微软机器翻译技术突破,中英新闻翻译媲美人类!
发表时间: 2018-03-15 12:02
翻译没有唯一标准答案,它更像一种艺术。
14日晚,微软亚洲研究院与雷德蒙研究院的研究人员宣布,其研发的机器翻译系统在通用新闻报道测试集newstest2017的中-英测试集上,达到了可与人工翻译媲美的水平;这是首个在新闻报道的翻译质量和准确率上可以比肩人工翻译的翻译系统。
newstest2017测试集由来自产业界和学术界的团队共同开发完成,并于2017年在WMT17大会上发布。而新闻(news)测试集则是三类翻译测试集中的一个,其他两类为生物医学(biomedical)和多模式(multimodal)。
四大技术
我们知道,对于同一个意思人类可以用不同的句子来表达,因此翻译并没有标准答案,即使是两位专业的翻译人员对于完全相同的句子也会有略微不同的翻译,而且两个人的翻译都不错。微软亚洲研究院副院长、自然语言计算组负责人周明表示:“这也是为什么机器翻译比纯粹的模式识别任务复杂得多,人们可能用不同的词语来表达完全相同的意思,但未必能准确判断哪一个更好。”
这也是为什么科研人员在机器翻译上攻坚了数十年,甚至曾经很多人都认为机器翻译永远不可能达到人类翻译的水平。近两年随着深度神经网络的引入,机器翻译的表现取得了很多显著的提升,翻译结果相较于以往的统计机器翻译结果更加的自然流畅。
据雷锋网(公众号:雷锋网)了解,在这次的工作中来自微软亚洲研究院和雷德蒙研究院的三个研究组通过多次交流合作,将他们的研究工作相结合,再次更进一步地提高了机器翻译的质量,其中用到的技术包括对偶学习(Dual Learning)、推敲网络(Deliberation Networks)、联合训练(Joint Training)和一致性规范(Agreement Regularization)等。
对偶无监督学习框架
对偶学习,即利用任务的对偶结构来进行学习。例如,在翻译领域,我们关心从英文翻译到中文,也同样关心从中文翻译回英文。由于存在这样的对偶结构,两个任务可以互相提供反馈信息,而这些反馈信息可以用来训练深度学习模型。也就是说,即便没有人为标注的数据,有了对偶结构也可以做深度学习。另一方面,两个对偶任务可以互相充当对方的环境,这样就不必与真实的环境做交互,两个对偶任务之间的交互就可以产生有效的反馈信号。因此,充分地利用对偶结构,就有望解决深度学习和增强学习的瓶颈——训练数据从哪里来、与环境的交互怎么持续进行等问题。
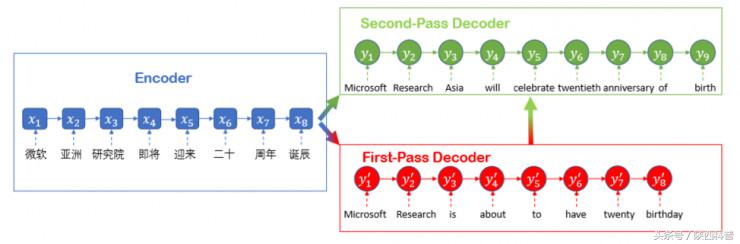
