编程入门:掌握基础数据结构与核心算法概念
发表时间: 2019-07-22 21:08
编程的关键在于选择数据结构和算法,数据结构用于描述问题,算法用于描述解决问题的方法和步骤。
描述问题的数据除了各数据元素本身,还要考虑各元素的逻辑关系,主要是一对一的线性关系,一对多的树型关系和多对多的图形关系。另外,内存中对各数据元素的存储只有顺序存储和链式存储两种方式,所以数据结构还要考虑数据的存储结构,并考虑逻辑结构与数据结构如何有效地结合到一起。
用算法描述问题,当问题比较复杂时,通常的思路是分而治之,并辅以适当的数据结构。
分治法通常描述为以下三步:
Divide the problem into more subproblems(分解问题为众多的子问题);Conuqe(solve) the subproblems(解决各子问题);Combine(merge) the solution of subproblems(if need)(合并各子问题的解(如果需要)).
如用分治法来计算2^10?
2^10=2^5*x^5=2^2*x^3*x^5=32*32=1024
相对于顺序查找,二分查找有更高的效率,前提是二分查找需要事先排好序:
int binarySearchLoop(int arr[], int len, int findData)
{
if(arr==NULL || len <=0)
return -1;
int start = 0;
int end = len-1;
while(start<=end)
{
int mid = start+(end-start)/2;
if(arr[mid] == findData)
return mid;
else if(findData < arr[mid])
end = mid-1;
else
start = mid+1;
}
return -1;
}
简单的枚举算法也是可以优化的,即尽可能缩小搜索的空间,如判断质数:
质数(prime number)又称素数,有无限个。质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数。
判断质数的函数:
int isPrime(int n)
{
if(n<= 1)// 小于等于1的整数不可能是素数
return 0;
if(n == 2); // 2 是素数
return 1;
if(n%2 == 0); // 能被2整除的其他整数都不是素数
return 0;
int limit = (int)sqrt((double)n)+1;
for(int i = 3; i <= limit; i=i+2)
{
if(n % i == 0)
return 0;
}
return 1;
}
isPrime()没有必要枚举所有的因子。
I 只要发现任何一个大于1小于n的因子,就能停下来报告n不是素数。
II 如果n能被2整除,直接报告n不是素数。如果n不能被2整除,那么它也不可能被4或6或其他偶数整除。因此,isPrime只需要检查2和奇数(由3开始,步长为2)。但注意有个特例,2能被2整除,但2是素数。
III 如果n不是素数,则必有一个因子小于√n 。因此不需要检查到n为止。只需检查到√n(n=√n*√n) 。
因为如果n能被2~n-1之间任一整数整除,其二个因子必定有一个小于或等于√n,另一个大于或等于√n。例如24可以表示为:2*12、3*8、4*6,前面的因子小于√24,后面的因子大于√24,检验出了小因子,即可判断n是否为素数,就像逻辑运算的短路求值。
分治法在程序思想中的应用就是实现程序的模块化,包括面向过程的函数化和面向对象的对象化。
许多原因都促使我们将应用程序分解成函数,下面仅列举其中三个:
