C++ 20即将发布:你对它抱有期待吗?
发表时间: 2018-12-29 20:07

编辑 | Lisa
C++ 20 要来了!然而,大家都不看好是怎么回事儿?
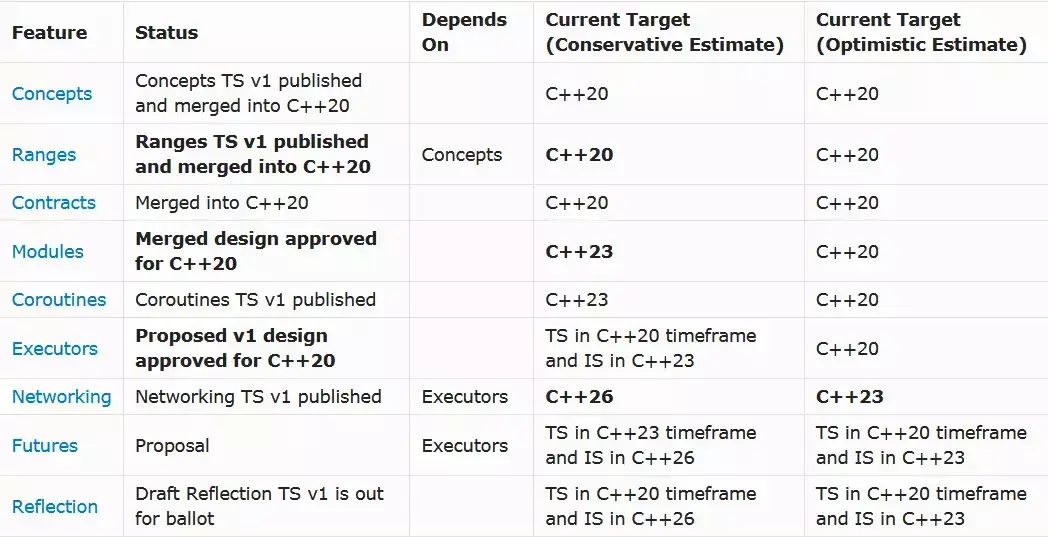
为了 C++20,C++ 标准委员会曾举办历史上规模最大的一次会议(180 人参会),试图通过会议确定哪些特性可以加入新版本,我们也已经看到媒体爆料的部分新特性,比如 Concepts、Ranges、Modules、Coroutimes 等,但大部分开发人员并不认可此次调整,并将部分新特性归结为“语法糖”。
不少网友看到上述特性纷纷在社交平台吐槽,表示不看好 C++20 版本的发布:
不仅国内如此,国外的一位游戏领域开发人员接连在社交平台发表看法,声明自己不看好 C++20 的新特性,并认为新版本没有解决最关键的问题,他通过使用毕达哥拉斯三元数组示例对 C++20 标准下的代码和旧版本进行对比,明确阐述自己对于 C++20 的态度。
毕达哥拉斯三元数组,C ++ 20 Ranges 风格
以下是 C++20 标准下代码的完整示例(超长预警):
// A sample standard C++20 program that prints// the first N Pythagorean triples.#include <iostream>#include <optional>#include <ranges> // New header!using namespace std;// maybe_view defines a view over zero or one// objects.template<Semiregular T>struct maybe_view : view_interface<maybe_view<T>> { maybe_view() = default; maybe_view(T t) : data_(std::move(t)) { } T const *begin() const noexcept { return data_ ? &*data_ : nullptr; } T const *end() const noexcept { return data_ ? &*data_ + 1 : nullptr; }private: optional<T> data_{};};// "for_each" creates a new view by applying a// transformation to each element in an input// range, and flattening the resulting range of// ranges.// (This uses one syntax for constrained lambdas// in C++20.)inline constexpr auto for_each = []<Range R, Iterator I = iterator_t<R>, IndirectUnaryInvocable<I> Fun>(R&& r, Fun fun) requires Range<indirect_result_t<Fun, I>> { return std::forward<R>(r) | view::transform(std::move(fun)) | view::join; };// "yield_if" takes a bool and a value and// returns a view of zero or one elements.inline constexpr auto yield_if = []<Semiregular T>(bool b, T x) { return b ? maybe_view{std::move(x)} : maybe_view<T>{}; };int main() { // Define an infinite range of all the // Pythagorean triples: using view::iota; auto triples = for_each(iota(1), [](int z) { return for_each(iota(1, z+1), [=](int x) { return