C++ 20版本未发布,就已经结束?
发表时间: 2019-01-14 10:28
一个月前,C++ 标准委会于美国 San Diego 举办了有史以来规模最大的一次会议(180 人参会),特地讨论了 C++ 新标准即
C++ 20
将确认添加以及有可能添加的特性。
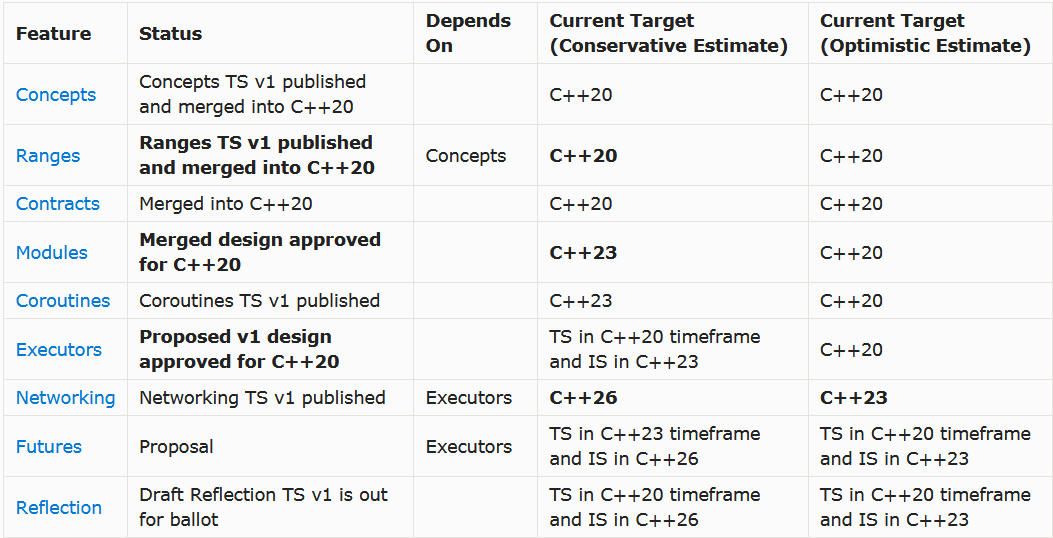
而如今距离 C++ 20 标准的正式发布不足一个月,C++ 20 却惨遭国内外开发者嫌弃。对此,更有一位来自国外的游戏开发者通过使用毕达哥拉斯三元数组示例发万字长文批判新版本的到来并没有解决最关键的技术问题。这到底是怎么一回事?接下来,我们将一窥究竟。

作者 | Aras Pranckevičius
译者 | 苏本如
责编 | 屠敏
出品 | CSDN(ID:CSDNNews)
以下为译文:
首先声明,本文较长,但我想表达的主要观点是:
Facebook工程师、Microsoft Visual C++开发者Eric Niebler在他的博文”Standard Range”(
http://ericniebler.com/2018/12/05/standard-ranges/)介绍了C++ 20的Range特性在最近的Twitter游戏开发的各种应用,很多地方都表达了对于Modern C++现状的“不喜欢”。
我也在这里表达了类似的看法:
使用C++ 20 Range和其他特性来计算毕达哥拉斯三元组的例子听起来很可怕。是的,我明白Range在这里是有用的,结果也是对的……。但是,这仍然是一个可怕的例子!没有人想要这样的代码?!
感觉有点失控了。这里我要为引用Eric的博文向他道歉,我的悲观看法大部分是基于最近的C++的现状,Twitter上的“Bunch of angry gamedev”已经采用了Boost库,Geometry rationale也同样这样做了,同样的事情发生在C++生态系统中也有十几次。
但你知道,Twitter上无法表达太多细节,所以我在这里展开一下!
