摘要: 在数据分析中,我们可能需要使用各种数据库,目前大概有七种常用数据库,包括4种常用的关系型数据库,3种常用NoSQL数据库(NoSQL = Not Only SQL 泛指非关系型的数据库)。
这些数据库作为业务底层的存储选型,每种数据库都有各自的定位和特点,结合业务,有各自的适用场景。
第一种:MySQL数据库
目前使用最广泛、流行度最高的的开源数据库。
2、特点:
功能:
支持事务,符合关系型数据库原理,符合ACID,支持多数SQL规范,以二维表方式组织数据,有插件式存储引擎,支持多种存储引擎格式
安装部署:
这里使用Docker安装启动
安装docker pull mysql:5.7启动docker run -p 3307:3307 --name mysql-3307 -v /data/mysql/3307/conf/my.conf:/etc/mysql/mysql.conf.d/mysqld.cnf -v /data/mysql/3307/mysql_data:/var/lib/mysql --net=host --privileged -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7通过docker exec -it 88dab2f338c6(容器id)bash 命令可进入容器进行修改密码、客户端连接权限等操作
使用:
使用标准的SQL语句进行数据库管理,简单SQL语句的并发和性能较好,对视图、存储过程、函数、触发器等支持的不是太好
监控:
在命令行界面有一些常用的命令显示状态和性能,在图形界面方面,有比较多的开源监控工具来监控和记录数据库的状态,比如zabbix,nagios,cacti,lepus等
备份:
逻辑备份 mysqldump/mysqldumper ,物理备份 用xtrabackup等工具进行备份;
高可用:
MySQL高可用有多种方案,官方有基础的master-slave主从复制,新版本的innodb cluster,第三方的有MHA等高可用方案;
扩展:
MySQL水平拆分,可以通过水平拆分proxy中间进行逻辑映射和拆分,扩大MySQL数据库的并发能力和吞吐量。当然,也可以使用数据库集群管理。
3、适用场景:
默认的innodb存储引擎,支持高并发,简单的绝大部分OLTP场景;
Tokudb存储引擎,使用高并发insert的场景;
Inforbright存储引擎,可以进行列压缩和OLAP统计查询场景;
4、选择注意:
使用MySQL进行OLTP业务时,需要注意数据量级,如果数据量级过大,需要进行水平拆分;
如果有OLAP需求,可以结合其他架构综合考虑。
第二种:Mongodb数据库
1、定位:开源、多平台、文档型nosql数据库
非常主流的文档型nosql数据库,“最像关系型数据库”,定位于“灵活”的nosql数据库
2、特点:
功能:数据文件存储格式为BSON,模式自由,整体架构与关系型数据库有对应关系,具有较好的高可用性和伸缩性,有插件式存储引擎,新版本默认是writedtiger存储引擎;
部署: 部署比较简答,下载软件,设置好配置文件即可启动服务;
使用:不支持SQL语句,使用与SQL对应的json方式管理数据库;
监控:有比较丰富的监控和性能命令,官方有比较完善的图形监控系统,但需要购买;
备份:支持冷备份和热备份,可以使用mongoexport/mongimport进行逻辑备份,也可以使用基于oplog的mongodump/mongorestore物理热备份;
高可用:MongoDB master-slave主从复制:在master节点上加 —master参数,从数据库加 -slave和-source参数,就可以实现同步,这种目前不建议;
