揭秘Meta最强开源模型Llama 3.1的突破之处
发表时间: 2024-07-24 08:22
北京时间7月23日晚,Meta 正式发布最新的开源大模型Llama 3.1系列,进一步缩小了开源模型与闭源模型的差距。Llama 3.1包含8B、70B和450B 3个参数规模,其中450B参数的模型在多项基准测试中超过了OpenAI的GPT-4o,与Claude 3.5 Sonnet 等领先的闭源模型相媲美。

Meta 创始人CEO 扎克伯格同一时间在官网发布一篇博客为这次发布造势,他表示,Llama 3.1 版本将成为行业的一个转折点,大多数开发人员将开始主要使用开源,开源AI是未来的发展方向。
英伟达高级研究科学家Jim Fan在X上发文祝贺Meta团队,他提到,“GPT-4的力量就在我们手中,(这是)一个真正具有历史意义的时刻。”
在具体细节上,Llama 3.1三个版本的模型上下文窗口都从 8k 增加到了 128K,扩大 16 倍,同时支持8种语言。其中Llama 3.1 -405B模型使用了超过15万亿个tokens进行训练,并且为了能达到这一训练规模,团队使用了1.6万块H100 的GPU。官方表示,405B模型是第一个以这种规模训练的 Llama 模型。
开源大型语言模型在功能和性能方面大多落后于闭源模型,“但现在,我们正迎来一个由开源引领的新时代。”
官方博客中,Meta 评估了超过了 150 个基准数据集的性能,比较了 Llama 3.1 与其他模型的能力表现,旗舰模型 Llama 3.1 -405B 在常识、可操作性、数学等一系列任务中可与GPT-4、GPT-4o 和 Claude 3.5 Sonnet 相媲美。此外,8B 和 70B 小型模型与具有相似数量参数的闭源和开源模型具有竞争力。
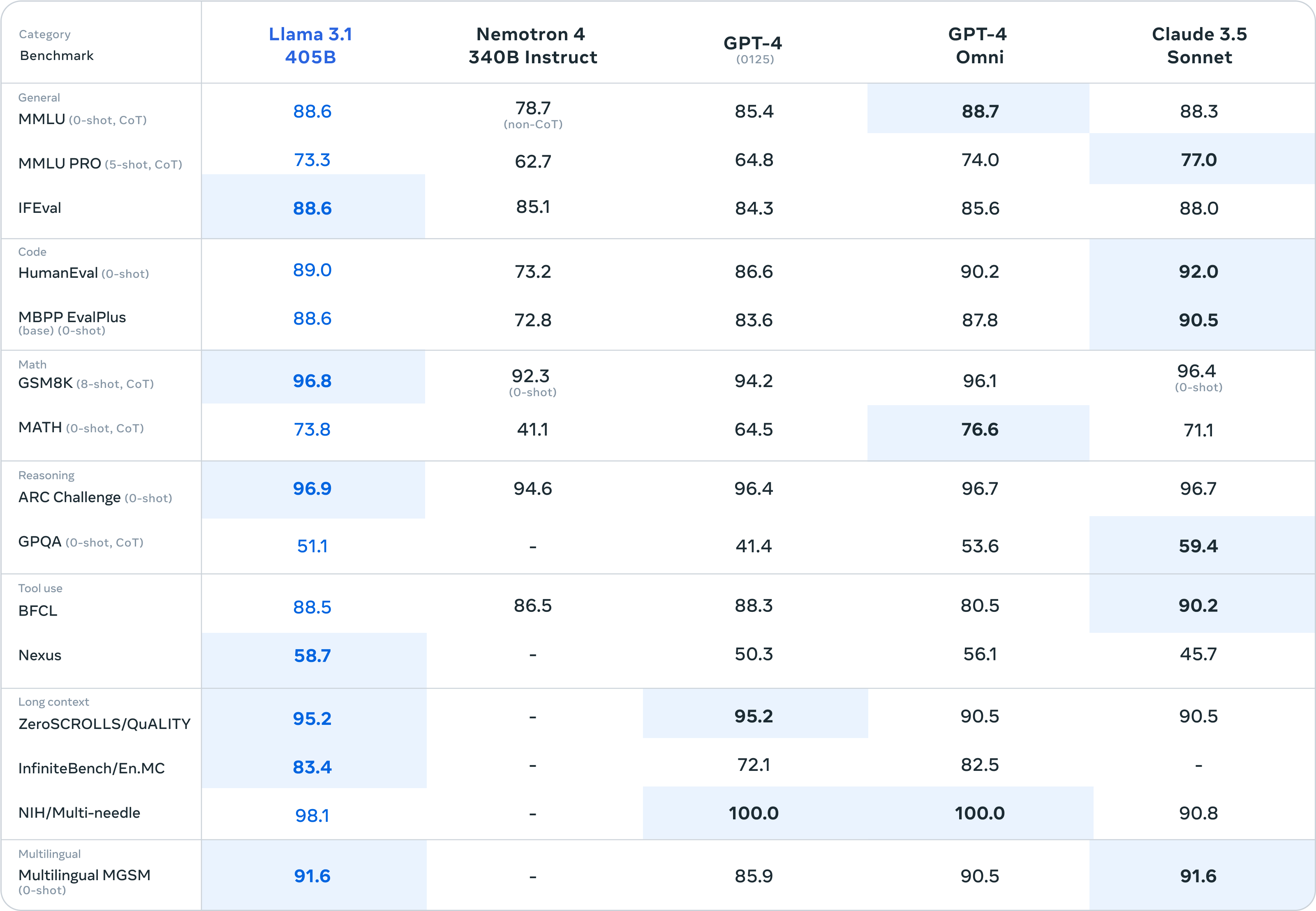
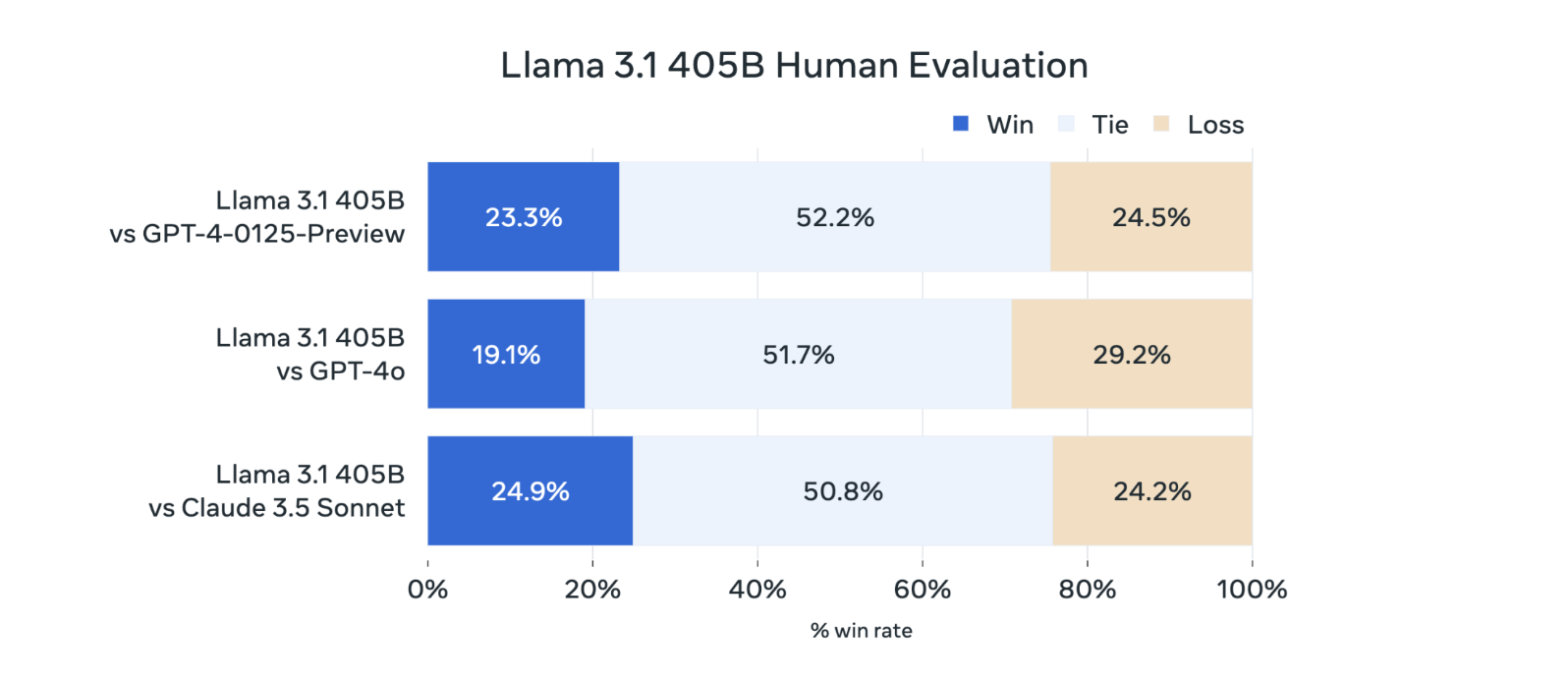