推敲网络的解码过程
推敲网络中的“推敲”二字可以认为是来源于人类阅读、写文章以及做其他任务时候的一种行为方式,即任务完成之后,并不当即终止,而是会反复推敲。微软亚洲研究院机器学习组将这个过程沿用到了机器学习中。推敲网络具有两段解码器,其中第一阶段解码器用于解码生成原始序列,第二阶段解码器通过推敲的过程打磨和润色原始语句。后者了解全局信息,在机器翻译中看,它可以基于第一阶段生成的语句,产生更好的翻译结果。
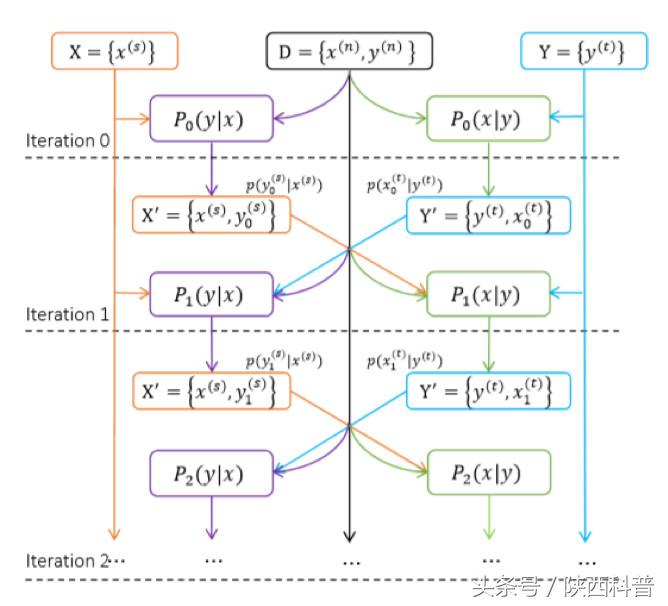
联合训练:从源语言到目标语言翻译(Source to Target)P(y|x) 与从目标语言到源语言翻译(Target to Source)P(x|y)
联合训练可以认为是从源语言到目标语言翻译(Source to Target)的学习与从目标语言到源语言翻译(Target to Source)的学习的结合。中英翻译和英中翻译都使用初始并行数据来训练,在每次训练的迭代过程中,中英翻译系统将中文句子翻译成英文句子,从而获得新的句对,而该句对又可以反过来补充到英中翻译系统的数据集中。同理,这个过程也可以反向进行。这样双向融合不仅使得两个系统的训练数据集大大增加,而且准确率也大幅提高。
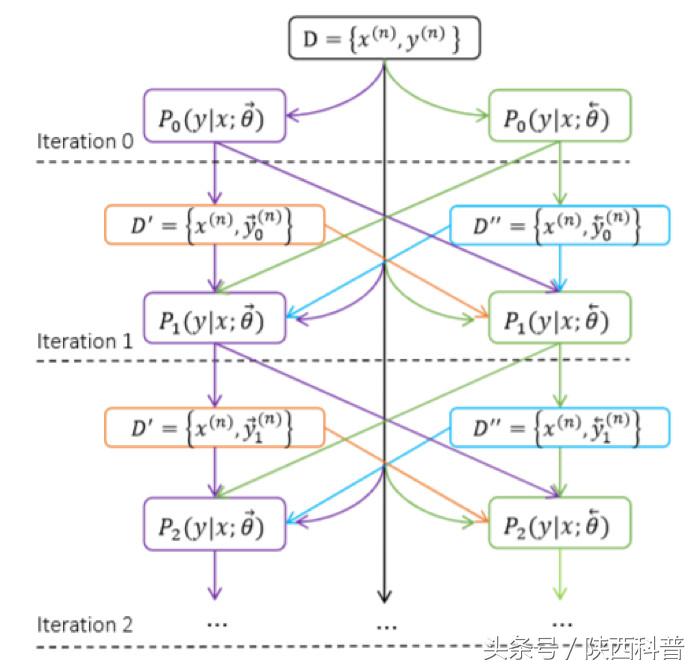
一致性规范:从左到右P(y|x,theta->) 和从右到左P(y|x,theta<-)
一致性规范,即翻译结果可以从左到右按顺序产生,也可以从右到左进行生成。该规范对从左到右和从右到左的翻译结果进行约束。如果这两个过程生成的翻译结果一样,一般而言比结果不一样的翻译更加可信。这个约束,应用于神经机器翻译训练过程中,以鼓励系统基于这两个相反的过程生成一致的翻译结果。
与人类比较
由于机器翻译没有“正确的”翻译结果,为了与人类的翻译水平进行比较,就必须严格地定义什么是与人类翻译水平相当。根据其发表的论文中表述,这种定义有两种:
1、如果一个具备双语能力的人判断人类输出的译文质量与机器输出的译文质量相当,则机器达到人类水平。
2、如果机器翻译系统在测试集上的译文质量得分(人工评分)与人类译文得分没有显著差别,则机器达到人类水平。
微软选择了第二种定义,因为这样相对而言比较公平且有实际意义。
newstest2017新闻报道测试集中共包括了约2000个句子,它们是由专业人员从在线报纸样本翻译而来。
微软团队对测试集进行了多轮评估,每次评估会随机挑选数百个句子进行翻译。
