开源大模型代码的短板已补齐!新羊驼Python超越ChatGPT,免费商用
发表时间: 2023-08-25 13:30
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
Llama 2系列又上新,这回是Meta官方出品的开源编程大模型Code Llama。
模型一发布,官方直接给贴了个“最强”标签,还强调了一把“免费可商用”。
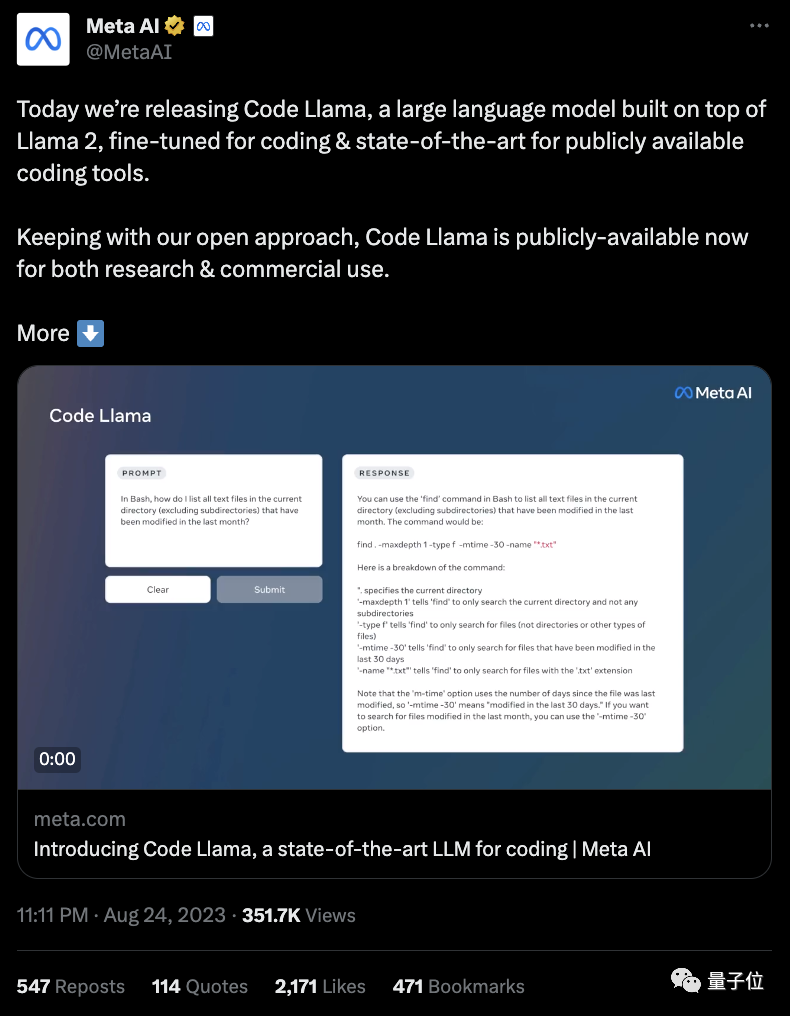
关键是,Code Llama支持10万token上下文,这可把网友们乐坏了:这是一口气读6000行Python代码不费劲的节奏啊。
