LSM树:数据结构与算法的完美结合
发表时间: 2019-11-20 11:14
LSM即Log Structured Merge Trees,翻译成中文即日志结构合并树,严格意义上来讲,它并不算一种数据结构,只是一种思想而已,小编考虑再三,还是把它当做数据结构放到本专题详细的聊一聊。
近年来,基于日志的策略在大数据之间越来越流行,同时他们也有一些缺点,从日志文件中读一些数据将会比写操作需要更多的时间,需要倒序扫描,直接找到所需的内容。
这说明日志仅仅适用于一些简单的场景:
1. 数据是被整体访问,像大部分数据库的WAL(write-ahead log)
2. 知道明确的offset,比如在Kafka中。
简单的说,LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。这是基于磁盘随机操作慢,顺序读写快。
LSM是当前被用在许多产品的文件结构策略:HBase, Cassandra, LevelDB, SQLite, rocksdb,mangodb,再次强调它不是数据结构,仅仅是一种设计思想。
1.哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right
2.B树存储引擎是B树(关于B树的由来,数据结构以及应用场景可以看之前一篇博文)的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
3.LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
从国外网站爬来的图片,感觉很贴切,基本是小编要表达的意思。
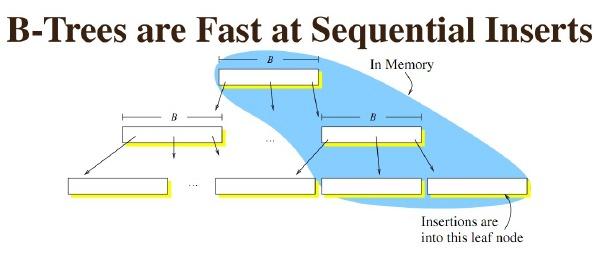
B树在插入的时候,如果是最后一个node,那么速度非常快,因为是顺序写
但如果有更新插入删除等综合写入,最后因为需要循环利用磁盘块,所以会出现较多的随机io.大量时间消耗在磁盘寻道时间上。
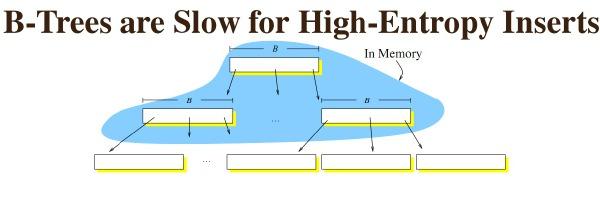
如果是一个运行时间很长的b树,那么几乎所有的请求,都是随机io。因为磁盘块本身已经不再连续,很难保证可以顺序读取
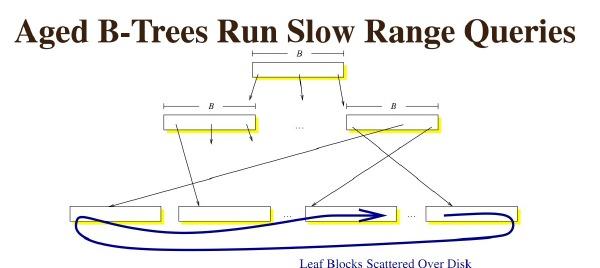
、
1.放弃部分读性能,使用更加面向顺序写的树的结构来提升写性能
一类是COLA(Cache-Oblivious Look ahead Array)(代表应用自然是tokuDB)。
一类是LSM tree(Log-structured merge Tree)或SSTABLE
2.使用ssd,让寻道成为往事
但是局限性依旧很大,假设海量数据,SSD显然有点捉襟见肘。
LSM思想非常朴素,就是将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘(由此提升了写性能),是一种基于硬盘的数据结构设计思想,与B-tree相比,能显著地减少硬盘磁盘臂的开销。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
读取时需要合并磁盘中的历史数据和内存中最近的修改操作,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件(存储在磁盘中的是许多小批量数据,由此降低了部分读性能。但是磁盘中会定期做merge操作,合并成一棵大树,以优化读性能)。LSM树的优势在于有效地规避了磁盘随机写入问题,但读取时可能需要访问较多的磁盘文件。
LSM核心就是放弃部分读能力,换取写入的最大化能力,放弃磁盘读性能来换取写的顺序性。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级(大概5~10倍),读性能低了一个数量级。
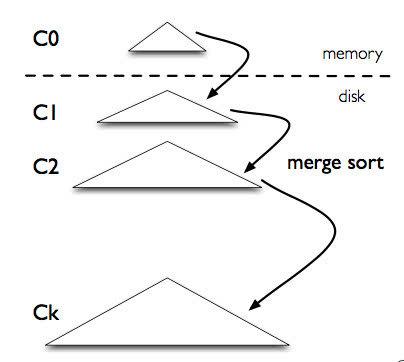
LSM数据结构简单示例
上图是 LSM-tree 的组成部分,是一个多层结构,就更一个树一样,上小下大。首先是内存的 C0 层,保存了所有最近写入的 (k,v),这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。剩下的 C1 到 Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构。
