揭秘PostgreSQL:数据组织的第一课
发表时间: 2022-11-16 15:47
PostgreSQL数据库(以下简称PG数据库),是目前功能最强大的开源数据库之一,近年来技术发展迅猛,曾经数次获得DB-Engines 排行榜“年度数据库”的称号。
PG数据库支持关系型数据和非关系型数据的查询,提供多种功能,主要包括帮助开发人员构建应用程序,管理员保护数据完整性,并且构建容错环境。依托20多年的社区发展,造就了其高水平的故障恢复能力、完整性和正确性。
在近期的直播中,HashData数据库内核工程师介绍了PG数据组织的相关知识。以下为直播文字节选,与大家共享。
PostgreSQL的数据组织
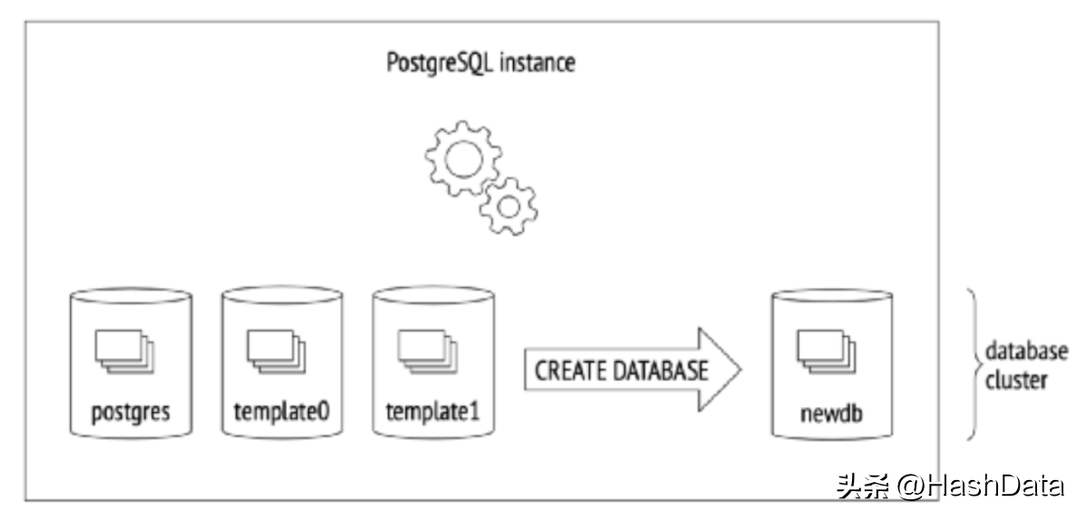
在PG初始化的时候,会默认创建三个数据库,分别为template 0、template 1、postgres database。用户也可以自己创建新的 database 。
另外,PG在数据库内引入了命名空间的概念即schema,避免同一数据库内相同名字的对象(比如数据库表)间的命名冲突。需要注意的是,schema隶属于数据库,不同数据库可以创建各自的schema。

以上图为例,在数据库Database 1和数据库Database 2里面分别存在有 Schema 1和 Schema 2。在 Schema 1和 Schema 2下面又有 t1、t2、t3,这些数据库表名字相同,但是Schema不一样,因此互相不会产生冲突。