使用 Serverless Framework 进行人工智能小程序的构建
发表时间: 2020-07-23 19:03
在日常生活中,我们经常会遇到搜索照片的情况,如果是要寻找已经过去很久的照片,并且记忆中仅剩下零散记忆,常用的检索照片的方法是定位到大致的时间,然后一张一张的去查看。但这种做法效率低下,经常还会漏掉目标图片,所以在这种时候,我们很需要一款可以搜索图片的软件,即通过简单的文字描述就能实现图片的快速检索。
近几年微信小程序的发展速度飞快,从张小龙在 2017 微信公开课 Pro 上发布小程序正式上线到目前为止,小程序已经覆盖了超过 200 个细分行业,服务超过 1000 亿人次用户,年交易增长超过 600%,创造超过 5000 亿的商业价值。
本实例将会通过微信小程序,在 Serverless 架构上实现一款基于人工智能的相册小工具,在保证基础相册功能(新建相册、删除相册、上传图片、查看图片、删除图片)的基础上,增加搜索功能,即用户上传图片之后,基于 Image Caption 技术自动对图片进行描述,实现 Image to Text 的过程,当用户进行搜索时,通过文本间的相似度返回给用户最贴近的图片。

该项目设计主要包括登录功能、相册新建、图片上传、相关预览以及搜索功能,整体如图所示。
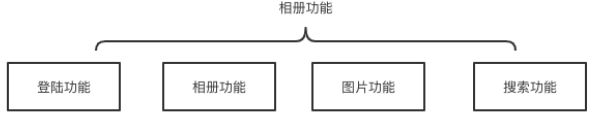
其中注册功能的主要作用是,通过获取用户的唯一 Id(微信中的 OpenId),将用户信息存储到数据库中,之后的所有操作都需要根据该 Id 作为区分。相册功能主要包括相册添加、修改、删除以及查看等。图片功能包括图片上传功能、删除功能、查看功能。搜索功能主要是可以查看指定标签对应的图片列表,以及指定搜索内容对应的列表。当然这四个主要功能和模块是与前端关系紧密的部分,除此之外还有后端异步操作的两个模块,分别是图像压缩功能和图像描述功能。
注册功能主要是用户点击注册账号之后执行的动作。该动作需要注意,用户点击注册账号注册的时候要先判断用户是否已经注册过,如果已经注册过则默认登陆,否则进行注册并登陆。当用户不想注册时,可以点击体验程序,可以对程序大部分页面进行预览。但是不能实现有关数据库的增删改查等功能。
