OpenAI GPT技术:自我修复Bug的革命性突破
发表时间: 2024-06-28 18:33
当 ChatGPT 横空出世之后,许多人都在讨论 AI 是否要取代程序员,技术的终点究竟会在哪里?
此前我曾与一些软件工程的专家讨论过这个话题,大家提出技术的终点将在于 GPT 是否会有自我进化的能力。
万万没想到,突然就这么来了。
北京时间 6 月 28 日凌晨,紧随 Google 正式发布 Gemma 2 之后,OpenAI 推出了一款基于 GPT-4 的模型——CriticGPT,旨在帮助人类评估和检测大型语言模型(LLM)生成的代码输出中的错误。CriticGPT 通过训练生成自然语言反馈,可以指出代码中的问题,并且在检测自然发生的 LLM 错误时,其生成的评审比人类评审更受欢迎,准确率达到63%。
一句话总结就是,OpenAI 实现了让 GPT-4 给 GPT-4 自己改 Bug,许多时候效果比人类还好。
经过 OpenAI 实测发现,当人们使用 CriticGPT 来审查 ChatGPT 的代码时,他们的表现比没有帮助时高出 60%。OpenAI 表示,“我们正在将类似 CriticGPT 的模型集成到我们的 RLHF 标注流程中,为我们的训练师提供明确的 AI 帮助。这是朝着能够评估高级 AI 系统输出迈出的一步,这些系统的输出对于没有更好工具的人来说可能很难评估。”
CriticGPT 因何而来?
据 OpenAI 官方表示,由于随着 OpenAI 在推理和模型行为方面的进步,ChatGPT 变得更加准确,其错误也变得更加微妙。这使得 AI 训练师在错误发生时更难发现不准确之处,从而使推动 RLHF 的比较任务变得更加困难。这是 RLHF 的一个基本限制,可能会使模型逐渐变得比任何能够提供反馈的人更具知识性,因而更难对齐模型。
为了解决这个挑战,OpenAI 训练了 CriticGPT 来撰写批评,突出 ChatGPT 回答中的不准确之处。
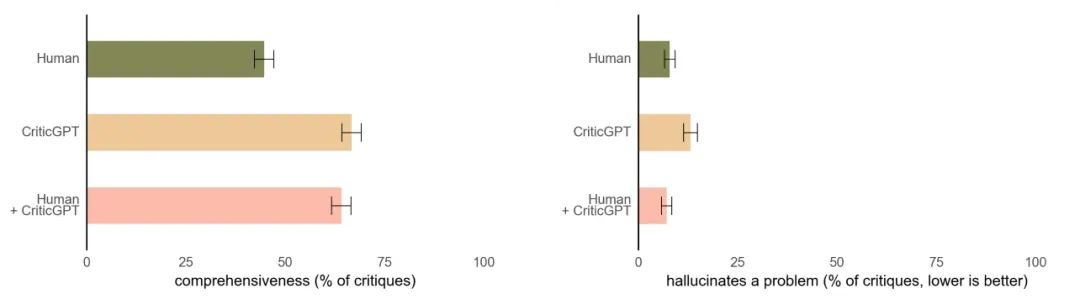
CriticGPT 的建议并不总是正确的,但它们可以帮助训练师发现比没有 AI 帮助时更多的模型回答问题。此外,当人们使用 CriticGPT 时,AI 会增强他们的技能,导致比人们单独工作时更全面的批评,并且比模型单独工作时产生更少的虚构错误。在 OpenAI 的实验中,第二个随机训练师在 60% 以上的时间里更喜欢 Human+CriticGPT 团队的批评,而不是没有辅助的人。
CriticGPT 帮助训练师撰写比没有帮助时更全面的批评,同时产生比模型单独批评时更少的虚构问题。
CriticGPT 背后的实现方法
CriticGPT 也通过 RLHF 训练,类似于 ChatGPT。但与 ChatGPT 不同的是,它看到大量包含错误的输入,然后需要对这些输入进行批评。OpenAI 要求 AI 训练师手动将这些错误插入到 ChatGPT 编写的代码中,然后撰写示例反馈,就像他们刚刚发现了他们自己插入的错误一样。然后同一个人比较多种修改后代码的批评,以便他们能轻易判断批评是否抓住了他们插入的错误。
OpenAI 研究了 CriticGPT 是否能够发现插入的错误和先前训练师发现的“自然发生”的 ChatGPT 错误。发现在 63% 的情况下,训练师更喜欢 CriticGPT 对自然发生错误的批评,部分原因是新的批评模型产生的“吹毛求疵”(无用的小抱怨)更少,并且较少虚构问题。
同时,OpenAI 还发现,通过使用额外的测试时搜索与批评奖励模型进行对比,可以生成更长和更全面的批评。这个搜索程序使得能够平衡在代码中查找问题的力度,并在虚构问题和发现的错误数量之间进行精度-召回权衡。这意味着可以生成尽可能对 RLHF 有帮助的批评。
CriticGPT 的局限
首先,依然是模型相对共性的问题。据 OpenAI 官方披露,他们在回答相对简短的 ChatGPT 答案上训练了 CriticGPT。为了监督未来的代理,还需要开发方法来帮助训练师理解长而复杂的任务。
其次依然是幻觉的问题。模型仍然会虚构,有时训练师在看到这些虚构时会犯标注错误。
此外,有时真实世界的错误可能分布在答案的许多部分,未来还需要解决分散的错误。
最后,当前 CriticGPT 的帮助还是有限的:如果任务或回答极其复杂,即使是专家在模型的帮助下也可能无法正确评估。
由 CSDN 和 Boolan 联合主办的「2024 全球软件研发技术大会(SDCon)」将于 7 月 4 -5 日在北京威斯汀酒店举行。
由世界著名软件架构大师、云原生和微服务领域技术先驱 Chris Richardson 和 MIT 计算机与 AI 实验室(CSAIL)副主任,ACM Fellow Daniel Jackson 领衔,华为、BAT、微软、字节跳动、京东等技术专家将齐聚一堂,共同探讨软件开发的最前沿趋势与技术实践。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12






 鲁公网安备37020202000738号
鲁公网安备37020202000738号