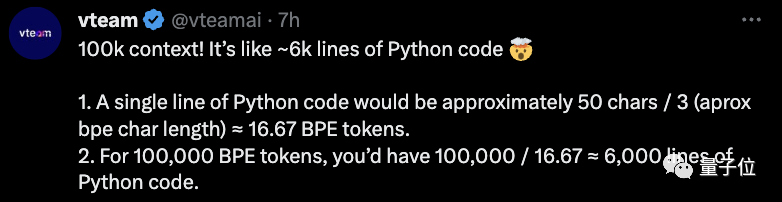
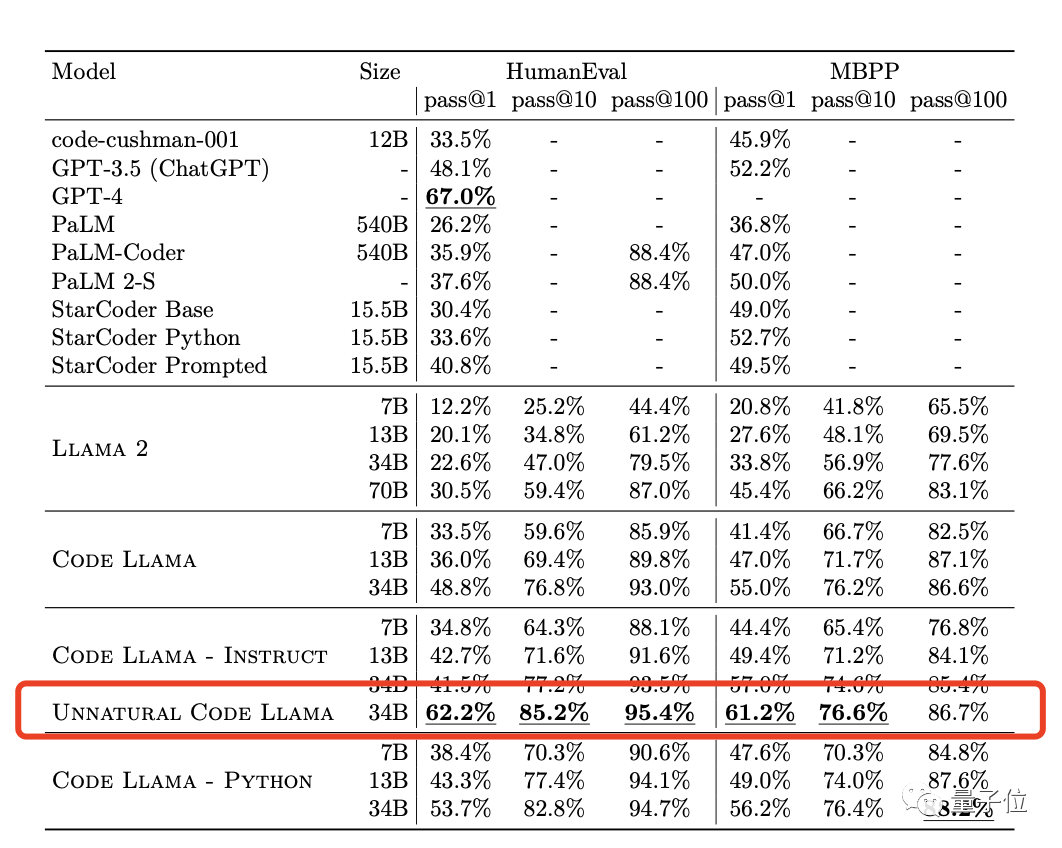
OpenAI创始成员Karpathy也闻讯前来围观,还指出了隐藏在论文中的“华点”:Code Llama没有公布的一个“unnatural”版本,性能已经超过ChatGPT,逼近GPT-4。
具体而言,Code Llama可以说是Llama 2的代码专用版,你既可以通过聊天的方式让它生成代码、解决编程问题,也可以用它来调试代码。
支持的语言包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash等。