有一些特别的schema 是系统内置的,比如public、pg_catalog、information_schema、pg_toast等。其中,PG元数据信息和表都放置在pg_catalog schema中,包括系统表 、索引 、内置数据类型、内置函数等。对于系统表,pg_class,其中储存了表的描述信息;pg_database 存储PG中已经创建的数据库的信息;pg_am 用于存储表访问方法的元数据。
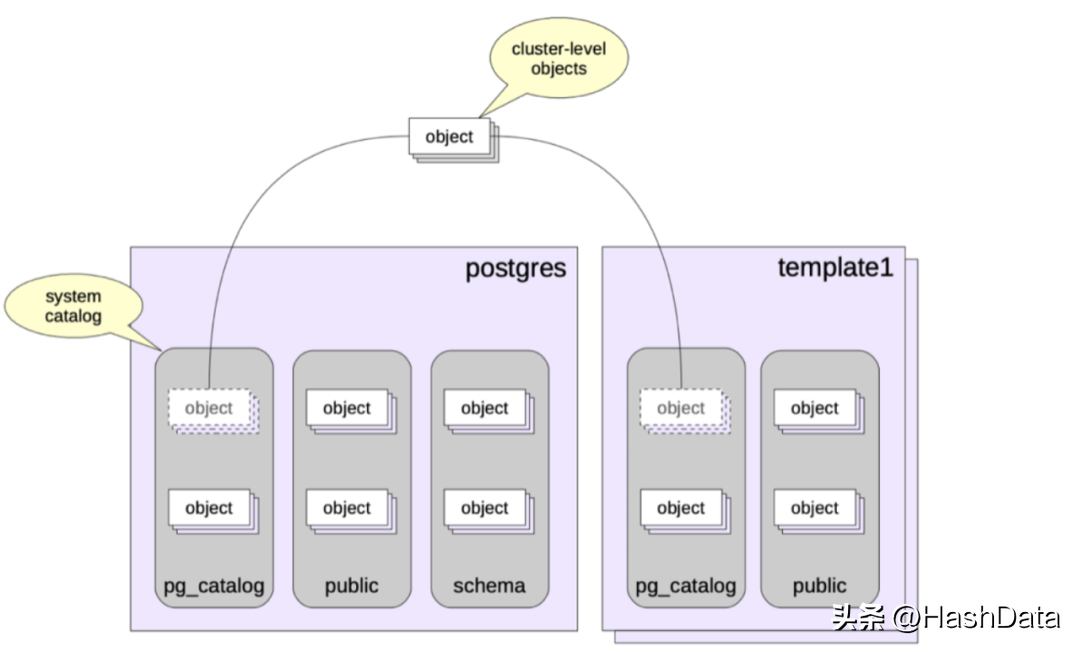
对于用户给定的表,PG怎么知道对应哪个schema下的数据表呢?为此,PG引入了一个配置参数search_path。search_path是一个schema的列表,用逗号分隔。用户可以通过search_path来指定要查找的schema列表的优先顺序,从前到后优先级依次递减。如果search_path中所有的schema都没有匹配的表名,就会报告错误,即使数据库中其他schema中存在匹配的表名。
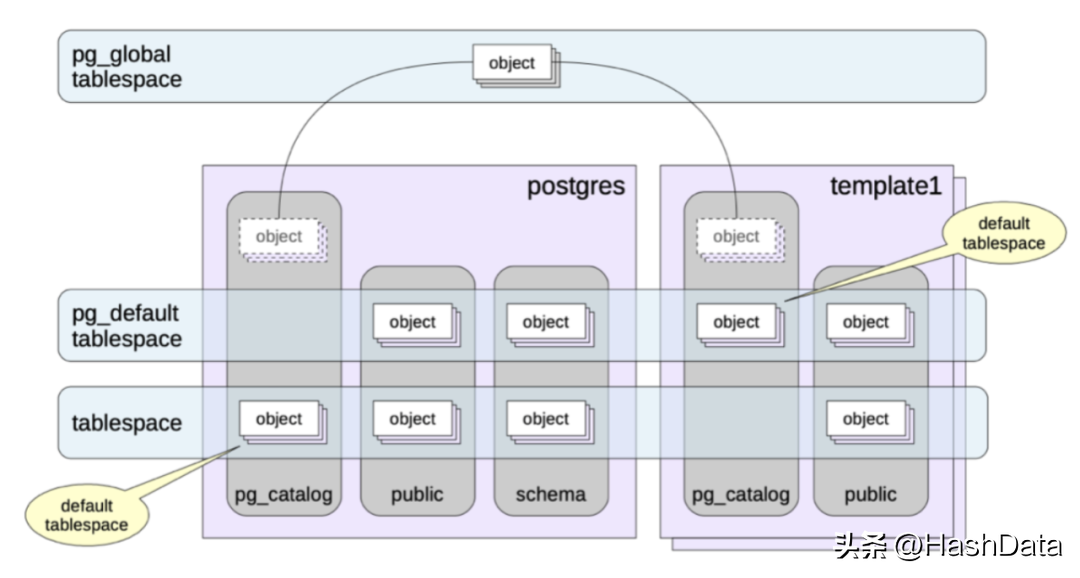
PostgerSQL文件布局
PG物理上引入了tablespace(表空间)的概念,它的作用是用于指定表的存储路径。系统默认的tablespace为pg_default,用户也可以自定义tablespace。
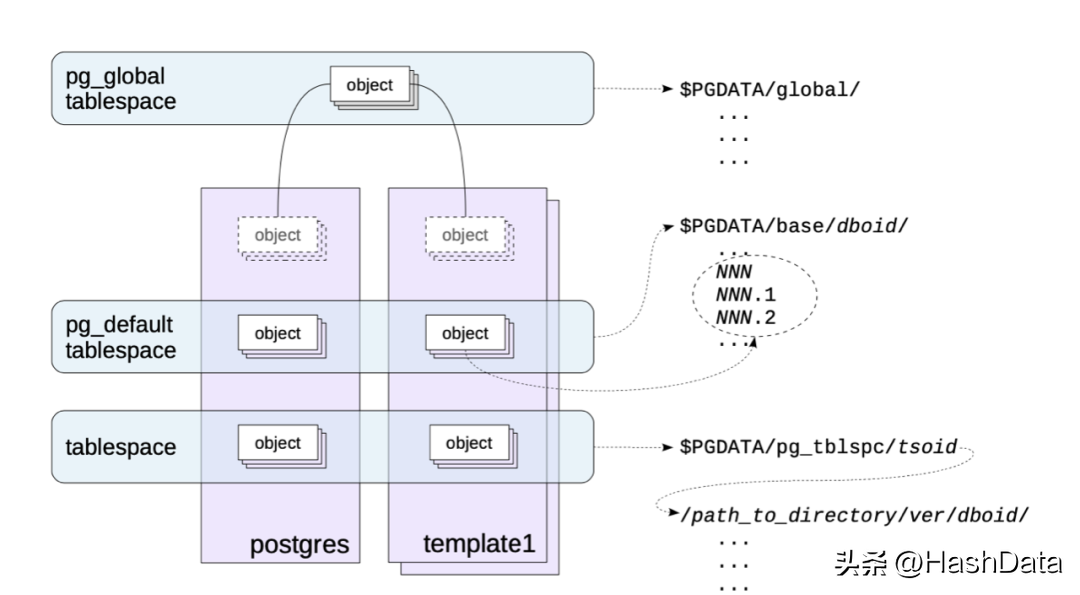
