大数据揭秘:后端技术在数据可视化中的应用
发表时间: 2019-12-18 16:43
这篇文章大致讲讲需要用到的后端技术。其实如果只是小数据量,或者是一些小型的项目,研究型的项目,纯前端就可以搞定,利用JS读取数据,JS处理数据。作者:代号22

后端无非就是处理数据,提取用户想要的数据。笔者最常用的就是python了,相对于java,c, c++,python简直对初学者太友好,提供了丰富多彩的API接口,比如常见的降维聚类算法:PCA, t-SNE, MDS, k-means等。笔者曾经用c实现过PCA算法,应该有几百行代码吧,可是在python里,只需要三行代码。下文将为大家介绍下如何用python实现对Iris数据集使用PCA算法,以及展示效果。
因此,笔者强烈建议新手使用python练手,操作门槛低,前期可以将更多的关注点集中在前端数据可视化上。到了后期,有经验了就可以自由组合。笔者前期使用的是python,可是到了后期由于性能问题,python已经很难解决我项目所遇到的数据和算法复杂度。于是我将复杂度高的算法全部用C重写了一遍,并用python调用这个模块。这样之前项目的项目代码框架不变,不需要代码全部重写重构,只需在相应的地方调用相应的C模块即可。
python使用PCA算法实战
在讲之前,用户需要安装python包,这里强烈建议新手安装anaconda,anaconda集成了python以及在开发过程中一大堆第三方包,比如下文用到的sklearn包。
引入第三方库的PCA算法,sklearn是pythonz中常用的机器学习第三方模块,对常用的机器学习方法进行了封装,包括回归、降维、分类、聚类等方法。
from sklearn.decomposition import PCA
加载python中自带的Iris数据集,做机器学习的应该比较熟悉这个数据集。主要包含4个维度,三个类。
from sklearn.datasets import load_iris irisData = load_iris()
对数据集使用PCA算法,将数据降到2维。
pca = PCA(n_components=2) reducedData = pca.fit(irisData)
将结果在散点图中画出来。这里就不讲具体python的绘制逻辑了,没错,python就是这么强大,也提供了可视化图表的能力。但是更多还是以处理数据为目的,将数据传给前端,让前端绘制。感兴趣的可以去了解下:matplotlib,这个是python的可视化绘图库。
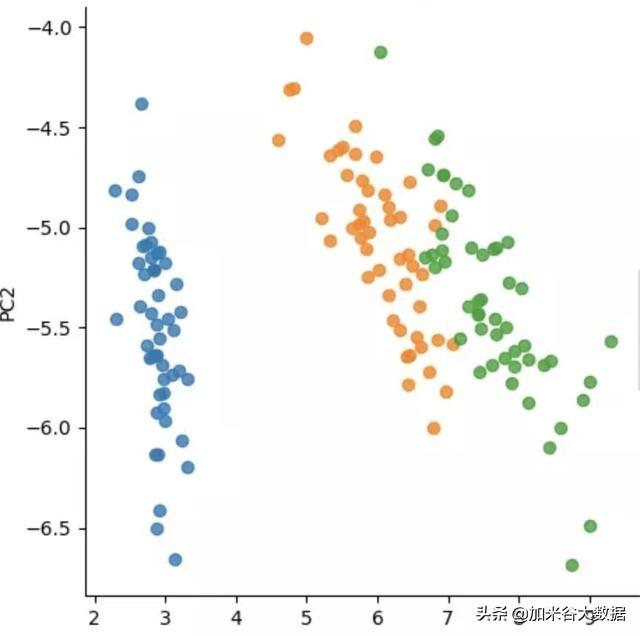
iris数据集降到二维
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号