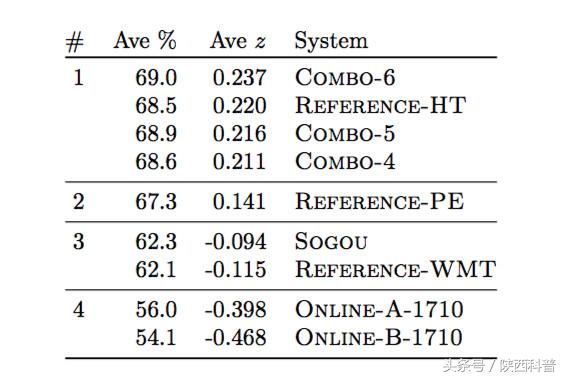
随后,为了验证微软的机器翻译是否达到了人类翻译水平,微软从外部聘请了一群双语语言顾问,让他们对微软的翻译结果和人工的翻译进行比较和评分,结果如下:
#表示集群的排名,Ave%表示平均原始分数(范围在[0,100]之间),Ave z表示标准 z分数。该表显示了系统收集了至少1827份评估结果。
从表中我们可以看出,微软的系统(Combo-4, 5, 6)已经与人类翻译(Reference-HT)无显著差别,远远超过Reference-PE(人类翻译—基于机器翻译后的编辑)以及Reference-WMT。
任重而道远
对于这项结果,来自微软的研究人员却表现地极为自然。
微软技术院士黄学东,负责微软语音、自然语言和机器翻译
微软技术院士黄学东告诉记者:
“在机器翻译方面达到与人类相同的水平是所有人的梦想,我们没有想到这么快就能实现。消除语言障碍,帮助人们更好地沟通,这非常有意义,值得我们多年来为此付出的努力。”
微软机器翻译团队研究经理Arul Menezes表示:
“团队想要证明的是:当一种语言对(比如中-英)拥有较多的训练数据,且测试集中包含的是常见的大众类新闻词汇时,那么在人工智能技术的加持下机器翻译系统的表现可以与人类媲美。”
微软亚洲研究院副院长、自然语言计算组负责人周明
微软亚洲研究院副院长、自然语言计算组负责人周明则表示任重而道远:
“在WMT17测试集上的翻译结果达到人类水平很鼓舞人心,但仍有很多挑战需要我们解决,比如在实时的新闻报道上测试系统等。”
微软亚洲研究院副院长、机器学习组负责人刘铁岩
而微软亚洲研究院副院长、机器学习组负责人刘铁岩对技术的进展表示乐观:
“我们不知道哪一天机器翻译系统才能在翻译任何语言、任何类型的文本时,都能在“信、达、雅”等多个维度上达到专业翻译人员的水准。我们可以预测的是,新技术的应用一定会让机器翻译的结果日臻完善。”
据雷锋网了解,此次的技术突破将很快应用到微软的商用多语言翻译系统产品中,从而帮助其它语言或词汇更复杂、更专业的文本实现更准确、更地道的翻译。此外,这些新技术还可以被应用在机器翻译之外的其他领域,催生更多人工智能技术和应用的突破。
(来源:雷锋网*)
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12




 鲁公网安备37020202000738号
鲁公网安备37020202000738号