如上图所示,pg_global tablespace的映射到路径是$PGDATA/global;pg_default 会映射到 $PGDATA/base/;用户自定义的tablespace 会映射到 $PGDATA/pg_tblspc/目录下,然后创建一个符号链接到实际的数据目录。另外,可以通过tablespace实现冷热数据分离:将热数据存在SSD的路径上,冷数据则存到SATA磁盘对应的路径上。
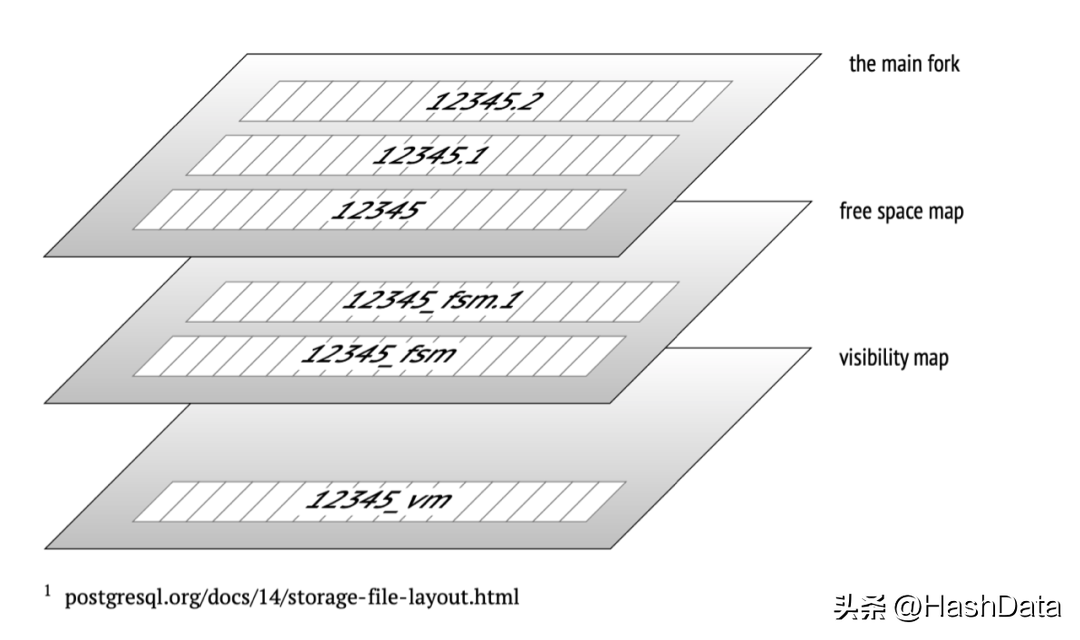
PG在使用过程中,随着文件变大,当达到1GB时,将创建一个相同fork的新文件。通常每个表的文件集合对应多个后缀fork文件。其中,main fork存储数据本身:即表和索引行。main fork可用于任何关系(不包含数据的视图除外)。通常,文件会被切割成1 GB大小的文件,称为segment 文件,以保证不同的文件系统都是可用的。限制文件的大小是为了更好地支持不同的文件系统,因为其中一些文件系统无法处理较大的文件。
为了便于管理文件内的空闲空间,PG引入了free space map(空闲空间映射)文件,用于记录跟踪数据页面内部空闲空间的位置信息。PG会动态维护空闲空间映射文件中的内容。比如通过vacuum进行无用数据回收后,它会将新增空闲页信息记录到空闲空间映射文件中,以便将来能够快速复用回收的空闲页面。