使用C++20 Ranges来计算毕达哥拉斯三元数组
这里是Eric的博文里的完整例子:
// A sample standard C++20 program that prints// the first N Pythagorean triples.#include <iostream>#include <optional>#include <ranges> // New header!using namespace std;// maybe_view defines a view over zero or one// objects.template<Semiregular T>struct maybe_view : view_interface<maybe_view<T>> { maybe_view() = default; maybe_view(T t) : data_(std::move(t)) { } T const *begin() const noexcept { return data_ ? &*data_ : nullptr; } T const *end() const noexcept { return data_ ? &*data_ + 1 : nullptr; }private: optional<T> data_{};};// "for_each" creates a new view by applying a// transformation to each element in an input// range, and flattening the resulting range of// ranges.// (This uses one syntax for constrained lambdas// in C++20.)inline constexpr auto for_each = []<Range R, Iterator I = iterator_t<R>, IndirectUnaryInvocable<I> Fun>(R&& r, Fun fun) requires Range<indirect_result_t<Fun, I>> { return std::forward<R>(r) | view::transform(std::move(fun)) | view::join; };// "yield_if" takes a bool and a value and// returns a view of zero or one elements.inline constexpr auto yield_if = []<Semiregular T>(bool b, T x) { return b ? maybe_view{std::move(x)} : maybe_view<T>{}; };int main() { // Define an infinite range of all the // Pythagorean triples: using view::iota; auto triples = for_each(iota(1), [](int z) { return for_each(iota(1, z+1), [=](int x) { return for_each(iota(x, z+1), [=](int y) { return yield_if(x*x + y*y == z*z, make_tuple(x, y, z)); }); }); }); // Display the first 10 triples for(auto triple : triples | view::take(10)) { cout << '(' << get<0>(triple) << ',' << get<1>(triple) << ',' << get<2>(triple) << ')' << '\n'; }}Eric的这篇博文可以追溯到他几年前发的另一篇博文(
http://ericniebler.com/2014/04/27/range-comprehensions/),这是对Bartosz Milewski写的这篇博文“Getting Lazy with C++”(
https://bartoszmilewski.com/2014/04/21/getting-lazy-with-c/)的回应,Eric在那篇博文给出了用一个简单C函数来打印出前N个毕达哥拉斯三元数组的例子:
void printNTriples(int n){ int i = 0; for (int z = 1; ; ++z) for (int x = 1; x <= z; ++x) for (int y = x; y <= z; ++y) if (x*x + y*y == z*z) { printf("%d, %d, %d\n", x, y, z); if (++i == n) return; }}从这个示例代码可以看出一些问题:
这段代码看起来没有问题,如果您不需要修改它或重用它的话。但是如果你想对它做更多的事问题就出来了,比如你不仅仅想打印出这些三元数组,而且想基于这些三元数组画一些三角形呢?或者如果你想在其中一个数字达到100时立即停止计算呢?