ReplicaSets复制集,在mongodb 1.6之后,开发了新的 replicaset,着呢家了故障自动切换和自动修复成员节点,各个DB将数据一致,建议使用这种方式;可以测试读写分离和故障转移;
扩展:mongodb海量数据水平拆分,将数据分别存储在sharding各个节点上,构建出分布式集群。Sharding架构由 底层多个mongodb Shared Server,config水平拆分配置库config server,前端路由 route process,三部分构成。Sharding集群底层可以是mongodb单实例,也可以高可用的replicaSet复制集。
3、适用场景:
网站后台数据库:mongodb非常适合实话实说插入、更新与查询,并可以实时复制和高伸缩性,适合更新迭代快、需求变更多、以对象为主的网站应用;
小文件系统:对于json文件,二进制数据,适合用mongodb进行存储和查询
日志分析系统:对于数据量大的日志文件,IM会话消息记录,适合用mongodb来保存和查询;
缓存系统:mongodb数据库也会使用大量的内存,合理的设计,也可以作为缓存系统使用;不过目前缓存系统使用更多的方案是 memcached和redis。
4、选择注意:
Mongodb不适合的场景:
高度事务性的系统:即传统的OLTP业务,mongodb,乃至其他nosql,对事务性支持都不太好;
传统的统计分析应用:即传统的OLAP业务,需要高度优化的查询方式,mongodb支持不好;
使用SQL语句比较方便的业务:mongodb是json类型的查询方式,虽然也灵活,但不如用SQL方便,如果业务和适合SQL,则就不太合适mongodb了。
第三种:Redis数据库
1、定位:
开源、Linux平台、key-value键值型Nosql数据库
简单稳定,非常主流的、全数据in-momory、定位于“快”的键值型nosql数据库
2、特点:
功能: 命令执行速度非常看,读写性能可达10万/秒;数据结构是key-value类似字典的功能,可以键过期-缓存,发布订阅-消息系统,简单的事物功能;
部署: 用下载软件介质,编译安装的方式,可以很快完成数据库部署;服务启动redis-server,可以用默认配置、运行参数配置、配置文件启动,三种方式;redis在Linux平台支撑较好,官方没有Windows版本,微软维护了一个分支;
使用:用redis-cli客户端连接,一般用简单的 set ,get,del 进行数据管理; 在单实例redis的基础上,进行可以数据持久化,主从复制,高可用和分布式等功能;
监控:在命令行界面有一些常用的命令显示状态和性能,在图形界面方面,有开源监控工具来监控和记录数据库的状态,比如cachecloud;
备份:直接备份成物理问价的RDB持久化,基于AOF日志的实时AOF持久化
高可用:官方的 redis sentinel哨兵高可用集群
扩展:官方基于分配槽的 redis cluster分布式集群
3、适用场景:
缓存
基础消息队列系统
排行榜系统
计数器使用
社交网站的点赞、粉丝、下拉刷新等应用;
4、选择注意:
Redis的使用场景,是redis适合的解决的问题,也有不适合解决的问题。
从数据规模角度讲,小数据规模使用redis比较合适,大数据规模使用redis不合适;(大数据规模,在一定程度上,可以用SSDB替代redis使用);
从数据冷热角度看,热数据适合放在redis中,冷数据不适合放在redis中。
第四种:Oracle数据库
1、定位:商业、多平台、关系型数据库
功能最强大、最复杂、市场占比最高的商业数据库
2、特点:
