深度解析:Kafka并非数据库
发表时间: 2020-12-24 16:43
理解流式基础设施的使用和滥用,这一点很重要。
Kafka 是一种消息代理,在过去几年中迅速流行起来。消息代理已经存在很长时间了,它们是一种专门用于在生产者和消费者系统之间“缓冲”消息的数据存储。Kafka 已经相当流行,因为它是开源的,并且能够支持海量的消息。
消息代理通常用于解耦数据的生产者和消费者。例如,我们使用一个类似 Kafka 的消息代理来缓冲客户生成的 Webhook,然后将它们批量加载到数据仓库中。

在这个场景中,消息代理提供了从客户发送事件到 Fivetran 将它们加载到数据仓库之间的事件持久存储。
但是,Kafka 有时候也被描述为是一种比消息代理更大的东西。这个观点的支持者将 Kafka 定位为一种全新的数据管理方式,Kafka 取代了关系数据库,用于保存事件的最终记录。与读写传统数据库不同,在 Kafka 中,先是追加事件,然后从表示当前状态的下游视图中读取数据。这种架构被看成是对“数据库的颠覆”。
原则上,以一种同时支持读和写的方式实现这个架构是有可能的。但是,在这个过程中,最终会遇到数据库管理系统几十年来遇到的所有难题。你或多或少需要在应用程序层开发一个功能齐全的 DBMS,而你可能不会做得太好,毕竟一个数据库需要很多年才能做好。你需要处理脏读、幻读、写偏移等问题,还要应付匆忙实现的数据库存在的所有其他问题。
将 Kafka 作为数据存储的一个最基本的问题是它没有提供隔离机制。隔离意味着在全局内,所有事务(读和写)都是沿着某些一致的历史记录发生的。Jepsen 提供了一个隔离级别指南(
https://jepsen.io/consistency)。
我们举一个简单的例子来说明为什么隔离很重要:假设我们正在运营一个在线商店。当用户结账时,我们要确保他们下的订单都有足够的库存。我们是这样做的:
假设我们使用 Kafka 来实现这个流程。我们的架构可能看起来像这样:
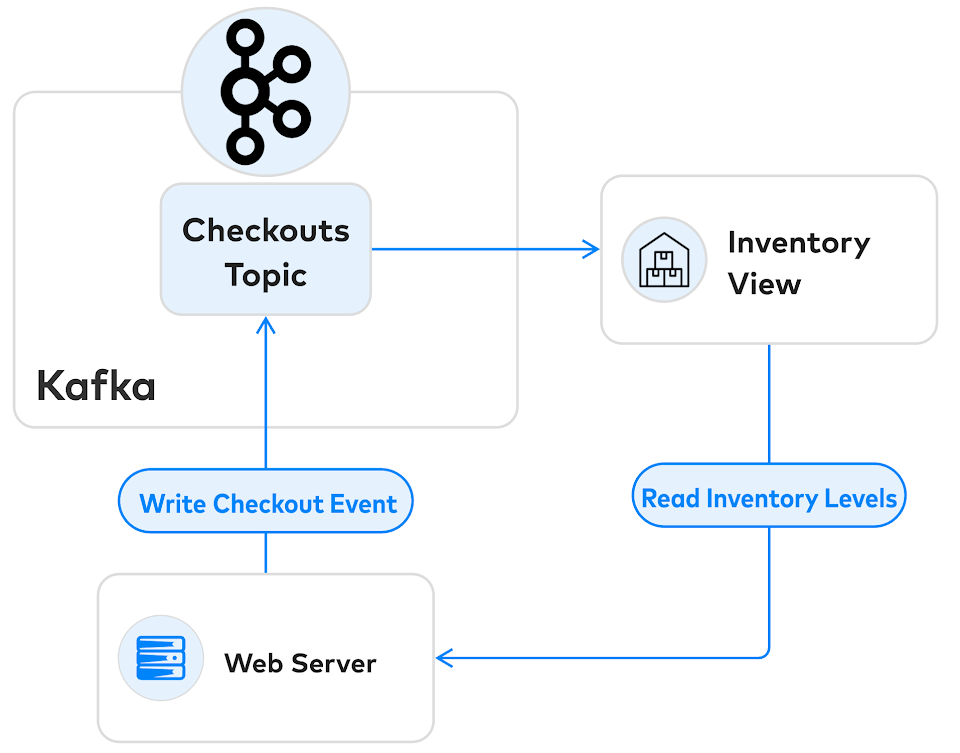
Web 服务器从 Kafka 下游的库存视图读取库存,但它只能在 Checkouts 主题的上游提交事务。问题在于并发控制:如果有两个用户争着购买最后一件商品,那么只有一个用户可以购买成功。我们需要读取库存视图,并在一个单独的时间点确认结帐。但是,在这个架构中没有办法做到这一点。
