小红书推荐算法揭秘:背后的工作原理
发表时间: 2024-05-21 15:29
小红书的内容推荐模型是怎样的?这篇文章里,作者就对小红书的推荐模型逻辑进行了拆解,感兴趣的同学,可以来看一下。

根据收集的用户个人信息,我们可以发现小红书的业务模式始终是基于内容进行过滤、检索的信息流生活平台,在这一平台上生活美妆是其主题。
工业界常见的推荐模型一般包括特征服务、索引、召回、粗排、精排、重排、样式创意等环节,我将基于此对小红书的推荐模型逻辑进行拆解。
在“设置-我的内容偏好”中,我们可以发现“为我们推荐可能感兴趣的内容”,其中如“狗狗日常”、“艺术绘画”便是平台所使用的用户特征、物料特征、情景特征。
此外,平台内部还有不对C端公开的细化标签,比如“狗狗日常”的“京巴”与“藏獒”便会被推送到不同用户界面处。平台基于这些物料特征为物料进行预训练、打标,以供后续召回、排序等环节的使用。

小红书主要采用Item-CF算法类似的逻辑,然而这一算法普遍存在以下表征:
为解决用户冷启动问题,以小红书为代表的内容消费平台采用双塔模型的思想,在召回阶段中往往会增加一路使用内容多模态表征的i2i召回进行优化,这路召回由于只使用了纯内容的特征,和老物品便可以公平比较,不会产生因为新物品后验行为少而导致无法被召回的问题,近期引入了LLM对i2i召回进行优化。
在现有的多模态i2i召回方法,在文本侧一般都是用一个BERT经过预训练后生成embedding然后基于embedding的相似度来进行召回,但是这样可能也会存在一些问题:
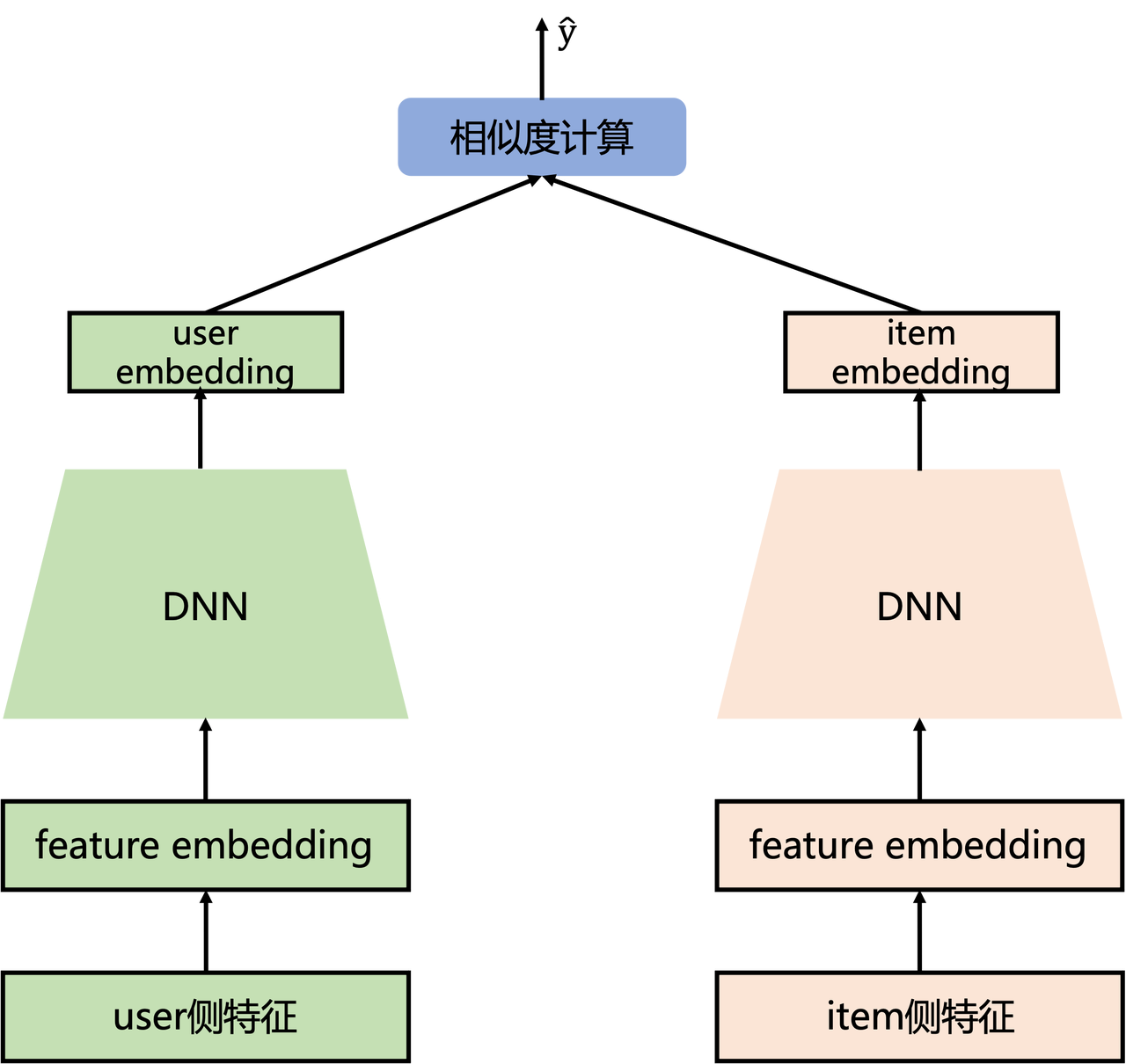
