黑马崛起:PostgreSQL的崭新力量
发表时间: 2018-02-01 17:37
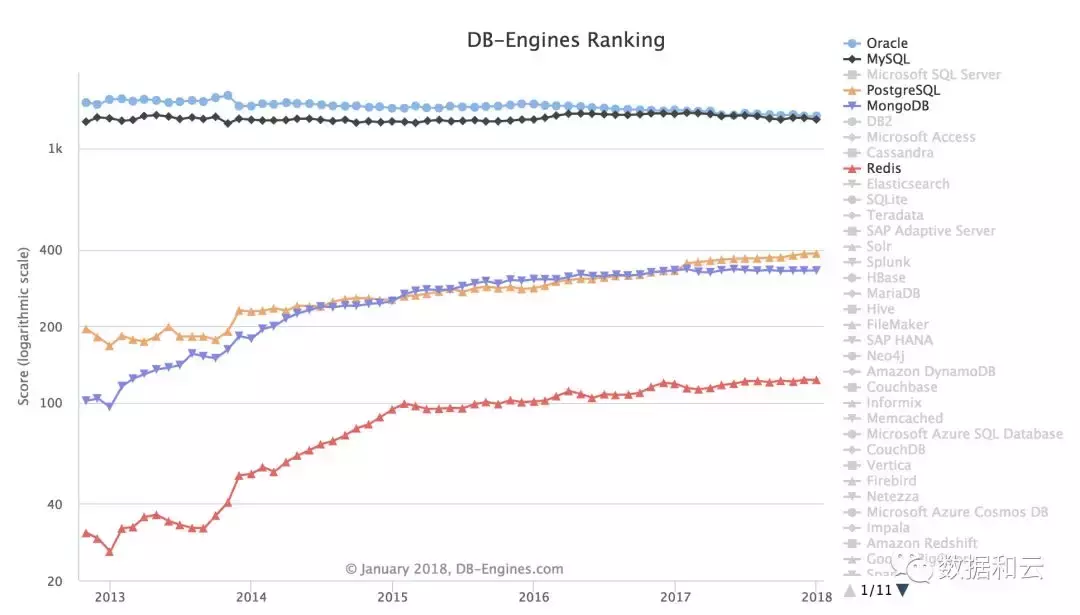
在2017年的DB-Engine的年度数据库榜单上,PostgreSQL以其超过其他341个受监控数据库管理系统的受欢迎程度居于榜首,被评为年度DBMS。其总体排名也超过MongoDB,在其流行程度上排名第四。
PostgreSQL是DB领域的一匹黑马,之前一直默默活在MySQL的阴影之下,今年随着 10.0版本的发布,Declarative Partitioning的引入,改进的查询并行性,逻辑复制和同步复制的Quorum Commit ,PostgreSQL 10 的影响力在不断的增强。
今天我们有幸邀请到了PostgreSQL的专家朱贤文老师,为我们分享PostgreSQL的核心技术、发展现状及未来方向。
遇见未来
DB舞台谁是王者之PostgreSQL专访
自我介绍,团队介绍
1.我是朱贤文,是成都文武信息技术有限公司的总经理、创始人。我入IT行业接近20年,主要熟悉数据库、存储和集群这些IT基础架构比较底层的技术;在这之前,曾在Oracle,Veritas,IBM等公司工作,做研发的经验主要在Oracle RAC和Storage和集群,涉及的技术比较底层。
我们是一个创业团队,现阶段不到20人,我们专注在PostgreSQL数据库的商业解决方案及和技术服务,产品和方案;比如集群、容灾、备份,咨询等。
我们有一套自研的专门用于数据库的高性能私有云系统,支持PostgreSQL和Oracle数据库高效可靠地运行。
2.作为PostgreSQL领域资深的专家,请您简单介绍下PostgreSQL技术的发展历程
实在不敢当专家的称号,我只是对PostgreSQL熟悉一点罢了。
PostgreSQL是一个非常先进的、有很多高级特征、企业级功能非常丰富的开源数据库,在金融、银行、电信、生产制造等行业有非常多的成功案例。
PostgreSQL的发展历程
PostgreSQL的前身是美国国防部与UC Berkeley大学合作的一个研究项目,叫Ingres,起源于1973年;1985年研究项目终止,随后开源,并且命名叫Postgre,随后又改名为Postgre95;1996年因为加入了完整的SQL92标准支持,为了强调对SQL的支持,所以更名为PostgreSQL,这个名字一直沿用到现在。到目前为止,其连续活跃的开发历史已超过32年,算上Ingres时期的开发历史,项目实际上接近45年连续开发。
PostgreSQL的发展,经历了几个重要的版本
从8.0开始,逐渐增加了众多的企业功能,包括写日志,表分区,物理同步复制,物理异步复制,逻辑复制,在线热备份,并行查询。
目前最新版本为10.1,完善了表分区和hash表功能。
PostgreSQL的特点
PostgreSQL数据库的跨平台特性非常强,支持几乎所有的操作系统和CPU硬件平台,如AIX,HPUX,Linux,BSD,Windows等。
PostgreSQL的开发是由社区驱动的,各种高级先进的特性主要来自于用户的反馈和需求;社区的成员来自于全球的商业公司,高校,研究机构等,开发和发行过程非常严谨,产品代码质量非常高。目前国内有很多公司基于PostgreSQL数据库开发自己的商业产品。
