Node.js在大型应用中为何备受质疑?
发表时间: 2018-11-02 13:31
首先要明确什么是大型应用,其实这是仁者见仁、智者见智的问题,并且它是一个哲学问题,不是一个技术问题。假如有人问你,一个可以进行线上销售的网站,比如优衣库,大不大?你可能会说大,因为这与你平常所见的博客、企业官网等逻辑相比较确实复杂很多。或者说小,那么说明你开发过比它还复杂的系统。那么相比较淘宝而言呢?大和小的对比是要有参照物的。
一个完备的 Web 应用可能只由一门语言或者一种技术构成吗?不可能。因为一个完备的 Web 应用其实是多门技术的综合体,解决某个问题有非常多的解决方案,比如后端的逻辑解决方案就非常多,Java、PHP、Python、Ruby 等都可以。
简单地概述,应用的组成内容可能包括:
其实还可以加入日志分析、数据分析等,只是上面几个最广为人知而已。
就常见的互联网产品而言,它的瓶颈并非在后端业务的逻辑上,而是在 I/O 上,即返回给用户看的数据的读入与输出。相对于应用程序而言,读入指的是从数据库里获取数据,而输出指的是将这些数据经过一定的处理输出到用户的浏览器,那么这就是 I/O 密集型。
而 CPU 密集型是指做频繁计算任务的应用,Node.js 在这方面确实是短板。
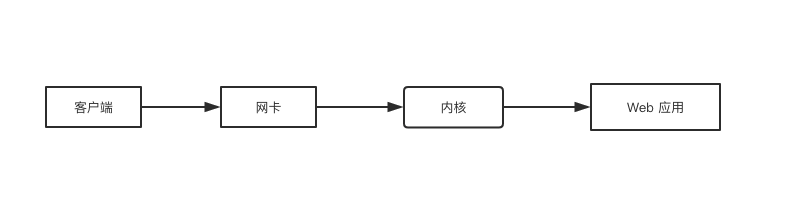
如图所示,用户通过浏览器发送请求,由网卡接收TCP 连接,通知内核,内核再去调用相对应的服务端程序。
Request 请求过程
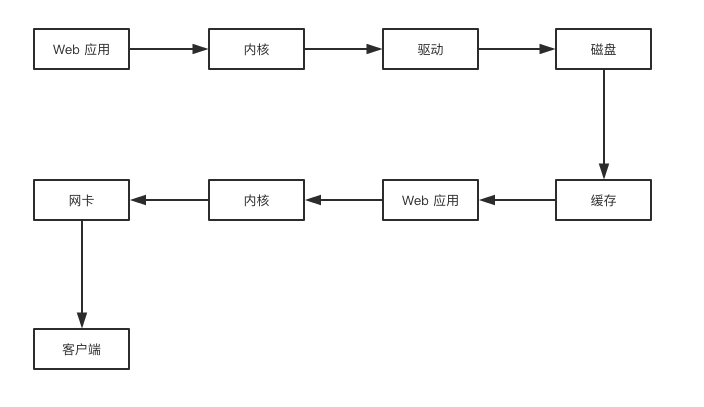
Response 返回过程
如下图,Web 应用要返回数据,首先要获取数据,通过内核调用磁盘的驱动程序,把数据读入缓存,这样就可以在 Web 应用程序中获取数据并进行数据处理,最终调用内核,将数据通过网卡发送给客户端。
通常 I/O 密集型的瓶颈会在磁盘的读写上,所以在购买云服务器的时候可以购买 SSD 的磁盘来提升性能,一般数据库软件的数据都是存储在文件上面的。首先考虑添加内存型缓存来解决这个瓶颈,缓存经常访问的数据,看能否解决当前场景的问题,比如使用 Redis。其次才考虑搭建或扩充数据库集群来提高并发。
而 CPU 密集型的应用瓶颈则在 CPU 上,只能增加 CPU 处理核心来解决瓶颈。
大型的普通应用与分布式应用其实是不同的概念。读者可以把分布式应用简单地理解为一个团队,每一个成员都是一个节点,一个大的项目要让成员合作完成,那么成员与成员之间就存在一些沟通成本,甚至有的成员与成员之间勾心斗角,说话阳奉阴违、推脱责任,也有可能成员生病在家休养,无法工作,等等。在面对这些问题的时候,Node.js 的优势并不能很好地显现出来(并非不可以做,只是没有完善的基础设施)。
分布式的真正定义是,在多台不同的服务器中部署不同的服务模块,以进程为基本单位,派发到服务器上,通过远程调用(RPC)通信并协同工作,最终对外提供服务。
相比较 Node.js目前的分布式基础设施,Go 语言的基础设施则完善多了,特别是在 Docker 这个项目上,充分证明了 Go 语言的优势,这也是为什么 Node.js 社区“大牛”TJ Holowaychuk 转向 Go 语言,因为他要开发分布式应用。
其实没必要过分地关心分布式的问题,毕竟 JavaScript 最初只是一个运行在浏览器端的脚本语言而已,JavaScript 不是万能的,为什么一定要把它用在操作系统级别的开发上呢?寻找一个更合适的语言不是更好吗?就像此刻我们选择 JavaScript 构建 Web 应用一样。
了解了以上的一些知识点,现在读者应该知道,Node.js 跟大型应用关系不大。大多数学习 Node.js 的开发者是前端开发者,所以对后端的基础知识并不了解,在网络上搜寻一些资料的时候发现 Node.js 只能利用单核,而又听说 TJ Holowaychuk 转向 Go 的阵营,所以有的开发者就产生了Node.js不适合开发大型应用的疑问。
Node.js 只能利用单核的问题已经被解决了,后面使用的 Egg.js 框架中的 Egg-Cluster 模块就利用多进程非常好地解决了这个问题。
本文选自《Node.js实战:使用Egg.js+Vue.js+Docker构建渐进式、可持续集成与交付应用》,作者yugo,电子工业出版社9月出版。了解详情请点击扩展链接。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号