我们现在遇到的问题叫做写偏移。当结账事件被处理时,从库存视图中读取的数据可能已经过时。如果两个用户同时尝试购买相同的物品,他们都将购买成功,那么我们便没有足够的库存供应给他们。
这种基于事件溯源的架构存在很多类似这样的隔离异常,让用户感到很困惑。更糟糕的是,研究表明,允许异常存在的架构也存在安全漏洞,给了黑客窃取数据的机会,正如这篇文章(
https://www.cockroachlabs.com/blog/acid-rain)所写的那样。
如果你只是将 Kafka 作为传统数据库的补充,这些问题就可以避免:
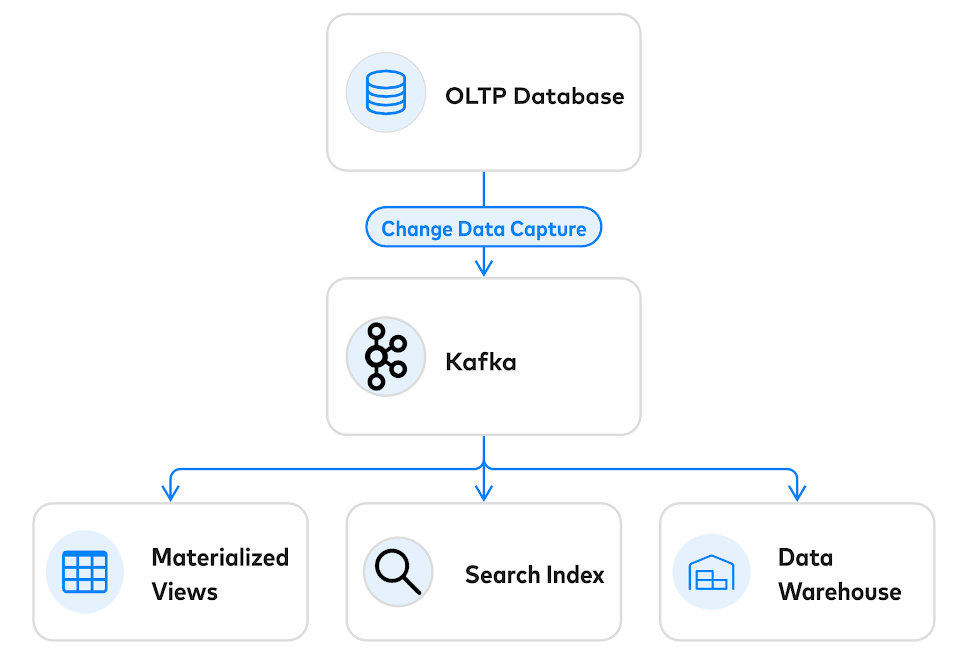
OLTP 数据库负责执行消息代理不太擅长的关键任务:事件的准入控制。与将消息代理作为“触发并遗忘”事件的容器不同,OLTP 数据库可以拒绝冲突性事件,确保只接收一个具有一致性的事件流。OLTP 数据库在这一核心并发控制任务上做得非常出色——可扩展到每秒处理数百万个事务。
当使用数据库作为数据入口,从数据库读取事件的最佳方法是通过 CDC(变更数据捕获)。市场上有几个很棒的 CDC 框架,例如 Debezium(http://debezium.io/)和 Maxwell(
http://maxwells-daemon.io/),以及来自现代 SQL 数据库的原生 CDC。CDC 还提供了优雅的运维解决方案。在进行数据恢复时,可以清除下游的所有内容,并从(持久化的)OLTP 数据库重新构建。
几十年来,数据库社区已经总结了一些重要的经验教训。这些教训都是在造成数据损坏、数据丢失和让用户遭受损失的情况下获得的,并为此付出了惨重的代价。如果你不小心构建了一个错误的数据库,那么你会发现自己只不过是在重新经历这些经验教训。
实时流式消息代理是管理快速变化的数据的一个很好的工具,但你仍然需要一个传统的 DBMS 来实现事务隔离。要实现一个“颠覆性的数据库”,可以使用 OLTP 数据库进行准入控制,使用 CDC 进行事件生成,并将数据的下游副本变成物化视图。
原文链接:
https://materialize.com/kafka-is-not-a-database
延伸阅读:
Kafka实时API探秘-InfoQ
关注我并转发此篇文章,私信我“领取资料”,即可免费获得InfoQ价值4999元迷你书,点击文末「了解更多」,即可移步InfoQ官网,获取最新资讯~
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号