for_each(iota(x, z+1), [=](int y) { return yield_if(x*x + y*y == z*z, make_tuple(x, y, z)); }); }); }); // Display the first 10 triples for(auto triple : triples | view::take(10)) { cout << '(' << get<0>(triple) << ',' << get<1>(triple) << ',' << get<2>(triple) << ')' << '\n'; }}以下代码为简单的 C 函数打印第一个 N Pythagorean Triples:
void printNTriples(int n){ int i = 0; for (int z = 1; ; ++z) for (int x = 1; x <= z; ++x) for (int y = x; y <= z; ++y) if (x*x + y*y == z*z) { printf("%d, %d, %d\n", x, y, z); if (++i == n) return; }}如果不必修改或重用此代码,那么一切都没问题。 但是,如果不想打印而是将三元数组绘制成三角形或者想在其中一个数字达到 100 时立即停止整个算法,应该怎么办呢?
毕达哥拉斯三元数组,简单的 C ++ 风格
以下是旧版本的 C++ 代码实现打印前 100 个三元数组的完整程序:
// simplest.cpp#include <time.h>#include <stdio.h>int main(){ clock_t t0 = clock(); int i = 0; for (int z = 1; ; ++z) for (int x = 1; x <= z; ++x) for (int y = x; y <= z; ++y) if (x*x + y*y == z*z) { printf("(%i,%i,%i)\n", x, y, z); if (++i == 100) goto done; } done: clock_t t1 = clock(); printf("%ims\n", (int)(t1-t0)*1000/CLOCKS_PER_SEC); return 0;}我们可以编译这段代码:clang simplest.cpp -o outsimplest,需要花费 0.064 秒,产生 8480 字节可执行文件,在 2 毫秒内运行并打印数字(使用的电脑是 2018 MacBookPro,Core i9 2.9GHz,Xcode 10 clang):
(3,4,5)
(6,8,10)
(5,12,13)
(9,12,15)
(8,15,17)
(12,16,20)
(7,24,25)
(15,20,25)
(10,24,26)
...
(65,156,169)
(119,120,169)
(26,168,170)
这是 Debug 版本的构建,优化的 Release 版本构建:clang simplest.cpp -o outsimplest -O2,编译花费 0.071 秒,生成相同大小(8480b)的可执行文件,并在 0ms 内运行(在 clock()的计时器精度下)。
接下来,对上述代码进行改进,加入代码调用并返回下一个三元数组,代码如下:
// simple-reusable.cpp#include <time.h>#include <stdio.h>struct pytriples{ pytriples() : x(1), y(1), z(1) {} void next() { do { if (y <= z) ++y; else { if (x <= z) ++x; else { x = 1; ++z; } y = x; } } while (x*x + y*y != z*z); } int x, y, z;};int main(){ clock_t t0 = clock(); pytriples py; for (int c = 0; c < 100; ++c) { py.next(); printf("(%i,%i,%i)\n", py.x, py.y, py.z); } clock_t t1 = clock(); printf("%ims\n", (int)(t1-t0)*1000/CLOCKS_PER_SEC); return 0;}这几乎在同一时间编译和运行完成,Debug 版本文件变大 168 字节,Release 版本文件大小相同。此示例编写了 pytriples 结构,每次调用 next() 都会跳到下一个有效三元组,调用者可随意做任何事情,此处只调用一百次,每次打印三联。