登录功能页面如图所示。

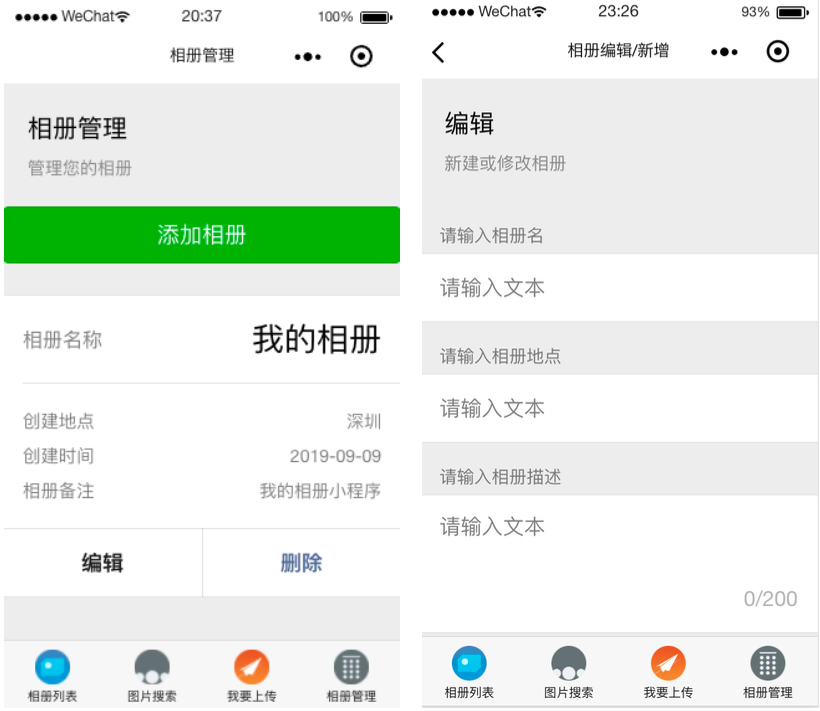
当用户注册登录之后,可以在相册管理页面进行相册相关的管理,包括编辑功能、删除功能以及新建功能,此处在进行添加和修改的时候,需要注意相册名称是否已经存在;在进行删除、修改相册等操作时要判断用户是否有操作该相册的权限等。
下图是相册功能相关原型图。
图片功能主要包括图片列表以及图片获取、图片删除以及图片上传功能,在图片获取与删除的过程中,要对用户是否有该项操作的权限进行判断,图片上传时也要判断用户是否有上传到指定相册的权限。图片功能相关原型图如所示。

图片功能部分除了用户侧可见的功能,还有定时任务,当用户上传图片之后,系统会在后台异步进行图像压缩以及图像的描述、关键词提取等。
整体流程如图所示:

搜索功能指的是通过关键词或者使用者的描述,获得目标数据的过程,这一功能原型图如图所示:
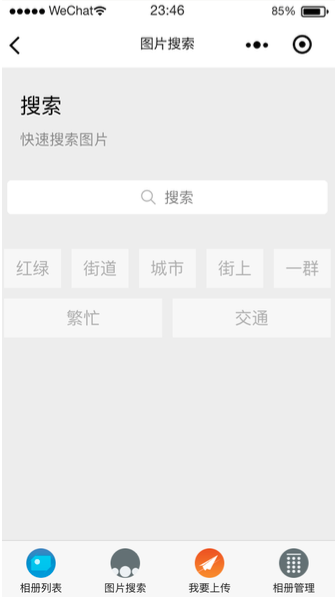
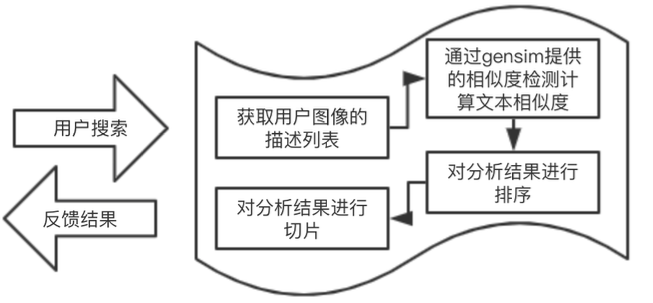
这一部分的难点和重点在于通过用户的描述,搜索到目标数据。这个过程的基本流程如图所示:
Serverless 架构具备按量付费、低成本运维、高效率开发等优点,可以帮助我们快速开发,快速迭代项目。而 Serverless Framework 则是一个非常高效的工具,其兼容了 AWS,Google Cloud 以及腾讯云等多家厂商的 Serverless 架构,为开发者提供一个多云的开发者工具,若以腾讯云为例,其拥有 Plugin 和 Components 两个部分。
Plugin 和 Components 这两个部分可以说是各有千秋,具体操作大家可以参看官方说明,我在这里想列举几点:
综上所述,对比 Plugin 和 Components 各有优劣,我很期待产品策略能够将二者合并或者功能对齐。在本文,我选择了 Components 来做这个项目。
使用 Components 做项目,我遇到的第一个难题是配置文件怎么办?我有很多的配置,我难道要在每个函数中写一遍?