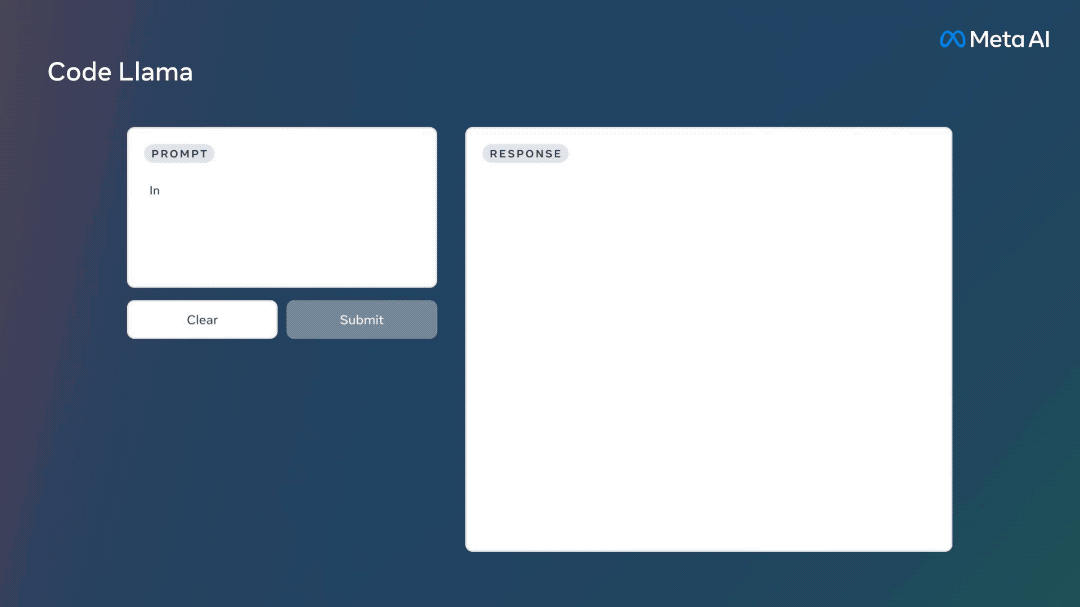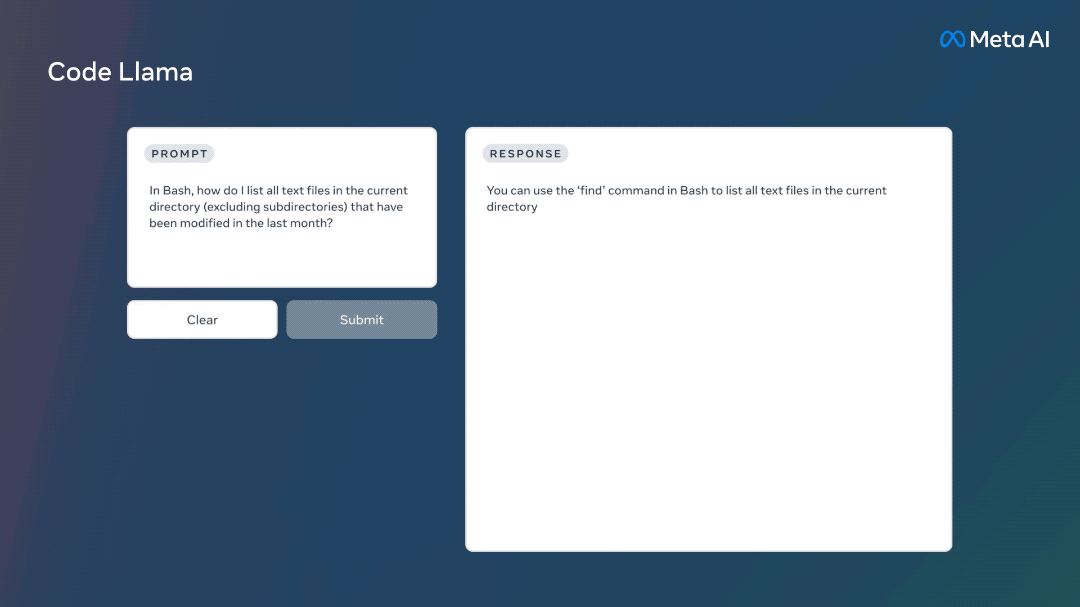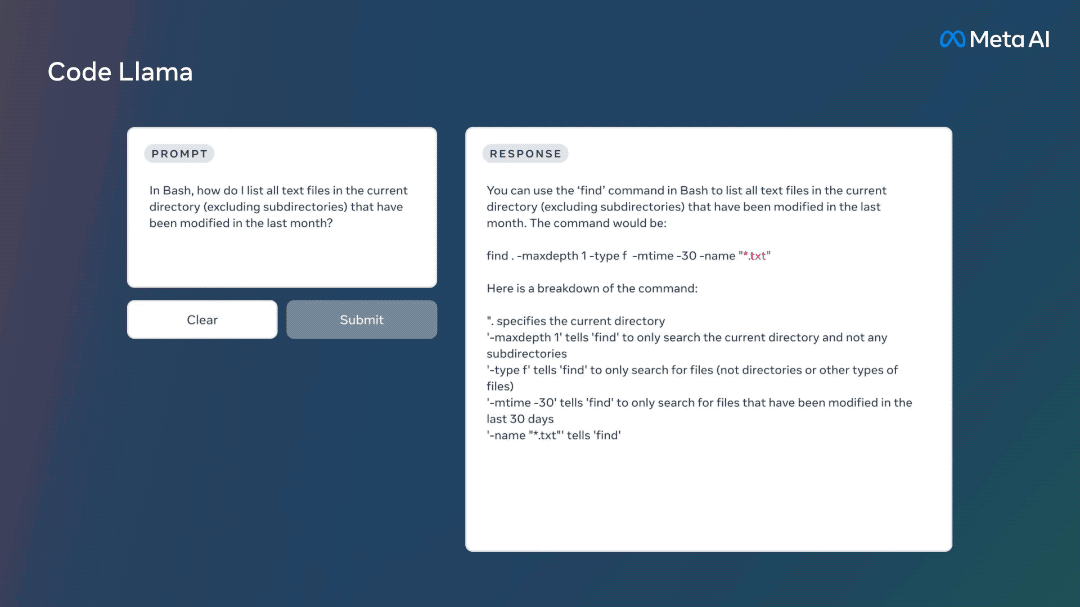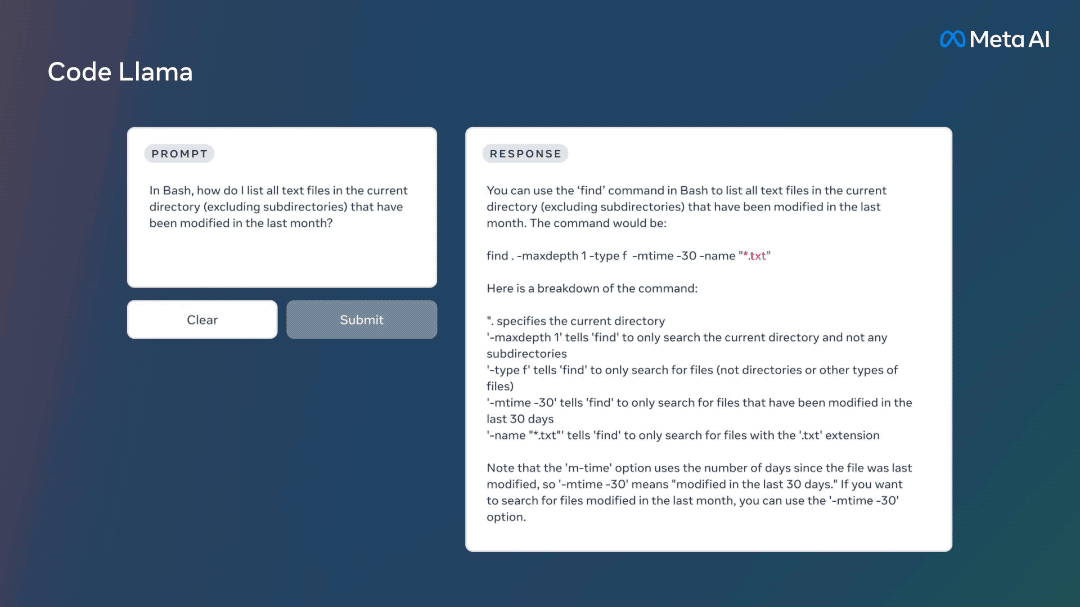
Meta提供了Code Llama的三个不同版本:
其中,Python微调版是在1000亿token的Python代码数据上进行微调的。
而Instruct版则能够更好地理解自然语言提示。
和Llama 2一样,Code Llama的3个版本各有3种不同尺寸的模型可供选择,分别是7B、13B和34B。
每个模型都被喂进了5000亿token的代码及代码相关数据。