小红书发现使用笔记内容生成标签和类别的过程和生成笔记的embedding十分类似,都是讲笔记的关键信息压缩成有限的内容,因此引入一个生成标签和类别的任务可能会提升最终embedding的质量,因此设计了3个方法:
笔记压缩prompt构建用来定义模型在训练时的输入,生成式对比学习和协同监督微调分别对应两个预训练任务,前者引入了推荐中的协同过滤信号作为标签进行对比学习来训练更好的文本表征,后者其实就是根据笔记内容来生成对应的标签和类别,以此强化embedding的可用性,结果表明将LLM引入i2i推荐任务可以提高推荐性能和用户体验。
此外,还观察到单日对新笔记的评论数量显着增加了3.58%。这表明LLM的引入有利于冷启动。NoteLLM最终推全上线。
3.1. 粗排策略
行业内普遍采用基于模型的粗排策略。使用DNN模型构建CTR预估模型,并进行离线AUC指标评估与线上AB Test测试。
3.2. 精排策略
在内容推荐场景,对于内容推荐平台如小红书等来说其核心的业务指标是DAU、互动率。小红书采用GBDT+Sparse D&W的模型算法通过构建click、hide、like、fav、comment、share、follow等模型特征来进行模型训练,并输出训练结果,即CES评分=点赞数×1分+收藏数×1分+评论数×4分+转发数×4分+关注数×8分。
3.3. 重排策略
3.3.1. 全局最优的排序策略
一个界面里有四个帖子,很明显小红书采用的是序列优化策略,会根据我点击物料的行为进行排序,最终排出我最喜欢的东西,你会发现实习求职多数在上面,大多在左上角哦!
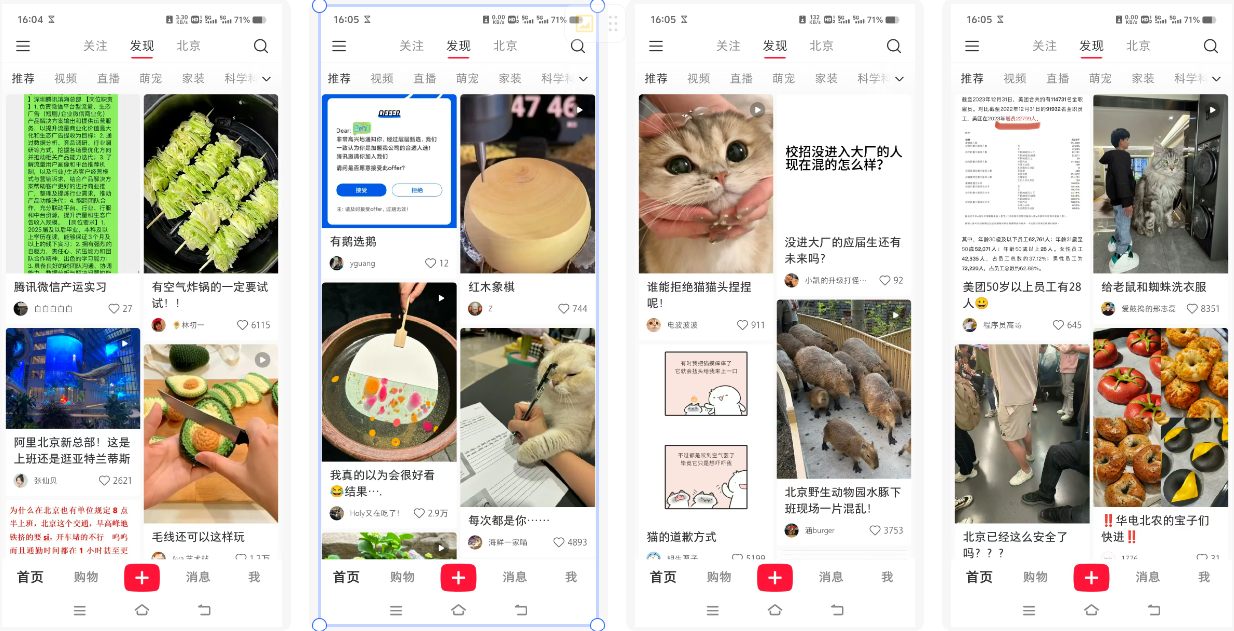
3.3.2. 基于用户体验的策略调整
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号