于是,我做了一个新的: serverless-global 。这是一个 Components 功能,用来满足全局变量的需求。
复制代码
Conf: component: "serverless-global" inputs: mysql_host: gz-cdb-mytest.sql.tencentcdb.com mysql_user: mytest mysql_password: mytest mysql_port: 62580 mysql_db: mytest mini_program_app_id: mytest mini_program_app_secret: mytest在使用的时候,只需要使用${}就可以引用,例如:
复制代码
Album_Login: component: "@serverless/tencent-scf" inputs: name: Album_Login codeUri: ./album/login handler: index.main_handler runtime: Python3.6 region: ap-shanghai environment: variables: mysql_host: ${Conf.mysql_host} mysql_port: ${Conf.mysql_port} mysql_user: ${Conf.mysql_user} mysql_password: ${Conf.mysql_password} mysql_db: ${Conf.mysql_db}利用这个功能就可以很轻松将配置信息统一提取到了一个地方。需要说明的是,为什么我要把一些配置信息放在环境变量,而不是统一放在一个配置文件中,因为环境变量在 SCF 中会真的打到环境中,也就是说,你可以直接取到,我个人觉得比每次创建实例读取一次配置文件性能要好一些,虽然性能优势有限,但是,我还是觉得这样做是比较优雅的。最主要的是,相比写到代码中和配置到单独的配置文件中,这样做可以将代码分享给别人,并更好的保护敏感信息。
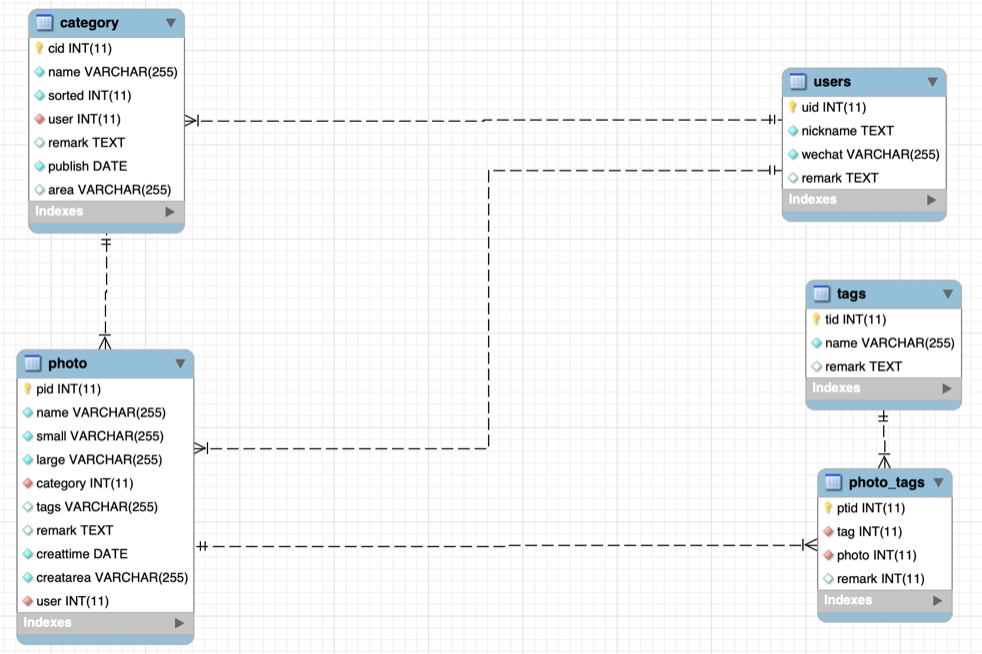
数据库部分主要对相关的表和表之间的关系进行建立。首先需要创建项目所必须的表:
复制代码
CREATE DATABASE `album`;CREATE TABLE `album`.`tags` ( `tid` INT NOT NULL AUTO_INCREMENT , `name` VARCHAR(255) NOT NULL , `remark` TEXT NULL , PRIMARY KEY (`tid`)) ENGINE = InnoDB;CREATE TABLE `album`.`category` ( `cid` INT NOT NULL AUTO_INCREMENT , `name` VARCHAR(255) NOT NULL , `sorted` INT NOT NULL DEFAULT '1' , `user` INT NOT NULL , `remark` TEXT NULL , `publish` DATE NOT NULL , `area` VARCHAR(255) NULL , PRIMARY KEY (`cid`)) ENGINE = InnoDB;CREATE TABLE `album`.`users` ( `uid` INT NOT NULL AUTO_INCREMENT , `nickname` TEXT NOT NULL , `wechat` VARCHAR(255) NOT NULL , `remark` TEXT NULL , PRIMARY KEY (`uid`)) ENGINE = InnoDB;CREATE TABLE `album`.`photo` ( `pid` INT NOT NULL AUTO_INCREMENT , `name` VARCHAR(255) NOT NULL , `small` VARCHAR(255) NOT NULL , `large` VARCHAR(255) NOT NULL , `category` INT NOT NULL , `tags` VARCHAR(255) NULL , `remark` TEXT NULL , `creattime` DATE NOT NULL , `creatarea` VARCHAR(255) NOT NULL , `user` INT NOT NULL , PRIMARY KEY (`pid`)) ENGINE = InnoDB;CREATE TABLE `album`.`photo_tags` ( `ptid` INT NOT NULL AUTO_INCREMENT , `tag` INT NOT NULL , `photo` INT NOT NULL , `remark` INT NULL , PRIMARY KEY (`ptid`)) ENGINE = InnoDB; 创建之后,逐步添加表之间的关系以及部分限制条件:
复制代码
ALTER TABLE `photo_tags` ADD CONSTRAINT `photo_tags_tags_alter` FOREIGN KEY (`tag`) REFERENCES `tags`(`tid`) ON DELETE CASCADE ON UPDATE RESTRICT; ALTER TABLE `photo_tags` ADD CONSTRAINT `photo_tags_photo_alter` FOREIGN KEY (`photo`) REFERENCES `photo`(`pid`) ON DELETE CASCADE ON UPDATE RESTRICT;ALTER TABLE `photo` ADD CONSTRAINT `photo_category_alter` FOREIGN KEY (`category`) REFERENCES `category`(`cid`) ON DELETE CASCADE ON UPDATE RESTRICT;ALTER TABLE `photo` ADD CONSTRAINT `photo_user_alter` FOREIGN KEY (`user`) REFERENCES `users`(`uid`) ON DELETE CASCADE ON UPDATE RESTRICT;ALTER TABLE `category` ADD CONSTRAINT `category_user_alter` FOREIGN KEY (`user`) REFERENCES `users`(`uid`) ON DELETE CASCADE ON UPDATE RESTRICT;ALTER TABLE `tags` ADD unique(`name`); 接下来,开始写第一个函数——注册登录函数。因为这是一个小程序,所以注册登录实际上就是拿着用户的 openId 去数据库查查有没有信息,有信息的话,就执行登录,没有信息的话就 insert 一下。那么问题来了,如何连接数据库?之所以有这样的问题,是源自两个因素:
针对问题 1,我们来做一个实验,先在腾讯云云函数创建一个 test:
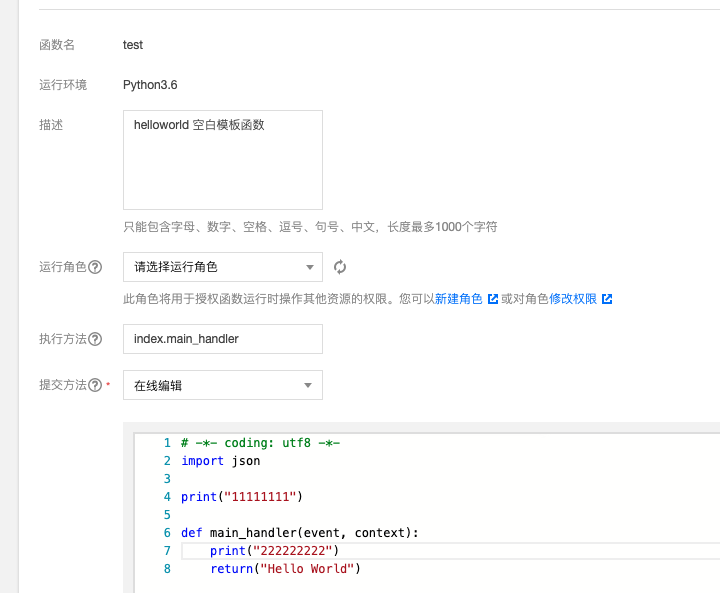
创建之后,疯狂点击测试按钮,多次记录运行日志:
第一次
复制代码
START RequestId: 4facbf59-3787-11ea-8026-52540029942f Event RequestId: 4facbf59-3787-11ea-8026-52540029942f 11111111 222222222 END RequestId: 4facbf59-3787-11ea-8026-52540029942f Report RequestId: 4facbf59-3787-11ea-8026-52540029942f Duration:1ms Memory:128MB MaxMemoryUsed:27.3164MB第二次
复制代码
START RequestId: 7aaf7921-3787-11ea-aba7-525400e4521d Event RequestId: 7aaf7921-3787-11ea-aba7-525400e4521d 222222222 END RequestId: 7aaf7921-3787-11ea-aba7-525400e4521d Report RequestId: 7aaf7921-3787-11ea-aba7-525400e4521d Duration:1ms Memory:128MB MaxMemoryUsed:27.1953MB第三次
复制代码
START RequestId: 742be57a-3787-11ea-b5c5-52540047de0f Event RequestId: 742be57a-3787-11ea-b5c5-52540047de0f 222222222 END RequestId: 742be57a-3787-11ea-b5c5-52540047de0f Report RequestId: 742be57a-3787-11ea-b5c5-52540047de0f Duration:1ms Memory:128MB MaxMemoryUsed:27.1953MB第四次
复制代码
START RequestId: 6faf934b-3787-11ea-8026-52540029942f Event RequestId: 6faf934b-3787-11ea-8026-52540029942f 222222222 END RequestId: 6faf934b-3787-11ea-8026-52540029942f Report RequestId: 6faf934b-3787-11ea-8026-52540029942f Duration:1ms Memory:128MB MaxMemoryUsed:27.1953MB大家仔细观察,发现了什么?我在函数外侧写的print("11111111")实际上只出现了一次,也就是说只运行了一次,而函数内的print("222222222")则是出现了多次,确切来说是每次都会出现,函数在创建的时候,会让我们写一个执行方法,例如index.main_handler,就是说默认的入口文件就是index.py下的main_handler方法。通过刚才的小实验,是不是可以认为,云函数实际上是随着机器或者容器启动同时启动了一个进程(这个时候会走一次外围的一些代码逻辑),然后当函数执行的时候,会走我们指定的方法,当函数执行完,这个容器并不会被马上销毁,而是进入销毁的倒计时,这个时候如果有请求来了,那么很可能复用这个容器,此时就没有容器启动的说法,会直接执行我们的方法。
按照这个逻辑,是不是我们的函数,如果要在我们的方法之外,初始化数据库就可以保证尽可能少的数据库连接建立,而满足更多的请求呢?换句话说,是不是和容器复用类似,我们就可以复用数据库的连接了?
所以,我们可以尝试这样写整个代码(login 为例)
复制代码
# -*- coding: utf8 -*- import osimport pymysqlimport json connection = pymysql.connect(host=os.environ.get('mysql_host'), user="root", password=os.environ.get('mysql_password'), port=int(62580), db="mini_album", charset='utf8', cursorclass=pymysql.cursors.DictCursor, autocommit=1) def getUserInfor(connection, wecaht): try: connection.ping(reconnect=True) cursor = connection.cursor() search_stmt = ( "SELECT * FROM `users` WHERE `wechat`=%s" ) data = (wecaht) cursor.execute(search_stmt, data) cursor.close() result = cursor.fetchall() return len(result) except Exception as e: print("getUserInfor", e) try: cursor.close() except: pass return False def addUseerInfor(connection, wecaht, nickname, remark): try: connection.ping(reconnect=True) cursor = connection.cursor() insert_stmt = ( "INSERT INTO users(wechat,nickname,remark) " "VALUES (%s,%s,%s)" ) data = (wecaht, nickname, remark) cursor.execute(insert_stmt, data) cursor.close() connection.close() return True except Exception as e: print(e) try: cursor.close() except: pass return False def main_handler(event, context): print(event) body = json.loads(event['body']) wecaht = body['wechat'] nickname = body['nickname'] remark = str(body['remark']) if getUserInfor(connection, wecaht) == 0: if addUseerInfor(connection, wecaht, nickname, remark): result = True else: result = False else: result = True return { "result": result } 所以,我将这个函数进行了规范化和完整化:
复制代码
# -*- coding: utf8 -*- import json try: import returnCommon from mysqlCommon import mysqlCommonexcept: import common.testCommon common.testCommon.setEnv() import common.returnCommon as returnCommon from common.mysqlCommon import mysqlCommon mysql = mysqlCommon() def main_handler(event, context): try: print(event) body = json.loads(event['body']) wecaht = body['wechat'] nickname = body['nickname'] remark = str(body['remark']) if not wecaht: return returnCommon.return_msg(True, "请使用微信小程序登陆本页面。") if not mysql.getUserInfor(wecaht): if not nickname: return returnCommon.return_msg(True, "参数异常,请重试。") if mysql.addUserInfor(wecaht, nickname, remark): return returnCommon.return_msg(False, "注册成功") return returnCommon.return_msg(True, "注册失败,请重试。") return returnCommon.return_msg(False, "登录成功") except Exception as e: print(e) return returnCommon.return_msg(True, "用户信息异常,请联系管理员处理") def test(): event = { "requestContext": { "serviceId": "service-f94sy04v", "path": "/test/{path}", "httpMethod": "POST", "requestId": "c6af9ac6-7b61-11e6-9a41-93e8deadbeef", "identity": { "secretId": "abdcdxxxxxxxsdfs" }, "sourceIp": "14.17.22.34", "stage": "release" }, "headers": { "Accept-Language": "en-US,en,cn", "Accept": "text/html,application/xml,application/json", "Host": "service-3ei3tii4-251000691.ap-guangzhou.apigateway.myqloud.com", "User-Agent": "User Agent String" }, "body": json.dumps({ "wechat": "12345", "nickname": "test", "remark": "", }), "pathParameters": { "path": "value" }, "queryStringParameters": { "foo": "bar" }, "headerParameters": { "Refer": "10.0.2.14" }, "stageVariables": { "stage": "release" }, "path": "/test/value", "queryString": { "foo": "bar", "bob": "alice" }, "httpMethod": "POST" } print(main_handler(event, None)) if __name__ == "__main__": test()数据库等一些公共组件,统一放在common目录下,例如mysqlCommon.py(部分):
复制代码