列表解析(list Comprehension)和延后计算(lazy evaluation)似乎可以作为解决这些问题的方法。事实上,它根本解决不了这些问题,因为C++语言不具备像Haskell或其他语言那样的内置功能。C++ 20在这方面会有更多内置的东西,如Eric的博文指出的内容。这部分容我稍后再谈。
使用Simple C++来计算毕达哥拉斯三元数组
所以,让我们回到简单的(正如Bartosz所说的“只要你不需要修改或重用”)C/C++方式解决这个问题。下面是一个完整的程序用来打印前100个毕达哥拉斯三元数组:
// simplest.cpp#include <time.h>#include <stdio.h>int main(){ clock_t t0 = clock(); int i = 0; for (int z = 1; ; ++z) for (int x = 1; x <= z; ++x) for (int y = x; y <= z; ++y) if (x*x + y*y == z*z) { printf("(%i,%i,%i)\n", x, y, z); if (++i == 100) goto done; } done: clock_t t1 = clock(); printf("%ims\n", (int)(t1-t0)*1000/CLOCKS_PER_SEC); return 0;}我们可以编译它:clang simpest.cpp-o outsimpest。编译需要0.064秒,生成8480字节的可执行文件,该文件在2毫秒内运行并打印数字(使用的机器为2018产的 MacBookPro;Core i9 2.9GHz CPU;xcode 10 clang):
(3,4,5)(6,8,10)(5,12,13)(9,12,15)(8,15,17)(12,16,20)(7,24,25)(15,20,25)(10,24,26)...(65,156,169)(119,120,169)(26,168,170)
但是等等!这是一个默认的非优化(“debug”)build;让我们用这个命令来做一次优化(“release”)build:clang simplest.cpp -o outsimplest -O2。它需要0.071进行编译,生成相同大小(8480b)的可执行文件,并在0毫秒内运行(在clock()的计时器精度内)。
正如Bartosz指出的那样,这里的算法不是“可重用的”,因为它将处理过程和输出结果混杂在一起了。这是不是一个问题不在本文的讨论范围之内(我个人认为,“可重用性”或“不惜一切代价避免重复”都被高估了)。让我们假设这是一个问题,事实上,我们想要的是一个只返回前n个三元数组的“东西”,而不需要对它们做任何额外操作。
我可能会写的是一段最简单的代码 - 调用它,返回下一个三元数组 - 看起来像下面这样:
// simple-reusable.cpp#include <time.h>#include <stdio.h>struct pytriples{ pytriples() : x(1), y(1), z(1) {} void next() { do { if (y <= z) ++y; else { if (x <= z) ++x; else { x = 1; ++z; } y = x; } } while (x*x + y*y != z*z); } int x, y, z;};int main(){ clock_t t0 = clock(); pytriples py; for (int c = 0; c < 100; ++c) { py.next(); printf("(%i,%i,%i)\n", py.x, py.y, py.z); } clock_t t1 = clock(); printf("%ims\n", (int)(t1-t0)*1000/CLOCKS_PER_SEC); return 0;}上面这段代码在几乎相同的时间编译和运行;Debug版本的可执行文件将变大168字节;Release版本的可执行文件大小不变。
这里我定义了一个名为pytriples的结构体(struct pytriples),通过对它的next()函数的每次调用都会得到下一个有效的三元数组;调用方可以对返回结果做任意处理。在这里,我只是调用了100次next()函数,然后将每次返回的三元数组打印出来。
然而,上段代码在功能上实现了原始示例中的三重嵌套for循环所做的工作。但事实上,它变得不那么清晰了,至少对我来说是这样,虽然我很清楚在一些分支和对整数的简单操作上它是如何做到的,但是搞不清在更高层次上它是怎么做的。
如果C++有一个类似“coroutine”的概念,那么它有可能将三元数组生成器的代码变得与原始嵌套for循环一样清晰,这样实现没有任何“问题”,就像Jason Meisel在博文“Ranges, Code Quality, and the Future of C++”指出的那样。代码看起来是这样的(它只是假设的写法,因为coroutines不是任何C++ 标准的一部分):
generator<std::tuple<int,int,int>> pytriples(){ for (int z = 1; ; ++z) for (int x = 1; x <= z; ++x) for (int y = x; y <= z; ++y) if (x*x + y*y == z*z) co_yield std::make_tuple(x, y, z);}回到C++ Ranges
用C++ 20的Ranges来实现三元数组的写法会更清楚吗?让我们再看看Eric的博文,这是代码的主要部分:
