Python 2020版数据清理的终极指南
发表时间: 2020-03-09 20:57

作者 | Lianne & Justin
译者 | 陆离
出品 | AI科技大本营(ID:rgznai100)
一般来说,我们在拟合一个机器学习模型或是统计模型之前,总是要进行数据清理的工作。因为没有一个模型能用一些杂乱无章的数据来产生对项目有意义的结果。
数据清理或清除是指从一个记录集、表或是数据库中检测和修改(或删除)损坏或不准确的数据记录的过程,它用于识别数据中不完整的、不正确的、不准确的或者与项目本身不相关的部分,然后对这些无效的数据进行替换、修改或者删除等操作。
这是个很长的定义,不过描述的较为简单,容易理解。
为了简便起见,我们在Python中新创建了一个完整的、分步的指南,你将从中学习到如何进行数据查找和清理的一些方法:
缺失的数据;
不规则的数据(异常值);
不必要的数据——重复数据等;
不一致的数据——字母大小写、地址等。
在本文中,我们将使用Kaggle提供的俄罗斯房地产数据集(
https://www.kaggle.com/c/sberbank-russian-housing-market/overview/description),目标是要预测一下俄罗斯近期的房价波动。我们不会去清理整个数据集,因为本文只是会用到其中的一部分示例。
在对数据集开始进行清理工作之前,让我们先简单地看一下里面的数据。
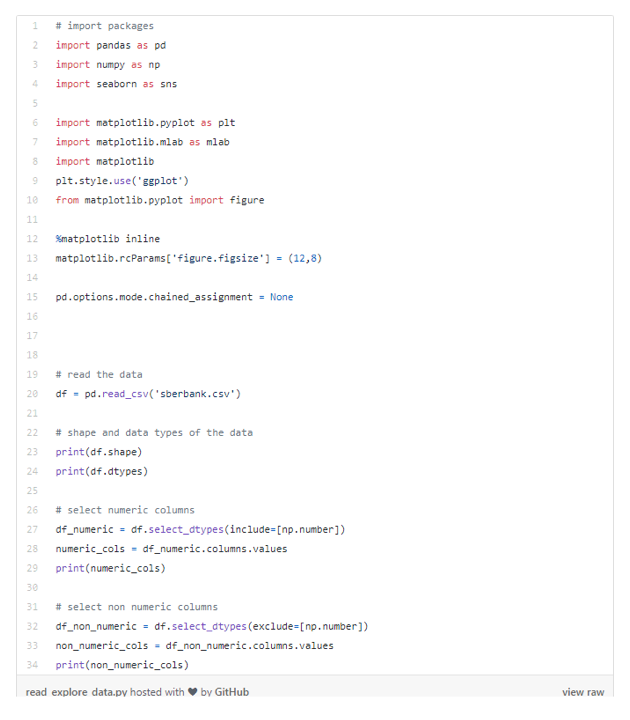
从上述的结果中,我们了解到这个数据集总共有30471行和292列,还确定了特征是数值变量还是分类变量,这些对我们来说都是有用的信息。
现在可以查看一下“dirty”数据类型的列表,然后逐个进行修复。
让我们马上开始。