# -*- coding: utf8 -*- import osimport randomimport pymysqlimport datetime try: import cosClientexcept: import common.cosClient as cosClient class mysqlCommon: def __init__(self): self.getConnection({ "host": os.environ.get('mysql_host'), "user": os.environ.get('mysql_user'), "port": int(os.environ.get('mysql_port')), "db": os.environ.get('mysql_db'), "password": os.environ.get('mysql_password') }) def getConnection(self, conf): self.connection = pymysql.connect(host=conf['host'], user=conf['user'], password=conf['password'], port=int(conf['port']), db=conf['db'], charset='utf8', cursorclass=pymysql.cursors.DictCursor, autocommit=1) def doAction(self, stmt, data): try: self.connection.ping(reconnect=True) cursor = self.connection.cursor() cursor.execute(stmt, data) result = cursor cursor.close() return result except Exception as e: print(e) try: cursor.close() except: pass return False def addUserInfor(self, wecaht, nickname, remark): insert_stmt = ( "INSERT INTO users(wechat, nickname, remark) " "VALUES (%s,%s,%s)" ) data = (wecaht, nickname, remark) result = self.doAction(insert_stmt, data) return False if result == False else True 这样做的好处是:
由于云函数的测试非常不友好,所以为了在编写代码时可以更快地模拟线上环境,我选择通过增加test()方法来模拟触发器情况,进行简单的测试。
复制代码
try: import cosClientexcept: import common.cosClient as cosClient这样会更加便利,同时模拟网关,做一个测试方法:
复制代码
def test(): event = { "requestContext": { "serviceId": "service-f94sy04v", "path": "/test/{path}", "httpMethod": "POST", "requestId": "c6af9ac6-7b61-11e6-9a41-93e8deadbeef", "identity": { "secretId": "abdcdxxxxxxxsdfs" }, "sourceIp": "14.17.22.34", "stage": "release" }, "headers": { "Accept-Language": "en-US,en,cn", "Accept": "text/html,application/xml,application/json", "Host": "service-3ei3tii4-251000691.ap-guangzhou.apigateway.myqloud.com", "User-Agent": "User Agent String" }, "body": json.dumps({ "wechat": "12345", "nickname": "test", "remark": "", }), "pathParameters": { "path": "value" }, "queryStringParameters": { "foo": "bar" }, "headerParameters": { "Refer": "10.0.2.14" }, "stageVariables": { "stage": "release" }, "path": "/test/value", "queryString": { "foo": "bar", "bob": "alice" }, "httpMethod": "POST" } print(main_handler(event, None))增加本地测试时,指定test()方法:
复制代码
if __name__ == "__main__": test()这样,线上触发时会默认执行main_handler, 而本地执行,则会通过test走入main_handler,我们可以边开发,边测试,全部弄好之后再部署到线上。
线上获取配置信息是通过获取环境变量,本地又该如何执行?我们需要先进行这个操作:
复制代码
# -*- coding: utf8 -*- import yamlimport os def setEnv(): file = open("/Users/dfounderliu/Documents/code/AIAlbum/serverless.yaml", 'r', encoding="utf-8") file_data = file.read() file.close() data = yaml.load(file_data) for eveKey, eveValue in data['Conf']['inputs'].items(): print(eveKey, eveValue) os.environ[eveKey] = str(eveValue) 这样,我们这个文件就既可以线上直接用,也可以本地直接用了!
那么,Yaml 怎么写?
