掌握Python数据分析:SQLite数据库操作技巧
发表时间: 2022-04-05 10:45
SQLite是一个内存数据库,不需要配置,也不需要服务器,可以直接使用。
本文介绍一下如何在Python中使用SQLite数据库,在Python中,可以sqlite3这个库来调用SQLite数据库。
使用前,需要先导入sqlite3。
import sqlite3接着,使用特定的文件名‘:memory:’在内存中创建一个数据库。
con = sqlite3.connect(':memory:')运行后,得到一个数据库连接对象con。
在这个数据库中创建一个表,SQL语句如下。
createtb_sql = '''create table test( stuid varchar(10), stuname varchar(20), gender varchar(2), age integer);'''以上只是通过多行字符串定义了一条SQL语句,接下来执行。
con.execute(createtb_sql)con.commit()以上代码中,通过con对象中的execute方法来执行这个建表语句。
运行后,创建一个表test,此时还没有数据。
向里面插入一条记录,代码如下。
insert_sql = "insert into test values('20161001', 'sunbin', '男', 29);"con.execute(insert_sql)con.commit()查询看看。
cursor = con.execute('select * from test;')cursor.fetchall()运行结果:
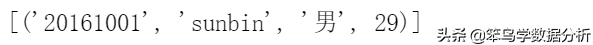
从查询结果可以看出,整个结果是一个列表,列表里每条记录是一个元组。
如果要插入多条记录,可以这样来写。
data = [('20161002','Zhangsan','男',19), ('20161003','Lisi','女',22), ('20161004','Wangwu','男',21)]insert_sql2 = "insert into test values(?, ?, ?, ?);"以上代码中,先定义数据data,再写一条insert语句,问号表示占位符。
接着,执行以上插入语句,代码如下。
con.executemany(insert_sql2, data)con.commit()注意,此时调用的是executemany,表示插入多条记录。
再次查询,代码如下。
cursor = con.execute('select * from test;')cursor.fetchall()运行结果:

但是,以上查询结果不太方便在Python中分析,因为在Python数据分析中,一般通过数据框的形式来处理数据,以上查询结果还需要转换为数据框的形式。

当然,我们并不需要去转换,因为pandas中提供了一个函数read_sql_query,位于pandas.io.sql模块,该函数能够直接得到数据框形式的查询结果,只需要传入select语句和连接对象即可。
import pandas.io.sql as sqlsql.read_sql_query('select * from test;', con)运行结果:
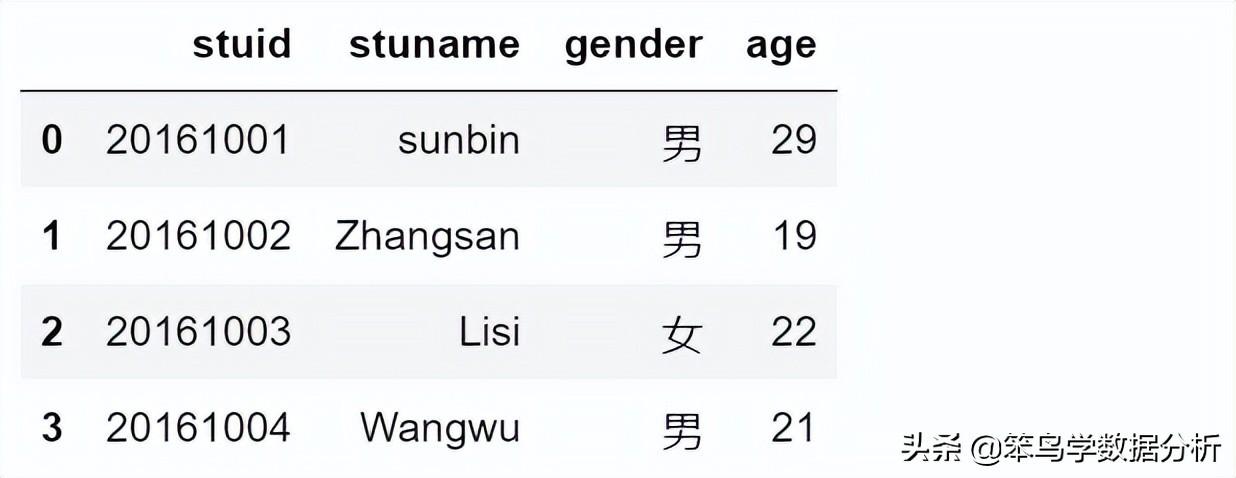
此时得到的查询结果就是一个数据框。
以上就是在Python中使用SQLite数据库。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号