虽然实现的功能等同于三重嵌套 for 循环,但 C++ 20 标准下的代码让人感觉不是很清楚,无法立即读懂程序逻辑。如果 C ++ 有类似 coroutine 的概念,就可能实现三元组生成器,并且和原始的 for 循环嵌套一样清晰:
generator<std::tuple<int,int,int>> pytriples(){ for (int z = 1; ; ++z) for (int x = 1; x <= z; ++x) for (int y = x; y <= z; ++y) if (x*x + y*y == z*z) co_yield std::make_tuple(x, y, z);}C ++20 Ranges 会让整段代码更加清晰吗?结果如下:
auto triples = for_each(iota(1), [](int z) { return for_each(iota(1, z+1), [=](int x) { return for_each(iota(x, z+1), [=](int y) { return yield_if(x*x + y*y == z*z, make_tuple(x, y, z)); }); }); });多次 return 实在是让人感觉很奇怪,这或许不应该成为好语法的标准。
如果谈到 C++ 的问题,至少有两个:
虽然 C++ 20 Ranges 还未正式发布,但本文使用了它的近似版,即 isrange-v3(由 Eric Niebler 编写),并编译了规范的“Pythagorean Triples with C ++ Ranges”示例:
// ranges.cpp#include <time.h>#include <stdio.h>#include <range/v3/all.hpp>using namespace ranges;int main(){ clock_t t0 = clock(); auto triples = view::for_each(view::ints(1), [](int z) { return view::for_each(view::ints(1, z + 1), [=](int x) { return view::for_each(view::ints(x, z + 1), [=](int y) { return yield_if(x * x + y * y == z * z, std::make_tuple(x, y, z)); }); }); }); RANGES_FOR(auto triple, triples | view::take(100)) { printf("(%i,%i,%i)\n", std::get<0>(triple), std::get<1>(triple), std::get<2>(triple)); } clock_t t1 = clock(); printf("%ims\n", (int)(t1-t0)*1000/CLOCKS_PER_SEC); return 0;}该代码使用 0.4.0 之后的版本,并用 clang ranges.cpp -I. -std=c++17 -lc++ -o outranges 编译,整个过程花费 2.92 秒,可执行文件为 219 千字节,运行在 300 毫秒之内。
这是一个非优化的构建,优化构建版本(clang ranges.cpp -I. -std=c++17 -lc++ -o outranges -O2)在 3.02 秒内编译,可执行文件为 13976 字节,并在 1ms 内运行。因此运行时性能很好,可执行文件稍大,编译时问题仍然存在。
编译时是 C ++ 的一个大问题,这个非常小的例子编译时间比简单版的 C ++ 长 2.85 秒。在 3 秒内,现代 CPU 可以进行大量操作,比如,在 Debug 构建中编译一个包含 22 万行代码的数据库引擎(SQLite)只需要 0.9 秒。所以,编译一个简单的 5 行示例代码比运行完整的数据库引擎慢三倍?