此外,visibility map用来记录一个页面中的数据是否都“可见”,即不需要对页内每行数据逐个进行MVCC可见性检查,进一步提升数据扫描性能。
PostgerSQL页内数据存储和TOAST
PG的页面大小默认为8K,当PG的元组(可以理解为表中的一行)特别大,无法放入页内时,PG需要使用超大属性存储技术(TOAST)。对于大属性,PG引入了下列多种存储策略:
TOAST策略:
通常,为了保证存储密度,PG一页(大小为8K字节)至少存储四个元组。因此理论上,一个元组大小阈值最大为:(8K字节 - 页面头部)/ 4。进行TOAST存储时,我们依次应用以下算法原则,并在该行不再超过阈值时立即停止:
有时,更改某些列的策略可能很有用。例如,如果事先知道无法压缩列中的数据,则可以为其设置“EXTERNAL”策略,这样可以避免不必要的压缩尝试,从而节省时间。请注意,TOAST仅适用于表,不适用于索引。这对要索引的键的大小施加了限制。
HashData作为一款100% 兼容PostgreSQL生态的数据仓库,在PostgreSQL的基础上拓展了新的存储引擎,比如AO表、基于Arrow的向量化执行引擎、列式存储引擎等,进一步提升了系统的性能。始于开源,回馈开源。HashData将立足于云原生数据仓库的研发和创新,以领先的技术推动开源技术发展,从开源使用者转向贡献者、引领者,打造出世界一流的云原生数仓平台。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号