在现实场景中,Llama 3.1 405B进行了与人工评估的比较,其总体表现优于GPT-4o和Claude 3.5 Sonnet。
此次Meta还更新了开源许可,允许开发者首次使用 Llama 模型(包括 405B)的输出来改进其他模型。对标GPT-4o,官方称,他们也会采用组合方式将图像、视频和语音功能整合到 Llama 3 中,使模型能够识别图像和视频,并通过语音支持交互。但目前这一功能仍在开发中,尚未准备好发布。
在官方博客中,Meta 表示,目前为止所有 Llama 版本的总下载量已超过 3 亿次。
除了此次模型发布外,扎克伯格同时在官网发布了长文《Open Source AI Is the Path Forward》,其中提到了开源的重要性,他认为开源对所有开发者、对Meta以及对世界都是好事。

扎克伯格以开源系统Linux战胜闭源系统 Unix为例,认为人工智能会以类似的方式发展。“有几家科技公司正在开发领先的封闭模型,但开源很快在缩小差距。”他提到,去年,Llama 2只能与旧一代模型相提并论。而今年,Llama 3 在一些领域具有竞争力,甚至在某些方面领先于最先进的模型。
扎克伯格认为,开源能促进创新、降低成本、提高安全性。对开发者来说,利用开源可以训练、微调和蒸馏自己的模型,每个组织都有不同的需求,最好使用不同尺寸的模型来满足这些需求,而这些模型是通过特定数据进行训练或微调的。
同时,开发者可以不被锁定在封闭供应商中,保护数据安全。“开源软件往往更安全,因为它的开发更加透明,可以被广泛审查。”扎克伯格认为。
扎克伯格同时提到,开源模型的成本更低且效率高,开发者可以在他们自己的基础设施上运行 Llama 3.1 405B 上的推理,成本大约是使用像 GPT-4o 这样的封闭模型的50%,适用于用户界面和离线推理任务。
“开源人工智能代表着世界最好的机会。”在扎克伯格看来,利用这项技术可以创造最大的经济机会和安全保障。
(本文来自第一财经)
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号