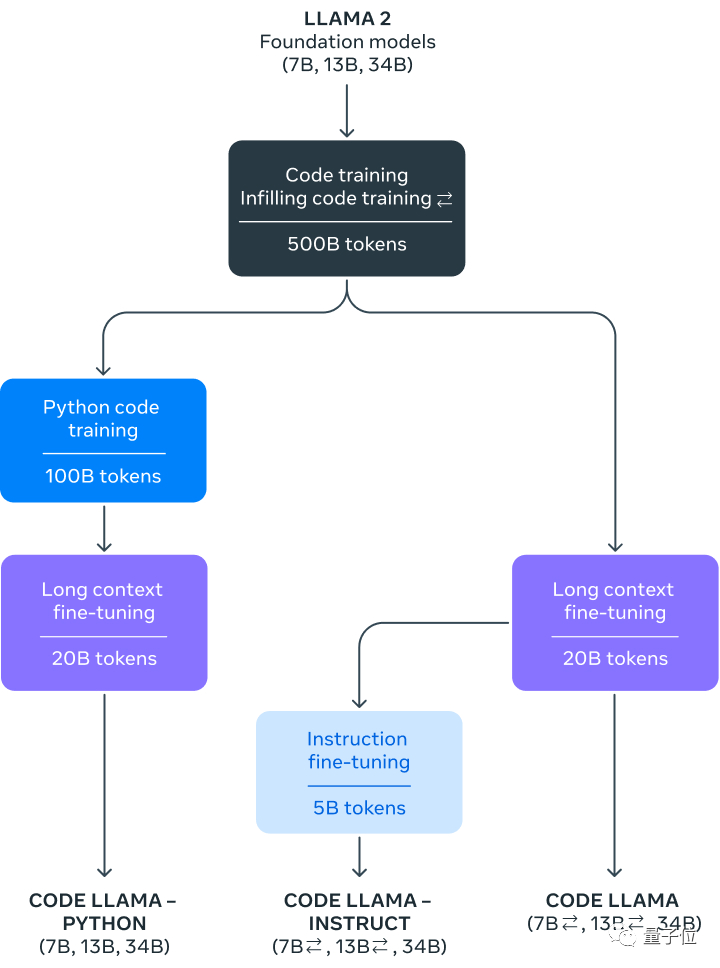
Meta提到,其中7B模型可以在单个GPU上运行。
另外,7B和13B的基础模型和Instruct版模型都有FIM(fill-in-the-middle)功能。也就是说,它们具备代码填充的能力,可以被用到IDE的代码自动补全场景中。

而最受网友关注的一个功能亮点是,Code Llama的全系列模型都进行了长序列上下文微调,最长支持10万token上下文。
这就意味着,你可以把整个代码库直接塞给Code Llama,再也不用担心大模型帮你调代码的时候根本不理解你想要啥。
有网友就提到,目前GPT-4、GitHub Copliot在实际使用中的一大问题,就是上下文窗口太短,理解不了项目的整体需求。