缺失的数据
处理缺失的数据是数据清理中最棘手但也是最常见的一种情况。虽然许多模型可以适应各种各样的情况,但大多数模型都不接受数据的缺失。
如何发现缺失的数据?
我们将为你介绍三种技术,可以进一步了解在数据集中的缺失数据。
1、缺失数据的热图
当特征数量较少的时候,我们可以通过热图来进行缺失数据的可视化工作。
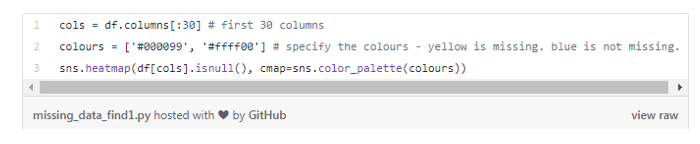
下图显示了前30个特征的缺失数据样本。横轴表示特征的名称;纵轴显示观测的数量以及行数;黄色表示缺失的数据,而其它的部分则用蓝色来表示。
例如,我们看到特征life_sq在许多行中是有缺失值的。而特征floor在第7000行附近几乎就没有什么缺失值。
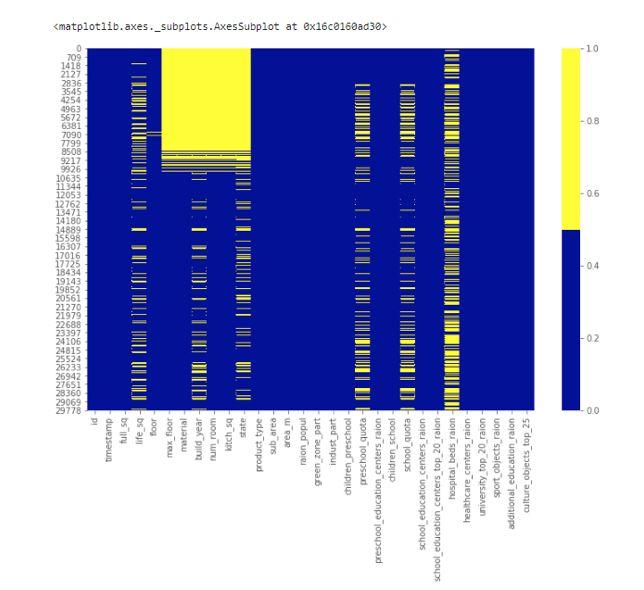
缺失数据热图
2、缺失数据的百分比列表
当在数据集中有足够多的特征时,我们可以为每个特征列出缺失数据的百分比。
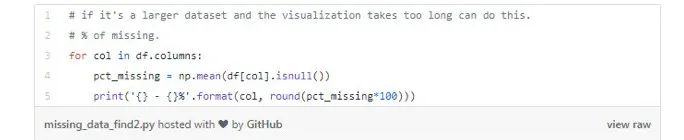
这将在下面形成一个列表,用来显示每个特征的缺失值的百分比。
具体来说,我们看到特征life_sq缺失了21%的数据,特征floor则只缺失了1%。这个列表是一个较为有用的汇总,根据它就可以补充热图可视化了。

缺失数据的百分比列表——前30个特征
3、缺失数据的直方图
当我们有足够多特征的时候,缺失数据的直方图也是一种技术。
为了了解更多关于观测数据的缺失值样本的信息,我们可以使用直方图来对它进行可视化操作。
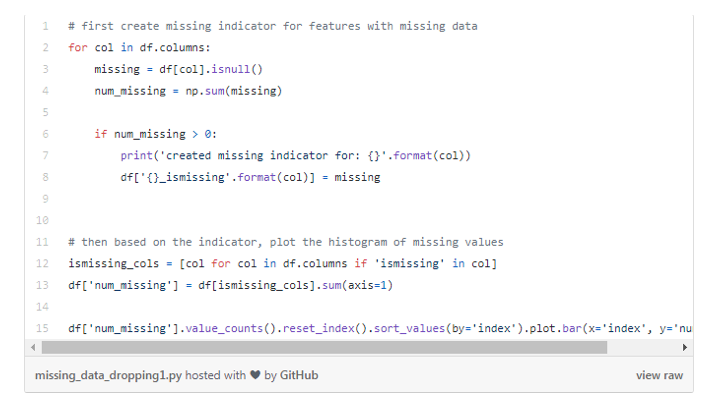
这个直方图有助于识别30471个观测数据中的缺失值情况。
例如,有6000多个没有缺失值的观测数据,而将近4000个观测数据中仅有一个缺失值。
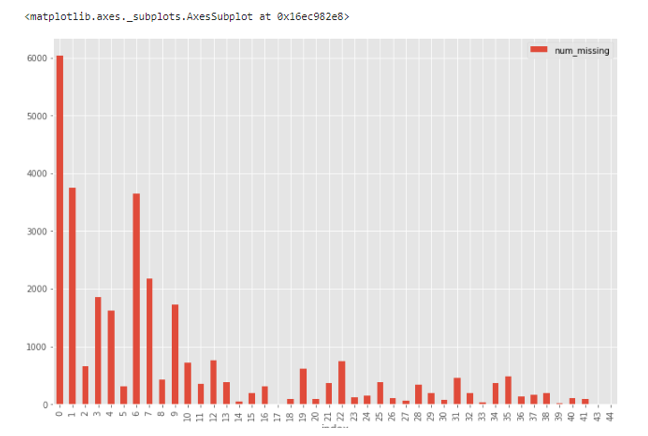
缺失数据直方图
我们应该怎么做?
对于处理缺失的数据,没有任何一致的解决办法。我们必须在研究了特定的特征和数据集之后,来决定处理它们的最佳方式。
在下文中,分别介绍了四种处理缺失数据的常见方法。但是,如果遇到更复杂的情况,我们就需要利用一些相对更加复杂的方法,比如缺失数据建模等。
1、放弃观察
在统计学中,这种方法被称为列表删除技术。在这个方案中,只要包含了一个缺失值,我们就要删除整条的观测数据。
只有当我们确定所缺失的数据没有提供有用信息的时候,我们才能执行此操作。否则,我们应该考虑使用其它的办法。
当然,也可以使用其它标准来删除观察数据。
例如,从缺失数据的直方图中,我们可以看到总共缺失了至少35个以上的特征观测数据。我们可以创建一个新的数据集df_less_missing_rows,然后删除具有35个以上缺失特征的观测数据。