还有一些明显的特点包括:比如非常丰富的数据类型,丰富的开发接口和编程语言的支持,丰富的索引类型,很多的企业级高级特性等等,都能够满足绝大多数企业级应用的要求。
PostgreSQL的发展
PostgreSQL数据库的支持跟商业数据库一样,从6.3开始,每一个发行版本社区都会支持5年,这个传统从1998年开始,马上也进行了20年了。
从国内使用情况来看,现在PostgreSQL的影响力越来越强,越来越多的专业用户将PostgreSQL用在他们的业务系统中,比如中国平安,中国移动,联通,互联网包括去哪儿,腾讯,阿里。
从生态区和支持这个方面来说是越来越完善,现在有华为,腾讯,阿里以及我们成都文武信息在内的专业公司,对其提供商业支持和服务,并且基于它开发自己的高性能数据库。
在PostgreSQL 10版本中,您最关注的新特性和技术点包含哪些?或者您认为最重要的变化?3
PostgreSQL 10版本中,新的特性比较多,下面只列出部分,详细的部分可以参考官方Wiki:
https://wiki.postgresql.org/wiki/New_in_postgres_10
大数据处理:原生分区,并行执行,FDW下发/push-down,更快的查询支持;
复制和很横向扩张:逻辑复制,同步复制实现Quorum Commit-类Raft的部分功能,临时复制slots支持,连接层的failover和routing,加强的物理复制;
系统管理:pg_receivewal支持压缩,pg_stat_activity有了专门的后台处理进程等;
SQL功能:Identity Columns,Crash Safe,Replicable HashIndexes,Transition Tables for Triggers;
XML和JSON:支持XMLTable,JSON和JSONB的全文搜索
4.PostgreSQL 的最佳应用场景是什么?有哪些比较成功的案例实践?目前市场需求如何?
个人认为PostgreSQL适合对性能、可靠性、业务连续性要求非常高的企业级OLTP应用,以及小规模OLAP应用,比如数据量小于50T的OLAP系统。
现在国内可以参考的案例还是非常多,比如平安集团有1500多个实例部署;乐友母婴用品店,核心的数据库系统是一个接近10T的PostgreSQL在线数据库支撑全国的业务;除此外,还有探探、去哪儿网、百度地图等,都有很大的PostgreSQL部署量,高效可靠地支撑业务系统;还有一些传统行业,如浙江移动,湖北移动,中国联通等。
根据我知道的信息,市场对PostgreSQL数据库的需求一直都是高速增长的,增长的量主要集中在两个方面:
一方面是新建的对可靠性、业务连续性要求高的OLTP系统,越来越多的用户将PostgreSQL作为优先选择的数据库;
另一方面是数据量小于50T的小型OLAP业务系统,很多用于会优先选择PostgreSQL作为分析引擎。
这种需求最近一两年表现尤为明显。
5.您是否可以简单介绍下互联网模式下,PostgreSQL 数据库的高可用架构有哪几种模式?