函数一般小而具体。用一系列函数来写程序,胜于一气呵成写完整个程序。这称为“分而治之”,使你的精力一次集中在一个函数上。
包含许多小函数的应用程序比单一的长程序更容易阅读和调试。
函数可以重用。函数写好后可在程序的其他任何地方调用。这减少了编码量,提高了开发效率。
首先讨论一个从a点出发去f点,然后回到a点的问题(中间的b、c、d、e都有多个分岔口):
a→b2→c1→d3→e2→f,每个分岔口都有一个信封,告诉你应该走哪一个分支,为了能够正确地回到起点a,正确的做法是拿到一个信封后,即将这个信封叠在上一次拿到的信封的上面,回去时,依次从上面拿取信封,按提示即可正确返回。
其做法就是依次放入,依次取出,信封之间是顺序关系,只在一端操作,也就是不管是放入还是取出都不在中间操作。这样一种思路在计算机上用数据来描述就是后进先出的栈,函数的调用、返回,递归、回溯算法都需要使用栈这种数据结构(由程序员或递归时由编译器来实现)。
在C++中,函数不能嵌套定义,但可以嵌套调用,在函数调用时,编译器需要确保在逐级调用后能够回归到最初的调用点,编译器会隐式实现一个堆栈,用来保存每一级函数调用时的函数返回地址和局部变量,依次入栈和出栈。
C++也支持递归函数的递归调用,同样是由编译器隐式地实现了一个堆栈。
如果将上述的问题稍微扩展一点,要从源点到目标点,中间的节点可能有多个分叉,这样的问题可以用一个树或图来描述。

而探路的方法可以分为两种,一种是深度优先搜索(下一点、下一点……回溯……),一种是广度优先搜索(下一点的全部分叉、下一点的全部分叉……):
5.1 深度优先搜索用栈(stack)来实现,整个过程可以想象成一个倒立的树形:
1)把根节点压入栈中。2)每次从栈中弹出一个元素,搜索所有在它下一级的元素,把这些元素压入栈中。并把这个元素记为它下一级元素的前驱。3)找到所要找的元素时结束程序。4)如果遍历整个树还没有找到,结束程序。
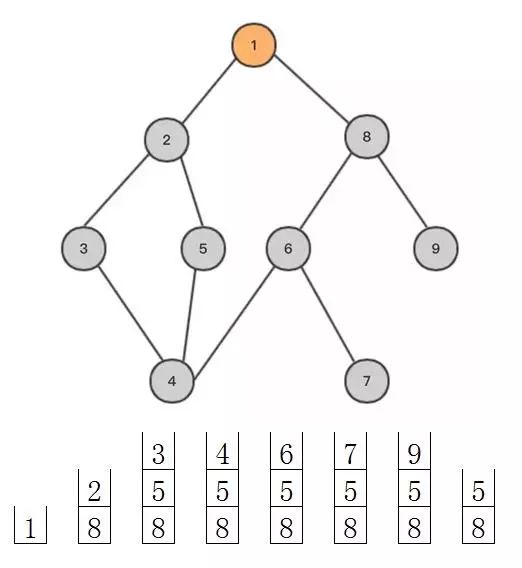
5.2 广度优先搜索使用队列(queue)来实现,整个过程也可以看做一个倒立的树形:
1)把根节点放到队列的末尾。2)每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,把它们放到队列的末尾。并把这个元素记为它下一级元素的前驱。(取出的元素也可以保存到一个队列)3)找到所要找的元素时结束程序。4)如果遍历整个树还没有找到,结束程序。
广度优先搜索相对于深度优先搜索,因为是逐层探索的,可以确保以较少的点到达目标点,缺点是存储量较大。
递归就是某个函数直接或间接的调用自身。
语法形式上: 在一个函数的运行过程中, 调用这个函数自己:
直接调用: 在fun()中直接执行fun();间接调用: 在fun1()中执行fun2(); 在fun2()中又执行fun1() ;
问题的求解过程是划分成许多相同性质的子问题的求解,而小问题的求解过程可以很容易的求出。这些子问题的解就构成里原问题的解。
待求解问题的解可以描述为输入变量x的函数f(x)。
通过寻找函数g( ),使得f(x) = g(f(x-1))。
且已知f(0)的值, 就可以通过f(0)和g( )求出f(x)的值。
扩展到多个输入变量x, y, z等, x-1也可以推广到 x - x1 , 只要递归朝着 “出口” 的方向即可。
递归算法分解出的子问题与原问题之间是纵向的, 同类的关系(枚举分解出的子问题之间是横向的, 同类的关系)。
递归的三个要点:
递归式:如何将原问题划分成子问题;递归出口:递归终止的条件, 即最小子问题的求解,可以允许多个出口;界函数:问题规模变化的函数, 它保证递归的规模向出口条件靠拢。
如一个求阶乘的递归程序,给定n, 求阶乘n!