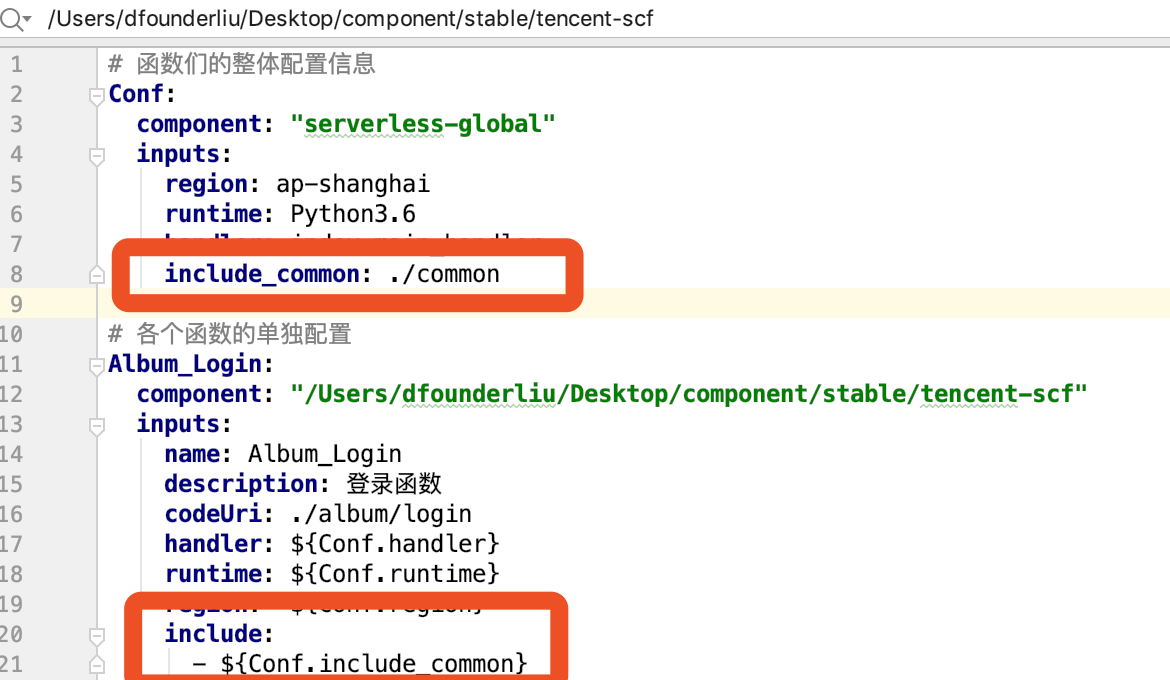
然后,我们可以在部署函数的时候将公共组件引入项目中。
本地形式:

线上形式:
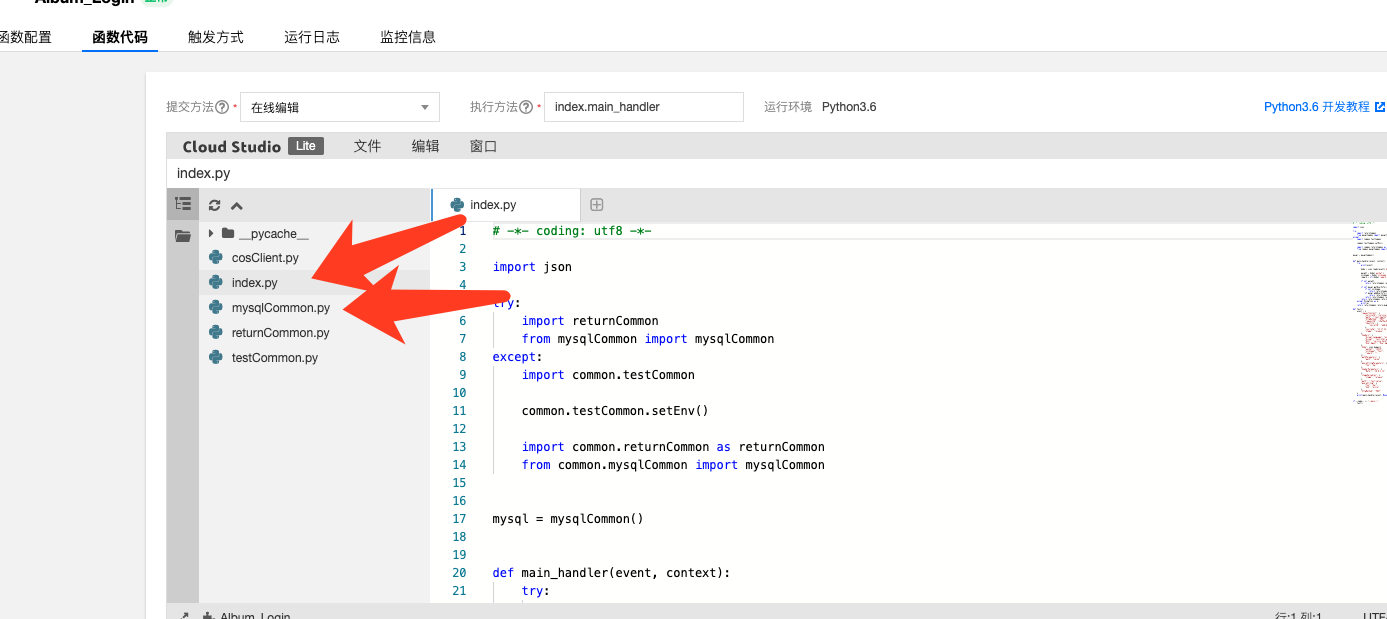
复制代码
# 函数们的整体配置信息Conf: component: "serverless-global" inputs: region: ap-shanghai runtime: Python3.6 handler: index.main_handler include_common: ./common mysql_host: gz-c************************.com mysql_user: root mysql_password: S************************! mysql_port: 6************************0 mysql_db: album mini_program_app_id: asdsa************************dddd mini_program_app_secret: fd340c4************************8744ee tencent_secret_id: AKID1y************************l1q0kK tencent_secret_key: cCoJ************************FZj5Oa tencent_appid: 1256773370 cos_bucket: 'album-1256773370' domain: album.0duzahn.com由于我目前使用的是 Serverless Components,没有全局变量等,所以在此处增加了全局变量组件,在这里设置好全局变量,在之后的 Components 中可以直接引用,例如:
复制代码
# 创建存储桶CosBucket: component: '@serverless/tencent-website' inputs: code: src: ./cos region: ${Conf.region} bucketName: ${Conf.cos_bucket}复制代码
DEBUG ─ Resolving the template's static variables. DEBUG ─ Collecting components from the template. DEBUG ─ Downloading any NPM components found in the template. DEBUG ─ Analyzing the template's components dependencies. DEBUG ─ Creating the template's components graph. DEBUG ─ Syncing template state. DEBUG ─ Executing the template's components graph. DEBUG ─ Starting API-Gateway deployment with name APIService in the ap-shanghai region ... ... DEBUG ─ Updating configure... DEBUG ─ Created function Album_Get_Photo_Search successful DEBUG ─ Setting tags for function Album_Get_Photo_Search DEBUG ─ Creating trigger for function Album_Get_Photo_Search DEBUG ─ Deployed function Album_Get_Photo_Search successful DEBUG ─ Uploaded package successful /Users/dfounderliu/Documents/code/AIAlbum/.serverless/Album_Prediction.zip DEBUG ─ Creating function Album_Prediction DEBUG ─ Updating code... DEBUG ─ Updating configure... DEBUG ─ Created function Album_Prediction successful DEBUG ─ Setting tags for function Album_Prediction DEBUG ─ Creating trigger for function Album_Prediction DEBUG ─ Trigger timer: timer not changed DEBUG ─ Deployed function Album_Prediction successful Conf: region: ap-shanghai ... ... - path: /photo/delete method: ANY apiId: api-g9u6r9wq - path: /album/delete method: ANY apiId: api-b4c4xrq8 - path: /album/add method: ANY apiId: api-ml6q5koy 156s › APIService › done 这个过程只用了 156s 就部署了所有函数,然后打开小程序的 id 带入miniProgram目录,并且填写自己的appid在文件project.config.json的第 17 行,同时也要配置自己项目的基础目录,就是 API 网关给我们返回的地址,写在app.js的第 10 行,此时项目就可以运行起来了。
本文中的例子是通过 Serverless 架构使用 Python 语言开发了一个微信小程序,这里面涉及到了数据库的增删改查,公共组件的提取,如何定义 Components 的全局变量,如何本地调试和线上触发二者兼得,以及在什么地方初始化数据库"性价比较高"。希望通过这样一个简单的例子,可以让 Serverless 在更多的领域都有实际的应用价值,可以给更多人灵感和启发:Serverless?万物都可以 Serverless 么?让我们一起来尝试更多 Serverless 架构的应用领域吧。
关注我并转发此篇文章,私信我“领取资料”,即可免费获得InfoQ价值4999元迷你书!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号