九章云极DataCanvas:致力于开源数据库的认真之作
发表时间: 2021-11-26 11:29
中国正值企业数智化转型的时代拐点之际,企业数据规模呈现爆炸性增长、数据类型愈发丰富、新数据应用场景深化等特点,云数据库、HTAP 数据库、开源数据库等新型数据库的出现,推动数据库领域全新发展。
据中国信息通信研究院发布的《数据库发展研究报告(2021年)》显示,2020 年全球数据库市场规模为 671 亿美元,其中中国数据库市场规模为 35 亿美元,占全球 5.2%。预计到 2025 年,全球数据库市场规模达到 798 亿美元。
中国数据库发展潜力巨大,随着业界对国产基础软件自主创新的呼声逐渐高涨,越来越多科技公司投入数据库研发。近日,九章云极DataCanvas将自研新一代集分析与高并发服务一体的混合数据库DingoDB正式开源,笔者认为,这是国产数据库逐步走出自身风格,形成独特流派的表现之一。
兼顾数据分析和高频数据服务,DingoDB为数据智能而生
随着Hadoop 开源技术的成熟,越来越多开源大数据工具都可以用来为数据分析提速,助力大数据平台发展。但是工具栈的繁荣却没有解决最根本的症结,如何兼顾数据分析与高并发服务的的实时能力,始终是众多大数据开发者所要面对的一道难题。
我们知道数据访问是受局部性原理所支配的,现代硬盘、内存工作原理是当用户读某一区域的数据时,其临近的数据也会被调入上一级高速缓存,读取临近的数据效率会远比随机的数据访问快得多,因此现代数据库最本质的优化工作,是将有关联计算需求的数据放在一起存储,在实际应用中高频数据服务与数据分析两种场景所需要的存储模型的确不同。
以金融场景为例,在银行实时交易场景中,数据访问是大多在数据行维度进行展开。如在存储交易中,对客户信息表中的特定一条记录进行多次访问,并对客户的姓名、帐户、手机号、密码进行识别验证,这种场景下以数据行为粒度进行数据的存储读取效率最高。
然而在数据分析生成报表的场景中,报表用户往往只关心总体情况,比如全行的存款总额、贷款总额等,此时数据以存储、贷款等列为粒度进行存取及关联计算的效果最好。总结来说,交易型数据库处理速度要快,分析型数据库处理能力要高。
之前交易与分析的应用场景基本处于“井水不犯河水”的状态,但随着直播带货等新场景需求涌现,在直播中既要保证用户顺利完成交易,同时根据用户行为做实时分析、精确营销的需求不断涌现,在时代大潮的推动下,HSAP(实时分析数据库)数据库应运而生,集分析和服务为一体的开源数据库 DingoDB正是其中的代表之一。
对于营销、推荐场景中,企业对数据的时效性相对于数据的准确性要求更高。而企业的数据处理架构通常以Lambda为主,通过批计算和流计算的混合计算引擎来服务企业数据处理。由于离线层和实时层引入的计算引擎、存储引擎各不相同,潜在的造成计算结果不一致、数据散列冗余存储、难以维护等问题。
九章云极DataCanvas最新开源的DingoDB,高效支持高频修改和查询、实时交互式分析、实时多维分析等功能,兼具行列混存等技术创新,有效直击行业痛点,引领未来 HSAP 数据库发展。
DingoDB混合场景的打开方式:行列混存+智能优化器
在直播带货、金融理财销售等场景,业务员可能仅有几分钟时间来争取客户,需根据客户行为快速做出反应,把握住转瞬即逝的营销机会。
但传统技术方案无法做到实时计算,或很难保证实时计算的准确性,数据准确性、时效性的高要求与系统实际的服务处理能力之间巨大的鸿沟,导致大数据工程师与产品经理之间永远无法达成协议。
DingoDB智能优化器实现行列优化选择的混合存储方案令人眼前一亮,之前业界有不少将行列进行混存,以综合行列存两者优势的探索,但对于联机交易场景而言,列式存储的写入性能低、难修改,最后退化成为行式存储。在通过夜间数据交换,将趋于稳定的交易数据转换到列式存储分析型数据库,进行数据价值挖掘,通过业务形态进行行列存数据的分别存储,在业务侧实现数据融合。