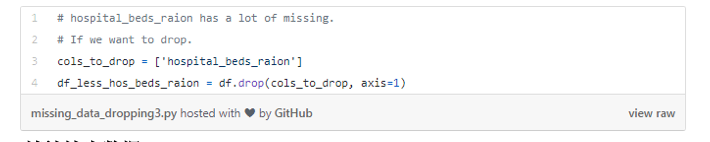
2、删除特征
与方案一比较类似,我们只有在确定当前特征没有提供任何有用信息的时候才能执行这个操作。
例如,从缺失数据百分比的列表中,我们注意到hospital_beds_raion的缺失值百分比高达47%。那么,我们就可以删除整个特征数据了。
3、填补缺失数据
当特征是一个数值变量的时候,可以进行缺失数据的填补。我们会将缺失的值替换为相同特征数据中已有数值的平均值或是中值。
当特征是一个分类变量的时候,我们可以通过模式(最频繁出现的值)来填补缺失的数据。
以life_sq为例,我们可以用它的中值来替换这个特征的缺失值。

此外,我们还可以同时对所有的数字特征使用相同的填补数据的方式。
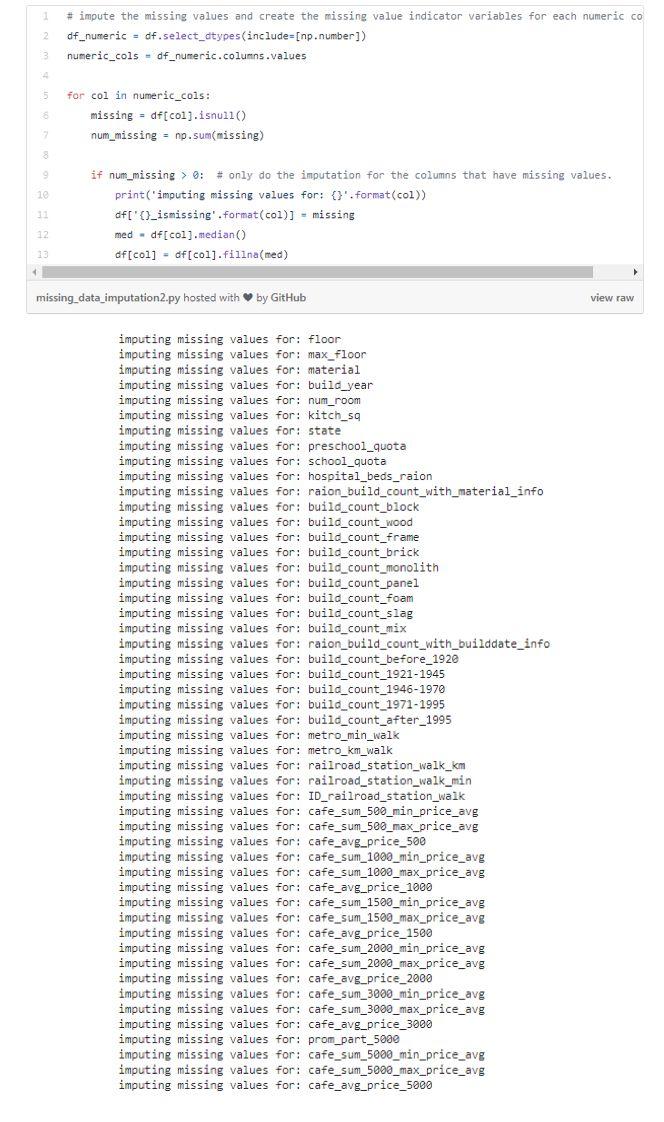
比较幸运的是,我们的数据集中并没有缺失分类特征的值。然而,我们可以对所有的分类特征进行一次性的模式填补操作。
4、替换缺失的数据
对于分类特征,我们可以添加一个类似于“_MISSING_”这样的值,这是一种新类型的值。对于数值特征,我们可以使用-999这样的特殊值来替换它。
这样,我们仍然可以保留缺失值作为有用的信息。