auto triples = for_each(iota(1), [](int z) { return for_each(iota(1, z+1), [=](int x) { return for_each(iota(x, z+1), [=](int y) { return yield_if(x*x + y*y == z*z, make_tuple(x, y, z)); }); }); });两种方式都有争议。我认为上面的“coroutines”方法更清晰。使用C++的Lambda表达式,或者使用看起来更聪明些的标准C++方式,都有些累赘。如果读者习惯了命令式编程风格,那么多个Return返回就显得不常见了,但可能有人会习惯它。
也许你可以眯起眼睛说这是一个可以接受的好的写法。
但是,我不相信像我们一样的没有C++博士学位的凡人能够写出下面的实用工具供上面代码使用:
template<Semiregular T>struct maybe_view : view_interface<maybe_view<T>> { maybe_view() = default; maybe_view(T t) : data_(std::move(t)) { } T const *begin() const noexcept { return data_ ? &*data_ : nullptr; } T const *end() const noexcept { return data_ ? &*data_ + 1 : nullptr; }private: optional<T> data_{};};inline constexpr auto for_each = []<Range R, Iterator I = iterator_t<R>, IndirectUnaryInvocable<I> Fun>(R&& r, Fun fun) requires Range<indirect_result_t<Fun, I>> { return std::forward<R>(r) | view::transform(std::move(fun)) | view::join; };inline constexpr auto yield_if = []<Semiregular T>(bool b, T x) { return b ? maybe_view{std::move(x)} : maybe_view<T>{}; };也许上面代码对某些人来说就像母语那样易读,但对我来言,感觉就像有人告诉我“Perl的可读性太好,而Brainfuck的可读性太不好了,让我们平衡一下吧”。但是我还是觉得很难读,尽管我用C++编程已经20年了,可能是我太蠢吧。
是的,这里的maybe_view, for_each, yield_if都是“可重用组件”,这些组件可以移到一个库中。 接下来我就要讨论这个问题。
C++的“一切都是Library”带来的问题
问题至少有两个:1)编译时间;2)非优化的运行时性能。
我还是以同样的毕达哥拉斯三元数组的例子为例,这些问题对于C++的许多其他特性也存在,因为它们也是作为Library的一部分来实现的。
实际上C++ 20还没有发布,我用了当前最接近C++20 Range的Range-v3(Eric Niebler自己写的),来实现标准的“毕达哥拉斯三元数组”,并做了快速编译测试。代码如下:
// ranges.cpp#include <time.h>#include <stdio.h>#include <range/v3/all.hpp>using namespace ranges;int main(){ clock_t t0 = clock(); auto triples = view::for_each(view::ints(1), [](int z) { return view::for_each(view::ints(1, z + 1), [=](int x) { return view::for_each(view::ints(x, z + 1), [=](int y) { return yield_if(x * x + y * y == z * z, std::make_tuple(x, y, z)); }); }); }); RANGES_FOR(auto triple, triples | view::take(100)) { printf("(%i,%i,%i)\n", std::get<0>(triple), std::get<1>(triple), std::get<2>(triple)); } clock_t t1 = clock(); printf("%ims\n", (int)(t1-t0)*1000/CLOCKS_PER_SEC); return 0;}使用命令:clang ranges.cpp -I. -std=c++17 -lc++ -o outranges 来编译版本为post-0.4.0 version (9232b449e44 on 2018 Dec 22)的代码。结果如下:
是的,以上是一个非优化的build的测试结果。优化的build的结果如下:
可以看出,runtime性能提升,可执行文件变小,但编译时间的问题不变。
下面再继续展开:
编译时间是C++的一个大问题
这个简单示例的编译时间比“Simple C++”版本 多耗时2.85秒。
千万不要认为“少于3秒”是一个很短的时间 - 这绝对不是。在3秒钟内,一个现代的CPU可以完成天文数量的操作。例如,一个完整的实际数据库引擎(SQlite)拥有22万行代码, 用clang命令做debug build,在我的机器上编译时间是0.9秒。你能想象编译微不足道的5行示例代码竟然比编译一个完整数据库引擎要慢三倍吗?!