功能:支持事务,符合关系型数据库原理,符合ACID,支持多数SQL规范,以二维表方式组织数据
部署:Oracle单实例数据库部署相对容易,但Oracle RAC集群环境,部署的步骤和依赖条件都比较多;
使用:通常使用命令行工具,进行各种数据库的管理,通常也可以用shell脚本和python脚本提高Oracle数据库管理效率;各种管理功能,都比较强大;
监控:Oracle官方有比较全面的监控工具,常用的第三方监控平台,如zabbix,cacti,lepus等都有对Oracle数据库的各项指标的完善监控;
备份:支持冷备份和热备份,可以用 exp/imp , expdp/impdp等进行逻辑备份和恢复,可以使用强大的RMAN工具进行专业的物理热备份和恢复;
高可用:Oracle数据库的高可用架构,可以用第三方双机热备软件,结合Oracle单实例实现;可以使用Oracle Dataguard,实现master和standby的备份;可以使用 Oracle RAC集群实现实例级别的高可用和负载均衡,使用ASM实现存储级别的高可用;
扩展:由于Oracle集群采用共享存储的方式,一般只能通过垂直硬件升级进行升级;
3、适用场景:绝大多数OLTP场景,部分OLAP
4、选择注意:Oracle从架构到运维,可以说是最难的数据库,学习和使用难度较高。
第五种:Postgresql数据库
1、定位:开源、多平台、关系型数据库,功能最强大的开源数据库。
2、特点:
功能:支持事务,符合关系型数据库原理,符合ACID,支持多数SQL规范,以二维表方式组织数据;
部署: postgresql需要先准备好Python等环境,然后编译安装软件,初始化数据库,启动实例,整个部署过程相对比较清晰;
使用: postgresql数据库可以使用命令行方式进行管理,也可以通过pgadmin图形工具进行管理;各种管理功能,都比较强大;
监控: 可以再命令行中查看各种性能视图和状态视图;相对其他其他数据库,并没有太好的图形监控工具和平台;
备份:支持冷备份和热备份,可以用 COPY命令进行逻辑导出和导入;用pgdump和pgrestore进行物理备份和恢复;
高可用:postgresql 官方支持 master-standby复制;也可以用Slony-I第三方组件进行数据库同步;
扩展:postgresql可以通过修改源码实现的postgres-XC实现水平扩展;
3、适用场景:
绝大多数OLTP场景,部分OLAP
适合目前互联网需要的一些信息,比如地理位置信息处理;
以postgresql作为底层数据库的greenplum数据仓库,是主流的MPP数据仓库;
基于postgresql的TimeScaleDB,是目前比较火的时序数据库之一;
4、选择注意:
Postgresql的架构、使用难度、功能性介于Oracle数据库和MySQL数据库之间,但因其开源的推动,各方面也有不错的发展;
Postgresql目前还没有比较主流和好用的监控平台,这是postgresql数据库目前存在的一个不足。
第六种:Memcache数据库
1、定位:Memcached主要是用来提高访问关系型数据库的效率问题,只局限于访问。
2、特点
可靠性:MemCached不支持数据持久化,断电或重启后数据消失,但其稳定性是有保证的。Redis支持数据持久化和数据恢复,允许单点故障,但是同时也会付出性能的代价。
3、适用场景
Memcached:动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量的情况(如人人网大量查询用户信息、好友信息、文章信息等)。
4、选择注意