第一种跟其它数据库的高可用架构基本上一样,就是采用共享存储模式,数据库存放在共享存储上;一台主机,一台备机;正常情况下,主机连接存储启动数据库对外提供服务;当主机故障,备机接管存储,并且启动数据库,继续对外提供服务;这种架构的好处就是数据是专门的存储提供保护,不用担心丢失,切换服务的时间需要集群管理软件决定,一般来说基本中就可以完成切换;
第二种是基于流复制的高可用架构,这里面有几个发展的阶段,
(1)第一个阶段是基于对PostgreSQL WAL日志文件的复制,这个方式目前基本上很少用了;大致的工作原理是集群内一个主库一个备库,当WAL日志归档后,这个文件同时拷贝到备库;备库始终处于恢复状态,接收到主机拷贝过来的WAL日志文件,立即恢复到备机;当主机宕机,备库立即切换模式,恢复成主库对外服务;
(2)第二个阶段是物理复制—--流复制,主库正常工作,所有提交的事务除了写在本地的WAL日志文件,同时还会将数据通过网络传输到备库。通过控制对网络上数据传输时间的确认,可以分为异步复制和同步复制,这两种复制方式会涉及SLA定义的RTO和RPO等指标,同时也涉及到系统性能。
(3)目前的阶段是物理流复制方式比较丰富的阶段。在以前的复制方式上,对同步复制的控制手段很少;现阶段不仅可以控制集群内有多少台同步复制,而且可以控制数据提交成功的确认方式,例如在多少个同步复制节点提交成功、以什么样的方式在同步节点上提交成功,first n, any n等比较细粒度的控制复制成功时确认信息的行为;同时也可以比较细粒度地控制复制过程中的性能,比如发送到备库的buffer确认,还是备库写入wal确认,还是备库需要replay确认等……
第三种是逻辑复制。逻辑复制的好处比较多,比如可以跨平台跨操作系统,可以控制需要复制的表而不是整个库进行部分数据的复制,比如用于OLAP分析系统的数据同步;也可以用于做不停机的业务系统升级。
另外说一点就是PostgreSQL可用的高可用方案比较丰富,有开源的方案比如pgpool,也有一些商业的解决方案,比如我们公司的ECOX系统。客户在设计和选用高可用方案的时候,严谨的生产系统最好要购买专业的服务。我们是国内比较好的服务团队并且能提供完整的解决方案跟相关技术。
6.请您介绍一下PostgreSQL中目前比较成熟并且流行的存储引擎和他们的使用场景吗?
PostgreSQL不像MySQL数据库那样有很多存储引擎。PostgreSQL只有一种存储引擎,对事务处理非常严谨严肃,主要用于高性能的OLTP业务场景。同时也可以用于小型的OLAP分析型业务场景。
7.PostgreSQL数据库在向着自动化运维的方向发展的过程中,面临的最大的挑战是什么?如何克服?
PostgreSQL数据库,不像我们常用的Oracle数据库,如果参数设置得当,应用设计也比较好,这种情况下其实不需要太多的维护;
对于PostgreSQL来说,反而是需要将精力放在存储子系统的可靠性,备份等方面。
存储子系统的可靠性需要仔细地设计,因为它不仅关乎系统性能,也关乎数据本身存放的可靠性。如果是严谨的商业应用,建议优先选用可靠的存储系统和文件系统;我们作为有丰富实施经验的专业厂商,我们会推荐用户优先选用ZFS,特别是原生的ZFS,这个领域我们有完整的方案。
8.PostgreSQL数据库与其他开源数据库相比较的优势
相对于其它数据库而言,PostgreSQL的优势是非常明显的,比如:
有庞大的潜在的开发群体、运维群体和完整的生态;因为Oracle的生态系统非常完善和成熟,熟悉Oracle技能的人迁移到PostgreSQL数据库上的学习曲线非常平滑,成本非常低。根据我自己的经验,基本上2周时间可成。
有大量的银行、电信、保险、政府等行业的关键业务应用案例和知名客户。
有丰富的开发接口和开发语言支持,丰富的数据类型,支持传统的关系型数据和非关系型数据。对GIS非常好,对JSON,JSONB,XMLTable支持非常好。
非常丰富的fdw扩展,几乎可以支持所有的外部数据源和数据库。
非常先进的企业级特性,比如复制,分区,在线热备份,非常丰富的索引、函数等。
非常优秀的跨平台、跨操作系统支持。支持几乎所有的硬件平台和操作系统。大到mainframe,小到嵌入式系统。
高品质的代码,优雅的设计,非常长时间的、持续活跃的开发历史。
每个发行版本都能获得为期5年的产品支持。
当然也有需要完善的地方,比如:
宣传不到位,现在还有很多用户不清楚、甚至不知道PostgreSQL是一个生么样的数据库。(这一点会导致用户选用技术线路失误,从而导致后面的应用系统开发和维护成本很高。)所以应该加强PostgreSQL数据库的培训和宣传。
国内从事PostgreSQL的服务商比较少,高质量的专业服务商更少。
技术上目前还不支持块级别的增量备份和恢复(这个功能已经在线路图上,很快会有)
9.可以请您谈一下对 OceanBase数据库的认识和看法吗?