不过,论文提到,当提示长度超过1.6万token时,Code Llama全系列模型的检索准确性(retrieval accuracy)都有所下降。
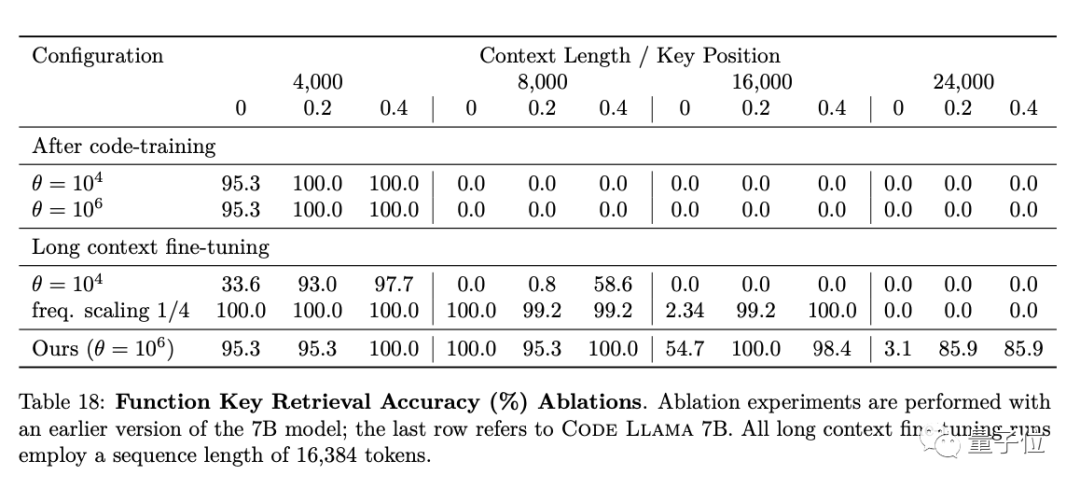
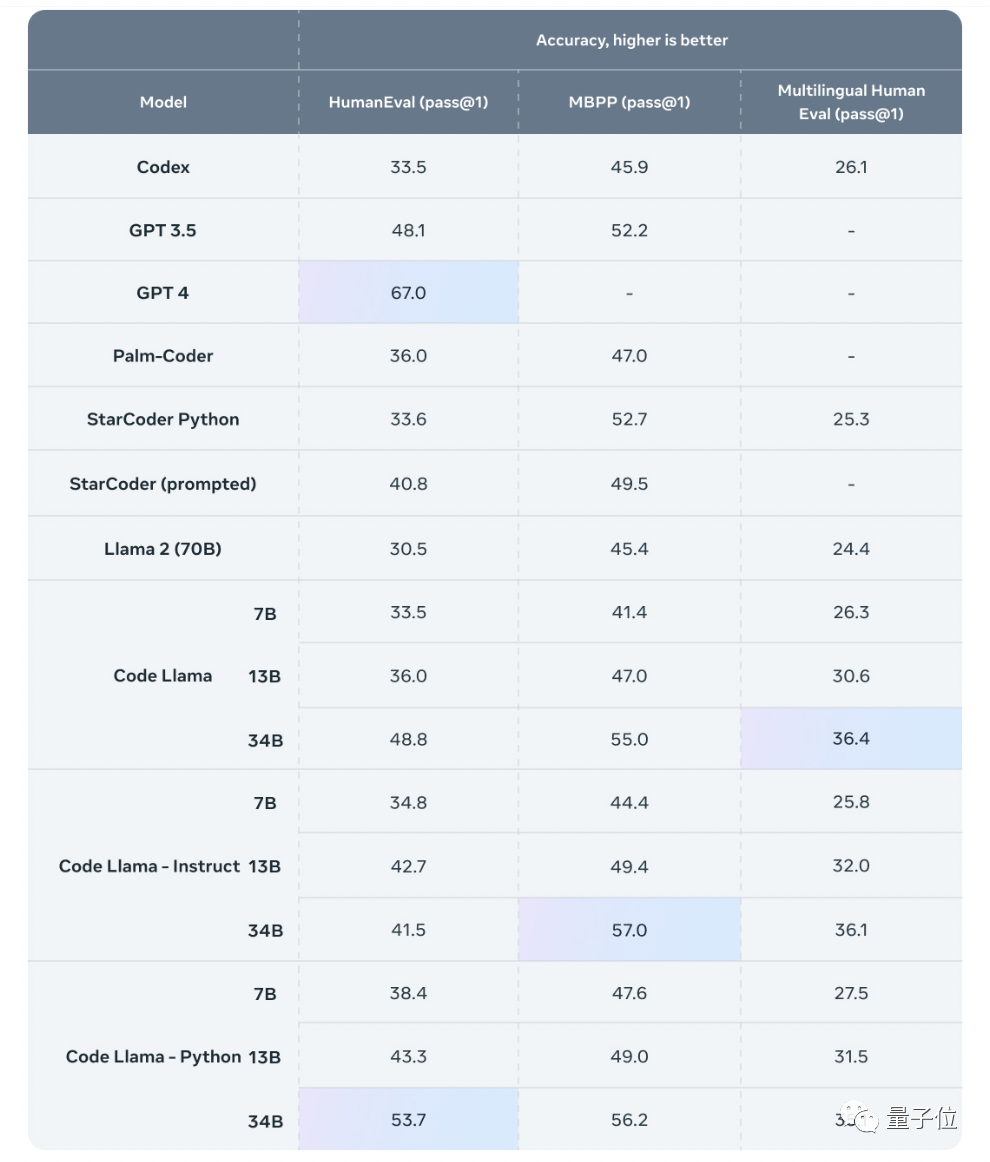
Meta分别在HumanEval和MBPP上测试了Code Llama的性能。
结果显示,Code Llama的表现在一众开源模型中位列第一,超过了Llama 2。
具体来说,Code Llama-Python 34B在HumanEval上得分为53.7%,在MBPP上得分为56.2%,超过了GPT-3.5(ChatGPT)的48.1%和52.2%。