MongoDB 的主要适用场景为:数据不是特别重要(例如通知,推送这些),数据表结构变化较为频繁,数据量特别大,数据的并发性特别高,数据结构比较特别(例如地图的位置坐标),这些情况下用 MongoDB
第七种:SQLite数据库
数据库就是一个文件,实现了自给自足、无服务器、零配置的、事务性的SQL数据库引擎。
2、特点:
- 不需要一个单独的服务器进程或操作的系统(无服务器的)。
- SQLite 不需要配置,这意味着不需要安装或管理。
- 一个完整的 SQLite 数据库是存储在一个单一的跨平台的磁盘文件。
- SQLite 是非常小的,是轻量级的,完全配置时小于 400KiB,省略可选功能配置时小于250KiB。
- SQLite 是自给自足的,这意味着不需要任何外部的依赖。
- SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问。
- SQLite 支持 SQL92(SQL2)标准的大多数查询语言的功能。
- SQLite 使用 ANSI-C 编写的,并提供了简单和易于使用的 API。
- SQLite 可在 UNIX(Linux, Mac OS-X, Android, iOS)和 Windows(Win32, WinCE, WinRT)中运行。3、区别:它是一个零配置的数据库,这就体现出来SQLite与其他数据库的最大的区别: 4、适用场景: 两大用途:
用于简单数据写入和海量、结构简单数据查询的业务场景;
用于成为其他数据库备份和下沉的数据库;5、选择注意: sqlite3的锁及事务类型 sqlite3总共有三种事务类型:BEGIN [DEFERRED /IMMEDIATE / EXCLUSIVE] TRANSCATION,
五种锁,按锁的级别依次是:UNLOCKED /SHARED /RESERVERD /PENDING /EXCLUSIVE。
当执行select即读操作时,需要获取到SHARED锁(共享锁),当执行insert/update/delete操作(即内存写操作时),需要进一步获取到RESERVERD锁(保留锁),当进行commit操作(即磁盘写操作时),需要进一步获取到EXCLUSIVE锁(排它锁)。
对于RESERVERD锁,sqlite3保证同一时间只有一个连接可以获取到保留锁,也就是同一时间只有一个连接可以写数据库(内存),但是其它连接仍然可以获取SHARED锁,也就是其它连接仍然可以进行读操作(这里可以认为写操作只是对磁盘数据的一份内存拷贝进行修改,并不影响读操作)。
对于EXCLUSIVE锁,是比保留锁更为严格的一种锁,在需要把修改写入磁盘即commit时需要在保留锁/未决锁的基础上进一步获取到排他锁,顾名思义,排他锁排斥任何其它类型的锁,即使是SHARED锁也不行,所以,在一个连接进行commit时,其它连接是不能做任何操作的(包括读)。
PENDING锁(即未决锁),则是比较特殊的一种锁,它可以允许已获取到SHARED锁的事务继续进行,但不允许其它连接再获取SHARED锁,当已存在的SHARED锁都被释放后(事务执行完成),持有未决锁的事务就可以获得commit的机会了。sqlite3使用这种锁来防止writer starvation(写饿死)。死锁的情况 死锁的情况:当两个连接使用begin transaction开始事务时,
第一个连接执行了一次select操作(已经获取到SHARED锁),第二个连接执行了一次insert操作(已经获取到了RESERVERD锁),此时第一个连接需要进行一次insert/update/delete(需要获取到RESERVERD锁),