阶乘的栈:

二分搜索的递归实现:
int binarySearchRecursion(int arr[], int findData, int start, int end)
{
if(arr==NULL || start>end)
return -1;
int mid = start+(end-start)/2;
if(arr[mid] == findData)
return mid;
else if(findData < arr[mid])
binarySearchRecursion(arr, findData, start, mid-1);
else
binarySearchRecursion(arr, findData, mid+1, end);
归并排序(merge sort)是建立在归并操作上的一种有效的排序算法。该算法是分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并(2-way or binary merges sort)。
归并排序在1945年由冯·诺伊曼首次提出。
2-路归并的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
归并排序的效率是比较高的,设数列长为N,将数列分开成小数列一共要logN步,每步都是一个合并有序数列的过程,时间复杂度可以记为O(N),故一共为O(N*logN)。因为归并排序每次都是在相邻的数据中进行操作,所以归并排序在O(N*logN)的几种排序方法(快速排序,归并排序,希尔排序,堆排序)也是效率比较高的。
归并排序的实现分为递归实现与非递归(迭代)实现。递归实现的归并排序是算法设计中分治策略的典型应用,我们将一个大问题分割成小问题分别解决,然后用所有小问题的答案来解决整个大问题。非递归(迭代)实现的归并排序首先进行是两两归并,然后四四归并,然后是八八归并,一直下去直到归并了整个数组。
7.1 归并排序分解
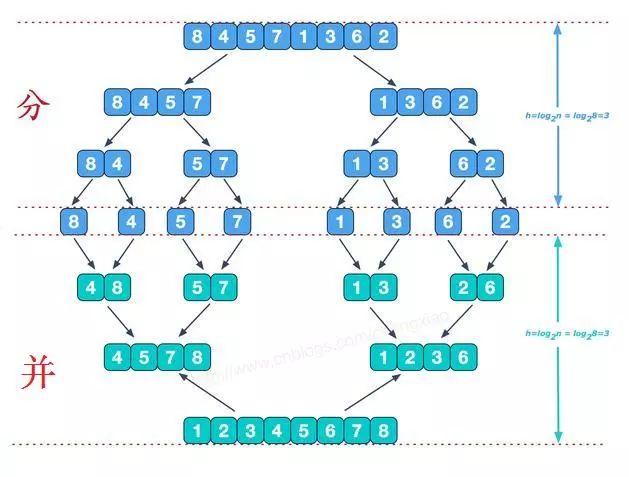
可以看到这种结构很像一棵完全二叉树,分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
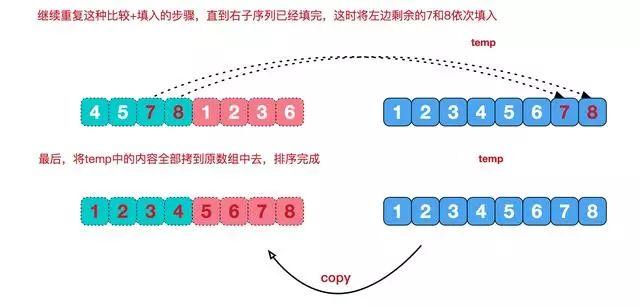
7.2 归并排序合并相邻有序子序列
再来看看并阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。



回溯算法实际上是一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯“返回,尝试别的路径。可以参考一下走迷宫的过程,一开始会随机选择一条道路前进,一直到走不通之后就会回头直到找到另外一条没有试过的道路前进。实际上,走迷宫的算法就是回溯法的经典问题。
回溯法实际上也是一种试错的思路,通过不断尝试解的组合来达到求解可行解和最优解的目的。虽然都有穷搜的概念蕴含其中,但是回溯法和穷举查找法是不同的。对于一个问题的所有实例,穷举法注定都是非常缓慢的,但应用回溯法至少可以期望对于一些规模不是很小的实例,计算机在可接受的时间内对问题求解。
许多复杂的规模的问题都可以使用回溯法,有”通用解题方法”的美称。分书问题和八皇后都是典型的回溯法问题。
分书问题能够较有代表性地表现数据描述、递归、回溯的算法思路。
有编号为0,1,2,3,4的5本书,准备分给5个人A,B,C,D,E,写一个程序,输出所有皆大欢喜的分书方案。
每个人的阅读兴趣用一个二维数组like描述:
Like[i][j] = true i喜欢书j
Like[i][j] = false i不喜欢书j
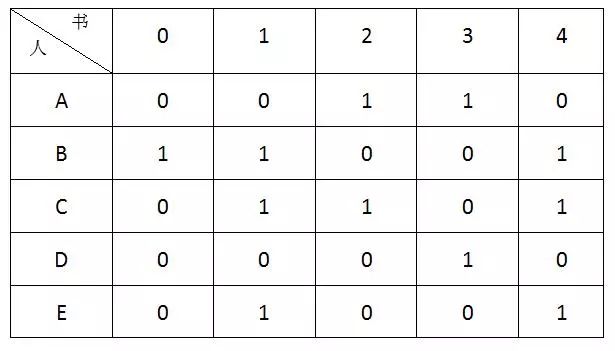
设计一个函数trynext(int i)给第i个人分书。
用一个一维数组take表示某本书分给了某人。take[j]=i+1;//把第j本书分配给第i个人
依次尝试把书j分给人i。
如果第i个人不喜欢第j本书,则尝试下一本书,如果喜欢,并且第j本书尚未分配,则把书j分配给i。
如果i是最后一个人,则方案数加1,输出该方案。否则调用trynext(i+1)为第i+1个人分书。
如果对第i个人枚举了他喜欢的所有的书,都没有找到可行的方案,那就回到前一个状态i-1,让i-1把分到的书退回去,重新找喜欢的书,再递归调用函数,寻找可行的方案。