OceanBase是一个非常有特点的数据库,全新的设计,也在高性能,高可靠性方面有比较好的表现,17年双11表现的每秒处理26万多笔交易的威力(性能)大家也见识过了。
OceanBase的主从数据库
在传统的数据库主从架构中,比如(Active)DataGuard,主库对外提供全功能的读写服务,从库对外提供只读服务,主库到从库通过流复制技术使数据保持同步;
在OceanBase中,也有主和从的概念,复制也是主到从,与传统数据库不一样的是这个数据库的主、从概念是建立在分区表的分区上,每个表有多个分区,所有节点都可以有全部或者部分分区,分区有多个副本,分布在集群内的其它节点上,副本可以看作是是从,只接收主上面的日志,并且回放到内存里,一个可以读写的分区就是一个主;一个主可以有多从,确保数据有多份拷贝,主到从的日志传输通过Paxos协议完成,确保数据可以正确传输到其它节点;
整个集群对外来看,所有节点都是读写的、全功能的,比传统数据库优势明显,因为多活,负载均衡可以实现比较好,可以用低廉的硬件实现高性能、高可靠的系统;
仔细观察集群内部,由很多表的不同分区及它们的副本构成非常多的主从复制,所有的日志数据复制基于Paxso协议,能够保证任何节点损坏都不会有数据丢失的危险(当然节点坏掉的个数不能大于节点总数的一半)。
OceanBase另外一个比较有意思的设计就是类似于传统数据库中的check_point的处理,传统数据库的check_point时间根据负载和SLA的一些要求,一般保持在几分钟到半个小时之间,数据库要做一次check_point,以确保数据库的数据一致性;而OceanBase数据库把传统数据库类似check_point功能的操作周期做得非常长,比如一天做一次数据整合(类似于传统数据库的check_point操作);这样做有好处,就是对SSD这种新型电子磁盘的寿命有帮助,因为对SSD的操作都是大片大片的、整块地删除、写入,尽量避免SSD内部的写放大,这个设计的前提是基于服务器有非常大的内存配置,比如256G、甚至1T,现在的机器内存配置都比较大,很容易配置大内存的集群,那么把数据库的data buffer做到足够大,数据库所有的操作都在内存里,相当于一个准内存数据库,比操作磁盘的IO要快很多;通过这些设计,非常合理地避免了全分布式、高可靠、高性能并发和mvcc之间的矛盾。
OceanBase的设计非常聪明,它的出现的确给了我耳目一新的感觉,不管是技术上的创新,架构上的创新,技术来源,都是值得大大地给一个赞,说到技术创新、架构创新,我们的鸿鹄彩云系统就是为高性能数据库业务设计的,里面也有很多可以让人感觉耳目一新的技术创新的点,希望更多的人可以尝试试用;
当然一个新事物的出现需要一个时间完善和成长/成熟的过程,对于OceanBase来说目前也需要有完善的地方,比如技术上与现有的用的广泛的Oracle的兼容性,跨库交易等,关键行业的成功的应用案例等,让我们多给它一些时间,多给一些耐心;(当然我对OceanBase的了解也比较有限,可能有很多技术特点没有讲到,请包涵)
10.近几年随着大数据时代的到来,NoSQL数据库在处理海量数据上表现出越来越多的优势,请问您如何看待数据库的未来,会朝着什么样的方向发展?
从数据本身来说,真实世界里生产的95%以上的数据都是关系型的,只有很少的数据是非关系型的。
所谓的NoSQL是Google在很多年提出来的处理大数据的一个技术方案,主要使用的思想就是Map/Reduce,学过数据库的人都应该了解,这项技术实际上在上个世纪60年代,在大型机上处理大量计算常用的技术思想。
Google最终推出了自己的Spanner数据库,结果是非常明显的,Google自己都不用NoSQL,而回到传统的SQL这个线路上面来,所以未来还会向SQL这个方向走。
11.PostgreSQL数据库未来将会如何演变,如何应对海量数据的实时处理需求?
PostgreSQL未来还是会持续、活跃地开发高品质的软件,并且根据市场需要提供满足市场的技术特性;国内的市场也会普及和成熟,用户也会接纳并且广泛地使用PostgreSQL数据库、并且从中受益。
应对海量数据的实施处理,可以选用高性能硬件,MPP架构的技术;以后也会有基于内存的MPP,甚至用GPU加速运算的数据库;但是最终还是需要看用户本身的需求和业务特点,根据这些进行有针对性的设计和实施,以满足这类需求。
End.
来源:数据和云
运行人员:中国统计网小编
中国统计网,是国内最早的大数据学习网站
//www.itongji.cn
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号