不规则的数据(异常值)
异常值是与其它的观测值截然不同的数据,它们可能是真正的异常值或者是错误值。
如何发现不规则的数据?
根据特征是数值的还是分类的,我们可以使用不同的技术来研究其分布特点用以检测它的异常值。
1、直方图和方框图
当特征是数值的时候,我们可以使用直方图或者是方框图来检测它的异常值。
下面是特征life_sq的直方图。

由于可能存在异常值,因此,数据准确性的差别看起来是异常显著的。
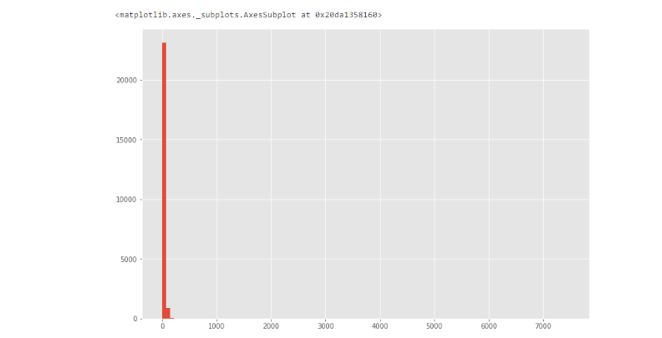
直方图
为了更深入地研究这个特征,下面我们来画一个方框图。

在这个图中,我们可以看到一个超过7000的异常值。

方框图
2、描述性统计数据
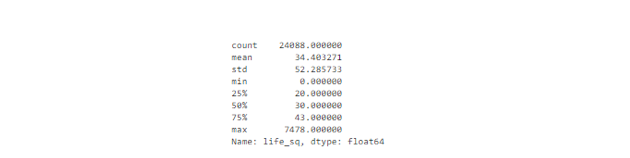
此外,对于数值特征,异常值可能过于明显,以致方框图无法对其进行可视化。相反地,我们可以看看它们的描述性统计数据。
例如,对于特征life_sq,我们可以看到最大值是7478,而75%的四分位数只有43。很明显,7478值是一个异常值。

3、条形图
对于分类特征,我们可以使用条形图来了解特征的类别以及分布的情况。
例如,特征ecology具有合理的分布,但是,如果有一个类别只有一个叫做“other”的值,那么这肯定就是一个异常值。

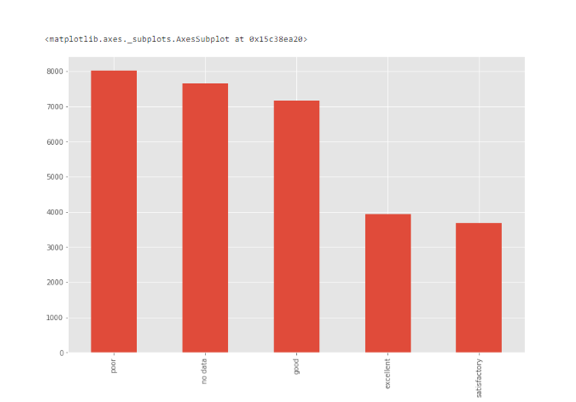
条形图
4、其它的技术
还有许多其它的技术也可以用来发现异常值,例如散点图、z-score和聚类等等,在这里将不会一一进行讲解。
我们应该怎么做?
虽然寻找异常值并不是什么难事,但是我们必须确定正确的解决办法来进行处理。它高度依赖于所使用的数据集和项目的目标。
处理异常值的方法有些类似于缺失数据的操作。我们要么放弃、要么调整、要么保留它们。对于可能的解决方案,我们可以参考本文的缺失数据部分。