在开发过程中,C ++ 编译时间一直是大小代码库的痛苦根源。他认为,C ++ 新版本应该把解决编译时问题排在第一位。但是,整个 C++ 社区好像并不知道该问题,每个版本都将更多内容放入头文件,甚至放入必须存在于头文件的模板化代码中。
range-v3 是 1.8 兆字节的源代码,全部在头文件中,因此,虽然使用 C++ 20 输出 100 个三元数组的代码示例只有 30 行,但加上头文件后,编译器最终会编译 102,000 行代码。在所有预处理之后,简单版本的 C ++ 示例只有 720 行代码。
Ranges 示例的运行时性能慢了 150 倍,这对于要解决实际问题的代码库而言,两个数量级的速度可能意味着不会对任何实际数据集起作用。该开发者在游戏行业工作,这意味着引擎或工具的 Debug 版本不适用于任何真实的游戏级别模拟(性能无法接近所需的交互级别)。
通过避免 STL 位(提交),可以让最终运行时快 10 倍,也可以让编译时间更快且调试更容易,因为微软的 STL 实现特别喜欢深度嵌套的函数调用。这并不是说 STL 必然不好,有可能编写 STL 实现在非优化版本中不会变慢 10 倍(如 EASTL 或 libc ++ 那样),但由于微软的 STL 过度依赖深度嵌套,因此会变慢。
作为语言的使用者,大部分人不关心它是否正确发展!即便知道 STL 在 Debug 中太慢,宁愿花时间修复或者研究替代方案(例如不使用 STL,重新实现需要的位,或者完全停止使用 C ++)也不会花时间整理论文上报 C++ 委员会,这太浪费时间。
这里简要介绍 C#中“毕达哥拉斯三元数组”实现,以下是完整 C#源代码:
using System;using System.Diagnostics;using System.Linq;class Program{ public static void Main() { var timer = Stopwatch.StartNew(); var triples = from z in Enumerable.Range(1, int.MaxValue) from x in Enumerable.Range(1, z) from y in Enumerable.Range(x, z) where x*x+y*y==z*z select (x:x, y:y, z:z); foreach (var t in triples.Take(100)) { Console.WriteLine($"({t.x},{t.y},{t.z})"); } timer.Stop(); Console.WriteLine($"{timer.ElapsedMilliseconds}ms"); }}就个人而言,C#可读性较高:
var triples = from z in Enumerable.Range(1, int.MaxValue) from x in Enumerable.Range(1, z) from y in Enumerable.Range(x, z) where x*x+y*y==z*z select (x:x, y:y, z:z);
用 C ++:
auto triples = view::for_each(view::ints(1), [](int z) { return view::for_each(view::ints(1, z + 1), [=](int x) { return view::for_each(view::ints(x, z + 1), [=](int y) { return yield_if(x * x + y * y == z * z, std::make_tuple(x, y, z)); }); });});C#LINQ 的另一种“数据库较少”的形式:
var triples = Enumerable.Range(1, int.MaxValue) .SelectMany(z => Enumerable.Range(1, z), (z, x) => new {z, x}) .SelectMany(t => Enumerable.Range(t.x, t.z), (t, y) => new {t, y}) .Where(t => t.t.x * t.t.x + t.y * t.y == t.t.z * t.t.z) .Select(t => (x: t.t.x, y: t.y, z: t.t.z));在 Mac 上编译这段代码,需要使用 Mono 编译器(本身是用 C#编写的),版本 5.16。mcs Linq.cs 需要 0.20 秒。相比之下,编译等效的简单 C#版本需要 0.17 秒。LINQ 样式为编译器创建了额外的 0.03 秒。但是,C ++ 却创造了额外的 3 秒。
一般来说,我们会试图避免大部分 STL,使用自己的容器,哈希表使用开放寻址代替...... 甚至不需要标准库的大部分功能。但是,难免需要时间说服每一位新员工(尤其是应届生),因为 C++20 被称为现代 C ++,很多新员工认为“新一定就是好”,其实并不是这样。
该开发者表示不太清楚 C++ 为什么会发展到现在这个地步。 但他个人认为,C++ 社区需要学会“保持接近 100%向后兼容的同时发展一种语言”。 在某种程度上,现在的 C++ 生态系统太专注于炫耀或证明其价值的复杂性,却并不易用。
在他的印象中,大多数游戏开发人员还停留在 C++ 11、14 或者 17 版本,C++20 基本忽略了一个问题,无论什么被添加到标准库,编译时间长和调试构建性能差的问题没有解决都是无用的。
对于游戏产业而言,大部分传统技术是用 C 或 C ++ 构建的,在很长一段时间内,没有出现可行的替代品(好在目前至少可以用 Rust 作为可能的竞争者),对 C 和 C ++ 的依赖程度很高,需要社区的一些帮助和回应。
Q 言 Q 语时刻
看到这里,你觉得 C++ 20 有搞头吗?欢迎在评论区分享你的观点!
参考链接
http://aras-p.info/blog/2018/12/28/Modern-C-Lamentations/
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号