只要我的编程工作用到的的代码库不是太小,C++编译时间就是我的一个痛苦来源。如果你不相信,你可以试着编译一个广泛使用的大代码库(如:Chromium,Clang/LLVM,UE4等等)看看需要多少时间。在我真正希望C++能解决的问题,“解决编译时间”可能位列第一,这个次序一直都是。然而,似乎C++社区并不认为这是个问题,每次版本的更新会把更多的东西放到头文件中,更多的东西放到模板代中,而这些模板也是头文件的一部分。
在很大程度上,这是由于C++从C语言继承下来的原始的#include命令导致的。然而C语言往往只在头文件中有结构声明和函数原型,但是C++中经常需要将整个模板类/函数放在头文件中。
range-v3的源代码有1.8兆字节,全部在头文件中!因此,尽管“使用range输出100个三元数组”的示例只有30行,但在处理完头文件之后,需要编译10.2万行代码。而“简单C++”的示例,在所有的预处理之后,只有720行代码。
你会说使用预编译头文件和/或预编译模块可以解决这个问题!这话有点道理, 让我们试验一下:
这时候的编译时间变成了2.24秒。
所以使用PCH确实可以节省大约0.7秒的编译时间。结果仍然比简单C++的编译时间多了2.1秒。
非优化的Build性能的重要性
“ranges”示例的运行时的性能慢了150倍。慢2-3倍我觉得勉强可以接受,“慢十倍以上”意味着“没法用”,慢了一百倍多?杀了我吧。
对于解决实际问题的实际代码,慢两个数量级意味着它根本无法正常工作。就拿我所从事的视频游戏行业;在实际工作中,慢两个数量级意味着对游戏引擎或工具的debug build将无法满足实际工作的需要(性能将远远满足不了游戏的互动要求)。对于有些行业,它允许你在一组数据上运行一个程序,然后慢慢等结果。那么调试过程多花费10-100倍的时间,可能仅仅有点“烦人”。但是如果某个功能必须是交互式的,那么它就不仅仅是“烦人”了,而是“不可用”了 。比如。如果某个游戏的界面以每秒两帧的速度渲染,那你就根本无法玩这个游戏。
是的,优化的build(clang -O2)的运行时性能与简单C++一样, C++的“zero-cost abstraction(零成本抽象)”确实起作用。前提要你不关心编译时间,而且你有一个优化编译器。
但是在选中优化代码选项时的debug还是很困难!当然,可能有些人认为这是一种非常有用的技巧……类似于骑独轮车可能教会你一种重要的平衡技巧。有些人喜欢它,甚至非常擅长它!但大多数人不会选择独轮车作为他们的主要交通工具,就像大多数人尽可能地避免在用选中优化代码选项的情况下来调试代码。
Arseny Kapoulkine在Youtube上有个很棒的视频“Optimizing OBJ loader”,他也遇到了“Debug build太慢”的问题,他通过去掉一些stl bit库文件,使其运行速度提高了10倍。同时这样做也让编译速度更快和调试更容易,原因是微软的STL实现特别喜欢深度嵌套的函数调用。
这并不是说“STL必然是坏的”, 编写一个在非优化的build模式下不会变慢10倍的STL实现是有可能的(如EASTL或Libc++)。但是无论出于何种原因,微软的STL速度非常慢。由于它过度依赖于inlining.
作为语言的使用者,我不在乎它是谁的错!我只知道的“STL在调试中太慢”,我要么将它解决掉,要么寻找替代方案(例如不使用STL,重新实现我需要的bits库,或者完全不再使用C++)。
其他语言怎么样呢?