不必要的数据
在对缺失数据和异常值进行了所有的努力之后,让我们看看关于不必要的数据,这就更简单了。
首先,所有输入到模型中的数据都应该为项目的目标服务。不必要的数据就是数据没有实际的数值。根据不同的情况,我们主要划分了三种类型的不必要数据。
1、无信息或者重复值
有时,一个特征没有有用的信息,因为太多的行具有相同的值。
如何发现无信息或者重复值?
我们可以创建一个具有相同数值的百分比较高的特征列表。
例如,我们在下面指定显示95%以上的具有相同值的行的特征。
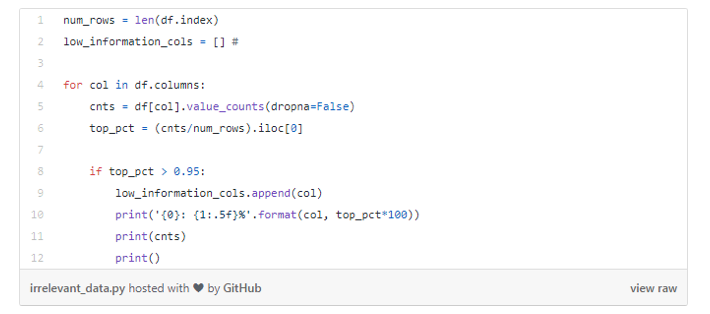
我们可以一个一个地研究这些变量,看看它们是否具有有价值的信息,在这里就不显示细节了。

我们应该怎么做?
我们需要了解重复特征背后的原因,当它们真的缺少有用信息的时候,就可以把它们放弃了。
2、不相关的数据
同样,数据需要为项目提供有用的信息。如果这些特征数据与我们在项目中要解决的问题没什么关系,那么它们就是不相关的。
如何发现不相关的数据?
首先,我们需要浏览一下这些特征,以便之后能识别那些不相关的数据。
例如,一个记录多伦多天气的特征数据并不能为预测俄罗斯房价提供任何有用的信息。
我们应该怎么做?
当这些特征数据并不符合项目的目标时,我们就可以放弃它们了。
3、重复数据
重复数据是指存在多个相同的观测值。
重复数据主要包含两种类型。
(1)基于所有特征的重复数据
如何发现基于所有特征的重复数据?
当观察到的所有特征数据都相同的时候,就会发生这种重复现象,这是很容易发现的。
我们首先要去除数据集中的唯一标识符id,然后通过删除重复数据来创建一个名为df_dedupped的数据集。我们通过比较两个数据集(df和df_deduped),找出有多少个重复行。
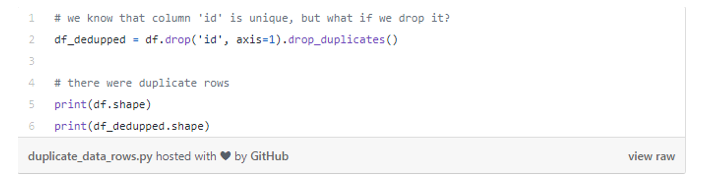
得出,10行是完全重复的观察结果。
我们应该怎么做?
我们应该删除这些重复数据。
(2)基于关键特征的重复数据
如何发现基于关键特征的重复数据?
有时最好根据一组唯一的标识符来删除那些重复的数据。
例如,同一建筑面积、同一价格、同一建筑年份的两个房产交易同时发生的可能性几乎为零。
我们可以设置一组关键特征作为交易的唯一标识符,包括timestamp、 full_sq、life_sq、floor、build_year、num_room、price_doc,我们会检查是否有基于这些标识符的副本(重复记录)。

基于这组关键特征,共有16个副本,也就是重复数据。
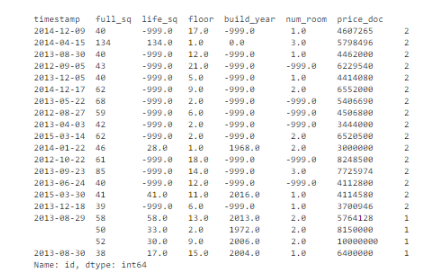
我们应该怎么做?
我们可以根据关键特征删除这些重复数据。
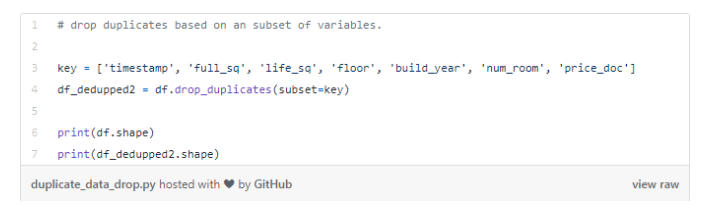
我们在名为df_dedupped2的新数据集中删除了16个重复数据。