写入流程:一个 put(k,v) 操作来了,首先追加到写前日志(Write Ahead Log,也就是真正写入之前记录的日志)中,接下来加到 C0 层。当 C0 层的数据达到一定大小(一般达到磁盘页大小),就把 C0 层 和 C1 层合并,类似归并排序,这个过程就是Compaction(合并)。合并出来的新的 new-C1 会顺序写磁盘,替换掉原来的 old-C1。当 C1 层达到一定大小,会继续和下层合并。合并之后所有旧文件都可以删掉,留下新的。
注意数据的写入可能重复,新版本需要覆盖老版本。什么叫新版本,我先写(a=1),再写(a=233),233 就是新版本了。假如 a 老版本已经到 Ck 层了,这时候 C0 层来了个新版本,这个时候不会去管底下的文件有没有老版本,老版本的清理是在合并的时候做的。
写入过程基本只用到了内存结构,Compaction 可以后台异步完成,不阻塞写入。
读取流程:在写入流程中可以看到,最新的数据在 C0 层,最老的数据在 Ck 层,所以查询也是先查 C0 层,如果没有要查的 k,再查 C1,逐层查。
一次查询可能需要多次单点查询,稍微慢一些。所以 LSM-tree 主要针对的场景是写密集、少量查询的场景。
LSM-tree 被用在各种键值数据库中,如 LevelDB,RocksDB,还有分布式行式存储数据库 Cassandra 也用了 LSM-tree 的存储架构。
在LSM树上进行一次数据更新不需要磁盘访问,在内存即可完成,速度远快于B+树。当数据访问以写操作为主,而读操作则集中在最近写入的数据上时,使用LSM树可以极大程度地减少磁盘的访问次数,加快访问速度。
LSM树 删除数据 前面讲了。LSM树所有操作都是在内存中进行的,那么删除并不是物理删除。而是一个逻辑删除,会在被删除的数据上打上一个标签,当内存中的数据达到阈值的时候,会与内存中的其他数据一起顺序写入磁盘。 这种操作会占用一定空间,但是LSM-Tree 提供了一些机制回收这些空间。
1. Bloom filter : 就是个带随即概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是我就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
2. 小树合并为大树: 也就是大家经常看到的compact的过程,因为小树他性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了。
读写放大(read and write amplification)是 LSM-tree 的主要问题,这么定义的:读写放大 = 磁盘上实际读写的数据量 / 用户需要的数据量。注意是和磁盘交互的数据量才算,这份数据在内存里计算了多少次是不关心的。比如用户本来要写 1KB 数据,结果你在内存里计算了1个小时,最后往磁盘写了 10KB 的数据,写放大就是 10,读也类似。
写放大:
假如现在有三层,文件大小分别是:9,90,900,r=10。又写了个 1,这时候就会不断合并,1+9=10,10+90=100,100+900=1000。总共写了 10+100+1000。按理来说写放大应该为 1110/1,但是各种论文里不是这么说的,论文里说的是等号右边的比上加号左边的和,也就是10/1 + 100/10 + 1000/100 = 30 = r * level。个人感觉写放大是一个过程,用一个数字衡量不太准确,而且这也只是最坏情况。
读放大:
为了查询一个 1KB 的数据。最坏需要读 L0 层的 8 个文件,再读 L1 到 L6 的每一个文件,一共 14 个文件。而每一个文件内部需要读 16KB 的索引,4KB的布隆过滤器,4KB的数据块(看不懂不重要,只要知道从一个SSTable里查一个key,需要读这么多东西就可以了)。一共 24*14/1=336倍。key-value 越小读放大越大。
关于数据在磁盘的存储速度,我们有必要了解一下,请关注下篇磁盘的基本知识及顺序读取和随机读取。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号