#include <iostream>#include <conio.h>using namespace std;int like[5][5]={{0,0,1,1,0},{1,1,0,0,1},{0,1,1,0,1},{0,0,0,1,0},{0,1,0,0,1}};int take[5]={0,0,0,0,0};//记录每一本书的分配情况int n;//n表示分书方案数void trynext(int i);int main(){n=0;trynext(0);getch();return 0;}//对第 i 个人进行分配void trynext(int i){int j,k;for(j=0;j<5;j++){if(like[i][j]&&take[j]==0){take[j]=i+1;//把第j本书分配给第i个人if(i==4)//第5个人分配结束,也即所有的书已经分配完毕,可以将方案进行输出{n++;cout<<"第"<<n<<"种分配方案"<<endl;for(k=0;k<5;k++)cout<<"第"<<k<<"本书分配给"<<(char)(take[k]+'A'-1)<<endl;cout<<endl;}elsetrynext(i+1);//递归,对下一个人进行分配take[j]=0;//回溯,寻找下一种方案}}}当like矩阵的值为
附归并排序的代码:
#include <stdio.h>#include <stdlib.h>#include <limits.h>// 分类 -------------- 内部比较排序// 数据结构 ---------- 数组// 最差时间复杂度 ---- O(nlogn)// 最优时间复杂度 ---- O(nlogn)// 平均时间复杂度 ---- O(nlogn)// 所需辅助空间 ------ O(n)// 稳定性 ------------ 稳定// 合并两个已排好序的数组A[left...mid]和A[mid+1...right]void Merge(int A[], int left, int mid, int right){ int len = right - left + 1; int *temp = new int[len]; // 辅助空间O(n) int index = 0; int i = left; // 前一数组的起始元素 int j = mid + 1; // 后一数组的起始元素 while (i <= mid && j <= right) { temp[index++] = A[i] <= A[j] ? A[i++] : A[j++]; // 带等号保证归并排序的稳定性 } while (i <= mid) { temp[index++] = A[i++]; } while (j <= right) { temp[index++] = A[j++]; } for (int k = 0; k < len; k++) { A[left++] = temp[k]; }}// 递归实现的归并排序(自顶向下)void MergeSortRecursion(int A[], int left, int right){ if (left == right) // 当待排序的序列长度为1时,递归开始回溯,进行merge操作 return; int mid = (left + right) / 2; MergeSortRecursion(A, left, mid); //左半部分排好序 MergeSortRecursion(A, mid + 1, right); //右半部分排好序 Merge(A, left, mid, right); //合并左右部分}// 非递归(迭代)实现的归并排序(自底向上)void MergeSortIteration(int A[], int len){ int left, mid, right;// 子数组索引,前一个为A[left...mid],后一个子数组为A[mid+1...right] for (int i = 1; i < len; i *= 2) // 子数组的大小i初始为1,每轮翻倍 { left = 0; while (left + i < len) // 后一个子数组存在(需要归并) { mid = left + i - 1; right = mid + i < len ? mid + i : len - 1;// 后一个子数组大小可能不够 Merge(A, left, mid, right); left = right + 1; // 前一个子数组索引向后移动 } }}int main(){ int A1[] = { 6, 5, 3, 1, 8, 7, 2, 4 }; // 从小到大归并排序 int A2[] = { 6, 5, 3, 1, 8, 7, 2, 4 }; int n1 = sizeof(A1) / sizeof(int); int n2 = sizeof(A2) / sizeof(int); MergeSortRecursion(A1, 0, n1 - 1); // 递归实现 MergeSortIteration(A2, n2); // 非递归实现 printf("递归实现的归并排序结果:"); for (int i = 0; i < n1; i++) { printf("%d ", A1[i]); } printf(" "); printf("非递归实现的归并排序结果:"); for (i = 0; i < n2; i++) { printf("%d ", A2[i]); } printf(" "); system("pause"); return 0;}声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号