基础模型版本和Instruct版本也有接近GPT-3.5的表现。
值得一提的是,在论文中,Meta还测试了一个“unnatural”34B版本,性能碾压一众模型,包括ChatGPT,仅略逊于GPT-4。
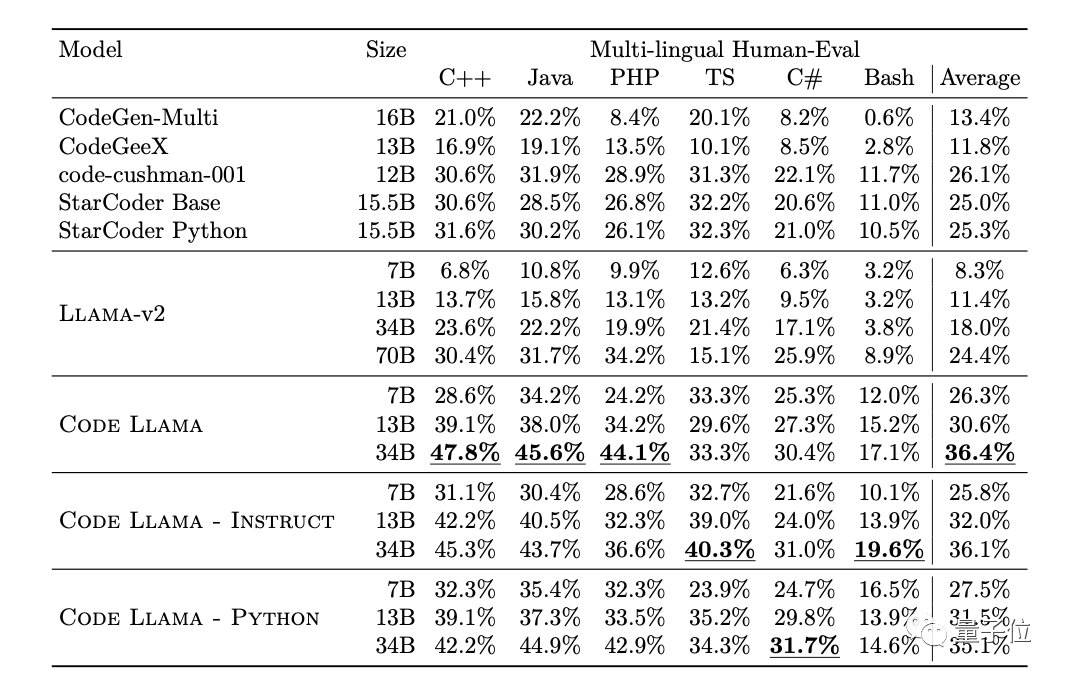
另外,Meta也在更多样化的编程语言数据集上评估了Code Llama的表现。
在任何语言的代码生成中,Code Llama都优于相同大小的Llama 2。从综合得分来看,Code Llama的7B模型甚至超过了Llama 2的70B模型。
同时,Code Llama 7B的表现也超过了CodeGen-Multi和StarCoder等编程大语言模型,水平与Codex相当。
如果你对Code Llama感兴趣,GitHub项目链接文末奉上~
不过,想要获得代码和模型权重,还得先给Meta发个申请。
参考链接:
[1]GitHub项目页:https://github.com/facebookresearch/codellama
[2]https://ai.meta.com/blog/code-llama-large-language-model-coding/
[3]https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号