下面简单介绍一下C#是如何实现“延后计算方式生成毕达哥拉斯三元数组”的。完整的C#源代码如下:
using System;using System.Diagnostics;using System.Linq;class Program{ public static void Main() { var timer = Stopwatch.StartNew(); var triples = from z in Enumerable.Range(1, int.MaxValue) from x in Enumerable.Range(1, z) from y in Enumerable.Range(x, z) where x*x+y*y==z*z select (x:x, y:y, z:z); foreach (var t in triples.Take(100)) { Console.WriteLine($"({t.x},{t.y},{t.z})"); } timer.Stop(); Console.WriteLine($"{timer.ElapsedMilliseconds}ms"); }}比较起来,C#的可读性比C++要好一点。下面是C#的写法
var triples = from z in Enumerable.Range(1, int.MaxValue) from x in Enumerable.Range(1, z) from y in Enumerable.Range(x, z) where x*x+y*y==z*z select (x:x, y:y, z:z);
下面是 C++的写法:
auto triples = view::for_each(view::ints(1), [](int z) { return view::for_each(view::ints(1, z + 1), [=](int x) { return view::for_each(view::ints(x, z + 1), [=](int y) { return yield_if(x * x + y * y == z * z, std::make_tuple(x, y, z)); }); });});我知道上面哪一个可读性更好。你怎么看?为公平起见,我们看看用C# LINQ的实现(代码如下):
var triples = Enumerable.Range(1, int.MaxValue) .SelectMany(z => Enumerable.Range(1, z), (z, x) => new {z, x}) .SelectMany(t => Enumerable.Range(t.x, t.z), (t, y) => new {t, y}) .Where(t => t.t.x * t.t.x + t.y * t.y == t.t.z * t.t.z) .Select(t => (x: t.t.x, y: t.y, z: t.t.z));编译上面这个C#代码需要多少时间?我在Mac上,所以我将使用Mono编译器(它本身是用C#写的),版本5.16。编译命令mcs linq.cs需要0.20秒。相比之下,编译相同功能的的“简单C#”版本需要0.17秒。
所以这个延后计算的LINQ写法为编译器增加了额外的0.03秒。相比之下,C++的写法增加了额外的3秒,增加的编译时间超过了100倍!
所以,不同语言的特性不同,决定了你得到的结果也不同。而不仅仅是“编译器费劲读完10万行代码”问题。
但你不能忽略你不喜欢的部分吗?
是的,在某种程度上来说,你可以。
例如,过去在我们Unity,我们有一句玩笑,“你敢向代码库中添加Boost你就等着被开除吧”。我想这不是真的,因为我发现去年某个时候Boost.asio被加进了代码库,自那以后我对于编译速度极慢抱怨了很多次,因为include <asio.h>头文件会导致include 整个的<windows.h>头文件,而include这个头文件会导致“ macro name hijack”错误
一般来说,我们努力避免使用大多数STL。容器我们也用我们自己的,这样做的原因和创建EASTL是一样的:
然而。要说服每一位新员工(尤其是那些刚刚大学毕业的初级员工)需要时间,不能仅仅因为它被称为“Modern C++”就并不意味着它会更好, 也不能因它是C就意味着它很难理解、使用或者有很多bug。
就在几周前的工作中,我试图读懂我们自己写的一段代码,但是由于代码太复杂我实在理解不了它。我正在百无聊赖时,一位(初级)程序员过来问我,为什么我看起来像要焉了一样,我告诉他“我看不懂这段代码,对我来说它太复杂了。”他的第一反应是“哦,是旧式的C代码?”“不,恰恰相反!”我回答。因为我正在看的代码是某种template metaprogramming。这位初级程序员还没有接触到大型代码库,既没有用过C也没有用过C++,但有些东西已经让他相信“难以理解的”肯定是C代码。我怀疑现在的大学班级里都会直接说“C不好”,而不会解释到底是怎么回事;但这确实给未来的年轻程序员留下了这样的印象。
所以,我当然可以忽略C++中我不喜欢的那部分。但是,教育我现在的同事是很烦人的,因为许多人认为“现代的肯定就更好”或者“标准库就肯定比我们自己写的任何东西都好”。
C++为什么会这样?
