合规。

图源:微博截图
大厂都明白,用Open AI的模型输出,只会一直活在其阴影里。因此,受Open AI“停服”影响的更多是国内没有研发实力、“套壳”ChatGPT、企图通过Open AI的工具训练AI系统和应用程序的企业和人员。
有网友就曾在论坛上分享了自己见到的ChatGPT套壳网站,其用网站流量检查器对该网站进行分析,发现其每月可创造2.1万美元的收入。盈利的方式主要通过广告、用户捐赠,甚至用户付费还可享受额外功能。
该网站可以完美充当ChatGPT的替代品,无需注册或登陆,用户即可实现写作或其他需求。
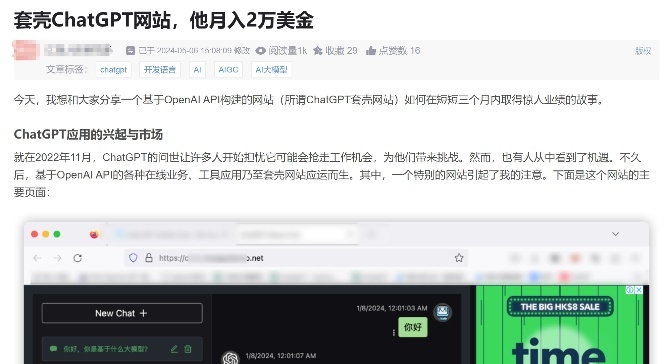
图源:论坛截图
此外,上海市场监管部门也曾查办一起ChatGPT商业混淆案。专家分析称,“套壳AI”主要有两种模式,一种是通过接入官方平台,以中转站形式给用户当“二传手”;另一种则完全使用山寨平台,靠与ChatGPT相似的名称、标识伪装自己。
张孝荣表示,对于一些新兴的大模型公司,特别是那些通过简单套壳或完全依赖Open AI提供的API接口构建产品和服务的公司,有可能要面临业务中断,甚至直接退市的风险。
在张孝荣看来,这些依赖Open AI API进行项目开发和创新的中国企业和开发者,可能需要转换技术底座,但也会因此增加研发成本和时间成本;转换后的服务效果可能会打折,因为国内模型在外文领域的理解能力可能不如Open AI。
总的来看,“停服”影响比较有限,国内相关创业公司不会因此大面积倒闭,短期内也不会突然爆发出现“超车”的可能。
据“趣解商业”了解,目前包括阿里、百度、腾讯、百川智能、智谱AI等在内,多家国内头部大模型厂商已经把实现技术底座转换的“搬家计划”喂到了用户嘴边。
例如,智谱AI就表示,会为开发者提供慷慨资源包,外加从Open AI到自家大模型的迁移培训;百度智能云则以“0成本切换”为亮点,推出“故乡的云”大模型普惠计划;AI Infra厂商硅基流动甚至直接把Qwen2-7B、GLM-4-9B、Yi-1.5-9B等顶尖开源大模型都给永久免费了。