不一致的数据
让数据集遵循特定的标准来拟合模型也是至关重要的。我们需要用不同的方法去探索数据,这样就可以找出不一致的数据了。很多时候,这取决于细致的观察和丰富的经验,并没有固定的代码用来运行和修复不一致的数据。
下面我们将介绍四种不一致的数据类型。
1、大小写不一致
在分类值中存在着大小写不一致的情况,这是一个常见的错误。由于Python中的数据分析是区分大小写的,因此这就可能会导致问题的出现。
如何发现大小写不一致?
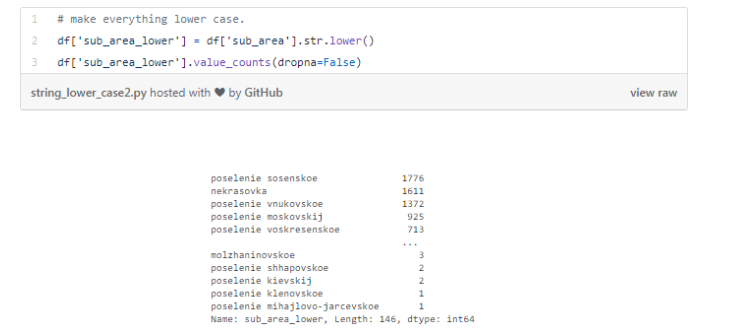
先让我们来看看特征sub_area。