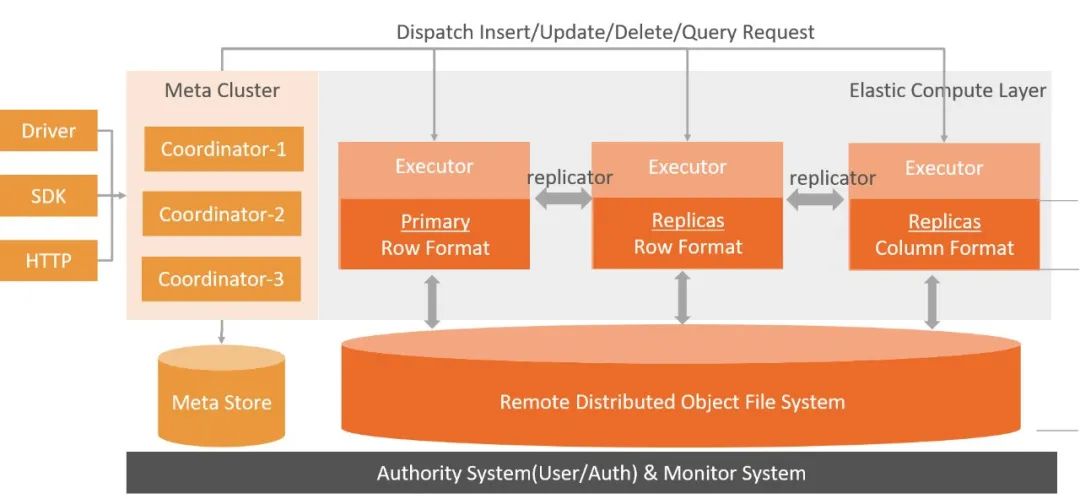
DingoDB 的行列混存方案是基于列存模式实现计算列的快速顺序读取,基于内存计算和Arrow,实现数据的聚合高效分析。针对交易场景中,DingoDB通过行存模式实现数据的记录级定位,实现数据的点查询、更新、修改和删除操作,基于分布式一致性协议来实现行列的转换,保证行存副本和列存副本的一致性,如此一来,既保证了实效性又保证了准确性。
在联机交易完成进行数据分析时,DingoDB将用户输入的SQL通过智能优化器来生成最优的执行计划,并分配计算任务。DingoDB系统内的Coordinator会对表级的元数据进行管理和存储,在进行SQL解析时,会基于执行计划和数据分布,提供最佳的数据存储格式。
如对聚合类的分析场景,优化器通过对SQL计划的解析,将SQL计划转变成分布式执行任务,基于任务中的算子类型自动选择列存模式;对于记录级的修改和查询操作,会转变成行存模式,实现数据的点查、修改操作。针对用户的分析计算场景,通过不同的优化器选择不同的数据存储格式,提供最佳的分析性能。
另外,DingoDB作为实时数字仓的底层存储,由实时数字仓演变出来的实时指标、实时大屏、实时报表等场景,均可通过 DingoDB 得到满足。
DingoDB——逻辑架构
DingoDB允许用户通过直接 SQL 语句来定义 BI 大屏或者报表中的计算逻辑,并由此实现企业核心业务指标的实时监测和计算,而不需要再去关心数据的实效性及准确性问题。基于DingoDB强大的分析能力,可对企业数据进行实时多维分析,提供最客观的业务数据,为企业用户的决策做出强力支持,企业基于实时计算的结果,可以实现核心业务的实时监控,并快速做出反应,实时分析+多维数据的方案完美地解决业务人员营销数据不快、不准的问题。
DingoDB K-V神方案:实时高频更新
Hadoop 等用于数据分析的大数据技术栈内大多使用 Key-value 的存储方式,Key-value存储的特点就是擅长增量写入和查询,然而一碰到插入、更新就效率下降;Mysql 等用于实时交易的数据库通常使用 B+ 树为模型进行数据存储,但 B+ 树虽然容易建立索引,优化读取速度,但数据的规模受限,很难应对大数据规模条件下的高频服务查询、修改、删除等场景。
DingoDB 行存储数据库没有使用 B+ 树的数据存储方案,转而采用基于 LSM Tree 的 RocksDB 作为行存底层数据存储引擎,RocksDB将数据的随机写,转换成了磁盘上的顺序写,具有很高的随机写吞吐能力。
在高频交易场景中,SQL 优化器将记录级的操作,转变成 RocksDB 中的记录级的点操作,可以实现数据记录的Upsert、Delete操作,实现高频更新。
这项创新技术在现实有广泛应用,如在手机银行积分兑换、支付宝信用分查询等场景中,用户需不断地调阅自身的历史交易记录,根据历史记录来决定自己后续的交易行为,借助 DingoDB 提供的高频点查、修改能力,完全可以让用户在刷积分时享受到丝丝顺滑的体验。
开源DingoDB,拓展企业数据新应用场景
专注自动化数据科学平台的持续开发与建设的九章云极DataCanvas,自研DingoDB基于智能优化器实现行列优化选择、多副本机制存算弹性扩展、高频点查、修改操作等创新技术,为行业提供前沿实时大屏、实时互动分析、多维实时数据分析、数据高频查询修改等数据新应用解决方案。相信未来DingoDB不断创新,为企业降低系统数据使用成本,提升数据价值。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12




 鲁公网安备37020202000738号
鲁公网安备37020202000738号