图源:微博截图
香港科技大学助理教授、香港生成式人工智能研发中心资深商业拓展经理韩斯睿表示,此次事件短期内会促进国产大模型公司市场占比的提升。
不过,长期来看,国产大模型能否实现对Open AI的完全替代,最终还是要落到模型能力上。
在这方面,国产大模型相较去年确实已经取得了不小的进步。
2023年,百度发布文心大模型4.0时,李彦宏曾表示其综合水平与GPT-4相比已经毫不逊色。
6月27日凌晨,全球著名开源平台huggingface(笑脸)的联合创始人兼首席执行官Clem在社交平台宣布,阿里最新开源的Qwen2-72B指令微调版本,成为开源模型排行榜第一名。而这份榜单上,囊括了全球100多个主流开源大模型。
具体而言,在模型中文能力方面,很多国产模型表现得比OpenAI更好。
《每日经济新闻》联合了30余位优秀记者、编辑、工程师,历时2个月对市场中主流大模型在财经新闻工作场景中的表现进行的测评显示,李开复带队孵化的零一万物Yi-Large在“财经新闻标题创作”“微博新闻写作”“文章差错校对”“财务数据计算与分析”四大应用场景的总分排名第一,而ChatGPT 4.0表现不佳,甚至在“财经新闻标题创作”场景中排名垫底。
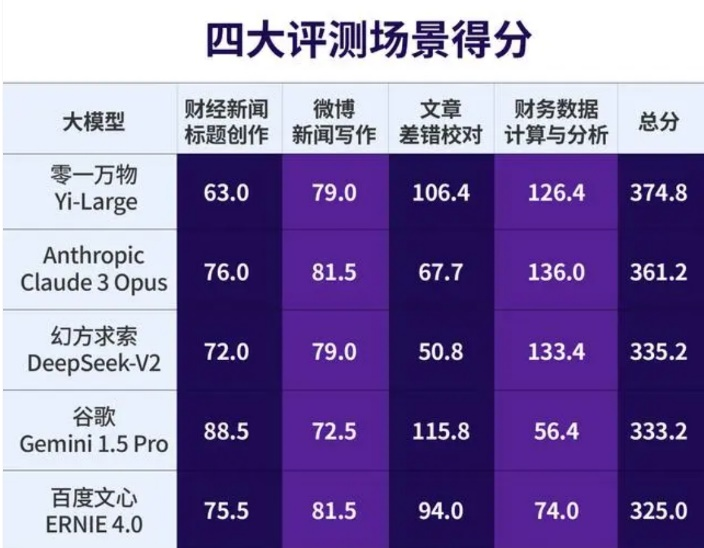
图源:每日经济新闻
另外,在价格上,国产大模型也更为实惠。此次阿里的免费迁移计划中,qwen-plus大模型的API定价仅是OpenAI的1/50。
但客观来看,韩斯睿也坦言,OpenAI的模型能力在文本模型中的复杂文档解析、复杂文档生成等高级任务方面能力仍较为领先,这些复杂模型能力的需求并不会在短期内因为API停止服务而有很大改变。
美国大模型本就起步更早。2023年5月,美国10亿级参数规模以上的基础大模型就已突破100个;除了广为人知的ChatGPT外,美国具有代表性的通用大模型公司还包括Anthropic、Cohere以及Google等。
其中,Anthropic一度被称为“OpenAI劲敌”。根据其释放出的榜单显示,自己最新发布的AI大模型Claude 3.5 Sonnet在研究生水平推理、编码能力、文本推理等方面的成绩均好于不久前红极一时的GPT-4o。

图源:微博截图
北京市社会科学院研究员王鹏认为,中美大模型的差别主要体现在融资水平、基础大模型发展水平和应用层发展水平三个方面。
根据dealroom.co数据,截至2023年7月10日,全球生成式AI企业融资额达150亿美元,其中有89%都流向了美国的初创公司。
而在基础大模型发展水平方面,国内大模型还存在数据总量缺乏、算力资源缺乏、场景渗透率有限等问题。毕竟从公开数据量上看,英文数据本身占主导优势,美国还在采取多种方式限制中国获取算力的核心资源。
至于应用层方面,中国同样处于跟随状态;其中在办公、金融及医疗领域落后美国较为明显。
这让外界对国内大模型产生了一些担忧。“彭博新闻社”在一篇报道中提到,新加坡Dorje AI公司CEO梁忠伟表示,他担心Meta旗下的Llama等开源大模型也可能会切断中国开发者的访问权限,这将带来更大的不确定性。
而不容忽视的是,中国有着超大的市场规模以及丰富的应用场景,为大模型的落地应用提供了广阔的空间和条件;而且越多的数据、场景,越能让大模型更实用。这让中国在底层研发技术上略逊于美国的情况下,依然具备赶超美国的机会。
但在赶超的过程中,会遇到越来越多的障碍,这对国内厂商而言可能是个确定的趋势,也是挑战。
作者 | 张凯旌,编辑 | 趣解商业科技组
本文由人人都是产品经理作者【趣解商业】,微信公众号:【趣解商业】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号