第二个连接则希望执行commit(需要获取到EXCLUSIVE锁),由于第二个连接已经获取到了RESERVERD锁,根据RESERVERD锁同一时间只有一个连接可以获取的特性,第一个连接获取RESERVERD锁的操作必定失败,而由于第一个连接已经获取到SHARED锁,第二个连接希望进一步获取到EXCLUSIVE锁的操作也必定失败。就导致了事务死锁。事务类型的使用原则 在用”begin transaction”显式开启一个事务时,默认的事务类型为DEFERRED,锁的状态为UNLOCKED,即不获取任何锁,如果在使用的数据库没有其它的连接,用begin就可以了。如果有多个连接都需要对数据库进行写操作,那就得使用BEGIN IMMEDIATE/EXCLUSIVE开始事务了。
使用事务的好处是:
1.一个事务的所有操作相当于一次原子操作,如果其中某一步失败,可以通过回滚来撤销之前所有的操作,只有当所有操作都成功时,才进行commit,保证了操作的原子特性;
2.对于多次的数据库操作,如果我们希望提高数据查询或更新的速度,可以在开始操作前显式开启一个事务,在执行完所有操作后,再通过一次commit来提交所有的修改或结束事务。对SQLITE_BUSY的处理 当有多个连接同时对数据库进行写操作时,根据事务类型的使用原则,我们在每个连接中用BEGIN IMMEDIATE开始事务,即多个连接都尝试取得保留锁的情况,根据保留锁同一时间只有一个连接可以获取到的特性,其它连接都将获取失败,即事务开始失败,
这种情况下,sqlite3将返回一个SQLITE_BUSY的错误,如果我们不希望操作就此失败而返回,就必须处理SQLITE_BUSY的情况,
sqlite3提供了sqlite3_busy_handler或sqlite3_busy_timeout来处理SQLITE_BUSY,对于sqlite3_busy_handler,我们可以指定一个busy_handler来处理,并可以指定失败重试的次数。
而sqlite3_busy_timeout则是由sqlite3自动进行sleep并重试,当sleep的累积时间超过指定的超时时间时,最终返回SQLITE_BUSY。
需要注意的是,这两个函数同时只能使用一个,后面的调用会覆盖掉前次调用。
从使用上来说,sqlite3_busy_timeout更易用一些,只需要指定一个总的超时时间,然后sqlite自己会决定多久进行重试以及重试的次数,直到达到总的超时时间最终返回SQLITE_BUSY。
并且,这两个函数一经调用,对其后的所有数据库操作都有效,非常方便。
通过对上面几种数据库的描述,也可以看到目前常用数据库的使用脉络和选择顺序,对应一个业务,可以优先选择最流行的开源数据库——MySQL;如果出于稳定和商业版考虑,可以选择Oracle数据库 ;如果想用开源,有想要有足够的功能来应对各种场景,可以使用 postgresql数据库。这四种数据库,都是关系型数据库,可以很好地满足大多数业务场景,解决通用性问题。
对于一些特殊性问题,尤其是想要在扩展性方面有比较高的要求,可以考虑nosql数据库。Mongodb数据库,介于关系型数据库和非关系型数据库之间,兼具两者的特点,是非常流行的文档型nosql数据库;Redis、Memcached定位于内存型键值nosql数据库;hbase是海量文件存储的列式nosql数据库。根据合适的业务场景,选择适合的nosql数据库,可以对某一类,或某几类业务问题有很好的解决,可以作为关系型数据库的一种补充。
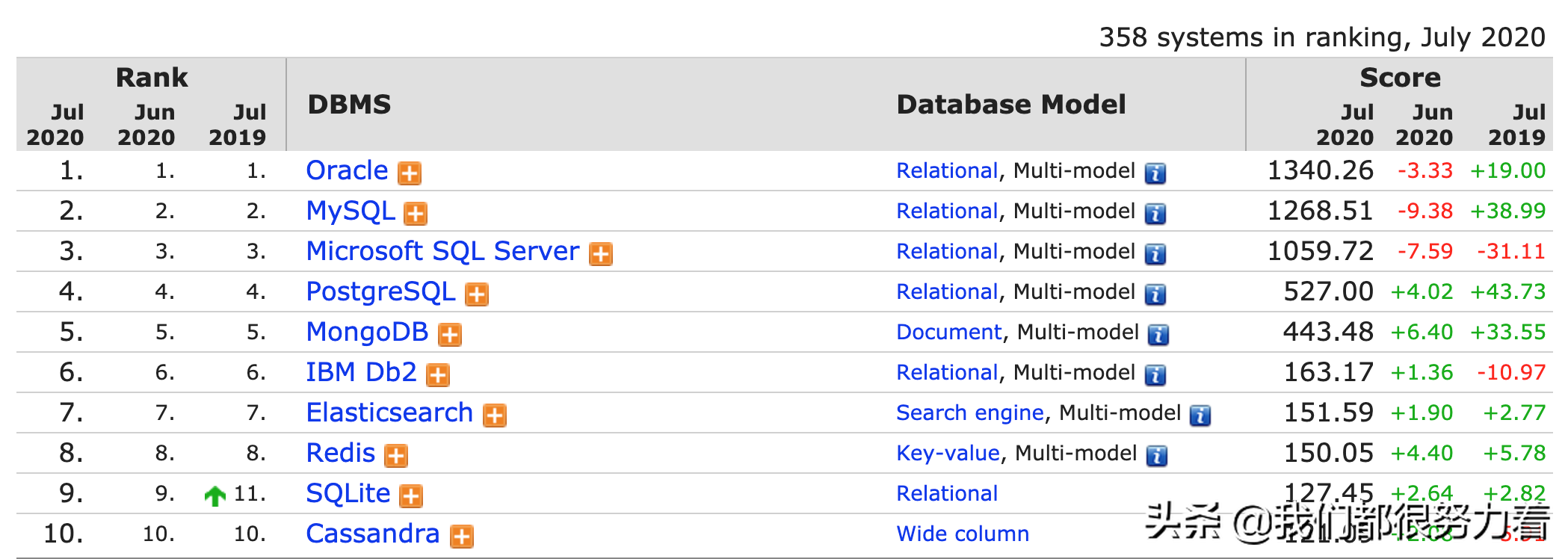
这里附一张DB-Engines数据库排行榜前10名的最新数据库排名已做参考。

 鲁公网安备37020202000738号
鲁公网安备37020202000738号