我不太清楚。诚然,他们确实有一个非常复杂的问题要解决,那就是“如何在保持一种语言与过去几十年的版本100%向下兼容的同时更新它”。再加上C++想要服务各种不同经验水平的人群,它不变得复杂才怪。
某种程度来讲,C++标准委员会和它的生态圈,对它的复杂性的关注更多则在于炫耀或证明自己的价值。
我记得大约16年前,我还是个中年人,非常迷恋Boost。那时互联网上有一个玩笑,一个C/C++程序员开发了个东西出来,人们就会惊叹“哇,你竟然能用C/C++写,太牛了!”,不会有人问你为什么要用它。
类似于一级方程式赛车或三颈吉他,你对它们印象深刻吧!当然啦,制造出这样的东西不可思议。然而掌握它需要大量的技能。你会发现在99%的情况下,完全用不上它们。
Christer Ericson在这里说得很好:
程序员的目标是按时按预算交付开发的产品。它不是“产生代码”。我个人认为,大多数Modern C++的支持者对源代码的重视超过对编译时间、可调试性、对新概念的认知负荷和额外的复杂性、项目需求等等。而后者才是最重要的。
关注C++和STL现状的人当然可以加入进来去改进它。有些人已经这样做了,有些人太忙了没能时间做这些,有些人抛弃了部分STL而建立了自己的并行库(如EASTL)。有些人认为C++不值得拯救,还不如自己另起炉灶,用新的语言来代替它(如Jai,Rust 和subsets of C#)。
接受反馈,并给出反馈
当“网上一群愤怒的人”说你的工作是众所周知的垃圾时,我知道这让人很难受。我正在开发可能是最受欢迎的游戏引擎,拥有数百万的用户,而他们中的一些人喜欢直接或间接地指责“它太差劲了”。这让人很难受,我们花了这么多的心思和精力的游戏,却有人过来说我们都是白痴而我们的游戏很垃圾。真是让人伤心!
对于任何工作在C++、STL或任何其他广泛使用的技术上的人来说,他们的遭遇可能是相同的。他们在某件事上工作了很多年,然后一群愤怒的网络用户来了,说你费尽心血的成果是垃圾。
自然而然地你会为自己辩护。但通常这不是最有建设性的。
忽略网上那些幸灾乐祸的键盘侠们,网上大多数的抱怨背后确实有实际的问题。有些措辞可能很差,或者夸张,或者抱怨的人没有考虑其他可能的观点,但是无论如何,抱怨背后的问题确实存在。
每当我听到有人抱怨我所做的东西时,我会试着不去想这是“我”和“我做的东西”,我会站在他们的立场来想,他们遇到了什么问题,他们想解决的问题是什么。任何软件/库/语言的目的都是帮助用户解决他们的问题。这可能是解决他们问题的一个完美工具,或者一个“大概可以”的工具,或者一个非常糟糕的工具。
然而,“游戏产业”在很大程度上也存在一定的缺陷。游戏技术一直采用C或C++,因为直到最近都没有其他可替代的系统编程语言可选择(现在你至少有Rust作为一个可能的竞争者)。对于依赖C/C++技术的行业来说,这个行业和从业者肯定没有做足工作,让我们能够看到C/C++语言、库和生态系统的改进。
在互联网上抱怨容易,但改进C/C++是是一项艰苦的工作。终结C++并不能解决迫在眉睫的问题;他们正在长线规划。有些公司可以负担得起;像拥有大型Engine的公司或拥有大型技术团队的公司都可以做到。我不知道这样做是否值得。但是如果仅仅说“C++是我们不需要的傻瓜语言”,而从不告诉那些使用它的人我们到底想要什么,那就有点言不由衷了。
在我的印象,许多从事游戏开发的人对最近(C++ 11/14/17)添加进去的很多C++特性都觉得非常好。如lambdas, constexpr if 等等。他们倾向于忽略添加到标准库中的任何东西,这是因为STL的设计/实现存在上面指出的问题(编译时间长,Debug build性能差),或者对他们没那么有用,或者他们的公司在几年前就已经编写了自己的容器/字符串/算法……,所以为什么要改变已经有效的东西呢?
原文:
http://aras-p.info/blog/2018/12/28/Modern-C-Lamentations/本文为 CSDN 翻译,如需转载,请注明来源出处。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号