它用来存储不同地区的名称,看起来已经非常的标准化了。

但是,有时候在同一个特征数据中存在着大小写不一致的情况。举个例子,“Poselenie Sosenskoe”和“pOseleNie sosenskeo”就可能指的是同一地区。
我们应该怎么做?
为了避免这种情况的发生,我们要么所有的字母用小写,要么全部用大写。
2、数据格式不一致
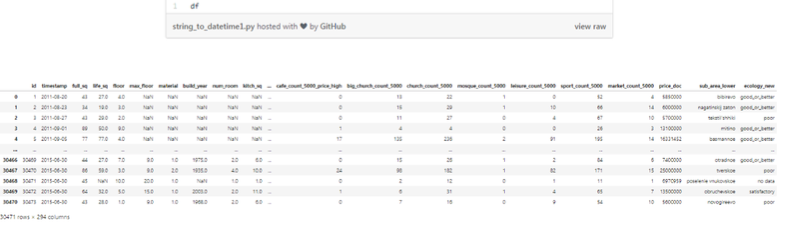
我们需要实行的另一个标准化是数据格式。这里有一个例子,是将特征从字符串(String)格式转换为日期时间(DateTime)格式。
如何发现不一致的数据格式?
特征timestamp是以字符串的格式来表示日期的。
我们应该怎么做?
我们可以使用下面的代码进行转换,并提取出日期或时间的值。之后,会更容易按年或月进行分组的交易量分析。
3、数据的分类值不一致
不一致的分类值是我们要讨论的最后一种不一致数据的类型。分类特征值的数量有限。有时候由于输入错误等原因,可能会存在其它的值。
如何发现不一致的分类值?
我们需要仔细观察一个特征来找出不一致的值,在这里,我们用一个例子来说明一下。
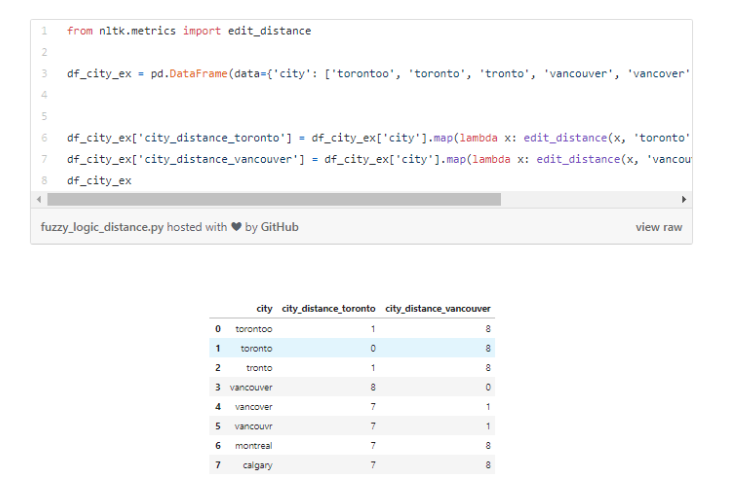
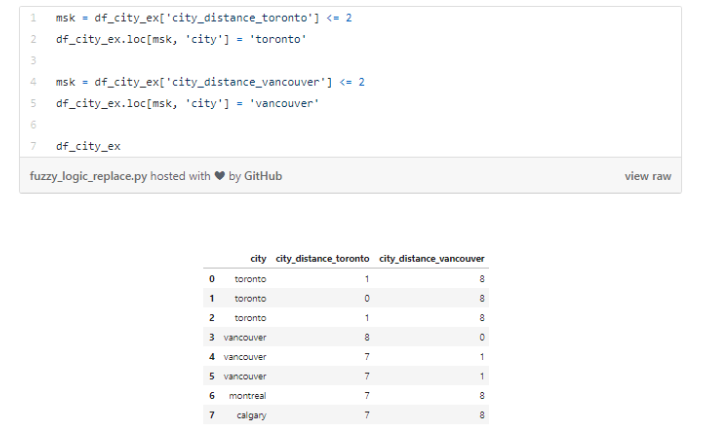
由于我们在房地产数据集中并不存在这样的问题,因此,我们在下面创建了一个新的数据集。例如,特征city的值被错误地定义为“torontoo”和“tronto”。但它们两个都指向了正确的值“toronto”。
一种简单的确认方法是模糊逻辑(或是编辑间隔,edit distance)。它衡量了我们需要更改一个值的拼写用来与另一个值进行匹配的字母差异数量(距离)。
我们知道这些类别应该只有“toronto”、“vancouver”、“montreal”以及“calgary”这四个值。我们计算了所有的值与单词“toronto”(和“vancouver”)之间的距离。可以看到,那些有可能是打字错误的单词与正确的单词之间的距离较小,因为它们之间只差了几个字母而已。
我们应该怎么做?
我们可以设置一个标准将这些错误的拼写转换为正确的值。例如,下面的代码将距离“toronto”2个字母以内的所有值都设置为“toronto”。
4、地址数据不一致
地址特征目前成为了我们许多人最头疼的问题。因为人们经常在不遵循标准格式的情况下,就将数据输入到数据库中了。
如何发现不一致的地址?
我们可以通过查看数据来找到难以处理的地址。即使有时候我们发现不了任何问题,但我们还可以运行代码,对地址数据进行标准化处理。
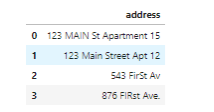
在我们的数据集中没有属于隐私的地址。因此,我们利用特征address创建了一个新的数据集df_add_ex。

正如我们所看到的那样,地址数据可是非常不规范的。
我们应该怎么做?
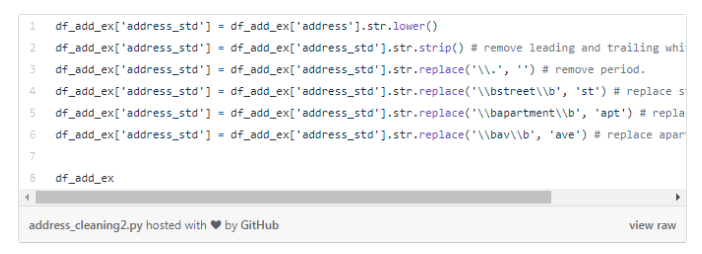
我们运行下面的代码,目的是将字母统一变成小写的、删除空格、删除空行以及进行单词标准化。
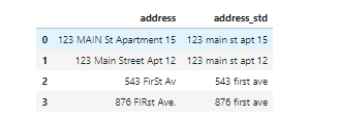
现在看起来好多了。
我们终于完成了,经过了一个很长的过程,清除了那些所有阻碍拟合模型的“dirty”数据。
原文链接:
https://towardsdatascience.com/data-cleaning-in-python-the-ultimate-guide-2020-c63b88bf0a0d
本文为 CSDN 翻译,转载请注明来源出处。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号